IoT Core PoC (AWS MSK)
- 1. 문서 목적
- 2. IoT Core) Sensor 데이터 전송 및 동작 테스트
- 3. IoT Core) Rule 설정
- 4. AWS MSK) MSK Connect 설정, mirror
- 5. AWS MSK) MSK Connect 설정, rds
- 6. RDS) DB Info
- 7. Lambda) RDS -> S3 저장 및 오래된 데이터 삭제
- 8. 인프라 정보
문서목적
이 문서는 IoT PoC 환경에서 데이터 처리 동작을 확인하는 과정을 정리하기 위해 작성되었다.
아래와 같은 내용을 다룬다.
- IoT Core) Sensor 데이터 전송 및 동작 테스트
- IoT Core) Rule 설정
- AWS MSK) MSK Connect 설정, mirror
- AWS MSK) MSK Connect 설정, rds
- RDS) DB Info
- Lambda) RDS -> S3 저장 및 오래된 데이터 삭제
IoT Core) Sensor 데이터 전송 및 동작 테스트
데이터 전송/처리/저장 서비스 흐름
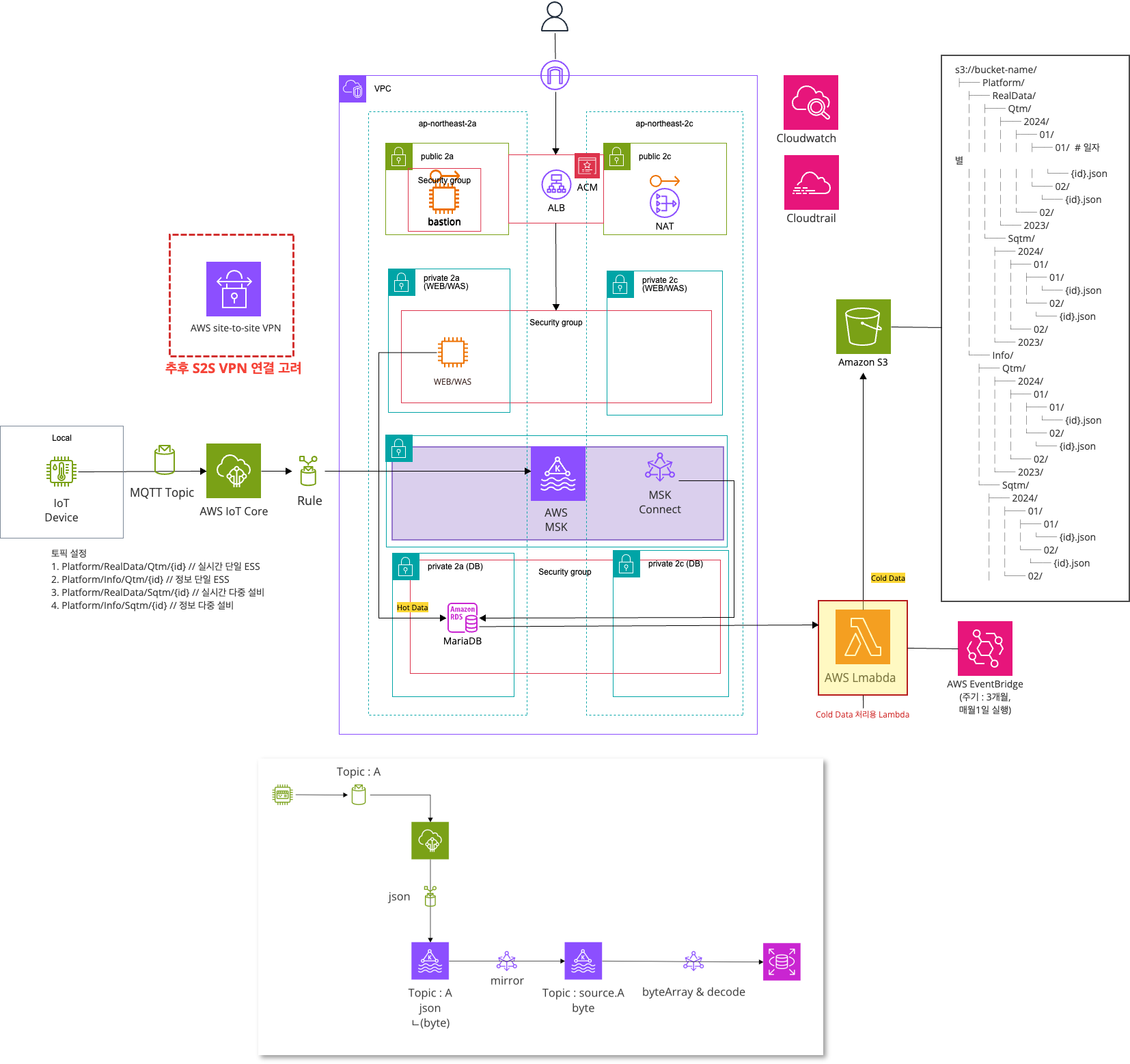
Subscription Topic
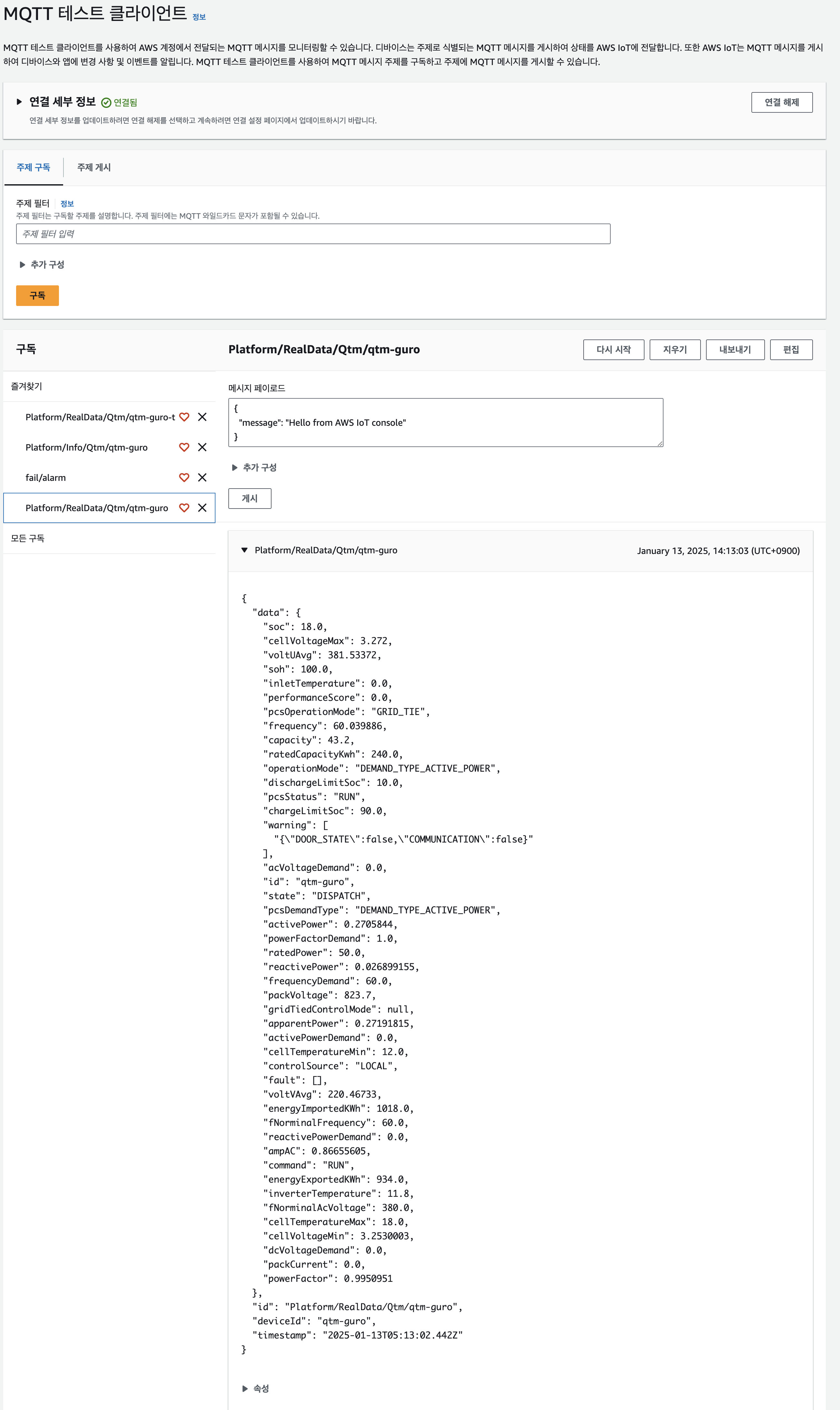
1. Platform/RealData/Qtm/{id} // 실시간 단일 ESS
2. Platform/Info/Qtm/{id} // 정보 단일 ESS
3. Platform/RealData/Sqtm/{id} // 실시간 다중 설비
4. Platform/Info/Sqtm/{id} // 정보 다중 설비Data
- Topic에 들어오는 데이터는 아래 형식을 따른다.
{
"id" : "{Topic name}",
"deviceId" : "{id},
"timestamp" : "{UTC}",
"data" : {
"soc" : float,
"cellVoltageMAx" : float,
...
}
}Topic 확인
AWS IoT -> 테스트 -> MQTT 테스트 클라이언트 -> 주제 구독 -> 주제 필터 -> Platform/RealData/Qtm/qtm-guro 입력 -> 구독
IoT Core) Rule 설정
AWS IoT -> 관리 -> 메시지 라우팅 -> 규칙
SQL
SELECT * FROM '토픽명'
SELECT * FROM 'Platform/RealData/Qtm/qtm-guro'규칙 작업
1. 작업
- Apache Kaka Cluster
- vpc 대상
- vpc-095b9d439021c0fa2 (dots-iot-poc-vpc)
- Kafka 주제
- R-${topic(4)} (RealData-qtm-guro)
- key
- ${deviceId}
2. 클라이언트 속성
- bootstrap.servers
- b-2.dotiotpocmskclust.hz2ndr.c2.kafka.ap-northeast-2.amazonaws.com:9096,b-1.dotiotpocmskclust.hz2ndr.c2.kafka.ap-northeast-2.amazonaws.com:9096
- security.protocol
- SASL_SSL
- SASL Configuration
- sasl.mechanism
- SCRAM-SHA-512
- sasl.scram.username
- ${get_secret('AmazonMSK_dot-iot-poc-msk-cluster', 'SecretString', 'username', 'arn:aws:iam::641345495137:role/dots-IoT-Rule-MSK-Role')}
- sasl.scram.password
- ${get_secret('AmazonMSK_dot-iot-poc-msk-cluster', 'SecretString', 'password', 'arn:aws:iam::641345495137:role/dots-IoT-Rule-MSK-Role')}
- sasl.mechanism
3. 오류작업
- Republish to AWS IoT topic
- 주제
- fail/alarm
- IAM 역할
- dots-iot-poc-fail-rule
- 주제
AWS MSK) MSK Connect 설정, mirror
1. dots-iot-poc-mirror-topic-connector
connector.class=org.apache.kafka.connect.mirror.MirrorSourceConnector
tasks.max=1
# Source cluster configuration
source.cluster.alias=source
source.cluster.bootstrap.servers=b-1.dotiotpocmskclust.v6q85l.c2.kafka.ap-northeast-2.amazonaws.com:9096
source.cluster.security.protocol=SASL_SSL
source.cluster.sasl.mechanism=SCRAM-SHA-512
source.cluster.sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username="dotsenergy" password="!dotsenergy";
# Target cluster configuration
target.cluster.alias=target
target.cluster.bootstrap.servers=b-1.dotiotpocmskclust.v6q85l.c2.kafka.ap-northeast-2.amazonaws.com:9096
target.cluster.security.protocol=SASL_SSL
target.cluster.sasl.mechanism=SCRAM-SHA-512
target.cluster.sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username="dotsenergy" password="!dotsenergy";
# Topic configuration
topics=I-qtm-guro,R-qtm-guro
sync.topic.configs.enabled=false
sync.topic.acls.enabled=false
# Topic Settings (토픽 생성 관련 설정 추가)
config.action.reload=restart
admin.target.replication.factor=1
target.cluster.allow.auto.create.topics=true
# Converter configuration
source.key.converter=org.apache.kafka.connect.storage.StringConverter
source.key.converter.schemas.enable=false
source.value.converter=org.apache.kafka.connect.storage.StringConverter
source.value.converter.schemas.enable=false
target.key.converter=org.apache.kafka.connect.storage.StringConverter
target.key.converter.schemas.enable=false
target.value.converter=org.apache.kafka.connect.storage.StringConverter
target.value.converter.schemas.enable=false
# Topic renaming
replication.policy.class=org.apache.kafka.connect.mirror.DefaultReplicationPolicy
replication.policy.separator=.
auto.create.topics.enable=true
# Replication settings
replication.factor=1설명
1. I(R)-qtm-guro 토픽을 찾습니다.
2. source.I(R)-qtm-guro 토픽을 새로 생성합니다.
3. source.I(R)-qtm-guro 토픽에 I(R)-qtm-guro 토픽 내용을 복사합니다.
복제하는 이유
1. AWS IoT Core에서 MSK로 data가 들어올때 key, value 형태로 들어옵니다.
2. 이때 value는 json(base64(data)) 로, base64인코딩이 된 data를 json이 감싼 형태로 들어옵니다.
3. 복제를 할때, worker에서value.converter=org.apache.kafka.connect.json.JsonConverter옵션을 이용해서 json을 읽고, 커넥터에서value.converter=org.apache.kafka.connect.storage.StringConverter옵션을 이용해서 string 형태로 다시source.I(R)-qtm-guro에 저장합니다.
EC2에서 topic 조회
[ec2-user@ip-10-8-4-84 bin]$ kafka-console-consumer.sh --bootstrap-server b-1.dotiotpocmskclust.v6q85l.c2.kafka.ap-northeast-2.amazonaws.com:9096 --consumer.config client.properties --topic qtm-t --from-beginning
{
"deviceId": "device123",
"id": "event002",
"data": {
"id": "data001",
"soc": 90,
"cellVoltageMax": 3.7,
"voltUAvg": 3.65,
"soh": 95,
"inletTemperature": 25,
"performanceScore": 100,
"pcsOperationMode": "active",
"frequency": 50.5
}
}EC2에서 미러링된 source.topic 조회
[ec2-user@ip-10-8-4-84 bin]$ kafka-console-consumer.sh --bootstrap-server b-1.dotiotpocmskclust.v6q85l.c2.kafka.ap-northeast-2.amazonaws.com:9096 --consumer.config client.properties --topic source.qtm-t --from-beginning
"ewogICJkZXZpY2VJZCI6ICJkZXZpY2UxMjMiLAogICJpZCI6ICJldmVudDAwMiIsCiAgImRhdGEiOiB7CiAgICAiaWQiOiAiZGF0YTAwMSIsCiAgICAic29jIjogOTAsCiAgICAiY2VsbFZvbHRhZ2VNYXgiOiAzLjcsCiAgICAidm9sdFVBdmciOiAzLjY1LAogICAgInNvaCI6IDk1LAogICAgImlubGV0VGVtcGVyYXR1cmUiOiAyNSwKICAgICJwZXJmb3JtYW5jZVNjb3JlIjogMTAwLAogICAgInBjc09wZXJhdGlvbk1vZGUiOiAiYWN0aXZlIiwKICAgICJmcmVxdWVuY3kiOiA1MC41CiAgfQp9"I-sqtm-guro, R-sqtm-guro와 같은 패턴도 포함하려면 다음과 같이 정규식을 수정하려면 아래와 같은 정규식을 사용합니다.
topics.regex=^[IR]-(qtm|sqtm)-guro$이 정규식은:
- ^: 문자열의 시작
- [IR]: 'I' 또는 'R' 중 하나의 문자
- -: 하이픈
- (qtm|sqtm): 'qtm' 또는 'sqtm' 중 하나와 매칭
- -guro: 정확히 이 문자열과 매칭
- $: 문자열의 끝
이렇게 설정하면:
-
매칭되는 예:
- "I-qtm-guro"
- "R-qtm-guro"
- "I-sqtm-guro"
- "R-sqtm-guro"
-
매칭되지 않는 예:
- "source.R-qtm-guro"
- "source.I-sqtm-guro"
- "A-qtm-guro"
- "I-aqtm-guro"
즉, dots-iot-poc-mirror-topic-connector 를 설정할때, 기본 설정은 유지한 채 topics=I-qtm-guro,R-qtm-guro 를 지우고, topics.regex=^[IR]-(qtm|sqtm)-guro$를 넣어주시면 됩니다.
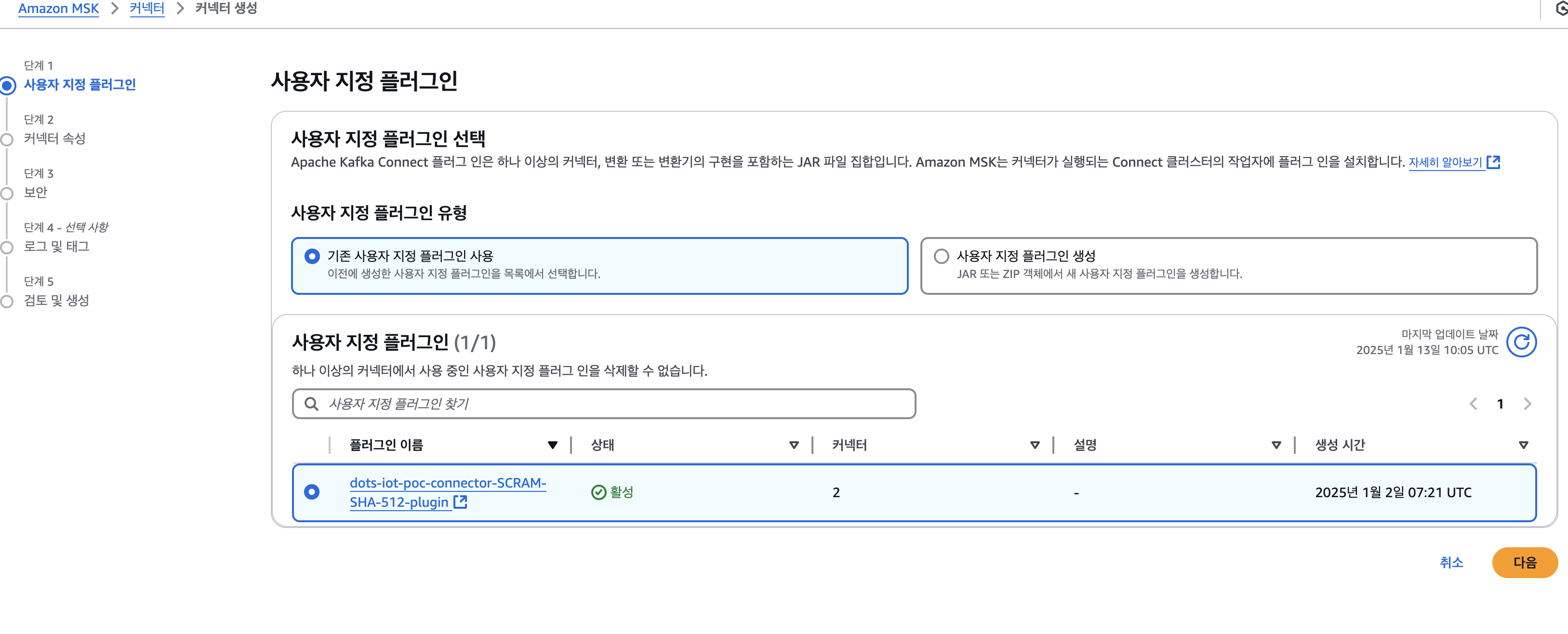
2. 커넥터 생성
2-1. 사용자 지정 플러그인
- dots-iot-poc-connector-SCRAM-SHA-512-plugin 선택
2-2. 인증 -> IAM 선택
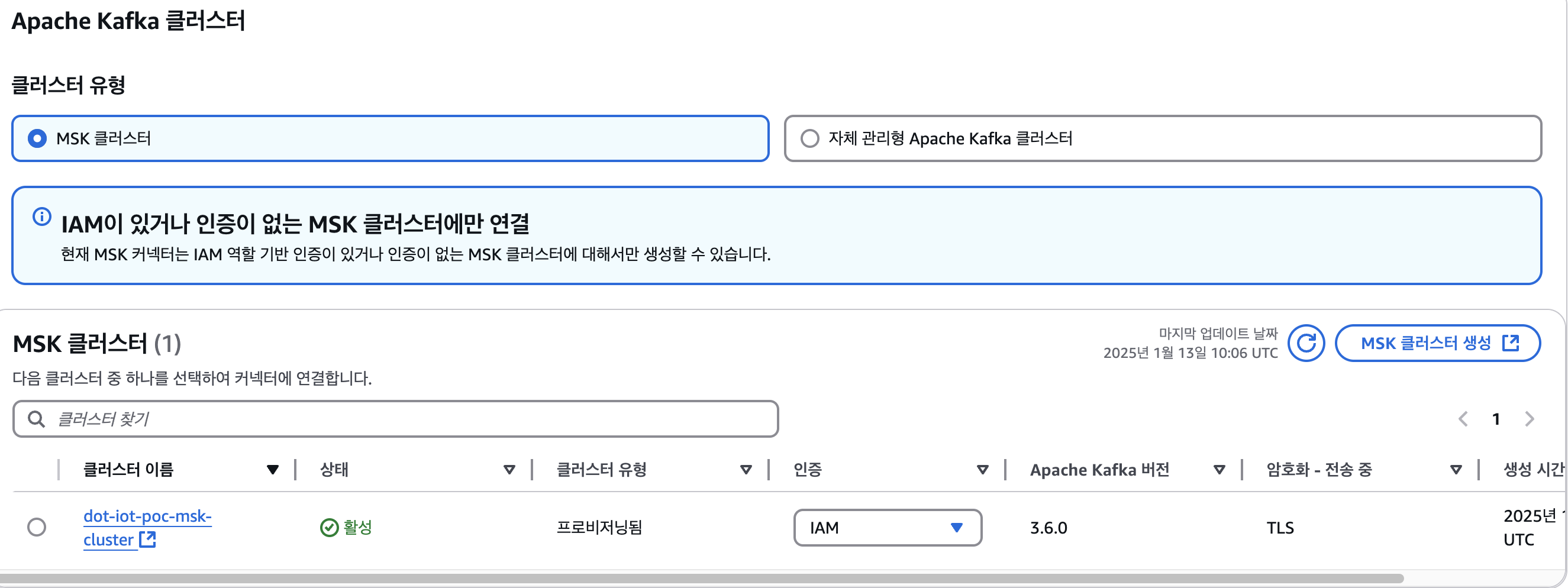
2-3. 구성 설정
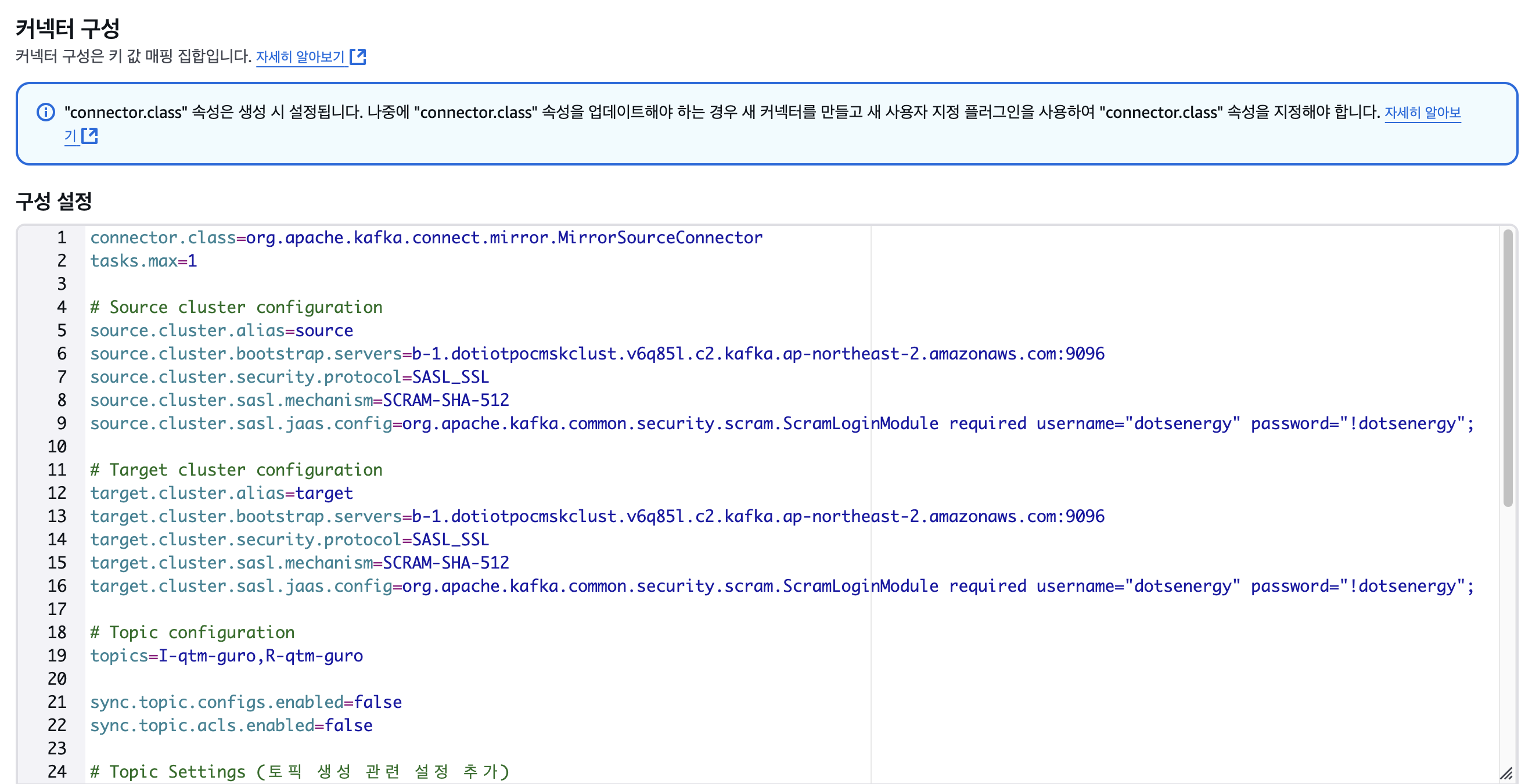
2-4. Apache Kafka Connect 버전
- 3.7.x
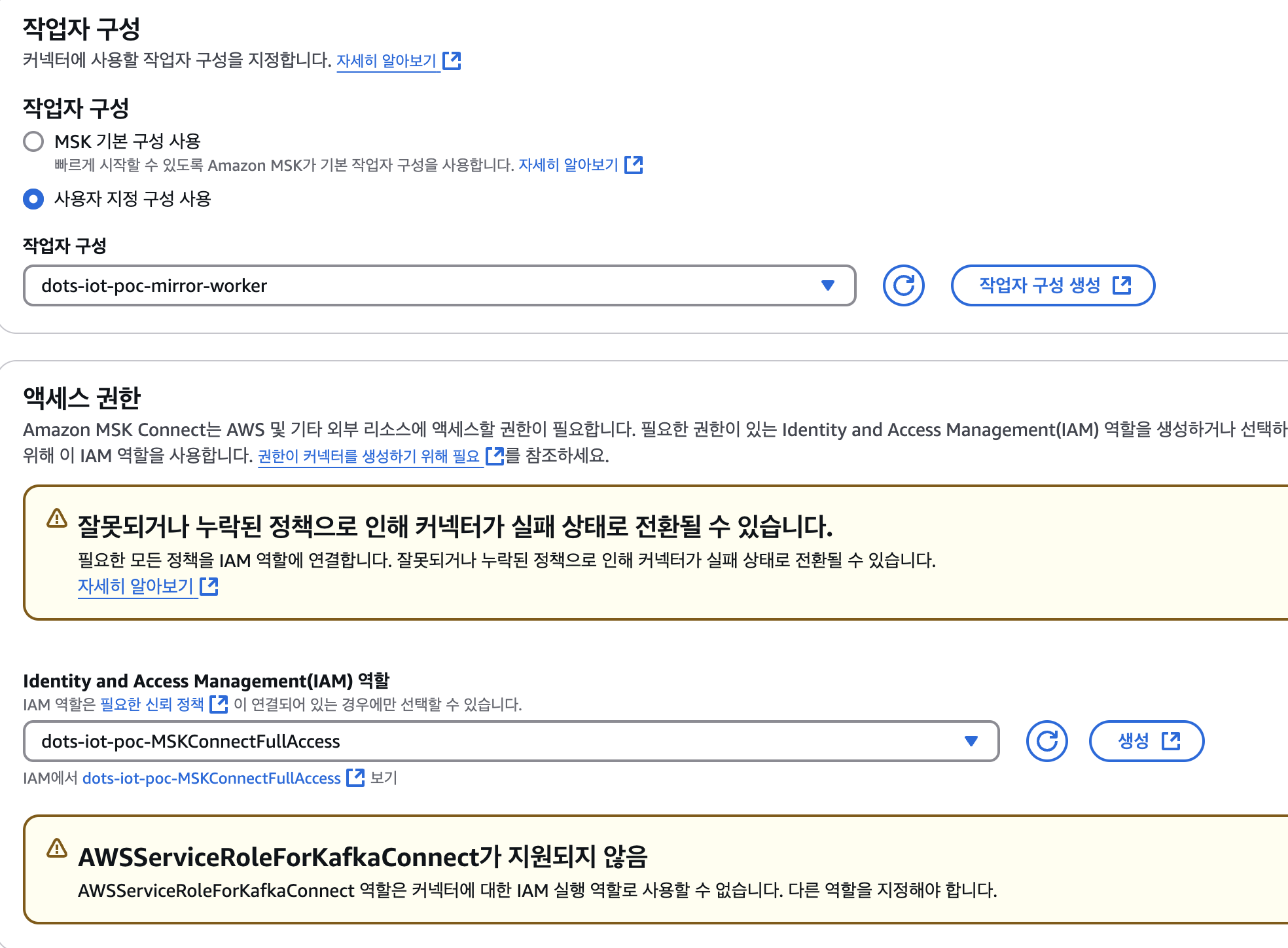
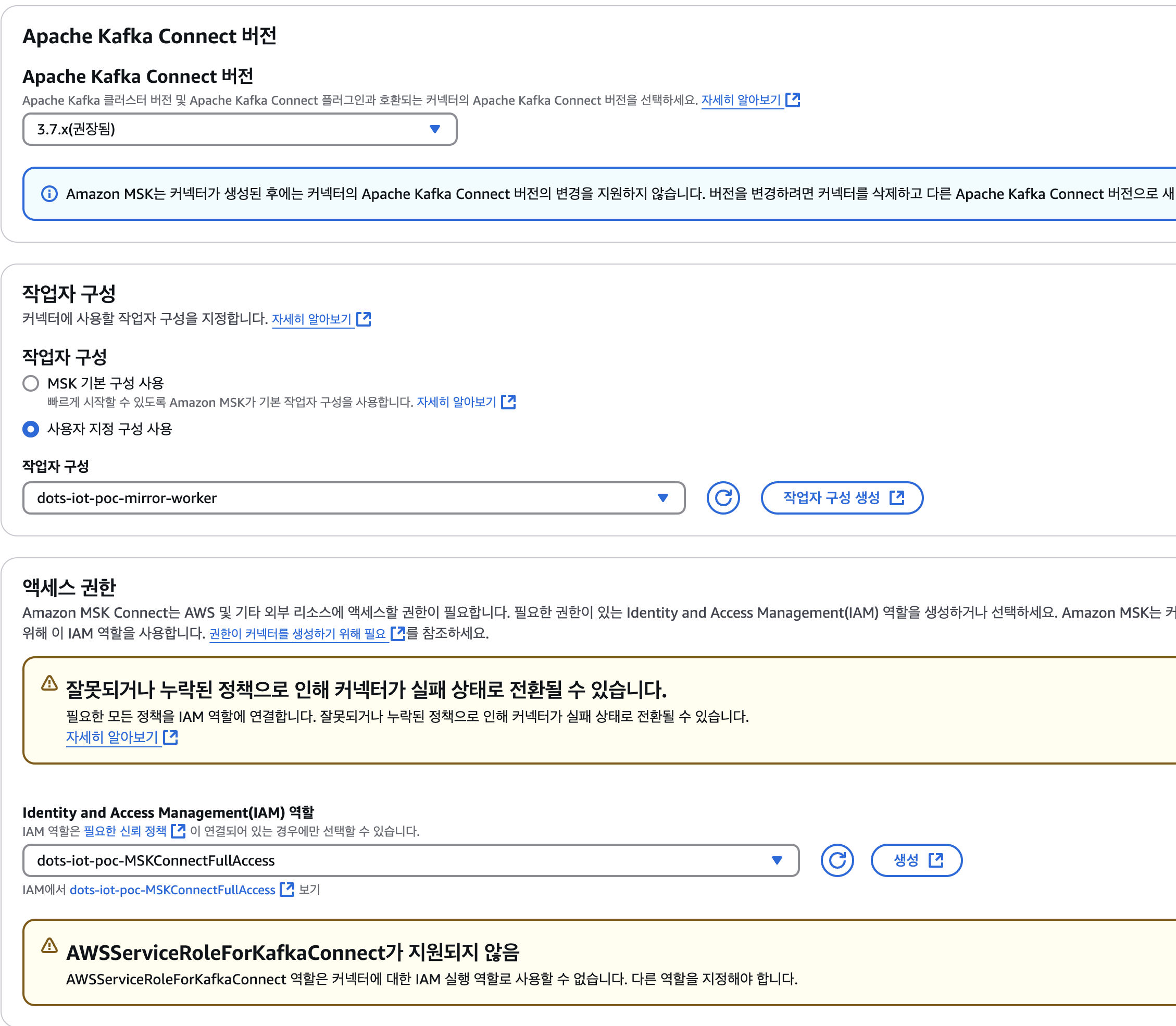
2-5. 작업자 구성 및 엑세스 권한
- 사용자 지정 구성 사용 : dots-iot-poc-mirror-worker
- IAM 역할 : dots-iot-poc-MSKConnectFullAccess
AWS MSK) MSK Connect 설정, rds
1. dots-iot-poc-trans-rds-connector
# Debezium JDBC Sink Connector 클래스 정의
connector.class=io.debezium.connector.jdbc.JdbcSinkConnector
# 오류 로깅 관련 설정
errors.log.include.messages=true
errors.log.enable=true
errors.tolerance=all
errors.retry.timeout=300000
errors.retry.delay.max.ms=60000
# MariaDB 연결 설정
connection.url=jdbc:mariadb://dots-iot-poc-mariadb.csrhj1omj0hp.ap-northeast-2.rds.amazonaws.com:3306/qtm
connection.driver=org.mariadb.jdbc.Driver
connection.username=dotsenergy
connection.password=!dotsenergy
# 토픽 및 테이블 설정
topics=source.I-qtm-guro,source.R-qtm-guro
table.name.format=${topic}
fields.whitelist=id,deviceId,data
auto.create=false
auto.create.topics.enable=true
auto.evolve=false
insert.mode=insert
quote.identifiers=true
# 컨버터 설정
key.converter=org.apache.kafka.connect.storage.StringConverter
key.converter.schemas.enable=false
value.converter=org.apache.kafka.connect.converters.ByteArrayConverter
value.converter.schemas.enable=false
# 트랜스포메이션 설정
transforms=decodeBase64,routeTable
# Base64 디코딩 트랜스포메이션
transforms.decodeBase64.type=com.example.kafka.connect.transforms.Base64DecodingTransformation
# 테이블 라우팅 트랜스포메이션
transforms.routeTable.type=org.apache.kafka.connect.transforms.RegexRouter
transforms.routeTable.regex=source\.(I|R)-(.*)-(.*)
transforms.routeTable.replacement=device_data_$1_$2_$3
# Dead Letter Queue(DLQ) 설정
errors.deadletterqueue.topic.name=qtm-dlq
errors.deadletterqueue.topic.replication.factor=2
errors.deadletterqueue.context.enable=true
errors.deadletterqueue.context.headers.enable=true
errors.deadletterqueue.key.converter=org.apache.kafka.connect.storage.StringConverter
errors.deadletterqueue.key.converter.schemas.enable=false
errors.deadletterqueue.value.converter=org.apache.kafka.connect.json.JsonConverter
errors.deadletterqueue.value.converter.schemas.enable=false
# 태스크 설정
tasks.max=1설명
1.value.converter=org.apache.kafka.connect.converters.ByteArrayConverter로source.I(R)-qtm-guro토픽을 읽습니다.
2.transforms.decodeBase64.type=com.example.kafka.connect.transforms.Base64DecodingTransformation로 데이터를 디코딩 합니다.
3. 디코딩 된 데이터를transforms.routeTable.replacement=device_data_$1_$2_$3형태로 RDS에 저장합니다.
source.I-sqtm-guro, source.R-sqtm-guro와 같은 패턴도 포함하려면 다음과 같이 정규식을 수정하려면 아래와 같은 정규식을 사용합니다.
topics.regex=source.^[IR]-(qtm|sqtm)-guro$2. 커넥터 설정
2-1. 사용자 지정 플러그인
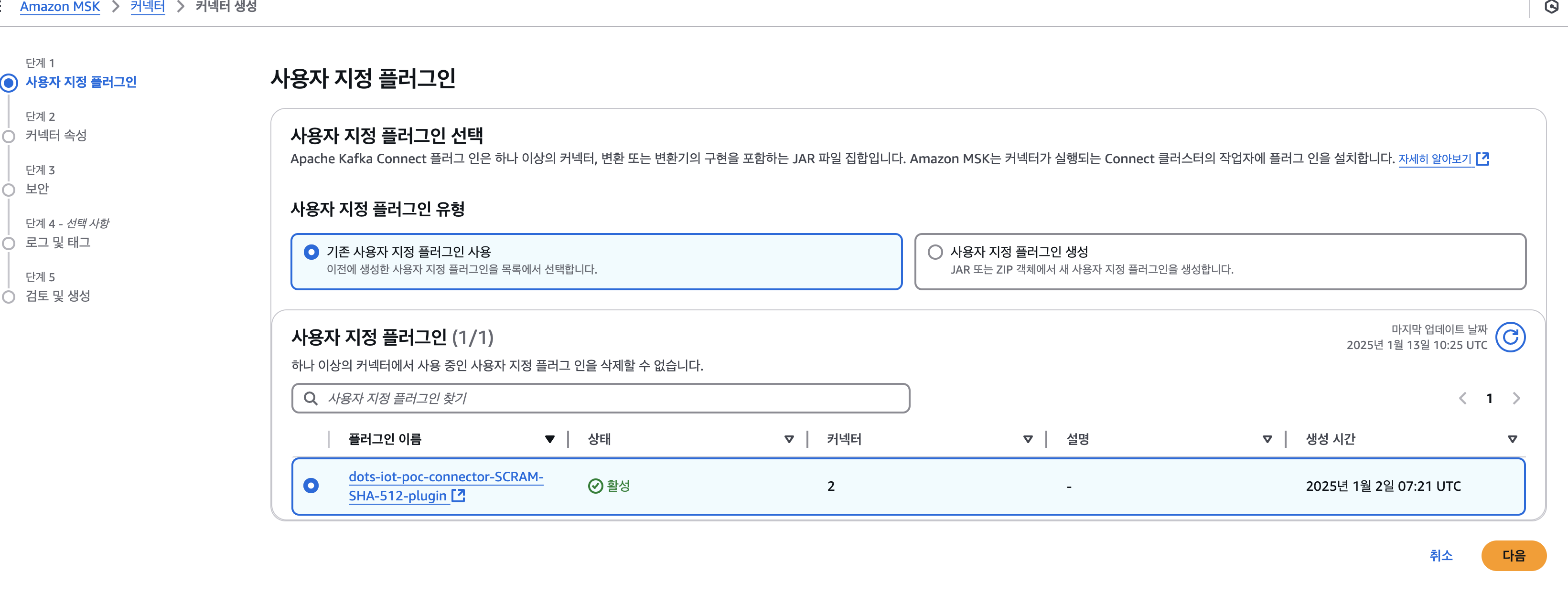
2-2. 인증 -> IAM
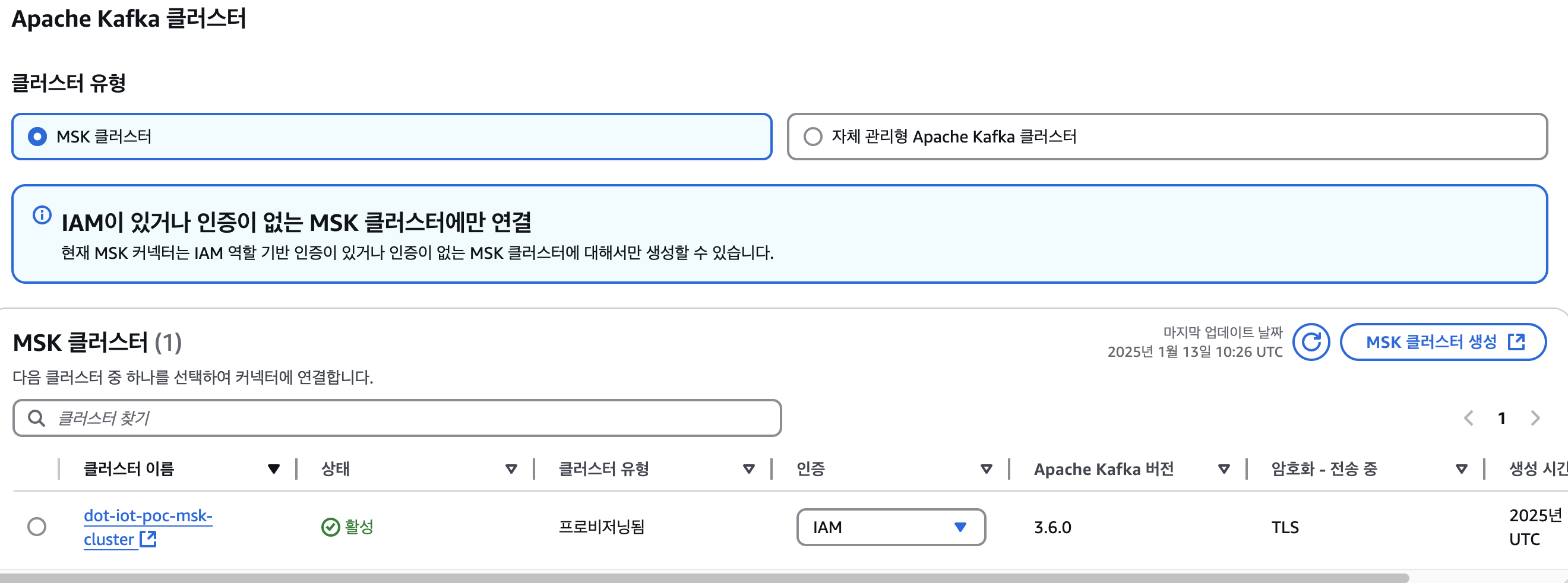
2-3. 커넥터 구성
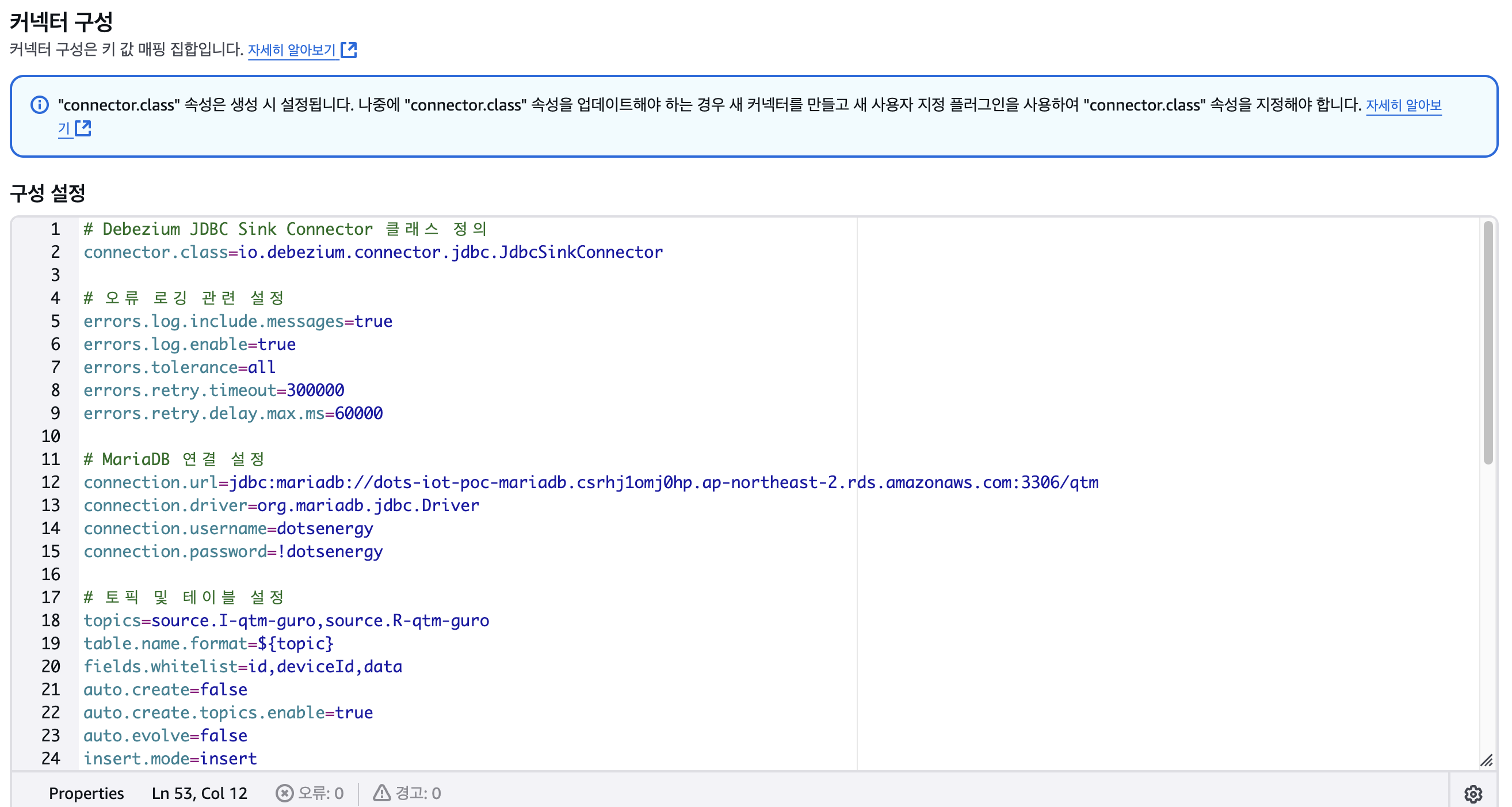
2-4. 버전, 작업자구성, 엑세스 권한
RDS) DB Info
RDS : RDS_MariaDB_10.11.9
username : dotsenergy
password : !dotsenergy
- 테이블 설정
CREATE TABLE t_device_data_11 (
sequence_id BIGINT AUTO_INCREMENT PRIMARY KEY,
id VARCHAR(255) NOT NULL,
deviceId VARCHAR(255) NOT NULL,
data LONGTEXT,
event_timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);1. EC2 -> dots-iot-poc-msk-ec2 (i-05491d8dd8f55f58f) -> 연결
2. EC2 인스턴스 연결 엔드포인트를 사용하여 연결
- 사용자 이름 : ec2-user
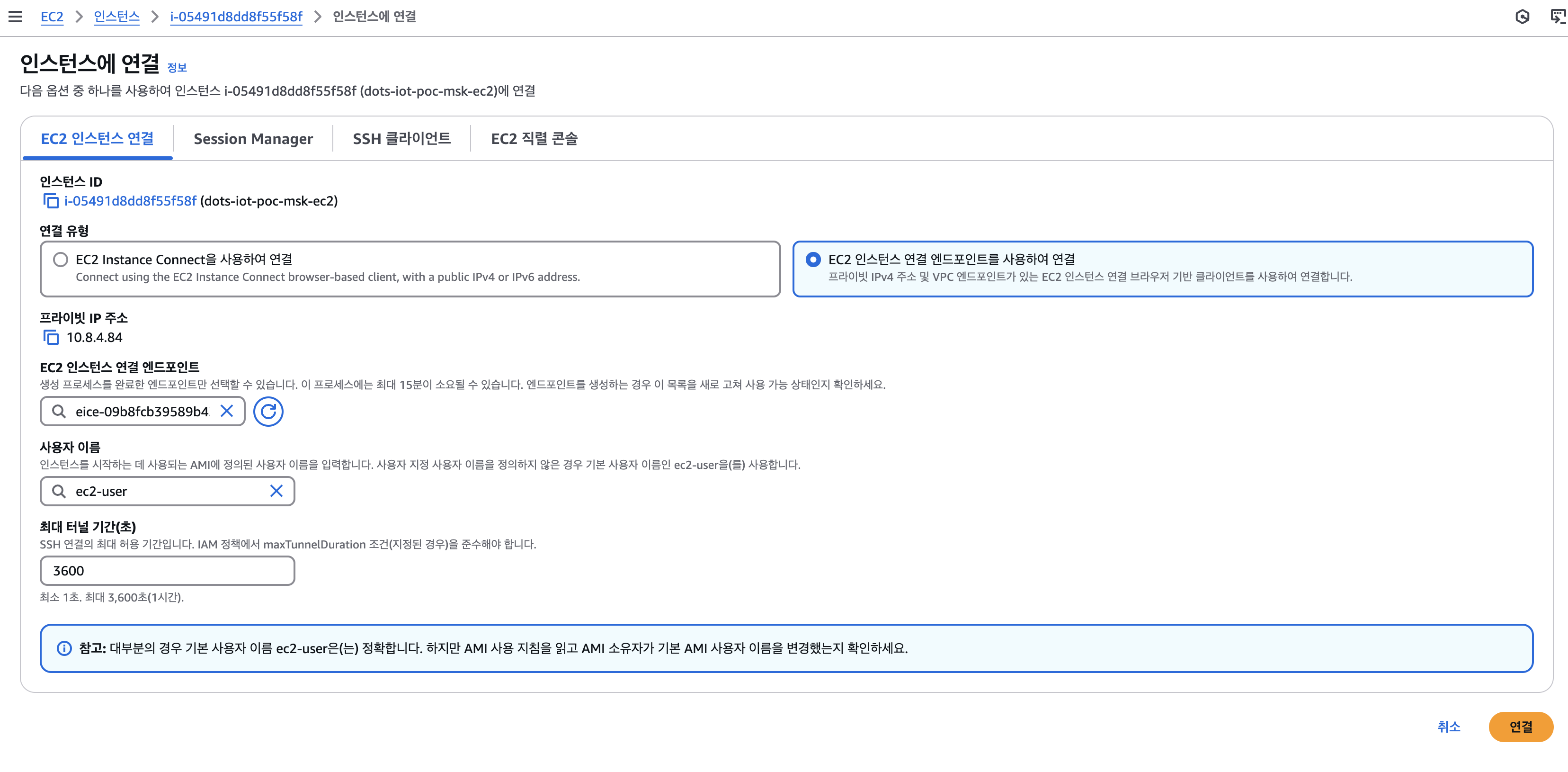
3. rds 접속
//명령어
$ mysql -h dots-iot-poc-mariadb.csrhj1omj0hp.ap-northeast-2.rds.amazonaws.com -u dotsenergy -p
$ show databases;
$ use qtm;
$ show tabels;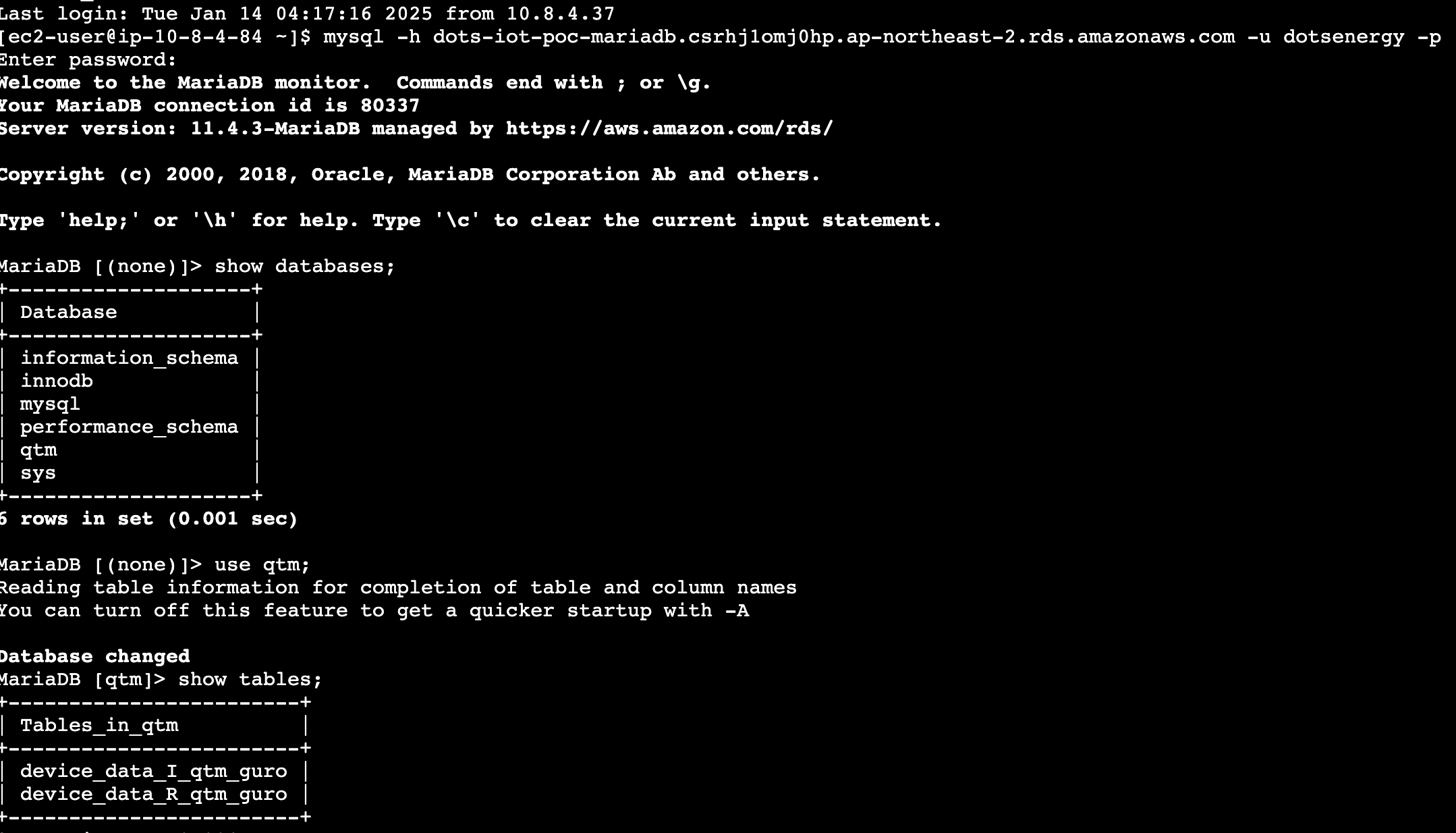
4. 테이블 조회
//테이블의 모든 데이터 조회
$ select * from 테이블이름;테이블에서 data 필드에 있는 JSON 데이터 중 soc 값을 추출하려면 다음과 같은 쿼리를 사용할 수 있습니다
SELECT
JSON_EXTRACT(data, '$.data.soc') AS soc_value
FROM
device_data_I_qtm_guro;만약 soc 값을 필터링하거나 특정 조건에 따라 검색하려면, WHERE 절을 사용할 수 있습니다. 예를 들어, soc 값이 20보다 큰 경우:
SELECT
JSON_EXTRACT(data, '$.data.soc') AS soc_value
FROM
device_data_I_qtm_guro
WHERE
JSON_EXTRACT(data, '$.data.soc') > 20;가장 최근 날짜의 1개 데이터 조회
SELECT
JSON_EXTRACT(data, '$.data.soc') AS soc_value,
created_at
FROM
device_data_ㄲ_qtm_guro
ORDER BY
created_at DESC;

Lambda) RDS -> S3 저장 및 오래된 데이터 삭제
- trigger : 30일마다
- action : rds안에 현재 날짜 기준 30일 이전의 데이터는 s3에 적제하고, 삭제한다.
import boto3
import pymysql
import json
from datetime import datetime, timedelta
import re
def lambda_handler(event, context):
print(f"Lambda function started at {datetime.now().isoformat()}")
# DB 연결 정보
rds_host = "dots-iot-poc-mariadb.csrhj1omj0hp.ap-northeast-2.rds.amazonaws.com"
db_name = "qtm"
user = "dotsenergy"
password = "!dotsenergy"
print(f"Connecting to database: {db_name} at {rds_host}")
# S3 클라이언트 초기화
s3 = boto3.client('s3')
bucket_name = 'dots-iot-poc-s3'
print(f"Initialized S3 client for bucket: {bucket_name}")
total_processed = 0
total_errors = 0
try:
# DB 연결
conn = pymysql.connect(
host=rds_host,
user=user,
passwd=password,
db=db_name,
connect_timeout=5
)
print("Successfully connected to database")
# 테이블 목록
tables = ['device_data_I_qtm_guro', 'device_data_R_qtm_guro']
with conn.cursor() as cursor:
for table in tables:
print(f"\n--- Processing table: {table} ---")
# 10분 이전 데이터 조회
query = f"""
SELECT sequence_id, id, deviceId, data, timestamp
FROM {table}
WHERE timestamp < DATE_SUB(NOW(), INTERVAL 10 MINUTE)
"""
print(f"Executing query: {query}")
cursor.execute(query)
old_records = cursor.fetchall()
print(f"Found {len(old_records)} records older than 10 minutes in {table}")
# 데이터 처리
for record in old_records:
sequence_id, device_id, device_name, data_str, timestamp = record
print(f"\nProcessing record: sequence_id={sequence_id}, timestamp={timestamp}")
try:
# JSON 데이터 파싱
print(f"Parsing JSON data for sequence_id {sequence_id}")
data = json.loads(data_str) if data_str else {}
# 원본 id에서 경로 추출
original_id = data.get('id', device_id)
print(f"Original ID path: {original_id}")
# 타임스탬프를 이용한 경로 생성
year = timestamp.strftime('%Y')
month = timestamp.strftime('%m')
day = timestamp.strftime('%d')
hour = timestamp.strftime('%H')
# S3 경로 생성
file_name = f"{device_name}_{timestamp.strftime('%Y%m%d%H%M%S')}_{sequence_id}.json"
s3_key = f"{original_id}/{year}/{month}/{day}/{hour}/{file_name}"
print(f"Generated S3 key: {s3_key}")
# JSON 데이터 준비
json_data = {
"id": device_id,
"deviceId": device_name,
"timestamp": timestamp.isoformat(),
"data": data
}
print(f"Uploading to S3: bucket={bucket_name}, key={s3_key}")
# S3에 데이터 업로드
s3.put_object(
Bucket=bucket_name,
Key=s3_key,
Body=json.dumps(json_data, indent=2),
ContentType='application/json'
)
print(f"Successfully uploaded to S3")
# 업로드 성공한 레코드 삭제
delete_query = f"DELETE FROM {table} WHERE sequence_id = %s"
print(f"Executing delete query: {delete_query} with sequence_id={sequence_id}")
cursor.execute(delete_query, (sequence_id,))
print(f"Successfully deleted record from database")
total_processed += 1
except Exception as e:
print(f"Error processing record {sequence_id}: {str(e)}")
total_errors += 1
continue
# 변경사항 커밋
conn.commit()
print(f"Committed changes for table {table}")
print(f"\n--- Summary ---")
print(f"Total records processed: {total_processed}")
print(f"Total errors encountered: {total_errors}")
return {
'statusCode': 200,
'body': json.dumps({
'message': 'Successfully processed records older than 10 minutes',
'total_processed': total_processed,
'total_errors': total_errors,
'timestamp': datetime.now().isoformat()
})
}
except Exception as e:
error_msg = f"Database error: {str(e)}"
print(error_msg)
return {
'statusCode': 500,
'body': json.dumps({
'error': error_msg,
'total_processed': total_processed,
'total_errors': total_errors + 1,
'timestamp': datetime.now().isoformat()
})
}
finally:
if 'conn' in locals() and conn is not None:
print("Closing database connection")
conn.close()인프라 정보
- vpc
- dots-iot-poc-vpc
- 10.8.0.0/16
- dots-iot-poc-vpc
- Pub-Subnet
- dots-iot-poc-pub-sub-2a
- 10.8.1.0/24
- dots-iot-poc-pub-sub-2c
- 10.8.2.0/24
- dots-iot-poc-pub-sub-2a
- Pri-Subnet
- dots-iot-poc-pri-sub-2a
- 10.8.3.0/24
- dots-iot-poc-pri-sub-2c
- 10.8.4.0/24
- dots-iot-poc-pri-sub-2a
- DB-Subnet
- dots-iot-poc-pri-db-sub-2a
- 10.8.5.0/24
- dots-iot-poc-pri-db-sub-2c
- 10.8.6.0/24
- dots-iot-poc-pri-db-sub-2a
- S3
- dots-iot-poc-s3
- MSK
- dot-iot-poc-msk-cluster
- MSK connector
- dots-iot-poc-mirror-topic-connector
- worker : dots-iot-poc-mirror-worker
- plugin : dots-iot-poc-connector-SCRAM-SHA-512-plugin
- dots-iot-poc-trans-rds-connector
- worker : dots-iot-poc-byte-worker
- plugin : dots-iot-poc-connector-SCRAM-SHA-512-plugin
- dots-iot-poc-mirror-topic-connector
- Lambda
- dots-iot-poc-rds-to-s3-lambda
- layer : dots-iot-poc-msk-to-rds-pymysql
- dots-iot-poc-rds-to-s3-lambda
- IoT Core rule
- dots_iot_poc_msk_R_qtm_rule
- rule topic : Platform/RealData/Qtm/qtm-guro
- dots_iot_poc_msk_I_qtm_rule
- rule topic : Platform/Info/Qtm/qtm-guro
- dots_iot_poc_msk_R_qtm_rule
