🎊 대회결과
PUBLIC 3위

PRIVATE 2위

🎉WINNER 등급 2위로 대회 마감 🎉
💁♂️ 대회소개
💡 이미지 기반 질의응답 AI 모델 개발
- 멀티모달 AI는 서로 다른 유형의 데이터를 결합하여 사용하는 기술로, 텍스트와 이미지 등 다양한 데이터를 종합적으로 다루는 기술입니다.
- 이미지를 텍스트로 변환하는 것은 물론, 텍스트를 기반으로 이미지를 생성하는 등 광범위한 응용분야에서 활용되고 있습니다.
👉 대회일정
👉 대회규칙
📂 데이터설명
Dataset Info.
image [폴더]
- train [폴더] : 107,231개 이미지
- test [폴더] : 11,915개 이미지
train.csv [파일]
- ID : 질문 ID
- image_id : 이미지 ID
- question : 이미지 관련 질문
- answer : 질문에 대한 정답
test.csv [파일]
- ID : 질문 ID
- image_id : 이미지 ID
- question : 이미지 관련 질문
sample_submission.csv [파일] - 제출 양식
- ID : 질문 ID
- answer : 질문에 대한 답변
📄 Code
https://github.com/jh941213/dacon-multimodal-vqa
🏆 대회 전략
Baseline Reference
- 베이스코드만 공부해도 엄청난 도움이 될거라고 생각했다. 비전처리를 한 후 자연어처리로 넘어가는 멀티모달의 과정이기 때문에 베이스라인을 꼼꼼하게 코드리딩을 했던것 같다.
- Resnet50 → EfficientNet 으로 변경
- GPT2 → LLM 모델 으로 변경
BaseLine 근처의 점수를 순회하였다. 또한 LLM 수정 과정에서 많은 에러를 직면하였다.
GIT: A Generative Image-to-text Transformer for Vision and Language
코드 공유에서 참조한 git-base 모델이다. 마이크로소프트 리서치에서 개발한 멀티모달이고 트랜스포머를 활용한 디코더 모델이다.
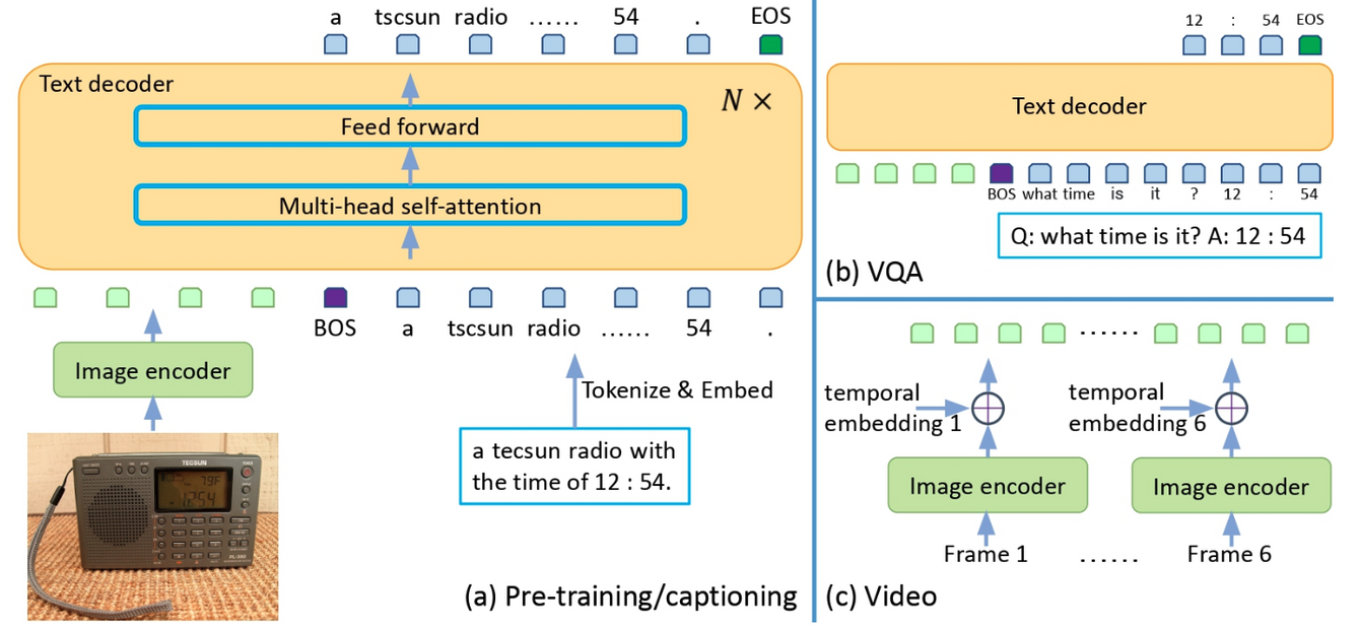
- https://github.com/ddobokki/dacon_vqa 위코드를 참조하여 ipynb 파일로 변경해서 가상환경에서 돌리게끔 코드를 수정
- VQA Dataset 을 관련한 사전학습, 파인튜닝이 불가능했기에 coco dataset을 활용한 git-base-coco 모델을 활용하였다.
- git-large 모델 크기가 큰 모델로 학습을 하였을때 조금이나마 성능이 증가한 모습이었다.
- VATEX 관련데이터셋이 있었지만 무슨이유인지 모르겠으나 모델 학습이 되지 않았다.(추후 디버깅)
- Transform 등을 활용한 전처리를 진행해보았으나 정규화말고는 불필요하다고 판단하였다. 다양한 기법들이 있겠지만 테스트셋도 동일한 이미지 위치의 환경일테고, 각도라던지 컬러관련해서 전처리하는것이 큰 의미가 없을것이라고 판단하였다. → 그래서 좋은 언어모델이 필요하다고 생각하였다.
가장 높은 점수를 기록하였으며 상위권 사람들과 비슷한 점수였다. 그러나 수상권의 점수에는 들지를 못했다.
Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding
Google-Reserch 에서 만든 멀티모달 모델이다. 위 모델도 비교적 최신에 나온 모델이라 모델셀렉션을 하면서 괜찮겠다 생각을 했다.
https://github.com/google-research/pix2struct
- Task 별로 이미 모델자체가 매우 많이 만들어져있었으나 활용가능한 모델이 없었다.
- DocVQA, ChartVQA 를 활용하면 fine-tunning 이 가능하지 않을까 생각
- pix2struct 베이스 모델로 fine-tunning 작업을 선택하였으나 오류가 많이떠서 실패하였다.
결과론적으로 Trainning 에 성공하진 못하였다 시간이 없었기 때문에 deep 하게 코드를 볼 수 없었다.
LLAVA : Large Language and Vision Assistant
CVPR2023 에 소개도되고 ,GPT-4 수준의 기능을 갖춘 대규모 언어 모델
https://github.com/haotian-liu/LLaVA
- LLaMA1을 자연어처리모델로 사용하고 있었고, 현재 LLaMA2 가 나와서 관련하여 업데이트 진행중이었다.
- LLM 의 파라미터 7B, 13B 로 추론이 가능했으나 현실적인 자원문제로 인하여 7B 모델로 학습진행
- Vicuna 7B 를 활용한 학습 진행 → LLaMA2 이전에 Open LLM 리더보드 좋은 점수를 가진 모델이었다. 팔콘 모델이전의 SOTA, LLaMA처럼 KoVicuna 등 다양하게 오픈소스가 활용되는 모델이다.
- LLaVA-Pretrain 데이터셋을 활용하여 LLaVA Lighting 모델을 학습하였고, 앞선 여러모델을 사용해본 결과 비전쪽 처리는 어느정도 성능이 비슷하였기에 자연어처리 언어모델이 중요하다고 생각하였다.
→ Fine-Tunning 을 우리의 데이터셋으로 하였을때 얼마나 비슷하게 추론을 해주냐가 관건이라 생각함
- pyfile 로 구성이 되어있었기에 코드를 리딩하며 수정을 하였다.
1epochs 당 10시간이 걸렸고 , 대회마감까지 2에폭을 학습시켜보며 추론을 할 수 있었다. 그 결과 리더보드 3등 점수에 도달하였고 에폭을 1회 더 학습을 시킨결과 private 점수에서 3등에서 2등으로 추월한 결과가 나오지 않았나 생각한다.
🙇♂️ Positive & Negative
🙆 Positive
- 모델 셀렉션
- 데이터셋에 대한 판단 모델에 맞는 데이터 구성
🙅 Negative
- pyfile 관련 코드 실행 능력
- reference 모델을 끝까지 실행 못한 점
🎥 대회를 마치며
멀티모달은 더욱더 중요해질 것이고, 여러분야에서 쓰일것이라고 생각한다. 하면서도 매우어려운 대회였다. 물론 누가 잘 만들어놓은 모델이 있었기에 학습을 시키는데 어려움은 없었지만, 엔지니어의 역량으로써 멀티모달은 또다른 숙제가아닐까 생각을 했다. 이번에 생각보다 높은 결과를 내어서 만족하지만 더욱 공부해야 될게 많다고 느끼게된 대회였던 것 같다.
