
1. 배경(Background)
2017년에 Attention is All You Need라는 논문이 나온 이후로 어텐션(뉴진스 - Attention 아님) 구조는 최초에 제안되었던 NLP 분야는 물론 Computer Vision 분야와 Time Series 분야까지 다양한 분야에서 적용되고 있습니다.
많은 사람들이 트랜스포머(Transformer)가 매우 혁신적인 모델이며 사용해야 할 필요성을 가슴으로는 알지만 그것을 제안한 Attention is All You Need 논문을 머리로 이해하는 것은 다른 문제입니다.
호기롭게 논문을 읽으려고 도전하지만 인코더(Encoder)-디코더(Decoder) 구조, 셀프-어텐션(Self-Attention)이 어텐션이랑 뭐가 다른지, 쿼리(Query)-키(Key)-값(Value)는 정확히 무엇을 의미하는 것인지, 포지셔널 인코딩(Positional Encoding)은 무엇이며, Multi-Head의 의미는 무엇인지 등 수많은 의문만을 가집니다. 그런 의문들을 뒤로한 채 torch에서 구현해놓은 transformer 모델을 불러오거나, Hugging Face 에서 학습해놓은 pre-trained transformer 모델을 사용하면서 본인이 트랜스포머를 완전히 이해하였다고 자기 최면을 걸곤 합니다.
저 역시 마찬가지였습니다.
트랜스포머의 구조와 쿼리-키-값의 사용, 포지셔널 인코딩(Positional Encoding)과 셀프 어텐션의 특징들을 이해하지 못한 채, torch에서 구현해놓은 nn.transformer 모델을 무한으로 사용하고 있었습니다.
torch느님, Hugging Face느님이 계시지 않았다면, 트랜스포머를 구현할 줄 몰랐을 애송이였던 제 자신을 돌아보며 이 게시글을 작성하게 되었습니다. 많은 Reference를 통해 최대한 이해하기 쉽게 쓰되, 필수적인 기술적 부분들을 놓치지 않고 담고자 하였습니다.
이 글을 읽는 당신이 더이상 트랜스포머 구조를 이해한 척 하고자 여러 블로그를 유랑하지 않기를 바랍니다.
2. 어텐션 매커니즘이란?
어텐션을 이해하기 전에 예시를 통해 단어 'Attend'가 어떤 의미로 사용되었는지 설명하고자 합니다.

"(옥상에서 담배 한 모금 마시면서) 모히또 가서 몰디브나 한잔 하자"
이 대사와 장면 조합을 한 화면에 보고 이 영화가 어느 영화인지 물어보는 질문에 답하기 위해 당신은 내부자들의 모든 장면과 대사를 숙지하고 있을 필요가 전혀 없습니다. 사실상 '모히또'와 '몰디브' 두 단어와 옥상에서 쌈배 타임을 가지며 야시꾸레한 미소와 함께 한강변을 그윽하게 바라보는 이병헌과 조승우만 보고도 당신은 이 영화가 <내부자들>이라는 사실을 쉽게 알 수 있습니다.
실제로 우리가, 보통의 인간이라면 그렇습니다. 어떤 정보가 들어왔을 때 모든 정보에 집중하는 것이 아니라 "Attend To" certain part 즉, 소수의 정보에만 집중하는 것이 인간의 직관이라는 것입니다.
어텐션 매커니즘은 여기서 출발합니다.
2.1 기존 Seq2Seq의 문제점
Seq2Seq 모델은 번역, 요약과 같이 시퀀스(Sequence)를 입력 받아 시퀀스를 출력하는 작업을 위해 고안된 RNN 기반의 모델입니다. 아래의 그림과 같이 영어 문장 I am a student.를 프랑스어 Je suis étudiant.로 번역하는 작업을 한다고 할 때, 인코더(Encoder)는 입력 문장("I am a student")를 입력 받아 문맥 벡터(Context Vector)를 출력하고, 디코더(Decoder)는 문맥 벡터와 <sos> 토큰을 입력받아 출력 문장("Je suis étudiant")를 출력합니다.
Seq2Seq 모델은 '시퀀스를 받아들이는 부분'과 '시퀀스를 출력하는 부분'을 분리한 것이 특징입니다. 구체적으로 동작의 순서를 살펴보면 다음과 같습니다.
- 인코더의 은닉 상태를 적절한 값으로 초기화
- 매 시점(time step) 원문의 단어(token)가 입력되면 인코더는 이를 이용해 은닉 상태를 업데이트
- 입력 시퀀스의 마지막까지 이 과정을 반복하면 인코더의 최종 은닉 상태는 입력 시퀀스의 압축 요약된 정보를 담게 됨
- 위의 마지막 시점에서의 인코더 은닉 상태를 문맥 벡터(Context Vector)라 하며, 이 값이 디코더로 넘어감
- 디코더는 전달받은 문맥 벡터로 자신의 은닉 상태를 초기화
- 매 시점(time step) 바로 직전 시점에 출력했던 단어를 입력받아 은닉 상태 업데이트
<eos>토큰이 나올 때까지 6의 과정 수행

앞서 설명한 것과 같이 RNN, LSTM, GRU와 같은 기존의 Seq2Seq 모델들도 이전 입력을 고려하는 것이 가능했습니다. 그러나 아래 그림과 같이 RNN은 짧은 참조 윈도우(Shorter Reference Window) 크기를 가지고 있기에 입력이 길어지면 주어진 시퀀스보다 긴 입력을 고려하지 못하는 문제를 가지고 있습니다.
그러고보니 Seq2Seq은 생각보다 단점이 많은 구조였습니다.
-
병렬화 문제 : 구조상 순차적으로 입력을 처리해야하기에 병렬화가 불가능했습니다. 이 때문에 대규모의 데이터셋의 경우 학습 시간이 지나치게 길어졌습니다.
-
Long Distance Dependency 문제 : 참조 윈도우의 크기가 고정되어 있었기 때문에 시퀀스에서 멀리 떨어진 항목들 간의 관계성은 Gradient Vanishing/Exploding 문제로 학습이 잘 되지 않았습니다.

이에 어텐션 매커니즘(Attention Mechanism)은 위 두가지 문제에 대한 좋은 해결책이 되었습니다.
RNN을 개선한 LSTM, GRU 등은 RNN에 비해 상대적으로 긴 윈도우 크기를 가지고 있지만 그 길이가 무한하지 않았습니다. 어텐션 매커니즘(Attention Mechanism)에서는 이론적으로, 컴퓨팅 리소스가 충분하다는 가정 아래 무한한 크기의 참조 윈도우 크기를 가질 수 있으며 긴 시퀀스가 담고 있는 전체적인 문맥 역시 반영할 수 있었습니다.
또한 병렬화가 가능하고, 각 QUERY와 모든 KEY를 비교하기에 Long Distance Dependency 문제를 해결할 수 있으며, 그에 따라 학습 속도가 빠르고 더 큰 데이터셋에 적용이 가능했습니다. 실제로 트랜스포머 모델은 Seq2Seq 모델에 비해 좋은 성능을 냈습니다.
트랜스포머 모델은 입력의 길이와 상관없이 중요한 모든 부분에 대해 "Attend to" 할 수 있게 만들었습니다. 바로 이 점이 트랜스포머가 가지는 강력함입니다.
2.2 Self-Attention이란 무엇인가?
![]()
셀프 어텐션(Self-Attention)은 같은 문장 내에서, 즉 입력으로 들어온 시퀀스 안에서 단어들 간의 관계를 고려하는 것입니다. 이를 보다 자세히 이해하려면 다음의 세가지 질문에 답을 할 수 있어야 합니다 :
💡 Questions
1. QUERY, KEY & VALUE는 무엇인가?
2. Positional Encoding은 무엇인가?
3. QUERY, KEY & VALUE에는 무엇이 들어가는가?
위의 질문에 답하기 위해 Attention is All You Need에서 소개하고 있는 인코더 모델에 대해 조금 더 깊이 있게 살펴보겠습니다.
1. QUERY KEY VALUE는 무엇인가?
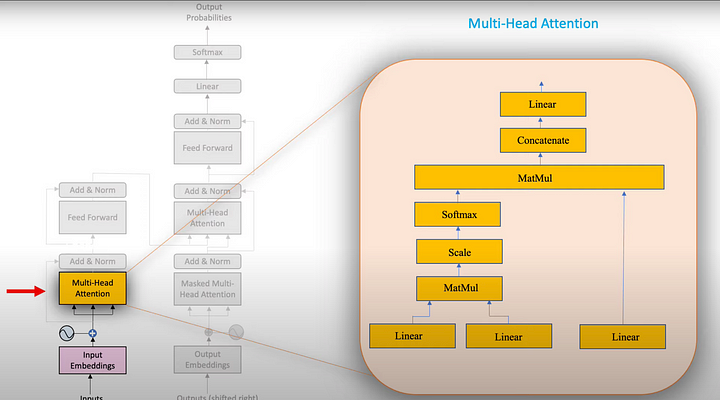
위 그림의 오른쪽 하단의 세개의 Linear Layer들이 QUERY, KEY, VALUE를 의미합니다. 예시를 통해 이해를 돕겠습니다.
만약 당신이 유튜브나 구글에서 무언가를 검색한다면, 검색 상자에 입력하는 텍스트가 QUERY입니다. 비디오 또는 기사 제목으로 표시되는 결과는 KEY이고 그 안의 내용은 VALUE입니다. 쿼리와 가장 잘 일치하는 KEY를 찾기 위해서는 QUERY와 KEY 사이의 유사성을 찾아야하며, 이것이 트랜스포머에서 QUERY와 KEY 사이의 유사성을 구하는 이유입니다.
쿼리와 키 사이의 유사성을 계산하기 위해 코사인 유사도(Cosine Similarity)를 구하는 방법을 사용합니다. 이는 두 벡터 사이의 유사성을 찾는 데에 흔히 사용되는 방법입니다. 코사인 유사도는 +1에서 -1까지 다양하며, 여기서 +1은 가장 유사한 것을, -1은 가장 비유사한 것을 의미합니다.
이와 같은 방식으로 QUERY, KEY의 유사도를 계산하며, QUERY와 KEY의 유사도에 따라 해당 부분의 중요도를 판단합니다.
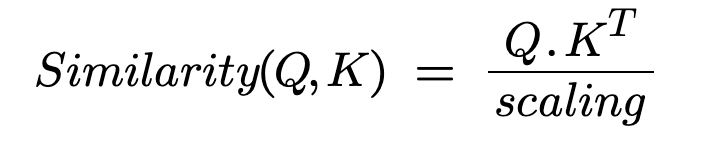
2. Positional Encoding은 무엇인가?
![]()
RNN 구조에서는 순서대로 들어오는 입력이 자연스럽게 모델에 들어왔으나, 어텐션 연산에서는 순서 정보가 고려되지 않습니다. 그렇기에 트랜스포머 모델에서는 모델에 입력되는 입력 임베딩(Input Embedding)에 Positional Encoding이라 불리는 입력 임베딩과 같은 차원의 위치 정보를 담고 있는 벡터를 더해줍니다.
입력 임베딩의 차원이 라 할 때, 번째 단어의 Positional Encoding은 다음 식을 사용하여 계산됩니다. (단, )
예를 들어 I love you but not love him이라는 문장이라면 앞의 love와 뒤의 love는 일반적인 임베딩만을 거쳤을 때 동일한 값을 가지게 됩니다(이는 일반적인 Word2Vec과 같은 임베딩의 문제이기도 합니다). 하지만 Positional Encoding 이라는 주기함수에 의한 위치에 따른 다른 임베딩을 거치면 같은 단어일지라도 문장에서 쓰인 위치에 따라 다른 임베딩 값을 갖게 되어 해당 단어의 위치 정보가 성공적으로 모델에 전달됩니다.
3. QUERY, KEY & VALUE에는 무엇이 들어가는가?
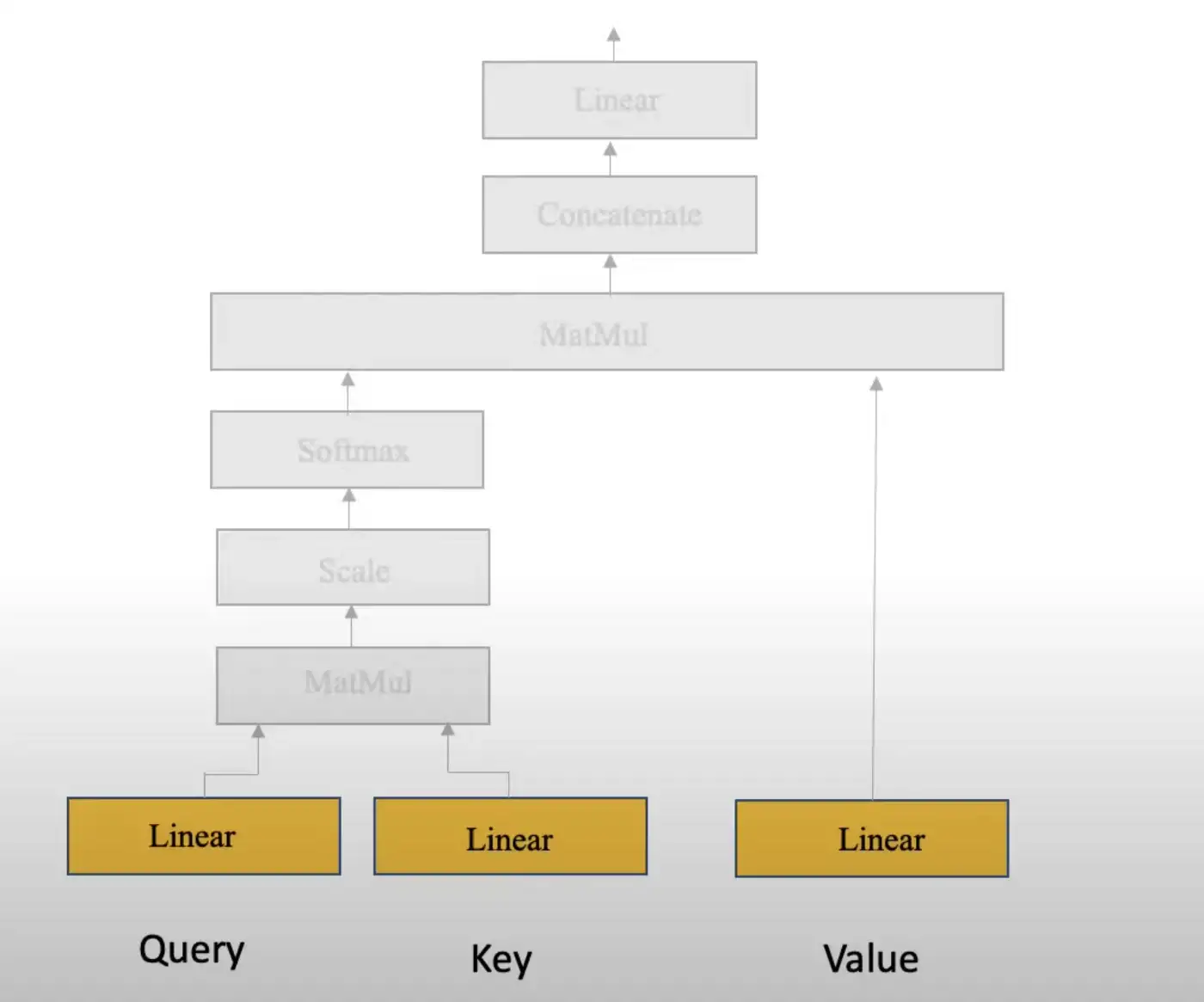
QUERY Layer에는 이전에 위치를 인식할 수 있도록 만들어놓은 Position-aware Embedding을 입력합니다. 그 이후 모델은 해당 임베딩에 대한 두개의 복사본을 만들어서 KEY, VALUE로 입력합니다. 이 지점이 사실 이해가 어려운 지점입니다. 왜 우리는 세개의 동일한 임베딩 레이어를 입력으로 사용하는 것일까요? 이런 방식이 어떤 의미가 있을까요? 이에 대한 답을 하기 위해서 Self-Attention에 대한 이해가 필요합니다.
아래의 예시를 통해 설명하겠습니다.
Hi, How are you?라는 입력을 모델에 넣었을 때, 트랜스포머가 I am fine.이라는 결과를 내도록 하는 Task입니다.
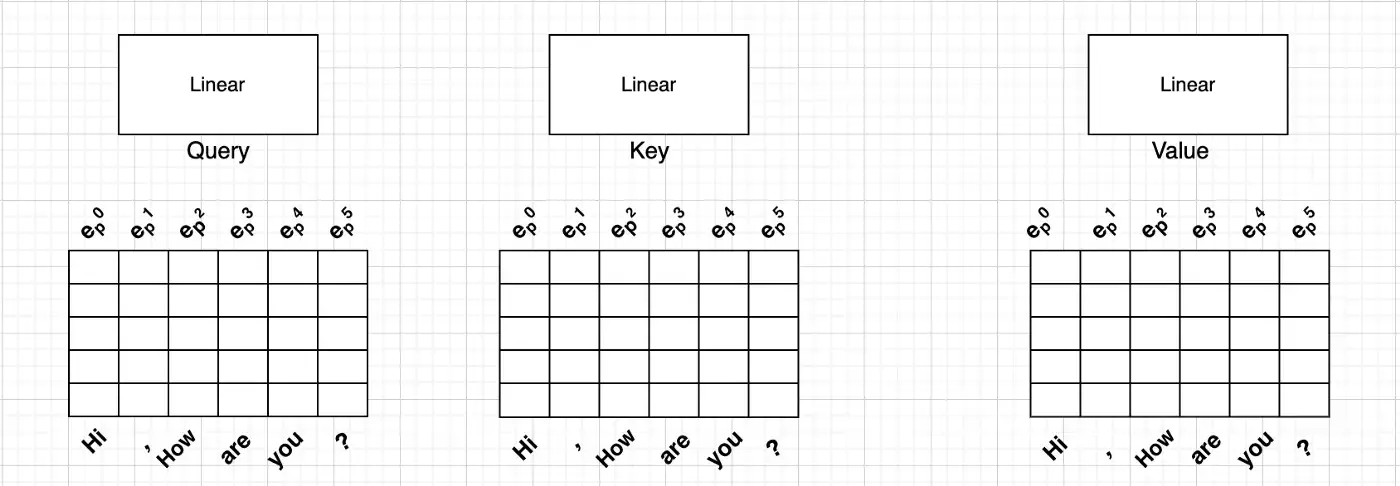
이 Task를 수행하기 위해서 우리는 Hi, How are you?라는 문장을 입력 임베딩 레이어에 입력시키며, 이에 대한 Positional Encoding을 먼저 진행하여야 합니다. 그렇게 생성된 Positional-aware Embedding을 트랜스포머를 구성하는 Linear Layer에 통과시킵니다.
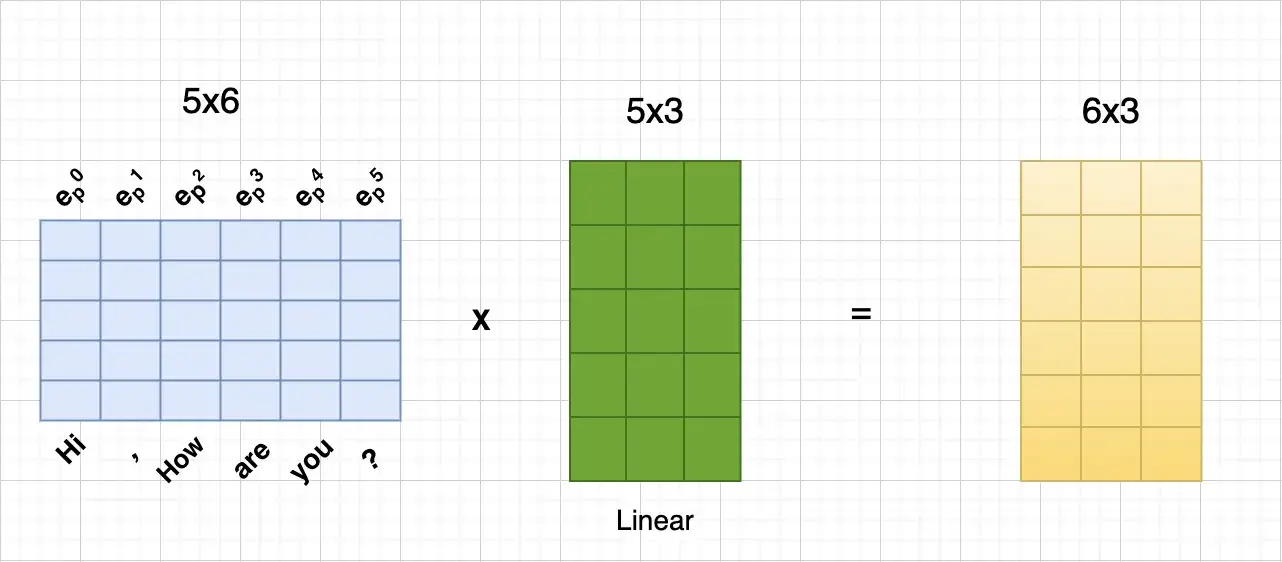
Postional-aware Embedding을 Linear Layer를 통과하면서 6x5 크기를 가지는 Embedding에 5x3 크기의 Transpose된 Linear Layer를 곱하여 최종적으로 6x3 형태로 전처리하며 같은 과정을 QUERY, KEY, VALUE 모두에 대해 수행함으로써 각각의 크기를 모조리 6x3으로 만듭니다.
2.3 Scaled Dot-Product Attention의 연산 결과는 어떻게 되는가?

Scaled Dot-Product Attention의 입력으로 들어가는 QUERY와 KEY는 둘 사이의 유사도를 게산하기 위해 사용되는 바, QUERY와 KEY의 Linear Layer는 (1) MatMul -> (2) Scale -> (3) Mask(opt.) -> (4) 'SoftMax' -> (5) Value와의 MatMul의 5가지 단계를 거치게 됩니다. 이 각각의 단계에서 어떤 결과물이 나오는지 아래에서 구체적으로 살펴보겠습니다.
(1) QUERY와 KEY의 MatMul
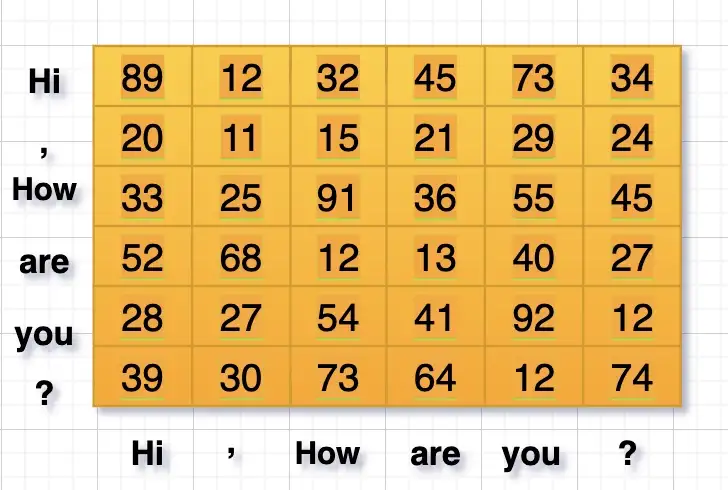
첫번째 Dot Product의 결과는 Attention Filter라고 불립니다. 그림의 예시에서와 같이 6x3의 크기를 가지는 QUERY와 3x6의 크기를 가지는 Transpose된 KEY에 대해 Dot Product를 수행하여 6x6 크기의 Attention Filter를 구합니다.
(2) Scale
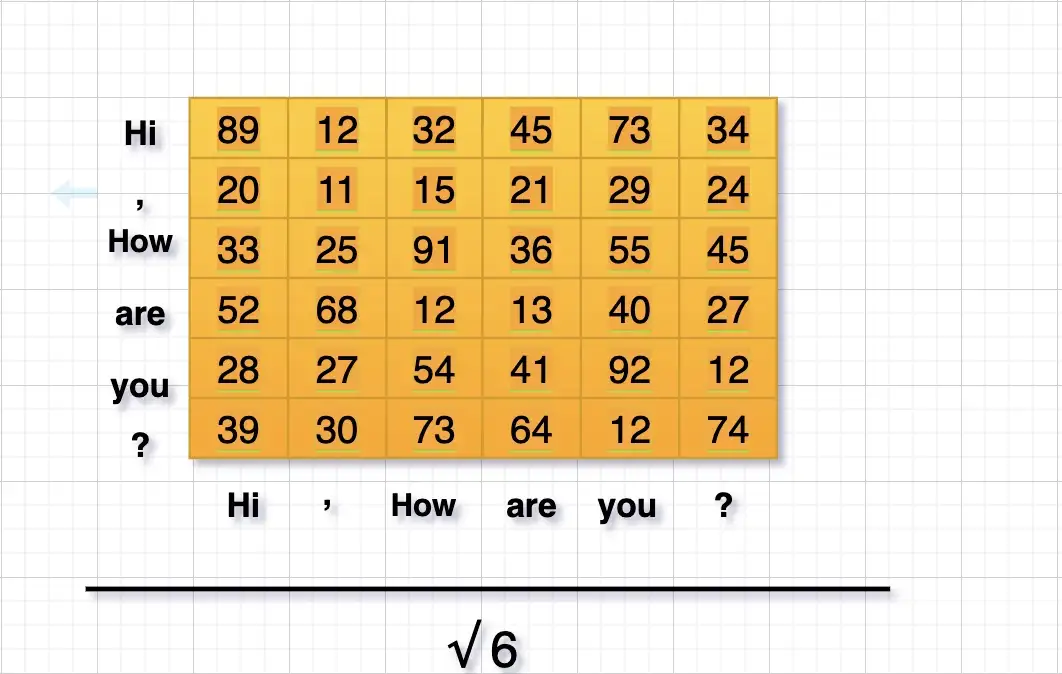
처음에 Attention Filter에 존재하는 값들은 랜덤한 숫자 그 이상도 이하도 아니었습니다. 그러나 한번 학습 과정이 마무리되면 모든 값들이 유의미한 값으로 채워지게 되며, 학습이 모두 마무리되면 이 Attention Filter의 값들은 Attention Score가 됩니다. <Attention is all you need>의 저자는 이렇게 구해지는 Attention Score 값을 KEY 벡터의 차원(Dimension)에 루트를 취한 값 으로 나누어 Scaling을 수행하는데, 이 예시에서는 d = 6이므로 으로 나누어 Scaling을 하게 됩니다.
(3) Mask(Opt.)
Mask(Opt.) 부분은 Opt.라는 라벨의 의미와 같이 Optional한 부분입니다. 입력 문장 중 Word인지 아닌지 여부를 Masking을 통해 구분하는 기능을 수행합니다. 이는 Word 입력이 끝난 후 Padding 처리하는 것과 동일합니다.
(4) SoftMax
SoftMax의 식은 위와 같습니다. Scale 이후에는 SoftMax Layer에 통과시켜 위에서 구한 Attention Score을 최종적으로 0에서 1의 값으로 바꾸게 됩니다.

이처럼 Attention Score로 대두되는 하나의 Filter를 사용하는 이유는 위의 그림으로 설명할 수 있습니다. 그림에서 Attention Filter가 Original Image와 곱해져서 최종적으로 얻고자 하는 Filtered Image가 되는 것처럼, Attention Score가 VALUE와 내적되어 불필요한 정보들을 제거하고 우리가 집중하고자 하는 정보만을 추출할 수 있게 됩니다.
(5) Value와 Dot-Product
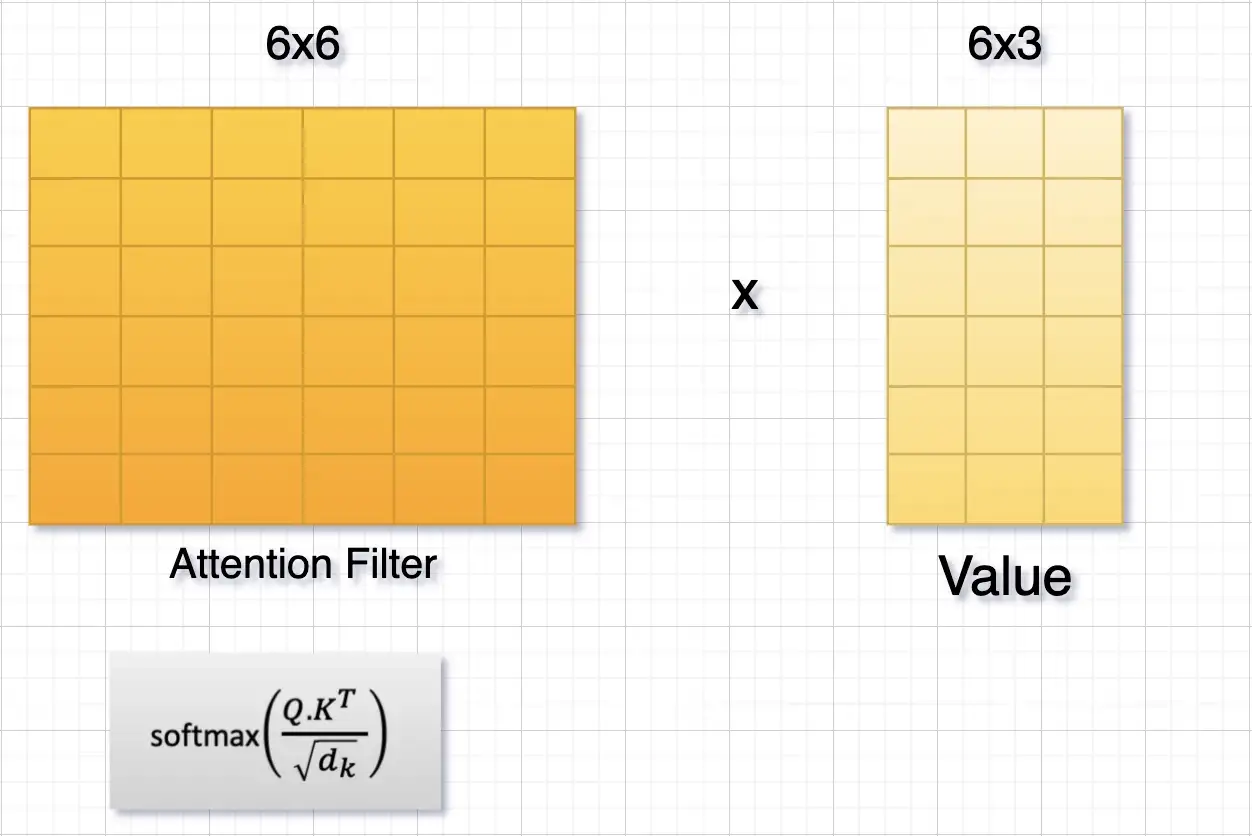
Seq2Seq Attention에서 F(enc_output)과 Alpha_vector를 내적해서 attention의 결과인 Context Vector로 사용하는 것처럼, 트랜스포머에서는 VALUE와 {QUERY와KEY의 내적에 SoftMax를 취한 Attention Score}를 내적하여 Context Vector로 사용합니다.
결국... Self-Attention...!
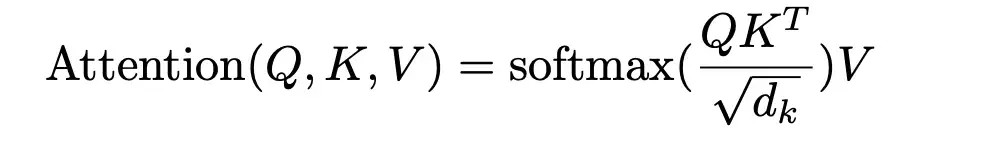
그래서 결국 의 식은 위와 같습니다. 단 한 줄의 수식이지만 코드로 구현한다면 5개의 Layer(MatMul, Scale, Mask(Opt.), SoftMax, MatMul)을 거쳐 계산되는 꽤 복잡한 과정입니다.
이것이 Self-Attention의 Step-by-Step 과정입니다. 이 단 한줄의 수식이 NLP와 Computer Vision 분야에 지대한 영향을 미쳤으며, 수많은 딥러닝 연구 분과에서 엄청난 성과들을 가져왔고, 딥러닝의 역사를 바꾸었습니다.
2.3 Multi-Head Attention이란 무엇인가?
Multi-Head Attention은 기본적으로 Multiple Self-Attention과 동일한 의미입니다. 예시를 통해 보다 구체적으로 Multi-Head Attention을 설명하겠습니다.
RPG 게임을 하다가 거대한 불을 뿜는 드래곤을 사냥하는 퀘스트를 받았다고 가정해봅시다. 추가적으로 그 용이 당신의 캐릭터에게 피해를 줄 수 있는 유일한 방법이 불을 뿜는 스킬 뿐이라고 가정해봅시다.
당신의 목표는 이 드래곤을 물리치고 퀘스트 보상을 받는 것입니다. 만약 당신이 이 퀘스트를 Self-Attention Mechanism으로 해결한다고 하면, 알고리즘은 학습 과정에서 불을 내뿜는지 여부를 확인하기 위해서 목이나 얼굴에 주의를 기울이는 것으로, 즉 목이나 얼굴의 변화에 높은 Score를 할당하는 Attention Score Vector를 생성해낼 것입니다. 그리고 이러한 Attention Score 덕에 당신은 쉽게 이 용을 물리치고 퀘스트 보상을 획득할 수 있을 것입니다.
그렇다면 문제를 좀 더 복잡하게 만들어보겠습니다.

만약 사냥터에 용이 한마리가 아니라 두마리가 있었고, 둘 다 불을 뿜을 수 있는 스킬을 가지고 있다면 어떨까요? 기존의 매커니즘은 한마리의 드래곤에만 집중할 수 있는 능력을 가지고 있었기 때문에 하나의 Attention만 사용하면 퀘스트를 깨지 못할 가능성이 높습니다. 이 때가 바로 Multi-Head Attention이 필요해지는 순간입니다.

앞서 말했듯, Multi-Head Attention에서는 여러 개의 Self-Attention Layer들이 있으며, 각각 다른 언어 현상을 학습합니다. 따라서 각 Self-Attention은 자체적인 Attetnion Filter들을 생성해내며, 이 필터들은 자체 필터링된 VALUE 행렬을 출력하게 됩니다. 결과적으로 각각의 Head들이 다른 Attention Filter를 생성함에 따라 같은 문장이 입력되더라도 다른 언어적 특징에 집중하게 되는 것입니다. 위의 예시의 경우 비슷한 용 두마리가 있다고 하더라도, 각각의 용가리가 언제 불을 뿜는지, 어떤 특징이 있는지 다른 Attention Mechanism을 사용함을 통해 사냥에 성공할 수 있을 것입니다.
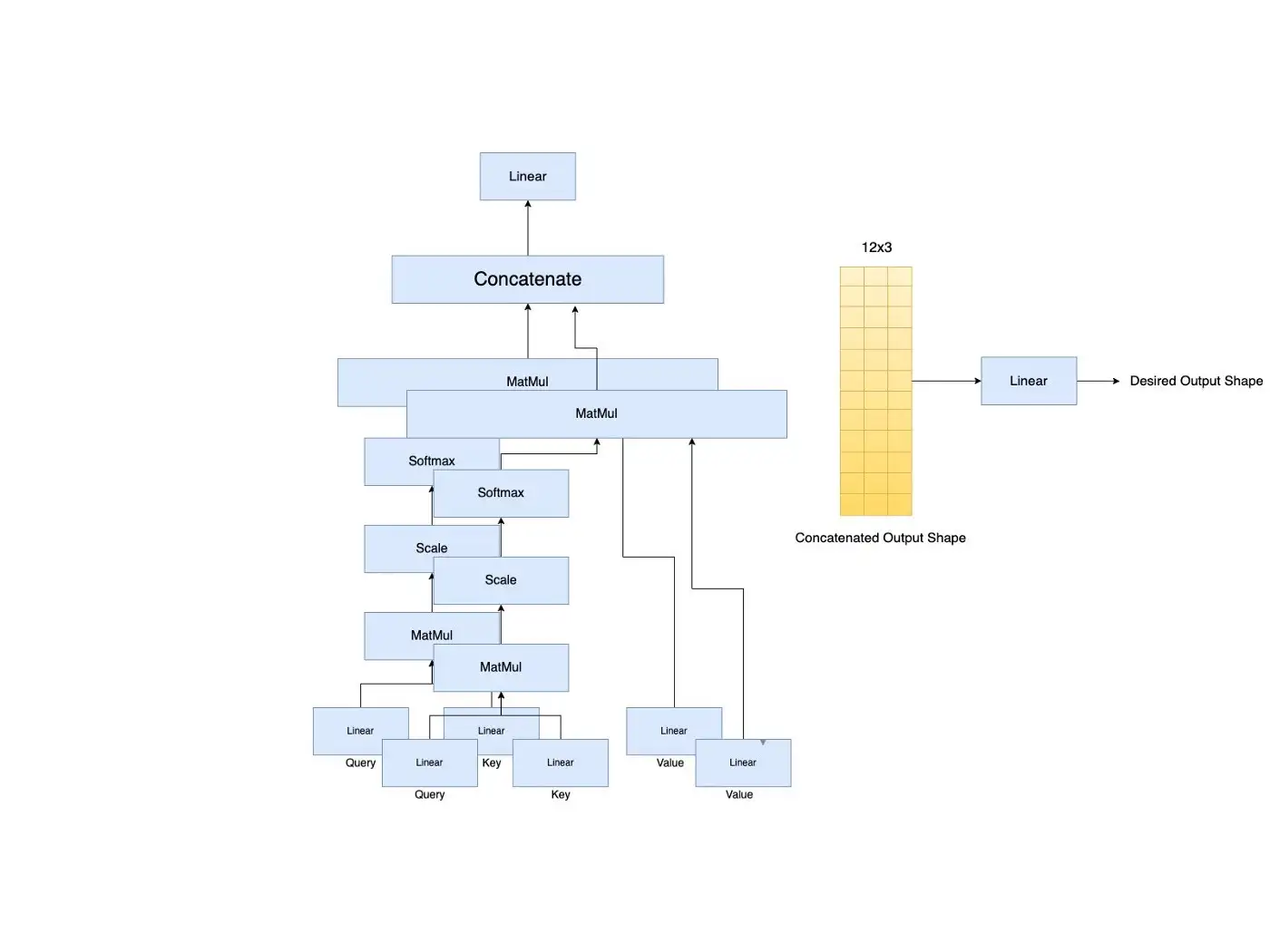
최종적으로 해결하려는 문제에 맞게 사용할 Head의 수, 즉 생성하고자 하는 Attention Filter의 수를 정해야 하며, 그에 따른 Ouptput을 Concatenate하여 Linear Layer에 통과시킴으로써 원하는 출력 크기를 갖추게 됩니다.
3. 결어(Conclusion)
Transformer는 GPT-3 및 BERT와 같은 유명한 언어 모델의 기반이 되며 NLP 분야 뿐 만 아니라 여러 딥러닝 연구 분과에 상상하지도 못할 혁신을 가져왔습니다.
따라서 딥러닝을 연구하는 사람에게 <Attention is all you need(2017)> 논문의 중요도를 평가할 수 없을 정도로 중요하며, Transformer 구조의 제안으로 NLP 분야를 천하통일한 게임 체인저이기 때문에 그 실용성 역시 평가할 수 없을 정도입니다.
이 논문을 누구나 이해할 수 있을 정도로 쉽게 정리하는 것을 숙원 사업 중 하나로 남겨놓고 있었는데 드디어 Writing을 마무리하여 마음이 한결 편합니다. 서론 부분에 언급했듯, 이 글을 본 딥러닝에 관심있는 모든 분들이 이 글로 🚘Transformer🚘와 👀Attention👀의 개념을 완벽히 이해하시어 더이상 이해를 위해 블로그 유랑 생활을 하시지 않으셨으면 좋겠습니다.
감사합니다.
Reference
[1] Visual Guide to Transformer Neural Networks — (Episode 2) Multi-Head & Self-Attention : https://www.youtube.com/watch?v=mMa2PmYJlCo&t=309s
[2] Illustrated Guide to Transformers- Step by Step Explanation : https://towardsdatascience.com/illustrated-guide-to-transformers-step-by-step-explanation-f74876522bc0)
[3] Attention Is All You Need : https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
[4] Introduction to Deep Learning: Attention Mechanism : https://www.youtube.com/watch?v=d25rAmk0NVk
[5] The Attention Mechanism from Scratch : https://machinelearningmastery.com/the-attention-mechanism-from-scratch/
[6] A Comprehensive Guide to Attention Mechanism in Deep Learning for Everyone : https://www.analyticsvidhya.com/blog/2019/11/comprehensive-guide-attention-mechanism-deep-learning/
[7] 어텐션 매커니즘(https://heekangpark.github.io/nlp/attention)
[8] Attention Networks: A simple way to understand Multi-Head Attention : https://medium.com/@geetkal67/attention-networks-a-simple-way-to-understand-multi-head-attention-3bc3409c4312







이해가 한 번에 됐습니다. 감사합니다.