자료구조 / 컬렉션
목표
- 각 자료구조의 특징을 설명할 수 있다.
- 각 자료구조의 탐색/추가/삭제 복잡도를 설명할 수 있다.
- 각 자료구조의 활용 방법을 설명할 수 있다.
- 각 자료구조를 간단하게 구현할 수 있다.
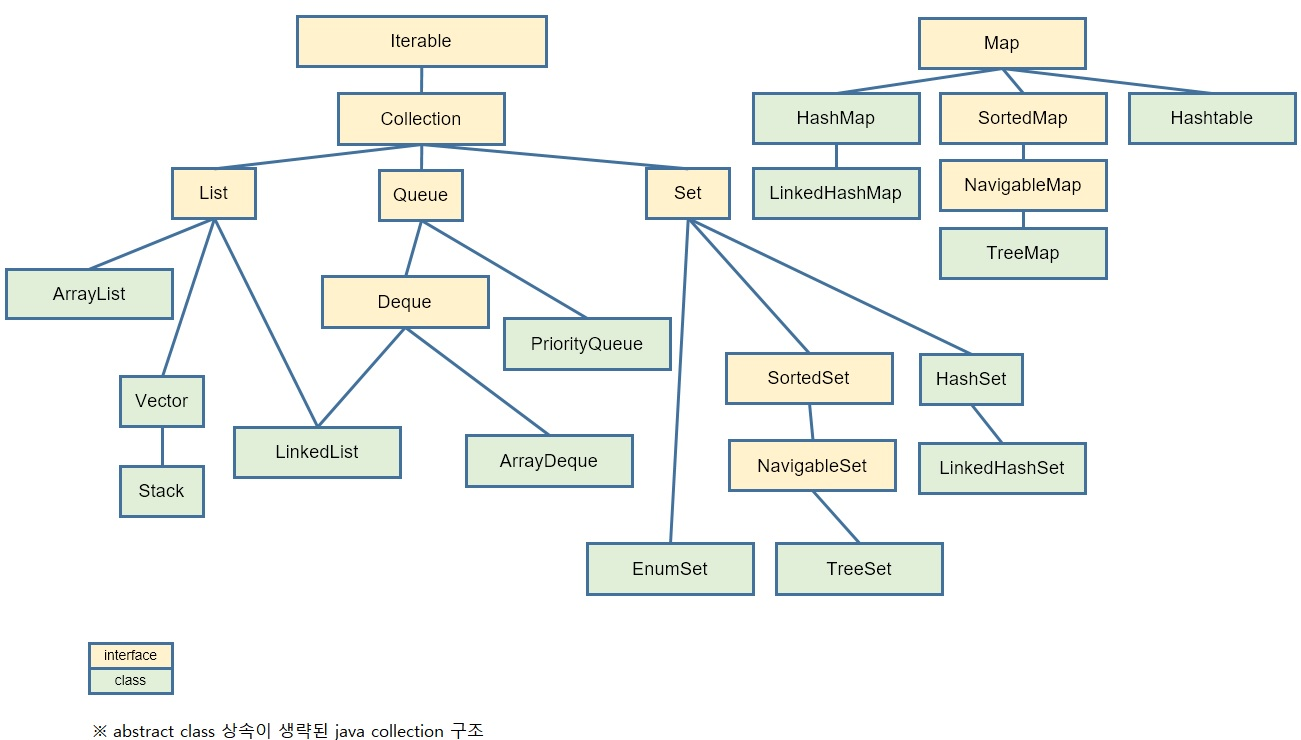
자료구조
개요
- Array
- List
- Set
- Map
- Tree
자료구조 특징 일대일 비교
- Array와 List 차이
Array는 여러 데이터를 하나의 이름으로 관리하기 위한 크기가 고정된 자료구조입니다.
Array는 크기가 고정된 객체를 생성하기 때문에 동적으로 크기를 변경할 수 없습니다.
또한 중간 값을 삭제하더라도 공간이 그대로 남아있습니다.
List는 여러 데이터를 하나의 이름으로 관리하기 위한 동적으로 크기가 변화하는 자료구조입니다.
List는 중간 값을 삭제하면 해당 공간을 다른 값으로 채우거나 삭제합니다.
이 경우에 자바에서는 구현체마다 다르게 작동하는데,
ArrayList의 경우 내부 구현이 Array로 이루어져 있기때문에,
기본적으로 크기 10으로 지정되어 생성이 되지만
크기가 부족해질 경우 1.5배 크기의 배열을 새로 생성하여 기존 값을 복사합니다.
중간 데이터가 삭제되면 중간 데이터 뒤에있는 요소들로 빈 공간을 채웁니다.
LinkedList의 경우 각각의 요소를 노드라는 객체를 생성하여 노드끼리의 연결로 List를 구성합니다.
중간 데이터가 삭제되면 중간 노드의 연결을 끊고 해당 노드 앞 뒤의 노드를 연결하는 방식으로 중간 데이터를 삭제합니다.
Array는
index를 사용한 검색/추가/삭제 모두 O(1)의 복잡도를 가집니다.
왜냐하면 Array는 index를 사용하여 원하는 데이터에 바로 접근할 수 있고
추가/삭제로 인한 다른 작업이 이루어지지 않기 때문입니다.
List 구현체 중에서
* ArrayList는
검색은 O(1)의 복잡도를 가지지만,
중간 데이터 추가/삭제의 경우에는 다른 요소의 이동 작업이 추가적으로 이루어지기 때문에 O(N) 복잡도를 가집니다.
* LinkedList는
검색/추가/삭제의 경우 모두 Node라는 객체를 순차적으로 탐색하는 과정이 필요하기 때문에 O(N) 복잡도를 가진다.
* Vector는 기본적을 ArrayList와 비슷한 구조를 가집니다.
대신 synchronized 키워드르 사용하여 Thrade Safe를 보장한다.- Set과 List의 차이에 대해서 설명해주세요
List와 Set의 가장 큰 차이는 List는 중복을 허용하고, Set은 중복을 허용하지 않습니다.
Set이 중복을 허용하지 않는 방법은 내부적으로 Map을 사용합니다.
HashSet의 경우 내부적으로 HashMap을 사용하고,
각 요소들을 Map의 key 값으로 사용하고 value로 더미 객체를 사용합니다.
Map에서는 이미 존재하는 key를 삽입하는 경우 새로운 객체로 덮어쓰기 때문에
Key에 대해서 중복을 허용하지 않는 구조로 사용할 수 있습니다.
TreeSet의 경우 내부적으로 TreeMap을 사용하고,
TreeMap도 Map에서는 이미 존재하는 key를 삽입하는 경우 새로운 객체로 덮어쓰기 때문에
Key에 대해서 중복을 허용하지 않는 구조로 사용할 수 있습니다.- Map에 대해서 알고있는 모든 것을 설명해주세요
Binary Tree
이진트리란 자식노드가 최대 두 개인 노드들로 구성된 트리입니다. Complete binary tree
이진 트리에서 마지막 레벨을 제외하고 모든 레벨이 완전히 채워져 있는 트리Heap
완전 이진 트리Binary Search Tree
이진탐색트리는 이진트리에서 확장된 트리로써, 빠른 탐색을 위한 다음과 같은 규칙을 갖습니다.
노드 중 하나를 선택하여 현재 노드로 지정합니다.
현재 노드의 왼쪽 자식 트리에는 현재 노드보다 작은 Key를 가지고, 오른쪽 자식 트리에는 현재 노드보다 큰 Key를 가집니다.탐색
이진탐색트리의 규칙을 사용하여,
루트 노드부터 시작하여 찾으려는 key와 노드의 값을 비교하며 일치하는 key 값이 나올때까지 찾습니다.
찾으려는 key 값이 특정 노드의 key보다 작으면 왼쪽 서브 트리에서 이 과정을 반복하고,
특정 노드의 key보다 크다면 오른쪽 서브 트리에서 이 과정을 반복합니다.
최종 리프 노드까지 도달했는데도 해당 key 값이 없다면 해당 이진탐색트리에는 그 값이 존재하지 않습니다.
매 과정마다 두개의 서브 트리 중 하나의 서브 트리를 선택하는 방식이기 때문에 O(logn)의 평균 시간 복잡도를 가집니다.
하지만 이진탐색트리는 불균형하게 트리게 구성되어있을 가능성이 있습니다.
따라서 최악의 경우에는 이진탐색트리가 일자형태로 구성이 될 수도 있기 때문에 O(n)의 시간 복잡도를 가집니다.삽입
이진탐색트리의 탐색과 비슷한 구조를 가집니다.
이진탐색트리의 규칙을 사용하여,
루트 노드부터 시작하여 삽입하려는 key와 노드의 값을 비교하며 일치하는 key 값이 나올때까지 찾습니다.
삽입하려는 key 값이 특정 노드의 key보다 작으면 왼쪽 서브 트리에서 이 과정을 반복하고,
특정 노드의 key보다 크다면 오른쪽 서브 트리에서 이 과정을 반복합니다.
최종 리프 노드까지 도달했는데도 해당 key 값이 없다면,
삽입하려는 key와 리프 노드의 key값을 비교합니다.
삽입하려는 key가 리프 노드의 key보다 작다면 왼쪽 자식으로 삽입하려는 key를 가지는 새로운 노드를 등록합니다.
삽입하려는 key가 리프 노드의 key보다 크다면 오른쪽 자식으로 삽입하려는 key를 가지는 새로운 노드를 등록합니다.삭제
삭제의 경우에는 삽입보다 조금 복잡한 작업이 필요합니다.
삭제하려는 노드가 자식이 없는 경우에는 해당 포인터를 null로 지정하는 방식으로 간단하게 삭제할 수 있습니다.
삭제하려는 노드가 왼쪽 자식만 있는 경우에는 왼쪽 자식 트리의 가장 오른쪽에 위치한 노드로 대체합니다.
삭제하려는 노드가 오른쪽 자식만 있는 경우에는 오른쪽 자식 트리의 가장 왼쪽에 위차한 노드로 대체합니다.
삭제하려는 노드가 양쪽 자식을 모두 가지고 있는 경우에는 오른쪽 자식의 트리의 가장 왼쪽에 위치한 노드로 대체합니다.Balanced Binary Search Tree
일반적인 이진 탐색 트리의 경우 트리 분배가 제대로 이루어지지 않아
탐색 성능이 최악의 경우 O(n)을 이루게 된다.
Balanced Binary Search Tree는 이런 단점을 보완하여
트리의 균형을 유지하여 트리의 높이를 최소화하여 탐색 성능이 저하되는 것을 막기 위한 트리이다.AVL Tree vs Red Black Tree
AVL트리는 더욱 엄격한 균형을 이루고 있기 때문에 Red-Black 트리보다 더 빠른 조회를 제공
Red-Black 트리는 상대적으로 느슨한 균형으로 인해 회전이 거의 이루어지지 않기 때문에 AVL트리보다 빠르게 삽입 및 제거 작업을 수행
AVL트리는 각 노드에 대해 BF를 저장하므로 노드 당 int 저장이 필요
Red-Black 트리는 노드당 1비트의 정보만 필요합니다. (플래그 반전만 시키면 됨)
Red-Black 트리는 맵, C++의 멀티캐스트, Java treeMap 등 대부분의 언어 라이브러리에서 사용,
AVL트리는 더 빠른 검색이 필요한 데이터베이스에서 사용AVL Tree
AVL트리가 나온 이유도 Red-Black 트리와 동일한데 다른 점은 Balnce Factor(BF)를 통해 균형을 맞춘다.
BF는 -1, 0, 1로 이루어져 있으며 이 범위를 벗어난다면 그 트리의 균형은 깨진거다.
왼쪽 서브 트리에서 오른쪽 서브트리를 뺀 값이 그 노드의 BF가 된다.Red Black Tree
레드블랙트리는 이진탐색트리지만, balanced binary search tree로써,
레드블랙트리의 높이는 logn을 넘지 않게 구성되어 search 연산은 O(logn)의 시간복잡도를 가진다.
레드블랙트리에 삽입(insertion)하는경우, Restructuring을 하든, Recoloring을 하든 O(logn)이 걸리게됩니다.
1. 루트 노드는 검정색이다.
2. 모든 External 노드는 검정색이다.
3. 빨강 노드의 자식은 검정색이다. -> 빨강 노드가 연속적으로 나올 수 없다.
4. 모든 리프 노드에서 Black Depth는 같다. -> 리프에서 루트까지 경로에서 검정 노드의 개수는 같다.
5. 삽입되는 모든 노드는 빨강색이다.
Red Black Tree는 HashMap의 Seperate Chaining과 Map의 구현체 중 하나인 TreeMap에서 사용된다.추가 로직
- Red Black Tree - Double Red를 해결하는 전략
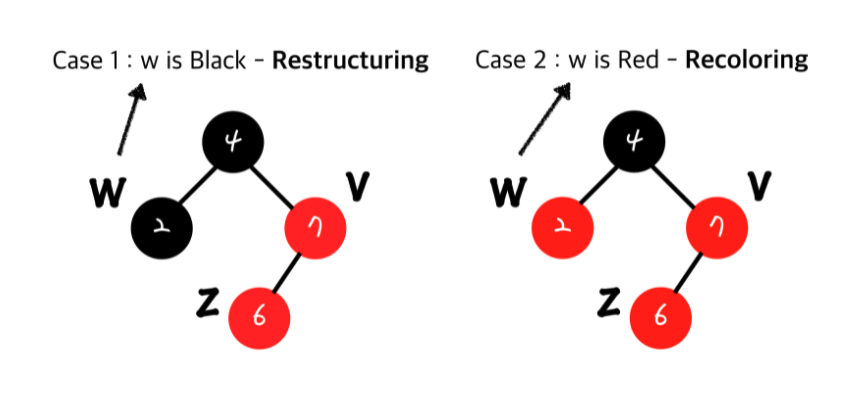
현재 insert된 노드의 uncle node의 색깔에 따라 수행하는 프로시저가 다릅니다.
w가 검정(Black) 일 땐 Restructuring.
w가 빨강(Red)일 땐 Recoloring을 수행하게 됩니다.
Restructuring은 다른 서브트리에 영향을 끼치지 않기 때문에 한번의 Restructuring이면 끝납니다.
Double Red를 해결하기 전과 해결 한 후의 Black 노드의 개수에 변화가 없기 때문에 다른서브트리에 영향을 끼치지 않게 됩니다. - Red Black Tree - Restructing
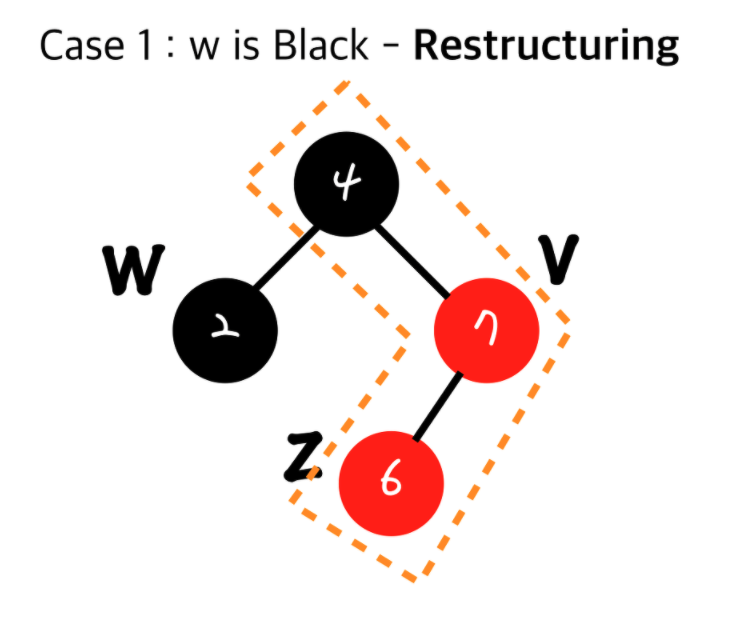

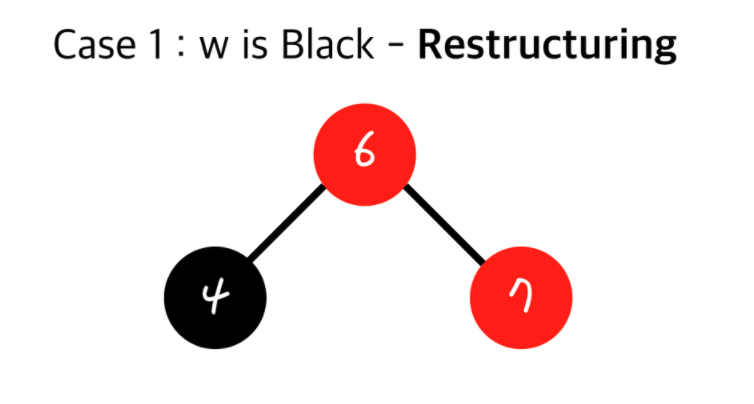
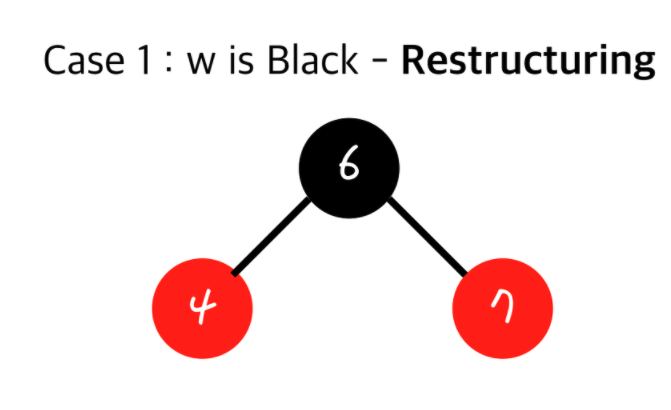
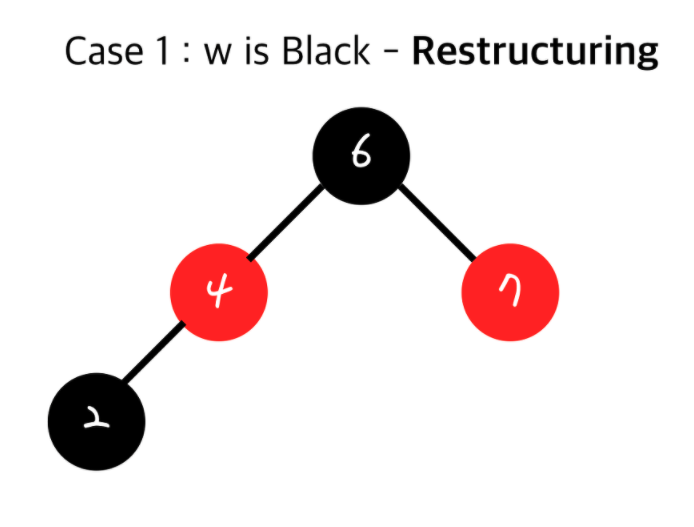
현재 insert된 노드(z)와 내 부모(v)와 내 부모의 부모(Grand Parent)를 가지고 Restructuring을 합니다.
1. 나(z)와 내 부모(v), 내 부모의 부모(Grand Parent)를 오름차순으로 정렬
2. 무조건 가운데 있는 값을 부모로 만들고 나머지 둘을 자식으로 만든다.
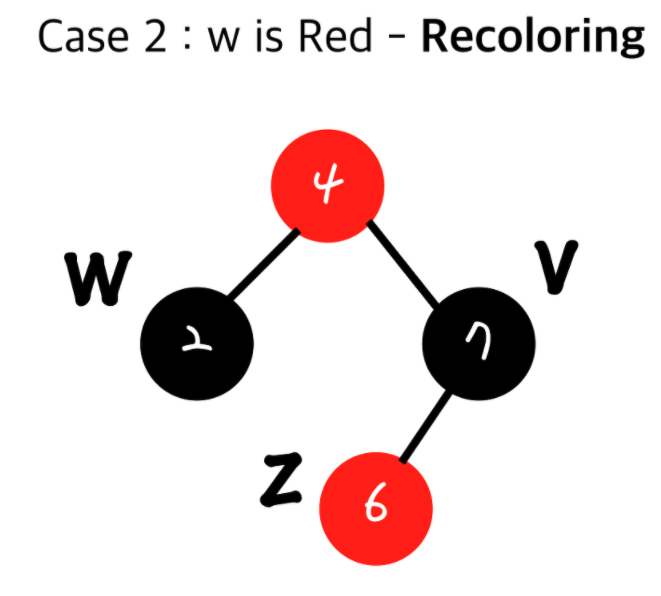
3. 올라간 가운데 있는 값을 검정(Black)으로 만들고 그 두자식들을 빨강(Red)로 만든다. - Red Black Tree - Recoloring
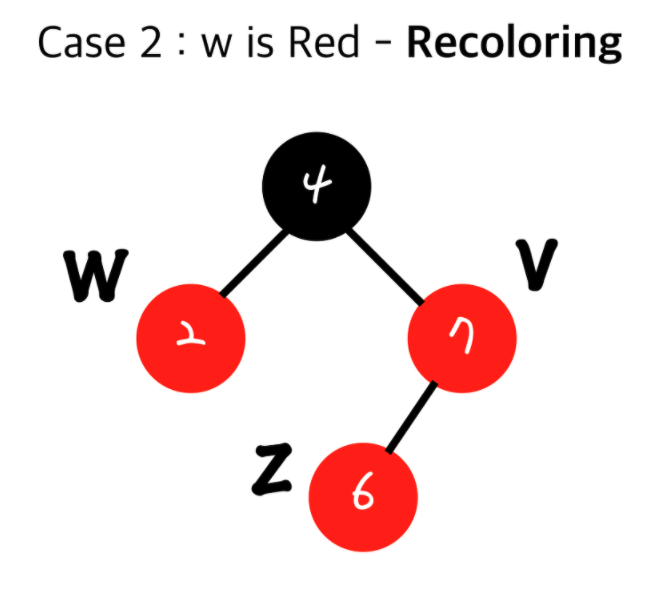
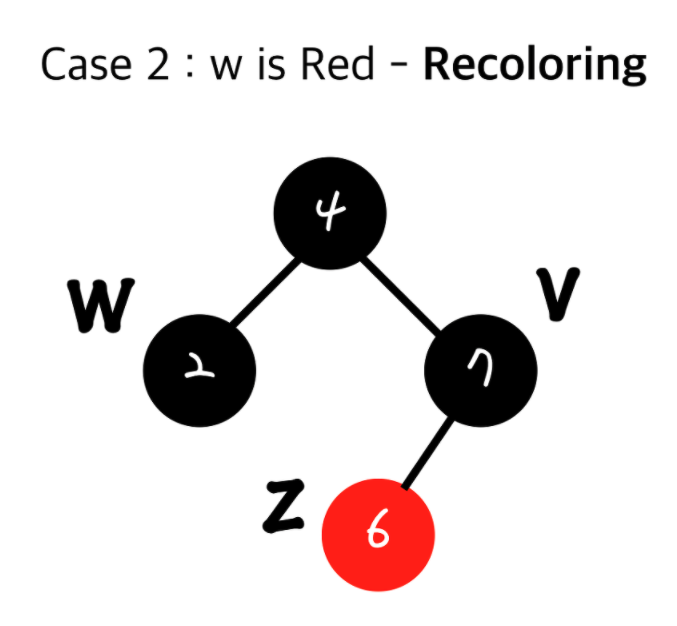
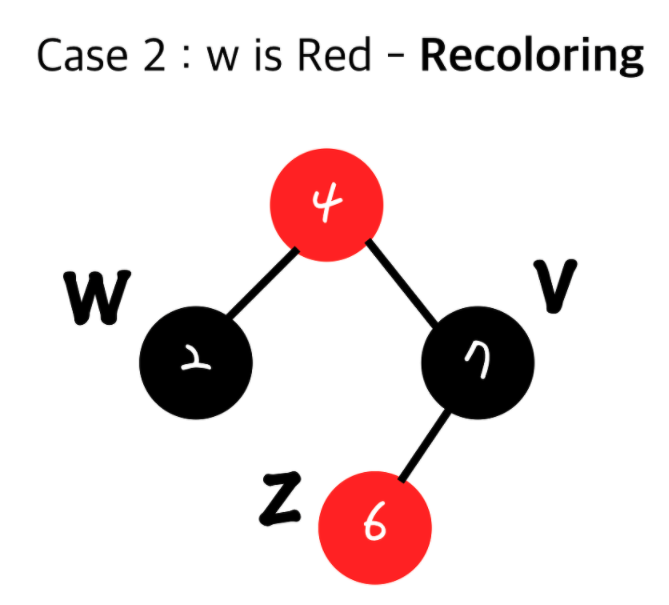
추가 로직 - Grand Parent 노드가 루트 노드일 경우
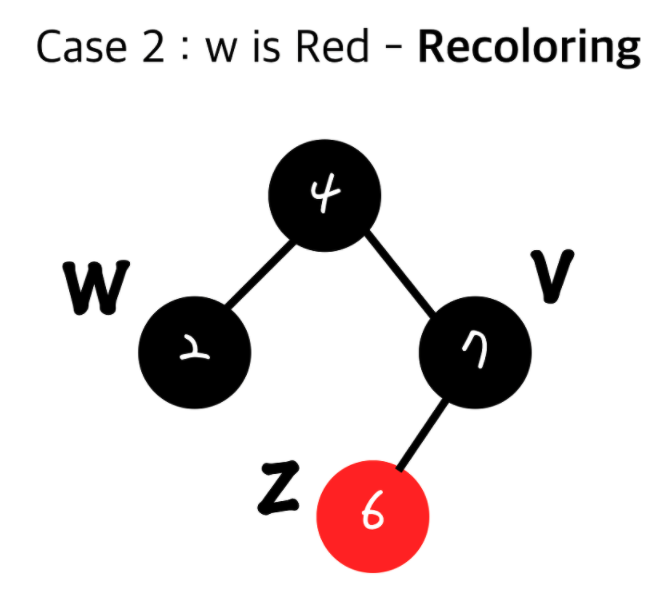
1. 현재 inset된 노드(z)의 부모와 그 형제(w)를 검정(Black)으로 하고 Grand Parent(내 부모의 부모)를 빨강(Red)로 한다.
2. Grand Parent(내 부모의 부모)가 Root node가 아니었을 시 Double Red가 다시 발생 할 수 있다.
그럴 경우 다시 윗 노드끼리 Double Red를 해결하기 위한 과정을 처리해야 합니다.
즉, Recoloring의 경우 Restructuring과 다르게 propagation될 수 있습니다.
최악의경우 Root까지 갈 수 있게되죠.추가 로직 - Grand Parent 노드가 특정 노드의 자식 노드일 경우
삭제 로직
# 삭제하려는 노드가 Red인 경우
* 바로 삭제
# 삭제하려는 노드가 Black인 경우
Red-Black Tree 특성 중 모든 리프노드와 루트 경로의 블랙 노드 개수는 일정해야하기 때문에
이 특성을 유지하게 삭제해야한다.
B Tree
B트리는 이진트리와 다르게 하나의 노드에 많은 수의 정보를 가지고 있을 수 있습니다.
최대 M개의 자식을 가질 수 있는 B트리를 M차 B트리라고 한다.B+ Tree
B+tree는 B-tree의 확장개념으로,
B-tree의 경우, internal 또는 branch 노드에 key와 data를 담을 수 있다.
하지만, B+tree의 경우 브랜치 노드에 key만 담아두고, data는 담지 않는다.
오직 리프 노드에만 key와 data를 저장하고, 리프 노드끼리 Linked list로 연결되어 있다.
장점
1. 리프 노드를 제외하고 데이터를 담아두지 않기 때문에 메모리를 더 확보함으로써 더 많은 key들을 수용할 수 있다.
하나의 노드에 더 많은 key들을 담을 수 있기에 트리의 높이는 더 낮아진다.(cache hit를 높일 수 있음)
2. 풀 스캔 시, B+tree는 리프 노드에 데이터가 모두 있기 때문에 한 번의 선형탐색만 하면 되기 때문에 B-tree에 비해 빠르다.
B-tree의 경우에는 모든 노드를 확인해야 한다. 컬렉션
개요
Array
Array(배열)은 여러 데이터를 하나의 이름으로 관리하기 위한 자료구조로,
index와 value의 쌍으로 그룹핑해서 관리하기 위한 자료구조
특징
- 순서를 유지할 수 있으며 중복 데이터를 허용한다.
- 배열의 크기는 선언 이후에 변경할 수 없다.
- 배열은 index에 따라서 값을 유지하기 때문에 element가 삭제되어도 빈 공간으로 남게 된다.
- 메모리 상에 순차적으로 저장된다.
List
List는 배열이 가지고 있는 index라는 장점을 버리고 빈틈없는 데이터의 적재라는 장점을 취한 자료구조
객체를 저장하면 자동으로 인덱스가 부여되고 인덱스를 통해 데이터의 검색 및 삭제가 가능하다.
대표적인 구현체로는 ArrayList, Vector, LinkedList가 있다.
특징
- 순서를 유지할 수 있으며 중복 데이터를 허용한다.
- 동적으로 크기 변경이 가능하다.
- array와 달리 element를 삭제하면 빈 공간으로 남지 않는다.
- 메모리 상에 순차적으로 저장되지 않아 spacial locality가 보장되자 않는다.
ArrayList
ArrayList는 초기에 설정된 저장용량(capacity)보다 많은 데이터가 들어오면 자동으로 용량이 늘어난다.
기본적으로 10의 저장용량을 갖는다.
기본적으로 데이터를 추가할 때는 인덱스 순으로 자동 저장되고,
중간에 데이터를 추가하거나 삭제하면 인덱스가 한 칸씩 뒤로 밀리거나 당겨진다.
구현
내부적으로 Object 배열을 갖고있고 초기에 설정된 용량 또는 기본값 10으로 배열을 생성한다.
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
private static final long serialVersionUID = 8683452581122892189L;
/**
* Default initial capacity.
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* Shared empty array instance used for empty instances.
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
/**
* Shared empty array instance used for default sized empty instances. We
* distinguish this from EMPTY_ELEMENTDATA to know how much to inflate when
* first element is added.
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer. Any
* empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to DEFAULT_CAPACITY when the first element is added.
*/
transient Object[] elementData; // non-private to simplify nested class access
/**
* The size of the ArrayList (the number of elements it contains).
*
* @serial
*/
private int size;배열의 최대 크기는 Integer의 max 정도이다.
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;초기 선언한 배열보다 더 많은 데이터가 삽입될 때 배열의 크기를 1.5배 증가시킨다.
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}Vector
Vector는 기본적으로 ArrayList와 동일한 구조를 갖는다.
ArrayList와 차이점은 Vector는 자동 동기화를 보장하므로 멀티 스레드 환경에서 사용이 가능하다.
단일 스레드에서는 ArrayList가 성능이 더 좋다.
구현
Vector는 기본적으로 ArrayList와 동일한 구조를 갖는다.
synchronized 키워드를 사용하여 Thread Safe를 보장한다.
public class Vector<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
/**
* The array buffer into which the components of the vector are
* stored. The capacity of the vector is the length of this array buffer,
* and is at least large enough to contain all the vector's elements.
*
* <p>Any array elements following the last element in the Vector are null.
*
* @serial
*/
protected Object[] elementData;
/**
* The number of valid components in this {@code Vector} object.
* Components {@code elementData[0]} through
* {@code elementData[elementCount-1]} are the actual items.
*
* @serial
*/
protected int elementCount;
/**
* The amount by which the capacity of the vector is automatically
* incremented when its size becomes greater than its capacity. If
* the capacity increment is less than or equal to zero, the capacity
* of the vector is doubled each time it needs to grow.
*
* @serial
*/
protected int capacityIncrement;LinkedList
위 컬렉션들은 인덱스로 데이터를 관리하지만 LinkedList는 인접한 곳을 링크하여 체인처럼 관리한다.
LinkedList는 다른 컬렉션과 다르게 중간의 데이터를 삭제할 때 인접한 곳의 링크만 변경하면 되기 때문에 중간에 데이터 추가/삭제의 경우 처리속도가 빠르다.
대신 검색의 경우 인접 링크를 따라가며 찾아야하기 때문에 ArrayList보다 느리다.
구현
Node라는 객체로 연결 리스트를 관리하며, 앞뒤 노드를 멤버변수로 갖고있다.
데이터를 앞에 넣는 경우 first Node를 사용하고,
뒤에 넣는 경우 last Node를 사용한다.
따라서 Queue 컬렉션처럼 사용할 수도 있다.
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
transient int size = 0;
/**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;Queue
- 먼저 들어간 데이터가 먼저 나오는 FIFO 구조
- Queue의 한 쪽 끝은 front로 지정하여 삭제 연산만 수행
- Queue의 다른 한 쪽은 rear로 지정하여 삽입 연산만 수행
- BFS에서 사용
- 컴퓨터 버퍼에서 사용, 입력이 갑작스럽게 많이 들어왔을때 버퍼를 통해 대기시킴
- 구현체로는 LinkedList와 PriorityQueue가 있다.
PriorityQueue
구현
- 내부적으로 배열로 데이터를 관리
- 최소/최대 힙을 사용하여 삽입/삭제를 할 때 마다 rebalancing
public class PriorityQueue<E> extends AbstractQueue<E>
implements java.io.Serializable {
private static final long serialVersionUID = -7720805057305804111L;
private static final int DEFAULT_INITIAL_CAPACITY = 11;
/**
* Priority queue represented as a balanced binary heap: the two
* children of queue[n] are queue[2*n+1] and queue[2*(n+1)]. The
* priority queue is ordered by comparator, or by the elements'
* natural ordering, if comparator is null: For each node n in the
* heap and each descendant d of n, n <= d. The element with the
* lowest value is in queue[0], assuming the queue is nonempty.
*/
transient Object[] queue; // non-private to simplify nested class access
ArrayDeque
Stack
나중에 들어간 데이터가 가장 먼저 나오는 LIFO 구조
DFS나 재귀적 함수 호출에 사용
인터럽트 처리, 서브루틴의 복귀 번지 저장 등에 사용
구현
Vector를 상속받아,
pop -> 가장 마지막 요소 반환
push -> 제일 마지막 요소로 저장
public
class Stack<E> extends Vector<E> {
/**
* Creates an empty Stack.
*/
public Stack() {
}Map
Map은 리스트나 배열처럼 순차적으로 해당 요소 값을 구하는 것이 아니라 key를 통해 value를 얻는다.
구현체로는 HashTable, HashMap, LinkedHashMap, TreeMap이 있다.
HashTable
Hashmap
"키에 대한 해시 값을 사용하여 값을 저장하고 조회하며, 키-값 쌍의 개수에 따라 동적으로 크기가 증가하는 연관 배열"HashMap vs HashTable
HashMap은 보조 해시 함수를 사용하기 때문에 보조 해시 함수를 사용하지 않는 HashTable에 비하여 해시 충돌이 덜 발생할 수 있어 상대으로 성능상 이점이 있다.해시 충돌 해결 방법
Open Addressing은 데이터를 삽입하려는 해시 버킷이 이미 사용 중인 경우 다른 해시 버킷에 해당 데이터를 삽입하는 방식이다.
Separate Chaining에서 각 배열의 인자는 인덱스가 같은 해시 버킷을 연결한 링크드 리스트의 첫 부분(head)이다.
Separate Chaining 방식은 기존에는 무조건 링크드 리스트를 사용하였으나
Java8부터 하나의 버킷에 요소가 특정 개수 이상(8개)되면 TreeMap을 사용한다.
하나의 버킷에 요소가 특정 개수 이하(6개)로 줄어들면 다시 LinkedList를 사용한다.해시 버킷 확장
버킷의 개수가 고정이라면 데이터 증가할수록 해시 충돌 발생이 증가하고 그만큼 데이터 효율이 떨어진다.
따라서 데이터의 수가 해시 버킷 수의 특정 비율을 가지게 되면 2배로 해시 버킷을 증가시킨다.LinkedHashMap
LinkedHashMap 입력된 순서대로 데이터가 출력된다.TreeMap
TreeMap은 입력된 key의 정렬 방식대로 데이터가 출력되는 특징
내부적으로 Red-Black Tree를 사용하여 구현Set
Set은 List와 다르게 데이터를 중복해서 저장할 수 없다.
저장된 객체를 인덱스로 관리하지 않기 때문에 저장 순서가 보장되지 않는다.
Set을 구현하는 대표적인 클래스는 HashSet, TreeSet, LinkedHashSet이 있다.HashSet
데이터를 중복 저장할 수 없고 순서를 보장하지 않는다.구현
내부적으로 HashMap을 갖고 있다.
데이터는 HashMap의 key로 저장한다.
HashMap의 value에 더미 객체를 넣는다.public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
static final long serialVersionUID = -5024744406713321676L;
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();TreeSet
TreeSet은 중복된 데이터를 저장할 수 없고 입력한 순서대로 값을 저장하지 않는다.
대신 TreeSet은 기본적으로 오름차순으로 데이터를 정렬한다.구현
내부적으로 TreeMap을 갖고 있다.
데이터는 TreeMap을 key로 저장한다.
TreeMap을 value에 더미 객체를 넣는다.public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
{
/**
* The backing map.
*/
private transient NavigableMap<E,Object> m;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();LinkedHashSet
HashSet을 상속하며, HashSet 생성자 중 Map을 LinkedHashMap으로 정의하는 생성자를 사용한다.
HashSet과의 차이점은 내부 Map을 HashMap으로 선언했는지, LinkedHashMap으로 선언했는지의 차이다.
데이터는 LinkedHashMap으로 key로 저장한다.
LinkedHashMap value로는 더미 객체를 넣는다.구현
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
private static final long serialVersionUID = -2851667679971038690L;
EnumSet
- EnumSet이 정적팩토리메소드 패턴으로만 생성할 수 있는 이유
기본적으로 EnumSet은 abstract 키워드가 사용되기 때문에 객체로써 생성 및 사용이 불가능합니다.
정적 팩토리 메소드(static factory method)만으로 EnumSet의 구현 객체를 반환받을 수 있습니다.
1. 사용자 편의성 - (사용자는 어떤 구현 객체가 적합한지 몰라도 상관없다)
RegularEnumSet은 원소의 갯수가 적을 때 적합하고, JumboEnumSet은 원소의 갯수가 많을때 적합하지만, 이는 EnumSet의 구현체들을 모두 알고 있는 사용자가 아니라면 난해한 선택지가 될 수도 있습니다. 하지만 EnumSet을 가장 잘 알고 있는 EnumSet 개발자가 적절한 구현 객체를 반환해준다면 EnumSet을 사용하는 입장에서는 어떤 구현체가 적합한지 고려하지 않아도 됩니다.
2. 사용자 편의성2 - (사용자는 빈번하게 발생되는 EnumSet초기화 과정을 간단히 진행할 수 있다.)
EnumSet이 다루는 Enum의 모든 원소들을 Set에 담는 행위는 빈번하게 수행될 것으로 예상되는 일입니다. 이러한 경우를 대비하여서 EnumSet의 allOf라는 메소드를 사용하면 모든 Enum 원소가 담겨있는 EnumSet을 쉽게 반환받고 사용 할 수 있습니다.
3. EnumSet의 확장성과 유지보수의 이점