자연어처리
1.[NLP] 원핫 인코딩(단어의 표현) Word Representation

RED, GREEN, BLUE → Label Encoding (0, 1, 2)→ One-Hot Encodingex) bias 때문에 편견이 생길 수 있다. DATA bias → Model bias단점 : 차원크기의 문제, 의미를 담지 못하는 문제 파이썬 함수 defa
2.[NLP] 자연어처리 임베딩

단어 빈도를 이용하는 방법단어 사전을 미리 구축 → 무작위로 corpus 내에 단어를 꺼내서 라벨을 부여문장 속 단어 빈도를 표시한다장점쉽고 직관적이다 문장을 숫자로 변환단어 빈도를 기반으로 문서 유사도를 파악 할 수 있다.단점단어의 빈도만 고려할 뿐 순서 고려 x세상
3.[NLP] RNN(Recurrent Neural Network)
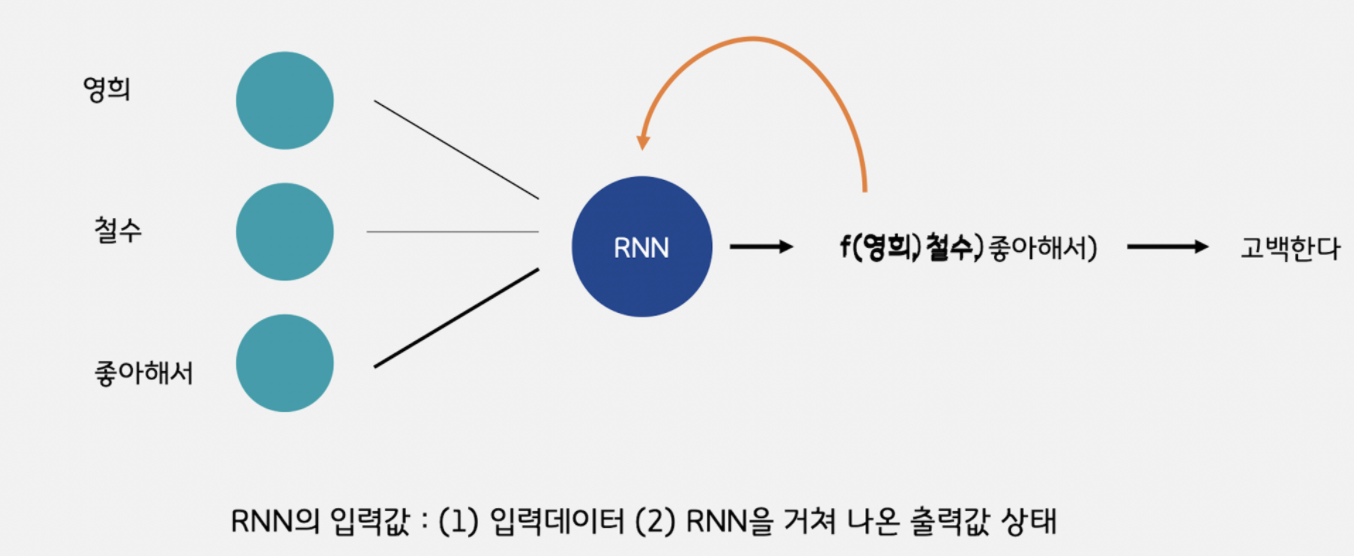
(순환 신경망)순차적으로 넣는다고 해서 RNN 이다.스크린샷 2022-12-19 오후 1.44.06.pngRecurrent Sell (순차적인 데이터 처리)스크린샷 2022-12-19 오후 1.44.14.png시계열에선 시간 , 자연어에서는
4.[NLP] RNN 을 쓰면서 쉽게 이해하는 방법?!

한국어 단어 → 5개(임베딩) ex) ‘김덕배’, ‘메시’, ‘호날두’, ‘안녕’문장의 개수 → 100개한 문장의 단어의 개수 → 모두 7개김덕배 : 1, 0, 0, 0 ,0메시 : 0, 1, 0, 0, 0호날두 0, 0, 1, 0, 0안녕 0, 0, 0, 1, 0
5.[NLP] LSTM(Long Short Term Memory)
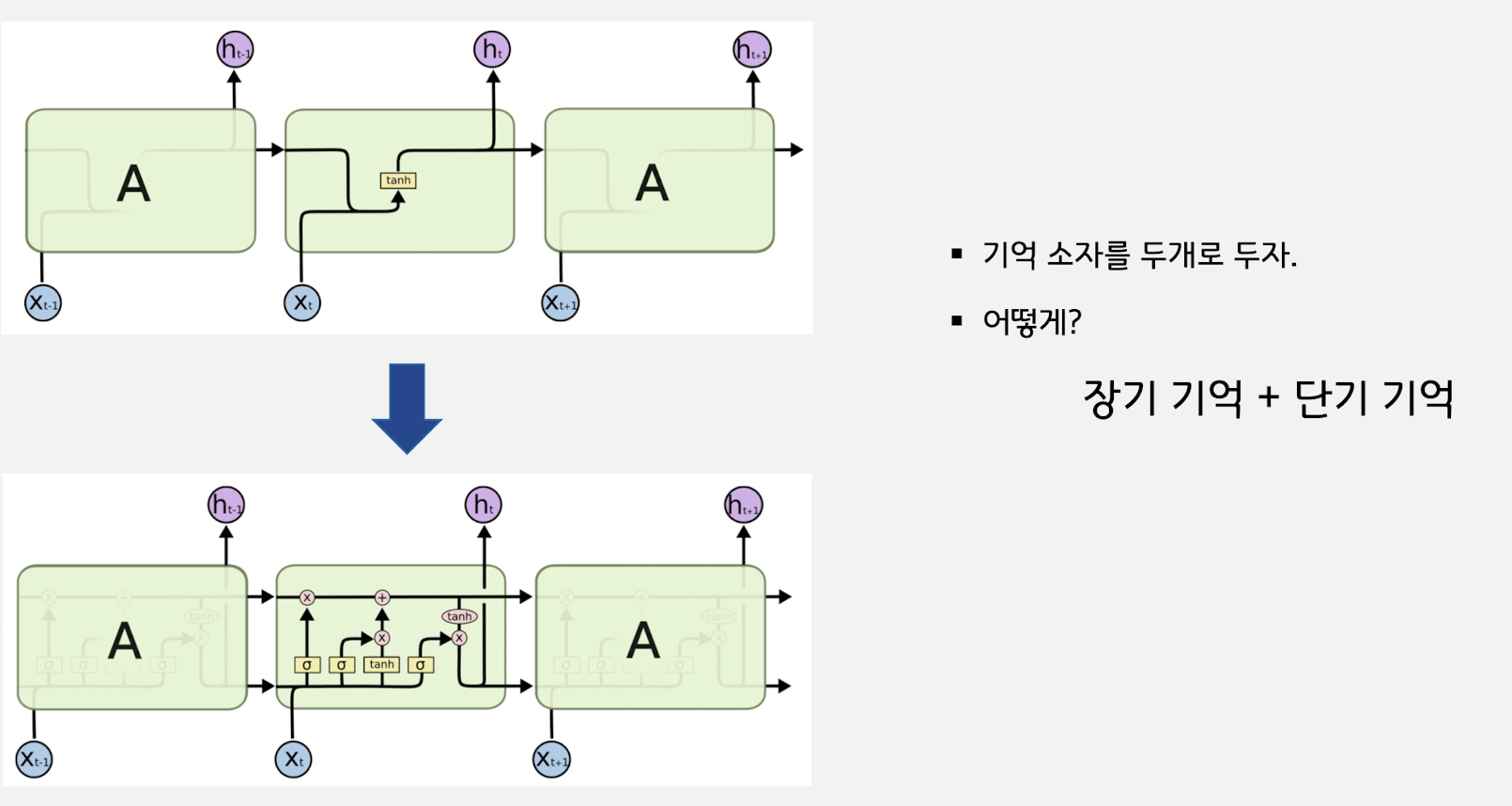
각 시점에 최적화 되어있는 벡터를 두가지를 만든다.\*\* 4개의 웨이트가 나오기 때문에 RNN 웨이트 계산보다 4배나 더 많게 나온다
6.[NLP] GRU, Gated Recurrent Unit
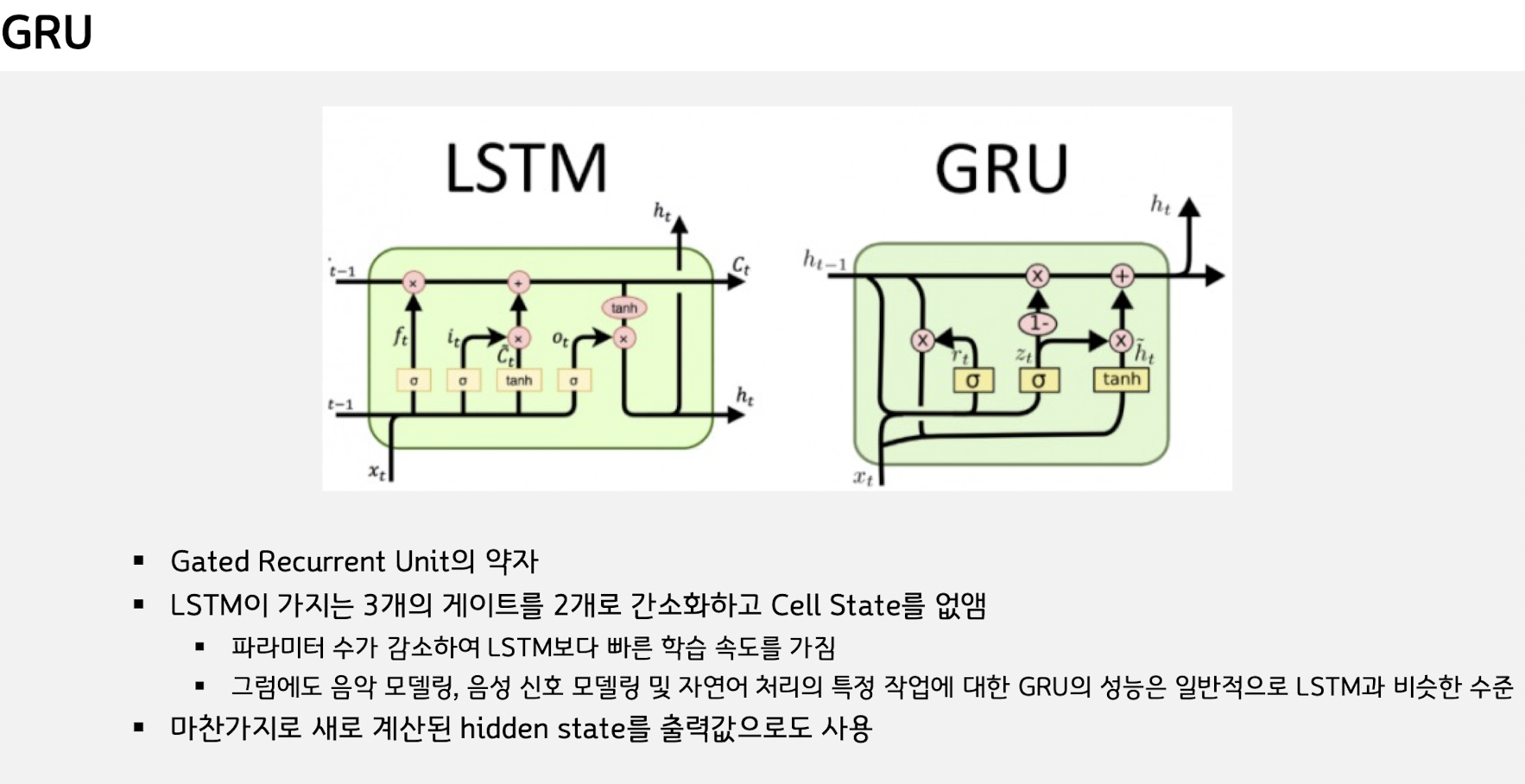
지난 히든스테이트와 이번 시점의 후보스테이트와 비중을 고려해서 ht를 만들었다는게 GRU 의 핵심이다.Weight 갯수가 중간 단계다 Vanlia RNN < GRU < LSTM 웨이트 순이다딥러닝 치트키인 웨이트 구하기로 이해해보자.W_reset : (nu
7.[NLP] transformer 정리
위 리뷰 정리는 유투버 : 나동빈님 영상을 공부하면서 정리 한 글입니다.문제가 될 시 삭제 하겠습니다출처 : 동빈나 youtubehttps://www.youtube.com/watch?v=AA621UofTUA2021년 년 기준으로 현대의 자연어 처리 네트워크에서