Target
- https://arxiv.org/abs/2312.00752
Transformer를 주축으로 이루어진 딥러닝의 아키텍처의 대안을 찾고자 개발자들은 다양한 시도를 진행하고 있음.- 그 중 하나의 대안으로 제시된 아키텍처로 State Space Model 이며, 그 중 해당 글에서 정리한
Mamba가 주목받고 있음.
키워드
- State Space Model
- Selection Mechanism
- Hardware-aware Parallel Scan Algorithm
배경
- 현재 딥러닝의 아키텍처는
Transformer를 주축으로 이용하고 있었음. - 이에 따라 많은 개발자들이
Transformer의 대안을 찾고자 다양한 시도를 진행하고 있음.
기본 개념
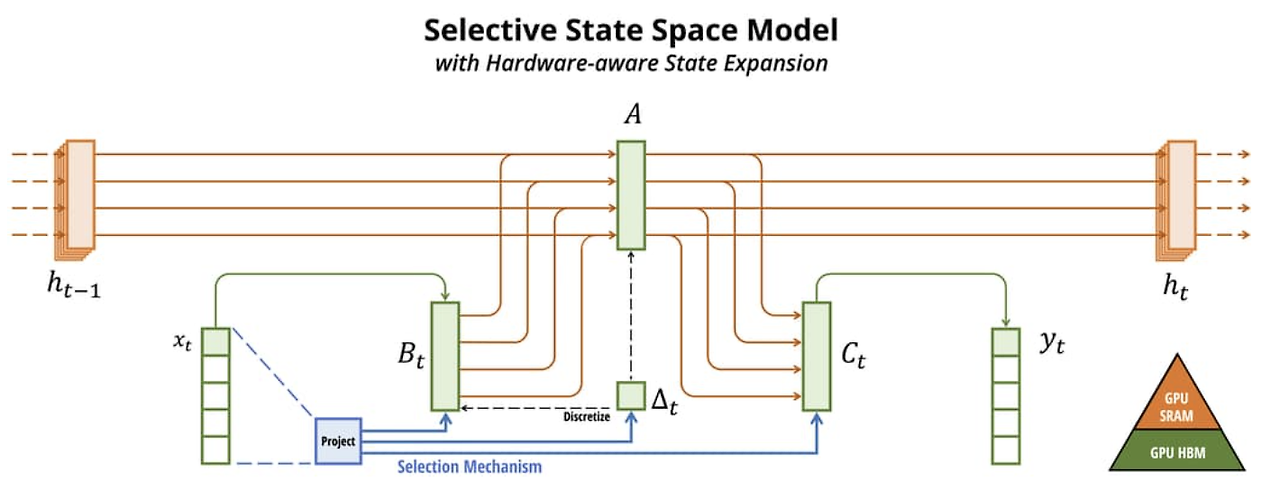
- State Space Model
- 제어이론에서 주로 이용되는 상태 공간 모델 중 하나로, RNN이나 CNN과 같은 고전적인 상태 공간 모델과 관련되어 있음.
- 딥러닝의 경우 사용되는 변수들이 모두 이산형 변수이기에 이산화를 반드시 수행해야 하며, 해당 논문에서는
ZOH (Zero-order Hold) 방식을 채택
- Selection Mechanism
- 기존 모델들은 과도하게 토큰들을 계산 or Context을 과도하게 압축하고 있다고 주장함.
- Mamba에서는 해당 현상을
∆값으로 제어하고자 함.- ∆값이 큰 경우, 해당 토큰에 집중하도록 함.
- ∆값이 작은 경우, 해당 토큰을 건너뛰고, 다음 상태에서 해당 토큰을 많이 포함시키지 않도록 함.
- Why?
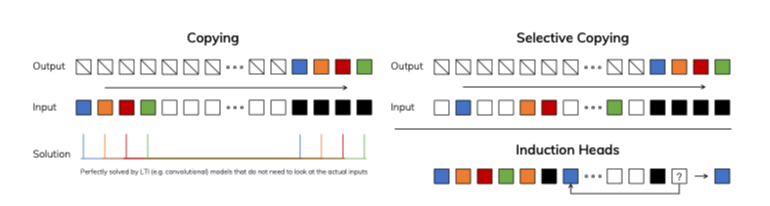
- Large Sequence Modeling의 능력을 평가하기 위해 하단 과정을 진행함.
Selective Copying : 암기할 토큰 위치를 선택적으로 복제해서 맞추는 과정, 암기하는 토큰과 관련서이 떨어지는 부분을 걸러내는 콘텐츠 인식 추론과 연관Induction Heads : LLM의 맥락 내 학습 능력의 대부분을 설명하기 위해 가설화된 과정, 문맥 인식 추론능력이 필요
- Selectivity를 부여함으로써, 각 토큰들을 필요에 맞게 상태로 변환할 수 있도록 함.
- Hardware-aware Parellel Scan Algorithm
- Mamba는 병렬적으로 Scan 알고리즘을 이용하는 알고리즘을 채택
- 모델이 작동하는 하드웨어에 맞춰 작동함.
- GPU 메모리 계층 간의 I/O 접근을 방지하고, 확장된 상태를 실체화하지 않음.
- 결과적으로, 이러한 구현은 이론적으로(시퀀스 길이에 따라 선형적으로 스케일링) 및 현대 하드웨어에서(예: A100 GPU에서 최대 3배 빠름) 이전 방법보다 빠름.
아키텍쳐
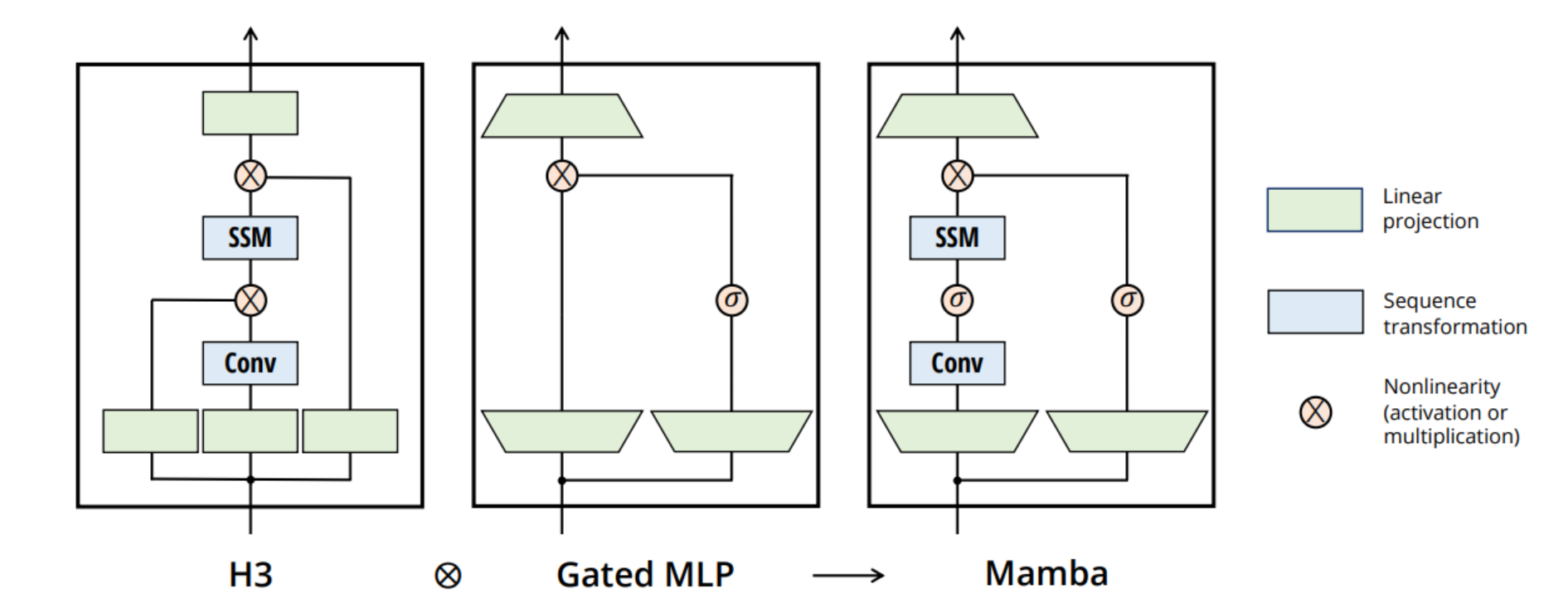
SSM 아키텍처와 Transformer 모델에서 자주 이용되던Gated-MLP블록을 이용- 기존 대비 보다 단순하고 효율적인 아키텍처를 제공함
- σ (활성화 함수)는 Swish (SiLU)를 이용
작은 변화에서는 적게 반응, 큰 변화에서는 크게 반응하는 활성화함수
- 이러한 아키텍쳐 형태
모델의 의의
- 논문 내 성능 비교를 보면, Transformer를 이용하는 모델들과 어느정도 비등한 성능을 나타낸 것을 확인할 수 있음.
- 메모리 소모량이 적고, 효율적으로 이용함.
- Transformer를 이용하지 않고 상당한 성능을 냈다는 점에서 큰 이목을 받을 수 있다고 보여짐.

성장 += 지식