로지스틱 회귀(Logistic Regression)이란?
로지스틱 회귀는 이름은 회귀지만, 분류 모델이다. 이 모델은 선형 회귀(Linear Regression)과 동일하게 선형 방정식을 학습한다.
이진 분류에서 선형 방정식으로 나온 값을 확률로 변환하여 0.5이상이면 양성 클래스(1), 0.5보다 작으면 음성 클래스(0)으로 분류한다.
그렇다면 로지스틱 회귀 모델에서 선형 방정식은 무엇이고, 이 값을 어떻게 확률로 변환할까?
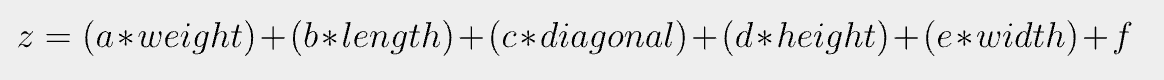
여기에서 a, b, c, d, e는 가중치 혹은 계수이다. z값은 어떠한 값도 가능하다.
하지만 우리는 확률로 변환해야 하기 때문에 z의 범위를 0~1로 변환해주어야 한다. z의 값을 0~1의 범위로 변환해주는 방법이 시그모이드 함수(sigmoid function)이다.
시그모이드 함수(sigmoid function)란?
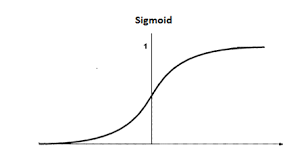
위의 식이 시그모이드 함수이다. z값을 시그모이드 함수에 넣는다면 다음과 같은 그래프 형태가 나온다.
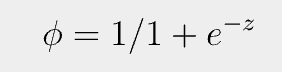
데이터 준비
#데이터 준비
import pandas as pd
fish = pd.read_csv('https://bit.ly/fish_csv_data')
print(len(fish))
fish.head()pd.unique(fish['Species'])
#생선의 종류는 총 7종류: ['Bream', 'Roach', 'Whitefish', 'Parkki', 'Perch', 'Pike', 'Smelt']독립변수는 생선 종류를 제외한 모든 피처, 종속변수는 생선 종류
fish_X = fish[fish.columns.difference(['Species'])].to_numpy()
fish_Y = fish['Species'].to_numpy()학습용 데이터셋, 테스트용 데이터셋을 나눈 후, 피처 스케일링(표준화)
#데이터셋 분리
from sklearn.model_selection import train_test_split
train_X, test_X, train_y, test_y = train_test_split(fish_input, fish_target, random_state=42)#피처 스케일링(표준화)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(train_X)
train_scaled = scaler.transform(train_X)
test_scaled = scaler.transform(test_X)
로지스틱 회귀로 이진 분류 수행하기
이진 분류이므로, 생선 종류를 도미와 방어로 한정한다.
bream_smelt_index = (train_y == 'Bream') | (train_y == 'Smelt')
train_bream_smelt = train_scaled[bream_smelt_index]
target_bream_smelt = train_y[bream_smelt_index]로지스틱 회귀 모델 구현 및 학습 및 평가
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_bream_smelt, target_bream_smelt)
print(target_bream_smelt[:5])
#출력값: ['Bream' 'Smelt' 'Bream' 'Bream' 'Bream']
print(lr.predict(train_bream_smelt[:5]))
#출력값: ['Bream' 'Smelt' 'Bream' 'Bream' 'Bream']
print(lr.predict_proba(train_bream_smelt[:5]))
#출력값: [[0.99759855 0.00240145]
[0.02735183 0.97264817]
[0.99486072 0.00513928]
[0.98584202 0.01415798]
[0.99767269 0.00232731]]첫 번째 출력값은 원래의 생선 종류, 두 번째 출력값은 예측한 생선 종류이다.
세 번째 출력값을 보면 샘플마다 2개의 확률이 출력되었다. 첫 번째 열은 음성 클래스(0)에 대한 확률이고 두 번째 열은 양성 클래스(1)에 대한 확률이다.
Bream, Smelt 클래스가 양성인지, 음성인지 확인하고 싶다면 다음과 같이 확인한다.
print(lr.classes_)
#해당 모델의 클래스 0과 1 순서대로 출력
#Bream이 0, Smelt가 1로지스틱 회귀 모델의 계수를 확인한다.
print(lr.coef_, lr.intercept_)
#출력값: [[-0.66280298 -1.01290277 -0.57620209 -0.4037798 -0.73168947]] [-2.16155132]즉 해당 모델이 학습한 선형 방정식은 다음과 같다
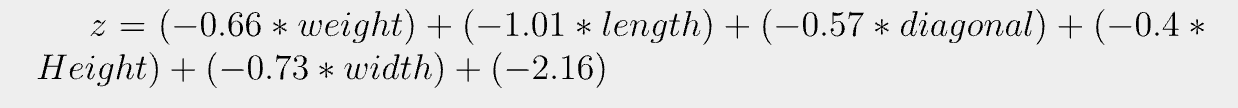
로지스틱 회귀 모델을 이용한 다중 분류
- 로지스틱 회귀는 기본적으로 릿지 회귀와 비슷하게 계수의 제곱을 규제함. L2 규제라고 부름.
- 릿지 회귀에서 규제의 매개변수는 alpha, 로지스틱 회귀에서는 C임. C의 기본값은 1임. C가 작을수록 규제가 커짐.
- 로지스틱 화귀는 기본적으로 반복적인 알고리즘을 사용함. max_iter 매개변수를 사용하여, 반복회수를 조절함.
다중 분류를 위한 로지스틱 회귀 모델 구현 후 학습 및 평가
lr = LogisticRegression(C=20, max_iter=1000)
lr.fit(train_scaled, train_y) #로지스틱 회귀모델을 학습용 데이터로 학습시킴
print(lr.score(train_scaled, train_y)) #학습된 모델을 학습용 데이터로 점수 판단.
print(lr.score(test_scaled, test_y)) #학습된 모델을 테스트용 데이터로 점수 판단.
#출력값: 0.9327731092436975
#출력값: 0.925둘다 점수가 높으며, 비슷하기 때문에 과적합이 아니다.
테스트용 데이터셋의 5개 샘플에 대한 예측 및 확률 출력
print(lr.predict(test_scaled[:5]))
print(np.round(lr.predict_proba(test_scaled[:5]), decimals=3))
#출력값: ['Perch' 'Smelt' 'Pike' 'Roach' 'Perch']
#출력값: [[0. 0.014 0.841 0. 0.136 0.007 0.003]
[0. 0.003 0.044 0. 0.007 0.946 0. ]
[0. 0. 0.034 0.935 0.015 0.016 0. ]
[0.011 0.034 0.306 0.007 0.567 0. 0.076]
[0. 0. 0.904 0.002 0.089 0.002 0.001]]5개의 샘플에 대한 예측이므로 5개의 행이 출력됐으며, 7개의 생선 종류에 대한 확률을 계산했으므로 7개의 열이 출력됐다.
어떤 행이 어떤 생선에 대한 확률일까?
print(lr.classes_)
#출력값: ['Bream', 'Parkki', 'Perch', 'Pike', 'Roach', 'Smelt', 'Whitefish']해당 모델의 선형 방정식에 대한 계수와 절편의 크기를 출력해보자.
#다중 분류의 선형 방정식
print(lr.coef_.shape, lr.intercept_.shape)
#출력값: (7, 5) (7,)이전에 이진 분류에서의 선형 방정식 z가 7개의 생선을 분류하는 다중 분류에서는 그 z가 7개나 있다는 뜻이다.
다중 분류는 클래스마다 z값을 하나씩 계산하여, 가장 높은 z값을 갖는 클래스로 예측을 한다.
아까 이진 분류에서는 확률을 시그모이드 함수를 이용하여 0~1 범위로 압축했다.
하지만 다중 분류에서는 소프트맥스(Softmax) 함수를 사용하여 7개의 z값을 확률로 변환한다.
- 소프트맥스 함수는 여러 개의 선형 방정식 z를 0~1로 압축 후, 전체 합이 1이 되도록 변환한다.
다음은 소프트맥스 함수에 대한 계산법이다.
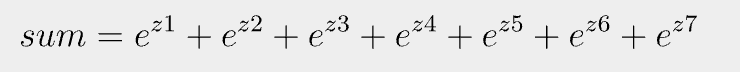
먼저 7개의 z값의 이름을 z1에서 z7이라 한다. 후에 위의 계산으로 sum을 구한다.
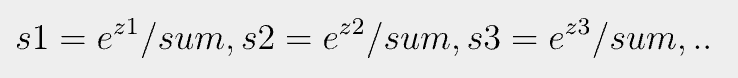
후에 다음의 계산과 같이 sum을 각각 나누어주면 된다. s1~ s7의 합은 1이 됨.
