✅ 문제 직면
내가 구현하고 있는 부분은 백오피스 부분이다.
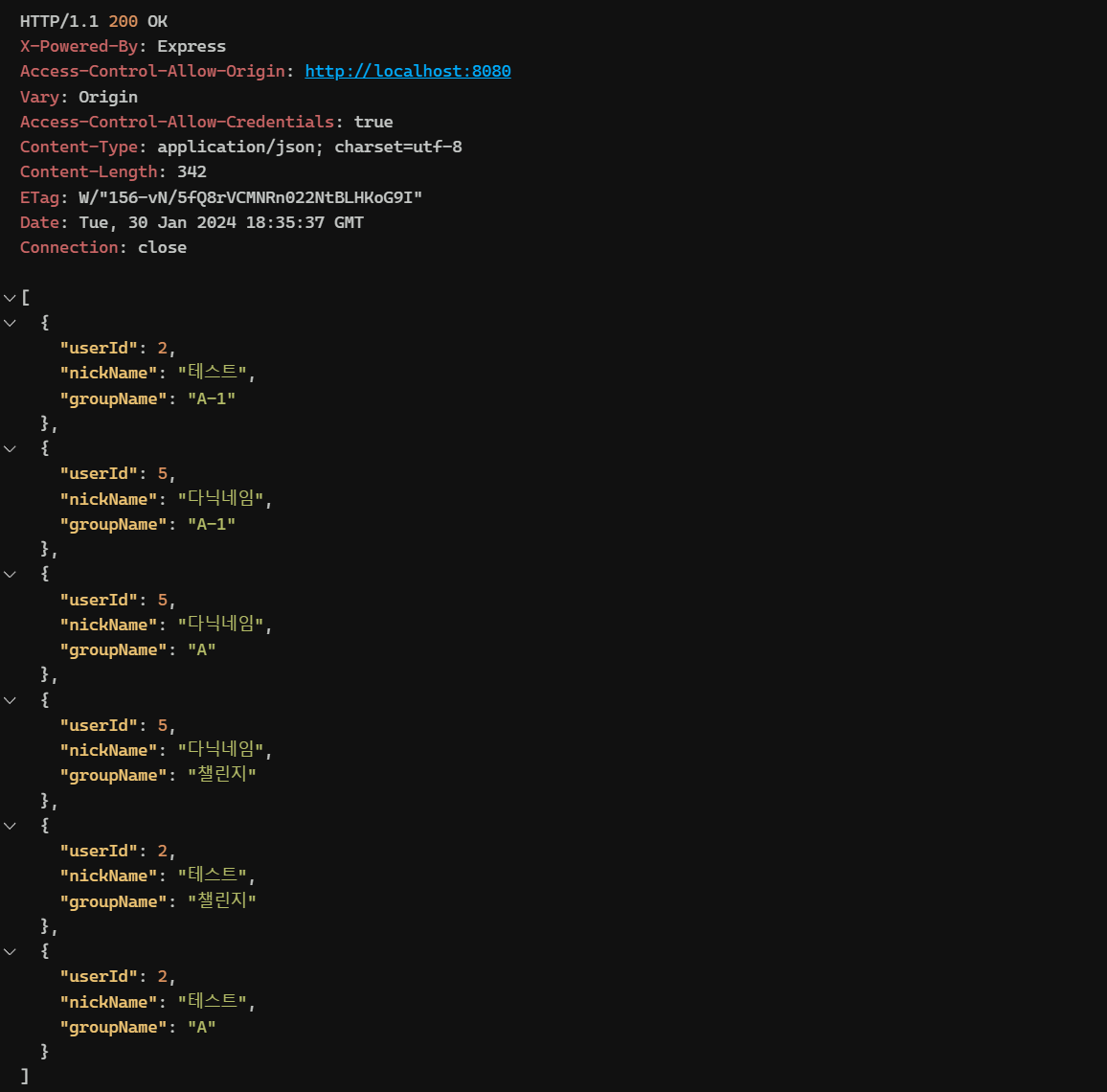
해당 스페이스의 관리자인 아이디로 스페이스에 속한 모든 사용자들의 그룹이름과 닉네임과 user_id값을 가지고와서 프론트에 뿌려줘야 한다.
하지만 문제가 있었다.
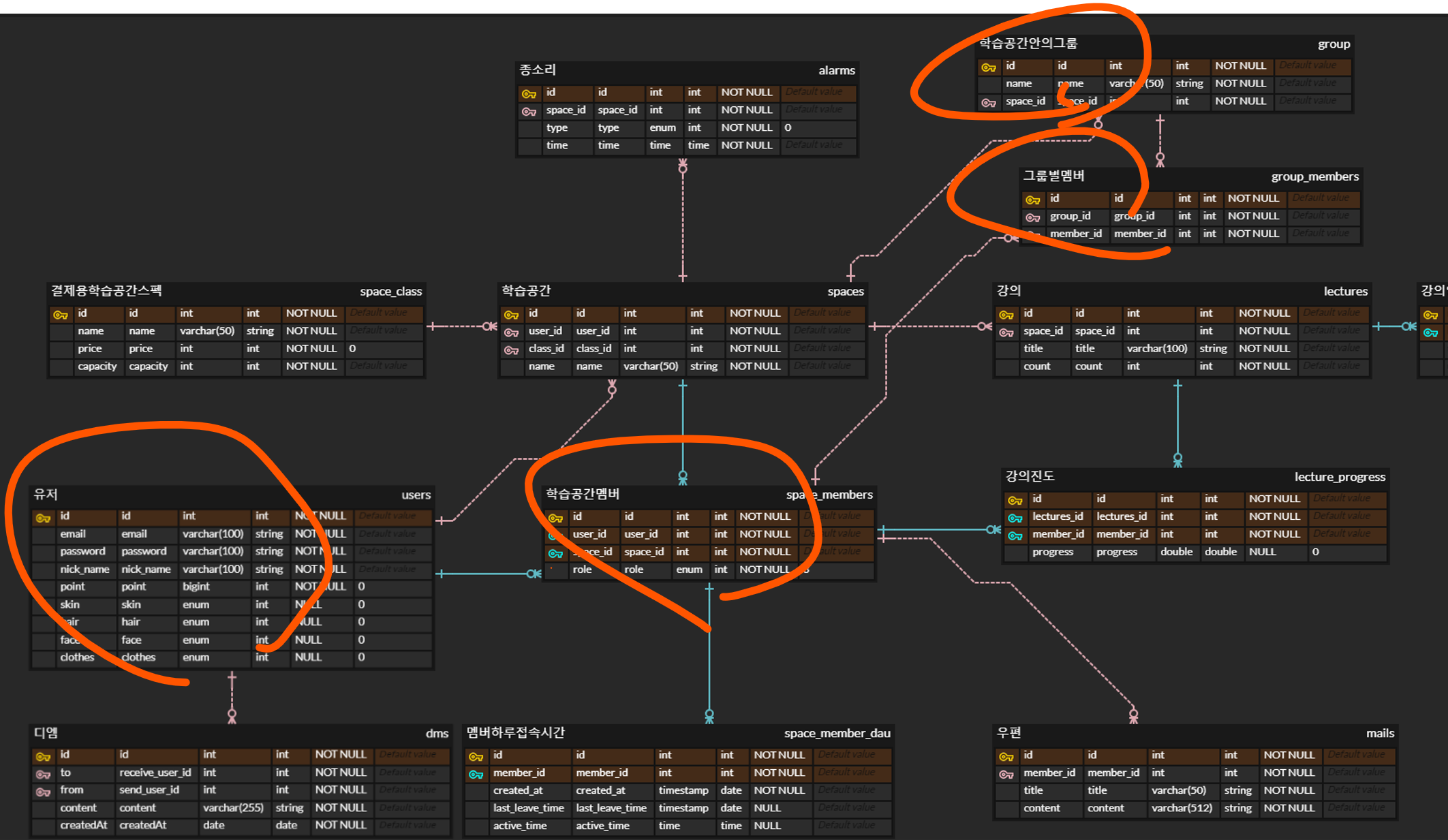
이를 위해서는 표시된 부분의 테이블을 모두 참조해야 한다.
현재 관리자가 가지고 있는 정보는 spaceId와 관리자의 userId 밖에 없는 상황에서

이 데이터들을 반환하게끔 만들 수 있을까?
현재 만들어 둔 백엔드 api 코드는 없었기 때문에 만들어줘야 했다.
✅ 기존 코드
async getGroupUsers(spaceId: number, userId: number) {
const groupMembers = [];
const groupMemberList =
await this.spaceMembersService.getSpaceMemberIdBySpaceId(spaceId, userId);
console.log('그룹 멤버에서 불러온 값 ===>', groupMemberList);
const promises = groupMemberList.map(async (data) => {
return this.groupMembersRepository.find({
where: { member_id: data.id },
relations: ['group', 'space_member.user'],
});
});
const results = await Promise.all(promises);
console.log('results ====> ', results);
results.forEach((result) => {
groupMembers.push(...result);
result.forEach((data) => {
const obj = {
userId: data.space_member.user.id,
nickName: data.space_member.user.nick_name,
groupName: data.group.name,
};
groupMembers.push(obj);
});
});
return groupMembers;
}일단 무조건 원하는 데이터를 "뽑아올 수 있게끔 반환" 하는 것을 목표로 짠 코드이다.
하지만 여기서 문제가 있다.
문제점
이 코드에서는 각
groupMemberList항목에 대해 별도의 데이터베이스 쿼리를 실행하고 있다. 이러한 방식은groupMemberList의 크기가 커질수록 많은 수의 쿼리를 발생시켜 성능에 부정적인 영향을 줄 수 있다. 이를N+1 쿼리 문제라고 한다. 즉, 초기 쿼리 1회와 각 항목에 대한 추가 쿼리 N회가 실행된다. 대량의 데이터 처리 시 이러한 접근 방식은 데이터베이스에 큰 부하를 주고 응답 시간을 늘릴 수 있다.
현재는 작은 프로젝트이고 실제 서비스가 아니기 떄문에 당장 부하는 없을지라도 내가 실제 서비스를 개발하는 개발자 입장에서 생각해봤을 때 위 코드는 상당히 안좋은 코드임이 분명히 느껴졌다.
따라서 원하는 데이터를 뽑아오기 위해서 많은 쿼리를 실행시키는 것을 최소화 하기 위해서 리팩토링을 했었다.
✅ 리팩토링
// 리팩토링 한거
async getGroupUsers(spaceId: number, userId: number) {
// 특정 스페이스에 속한 모든 그룹 멤버의 ID를 가져옴
const groupMemberIds = (
await this.spaceMembersService.getSpaceMemberIdBySpaceId(spaceId, userId)
).map((data) => data.id);
// groupMemberIds 배열을 사용하여 모든 관련 데이터를 한 번의 쿼리로 가져옴
const groupMembersData = await this.groupMembersRepository
.createQueryBuilder('groupMember')
.leftJoinAndSelect('groupMember.group', 'group')
.leftJoinAndSelect('groupMember.space_member', 'spaceMember')
.leftJoinAndSelect('spaceMember.user', 'user')
.where('groupMember.member_id IN (:...groupMemberIds)', {
groupMemberIds,
})
.getMany();
// 결과 데이터를 원하는 구조로 변환
const groupMembers = groupMembersData.map((data) => ({
userId: data.space_member.user.id,
nickName: data.space_member.user.nick_name,
groupName: data.group.name,
}));
return groupMembers;
}해당 리팩토링한 코드의 목표는 다음과 같다.
- 불필요한 중복 제거
- N+1 쿼리 문제 해결
- 결과 구조의 명확성
중복 제거
- 처음에
groupMembers.push(...result)를 사용해 결과 배열에 데이터를 두 번 추가하는 부분을 제거 했다. 이는 데이터 중복을 방지하고 결과 배열의 정확성을 보장한다.
단일 쿼리 실행
- 모든
groupMemberList에 대해 개별 쿼리를 실행하는 대신groupMemberIds를 사용하여 관련된 모든 데이터를 단일 쿼리로 가져온다. 이는 데이터베이스에 대한 쿼리 수를 크게 줄이고,N+1 쿼리 문제를 해결할 수 있다.
데이터 변환
- 가져온 데이터
groupMemberData를 바로 결과 배열에 푸시하는 대신map을 사용하여 원하는 구조의 객체로 변환 후 결과 배열에 추가한다. 이는 코드의 가독성과 유지보수성을 향상시킬 수 있다.
✅ 기존 코드와 리팩토링 코드의 차이점
기존 코드
Promise.all을 사용하여 각 groupMemberList 항목에 대해 별도의 쿼리를 비동기적으로 실행한다. 이는 다음과 같은 특징을 가진다.
병렬 처리
Promise.all은 모든 프로미스가 완료될 때까지 병렬로 실행되므로, 각 쿼리의 실행 시간이 서로에게 영향을 미치지 않는다. 하지만 각 쿼리에 대한 초기화와 네트워크 요청이 별도로 이루어져야 한다.
N+1 쿼리 문제
- 각 항목에 대한 별도의 쿼리를 실행하는 방식은
N+1쿼리 문제를 발생시킬 수 있다. 이는groupMemberList의 크기에 비례하여 데이터베이스 요청 수가 증가함을 의미한다.
네트워크 지연과 데이터베이스 부하
- 각 쿼리에 대한 별도의 네트워크 요청은 지연을 증가시키고 데이터베이스에 더 많은 부하를 줄 수 있다. 특히
groupMemberList의 크기가 큰 경우 이 문제는 더욱 심각해질 수 있다.
리팩토링 코드
리팩토링 코드는 createQueryBuilder를 사용하여 관련 데이터를 한 번의 쿼리로 가져온다. 이 접근 방식의 주요 장점은 다음과 같다.
N+1 문제 회피
- 여러 관계를 포함하는 복잡한 데이터를 가져올 떄
N+1 쿼리 문제를 자연스럽게 회피한다. 해당 문제는 각 항목에 대해 추가 쿼리를 실행해야 하므로 성능 저하를 일으킬 수 있다.
네트워크 지연 최소화
- 단일 쿼리를 사용하면 여러 번의 네트워크 요청 대신 한 번의 요청으로 필요한 모든 데이터를 검색할 수 있어 네트워크 지연이 크게 줄어든다.
데이터베이스 부하 감소
- 하나의 복잡한 쿼리가 여러 개의 간단한 쿼리보다 데이터베이스에 미치는 부하가 적을 수 있다. 데이터베이스는 쿼리 최적화를 통해 효율적인 실행 계획을 수립할 수 있다.
✅ N+1 쿼리 문제란?
먼저 기존에 작성한 코드에서 N+1쿼리 문제가 발생한 이유에 대해서 알아보자면
groupMemberList 배열의 각 항목 data에 대해 반복문 map을 사용하여 groupMembersRepository.find 메서드를 호출한다 이 과정에서 groupMemberList의 각 항목마다 아래와 같은 쿼리가 실행된다.
-
where조건으로{ member_id: data.id }를 사용하여, 각groupMemberList항목의member_id에 해당하는groupMember레코드를 찾는다. -
relation옵션으로['group', 'space_member.user']를 지정하여 찾은groupMember레코드와 관련된group및space_member.user엔티티를 로드한다.
이 과정에서 groupMemberList배열의 길이만큼 데이터베이스 쿼리가 실행된다. 예를 들어, groupMembe 레코드와 관련된 group및 space_member.user 배열에 10개의 항목이 있다면 총 10개의 별도 쿼리가 데이터베이스에 전송된다.
하지만 리팩토링 된 코드에서는 createQueryBuilder를 사용하여 groupMemberIds 배열에 있는 모든 member_id 에 대응하는 데이터를 한 번의 쿼리로 가져온다 즉, .where('groupMember.member.id IN (:...gorupMemberIds)', { groupMemberIds})'부분에서 IN연산자를 사용하여 groupMemberIds 배열에 포함된 모든 member_id값을 한 번의 쿼리로 처리한다.
✅ 결과