Target
- https://paperswithcode.com/paper/an-image-is-worth-16x16-words-transformers-1
- https://arxiv.org/abs/2010.11929
- Transformer 구조를 NLP 분야가 아닌 Vision 분야에도 적용
- 논문 출간 기점으로 많이 이용되는 CNN 구조의 모델과 비교하였을 때 어느정도 동일한 성능지표를 나타냄
키워드
- CNN
- Transformer
배경
- CNN 구조에 의존하는 방식에서 벗어나, Transformer를 직접적으로 사용하면서 이미지를 Patch 형식으로 잘라 Sequence로써 활용하는 방식으로 이미지 분류를 수행
- Transformer가 NLP 분야에서 높은 성능을 나타내면서 자리를 잡던 시점, Vision 분야에서는 그리 힘을 쓰지 못했음.
- Vision 분야에서 Attention은 주로 CNN 구조에 결합하여 쓰거나, CNN의 구성요소를 대체하는 방식으로 주로 이용되었음.
기본 개념
- 이미지 자체를 Transformer 모델에 직접적으로 input하는 형태로 구성하며, Vision Transformer (ViT) 이라 통칭
- 이미지를 Patch 단위로 쪼개서 Token화 시킴
- Patch에 linear embedding 적용, 이후 시퀀스로 만들어 준 형태로 Transformer 모델로 Input
모델 아키텍쳐
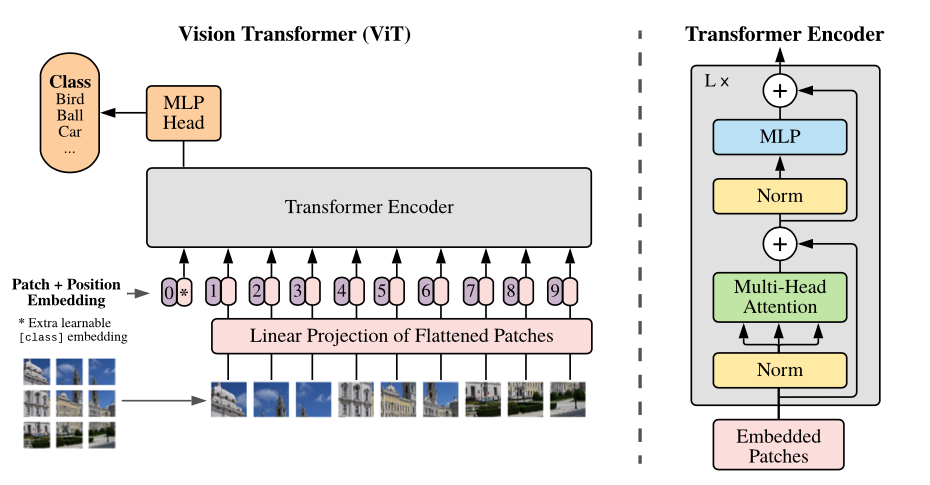
- (Height, Width, Channel)의 이미지를
일정한 사이즈의 (P, P) 패치로 분할 - 위치 정보를 포함하도록 Position embedding 진행
- 학습 가능한 Class 토큰을 입력
- Class 토큰을 제일 첫 부분 (0번) 에 입력함.
- 분할된 패치들을
Linear embedding + Flatten화를 수행한 뒤 Transformer Encoder에 input 값으로 입력 - Encoder를 통해 나오는 Class 토큰 값을 MLP Head에 넣어서 예측
기존 구조와의 차이점
- Transformer 기존 모델의 경우 Encoder, Decoder 구조 | Multihead Self-attention과 MLP 이후 Layer Normalization을 진행하였으나, ViT에서는 Encoder만 이용하며, Layer Normalization 이후 Multihead Self-attention과 MLP를 진행한다.
모델의 의의 & 한계
- Vision Task에서 CNN을 이용하지 않고, Transformer 구조를 이용하여 충분한성능을 나타냄
- 학습 과정에서의 자원을 적게 소모하면서, CNN 기반의 모델들과 비교했을 때 좋은 성능을 나타냄
- 데이터셋의 크기가 크지 않은 경우 (중간 사이즈 정도일 경우), 기존 Resnet 대비 좋은 성능을 얻진 못한다는 한계점 존재
- 실제 해당 논문에서도 JFT-300M 데이터셋을 이용하였음.
- 다만, 데이터셋의 사이즈가 큰 경우, 상단의 한계 극복 가능
- 이는 충분한 데이터셋으로 Pretrain 한 뒤, 목표하는 Target에 맞춰 Fine-Tuning을 진행해야 함.

성장 += 지식