이전 포스팅에서 마지막 사진을 기억하신가요?

네. 이번 포스팅의 주제는 "삶은 계란" 입니다.
지금부터 "AWS IoT 에서 데이터를 MSK에 어떻게 주는가"를 살펴볼겁니다.
1. MSK Topic 내용 확인
$ kafka-console-consumer.sh --bootstrap-server [부트스트랩주소]
--consumer-property security.protocol=SASL_SSL
--consumer-property sasl.mechanism=SCRAM-SHA-512
--consumer-property sasl.jaas.config='org.apache.kafka.common.security.scram.ScramLoginModule required username="admin" password="!admin";'
--topic I-sensor --from-beginning
--property print.key=true--property print.key=true 옵션을 주면 key value 형태로 나오게 됩니다.
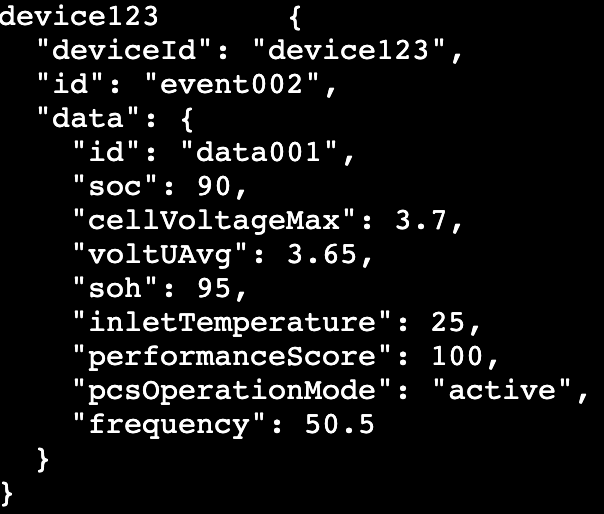
우리는 여기서 key는 device123 이고, value는 { ... } 라고 알 수 있습니다.
그렇담 key는 string이고, value는 { } 의 json 타입이겠거니 생각할 수 있습니다.
- 커넥터 설정
connector.class=io.confluent.connect.jdbc.JdbcSinkConnector
topics=I-sensor
tasks.max=1
# MSK IAM 인증 설정
security.protocol=SASL_SSL
sasl.mechanism=AWS_MSK_IAM
sasl.jaas.config=software.amazon.msk.auth.iam.IAMLoginModule required;
sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandler
# 데이터베이스 연결 설정
connection.url=jdbc:mariadb://[RDS 주소]:3306/test_db
connection.user=[DB username]
connection.password=[DB password]
table.name.format=t_device_data
# Converter 설정
key.converter=org.apache.kafka.connect.storage.StringConverter
key.converter.schemas.enable=false
value.converter=org.apache.kafka.connect.json.JsonConverter
value.converter.schemas.enable=false
# 테이블 매핑 설정
fields.whitelist=id,deviceId,data
insert.mode=insert
pk.mode=record_key
pk.fields=deviceId
delete.enabled=false
# 데이터 변환(SMT) 설정
transforms=Flatten,ExtractFields
transforms.Flatten.type=org.apache.kafka.connect.transforms.Flatten$Value
transforms.Flatten.delimiter=_
# 필드 추출 (id, deviceId, data만 포함)
transforms=FilterNulls,ExtractFields
transforms.FilterNulls.type=org.apache.kafka.connect.transforms.Filter$Value
transforms.FilterNulls.filter.condition=IS_NOT_NULL
transforms.ExtractFields.type=org.apache.kafka.connect.transforms.ReplaceField$Value
transforms.ExtractFields.whitelist=id,deviceId,data- RDS 테이블 설정
//test_db/t_device_data
CREATE TABLE t_device_data (
sequence_id BIGINT AUTO_INCREMENT PRIMARY KEY,
id VARCHAR(255) NOT NULL,
deviceId VARCHAR(255) NOT NULL,
data LONGTEXT,
event_timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);위와같이 커넥터 및 DB의 table 설정까지 마치고 실행해보면 cloudwatch에서 에러를 확인할 수 있습니다.
[Worker-0ef9a58fc60a58dbf] java.lang.NoSuchMethodError: 'boolean org.apache.kafka.common.utils.Utils.isBlank(java.lang.String)'
[Worker-0ef9a58fc60a58dbf] java.lang.NullPointerException커넥터 설정중에 SMT를 사용했습니다.
트랜스포메이션(SMT) 설정
- FilterNulls: NULL 값 필터링
- ExtractFields: 특정 필드만 추출
해당 설정대로라면, NULL이 없어야 되는데 "실제 값이 아닌 null을 가지고 있는 객체/변수를 호출" 하고 있습니다.

왜 그럴까요?
이유를 알아보기 위해 커텍터를 이용해 해당 토픽을 "복사" 해보았습니다.
connector.class=org.apache.kafka.connect.mirror.MirrorSourceConnector
tasks.max=1
# Source cluster configuration
source.cluster.alias=source
source.cluster.bootstrap.servers=b-1.[서버주소]
source.cluster.security.protocol=SASL_SSL
source.cluster.sasl.mechanism=SCRAM-SHA-512
source.cluster.sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username="이름" password="패스워드";
# Target cluster configuration
target.cluster.alias=target
target.cluster.bootstrap.servers=b-1.[서버주소]
target.cluster.security.protocol=SASL_SSL
target.cluster.sasl.mechanism=SCRAM-SHA-512
target.cluster.sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username="이름" password="패스워드";
# Topic configuration
topics=I-sensor
sync.topic.configs.enabled=false
sync.topic.acls.enabled=false
# Topic Settings (토픽 생성 관련 설정 추가)
config.action.reload=restart
admin.target.replication.factor=1
target.cluster.allow.auto.create.topics=true
# Converter configuration
source.key.converter=org.apache.kafka.connect.storage.StringConverter
source.key.converter.schemas.enable=false
source.value.converter=org.apache.kafka.connect.storage.StringConverter
source.value.converter.schemas.enable=false
target.key.converter=org.apache.kafka.connect.storage.StringConverter
target.key.converter.schemas.enable=false
target.value.converter=org.apache.kafka.connect.storage.StringConverter
target.value.converter.schemas.enable=false
# Topic renaming
replication.policy.class=org.apache.kafka.connect.mirror.DefaultReplicationPolicy
replication.policy.separator=.
auto.create.topics.enable=true
# Replication settings
replication.factor=1즉, "I-sensor"라는 토픽을 "source.I-sensor" 라는 토픽 으로 복사 (미러링) 합니다.
그러면 토픽을 조회했을 때, 아래와 같이 나옵니다.
//topic : source.qtm-t
[ec2-user@ip-10-8-4-84 bin]$ kafka-console-consumer.sh --bootstrap-server b-1.dotiotpocmskclust.v6q85l.c2.kafka.ap-northeast-2.amazonaws.com:9096 --consumer.config client.properties --topic source.I-sensor --from-beginning
"ewogICJkZXZpY2VJZCI6ICJkZXZpY2UxMjMiLAogICJpZCI6ICJldmVudDAwMiIsCiAgImRhdGEiOiB7CiAgICAiaWQiOiAiZGF0YTAwMSIsCiAgICAic29jIjogOTAsCiAgICAiY2VsbFZvbHRhZ2VNYXgiOiAzLjcsCiAgICAidm9sdFVBdmciOiAzLjY1LAogICAgInNvaCI6IDk1LAogICAgImlubGV0VGVtcGVyYXR1cmUiOiAyNSwKICAgICJwZXJmb3JtYW5jZVNjb3JlIjogMTAwLAogICAgInBjc09wZXJhdGlvbk1vZGUiOiAiYWN0aXZlIiwKICAgICJmcmVxdWVuY3kiOiA1MC41CiAgfQp9"
네, 맞습니다. base64로 인코딩 되어 있던 겁니다.
형태로 따지자면, 아래처럼 생겼습니다.
json(base64(data))
이제 왜 삶은 달걀인지 이해하셨나요?
data -> 노른자
base64 -> 흰자
json -> 계란 껍질
우리는 당연히 계란 안에 노른자가 있으니 이걸 꺼내려는데
커넥터 입장에서는 껍질 -> 흰자 -> 노른자 가 있으니 노른자를 못보는 상황이였던 것입니다!
(후...)

다음 포스팅에는 커넥터로 계란 까는 법을 설명드리겠습니다.
