한국어 단어 → 5개(임베딩) ex) ‘김덕배’, ‘메시’, ‘호날두’, ‘안녕’
문장의 개수 → 100개
한 문장의 단어의 개수 → 모두 7개
김덕배 : [1, 0, 0, 0 ,0]
메시 : [0, 1, 0, 0, 0]
호날두 [0, 0, 1, 0, 0]
안녕 [ 0, 0, 0, 1, 0]
김덕배와 메시가 싸운다
딥러닝 엔지니어
hidden vector의 크기 : 7
RNN layer : 1개
단어 임베딩 : 원핫 벡터
tf.keras.layers.SimpleRNN(
units = 7,
input_shape = (3, 5) #time step, input_dim파라미터의 뜻
time_step(seq_length): 문장의 길이만큼 rnn 에서 가져오는 t
input_dim : 하나의 단어의 벡터의 크기 ( [1,0,0,0] → 4 , [0.2 , 0.8] →2 )
units : ht의 크기, weight의 갯수를 구할 수 있어 파라미터 조정이 가능하다

hidden_dim = units (모델핸들링 가능)
예제1)
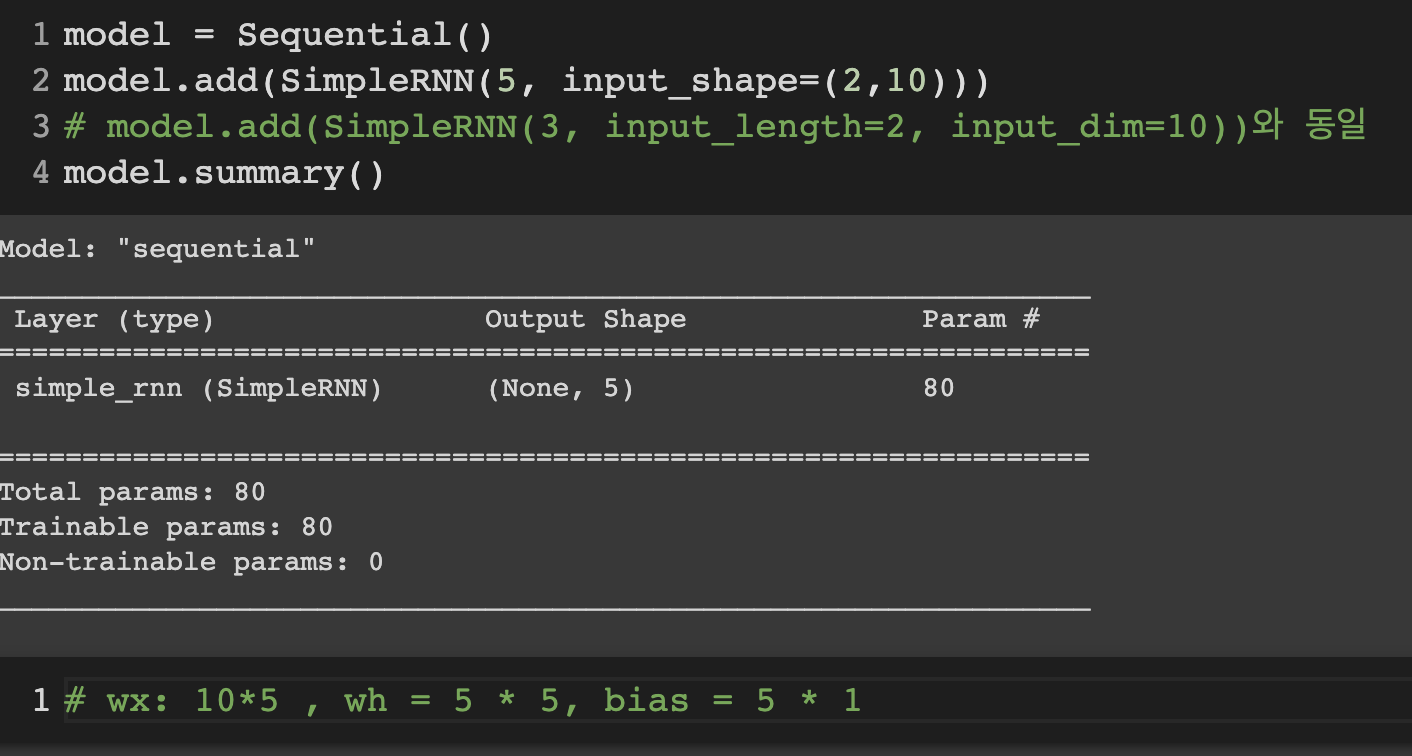
예제2)
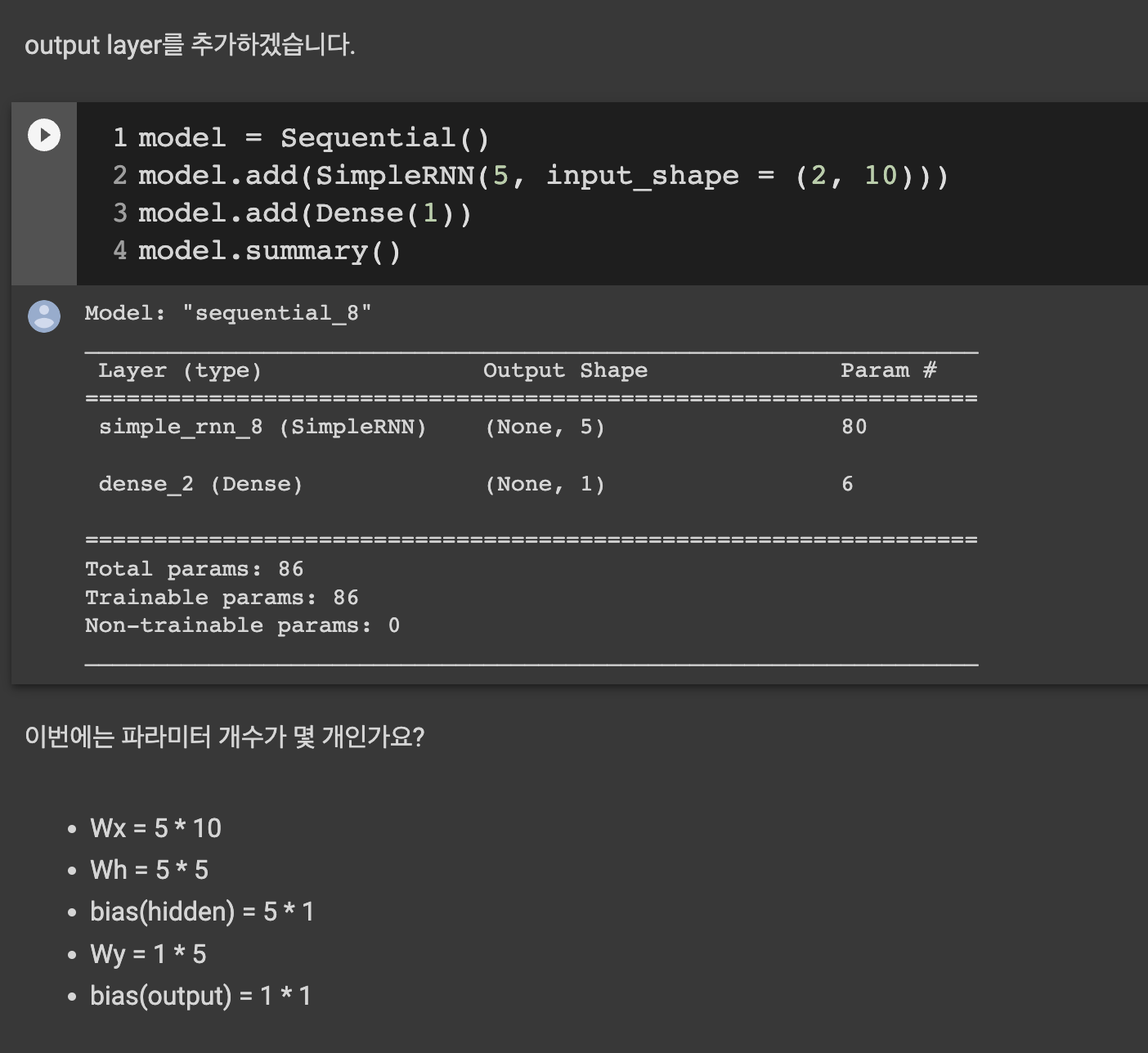
이렇게 Weight 를 세어보면 딥러닝의 치트키같은 이해다.

AI engineer