
4장 의사결정나무
4.1 기본 프로세스
Decision Tree는 분류 또는 회귀 모두 가능한 지도 학습 모델 중 하나임. 일반적으로 의사결정나무는 하나의 Root Node, 여러개의 Internal Node, 그리고 여러개의 Leaf Node 또는 Terminal Node를 포함.
Leaf Node의 경우 결정 결과에 상응하고, 기타 다른 노드는 하나의 속성 테스트에 상응함. 각 노드에 포함된 샘플 집합은 속성 테스트 결과에 따라 하위 노드로 분류되며 Root Node를 모든 샘플의 집합을 포함하는 것으로 보고 Root Node에서 시작해 각 Leaf Node로 뻗어가는 과정은 일련의 판단과 테스트의 과정임.
의사결정나무 학습의 목표는 일반화 성능이 뛰어난 의사결정나무를 얻는 것임. 기본적인 프로세스는 재귀적으로 간단하고 직관적인 분할 정복(Divide and Conquer) 전략을 기본으로 함.
# Pseudo Code for Decision Tree
input : training set D, Feature A
def TreeGenerate(D,A)
1: node 생성
2: if D의 샘플이 같은 클래스 C에 속하면:
3: 해당 node를 레이블이 C인 Terminal Node로 정함
4: if A = 0 or D의 샘플이 A 속성에 같은 값 취할 경우:
5: 해당 node를 Terminal Node로 정하고, 해당 클래스는 D 샘플 중 가장 많은 샘플의 수가 속한 속성으로 정함
6: A에서 최적의 분할 속성 a*를 선택
7: for a*의 각 값 a*[v]에 대해 다음:
node에서 하나의 가지를 생성.
D_v는 a*[v] 속성값을 가지는 샘플의 하위 집합으로 표기
if D_v = 0:
해당 가지 node를 Terminal Node로 정하고 해당 클래스는 D 샘플 중 가장 많은 클래스로 정함
else:
TreeGenerate(D_v, A\{a*})을 가지 노드로 정함
output : node를 Root Node로 하는 Decision Tree🔎 위 알고리즘에서 볼 수 있듯이 의사결정나무는 다음과 같은 세가지 상황 때문에 재귀 과정이 일어나게 됨.
- 해당 노드에 포함된 샘플이 모두 같은 클래스에 속할 경우 더는 분할을 진행하지 않음 ... (1)
- 해당 속성 집합이 0일 경우, 혹은 모든 샘플이 모든 속성에서 같은 값을 취할 경우, 더는 분할을 진행하지 않음 ... (2)
- 해당 노드가 포함하고 있는 샘플의 집합이 0인 경우, 더는 분할을 진행하지 않음 ... (3)
두번째 상황에서 해당 노드를 Terminal Node라고 정의하며 해당 클래스를 해당 노드가 포함하고 있는 샘플 중 다수를 차지하는 클래스로 정의함.
세번째 상황에서는 동일하게 해당 노드를 Terminal Node라고 정의하지만 해당 클래스는 부모 노드가 포함하고 있는 샘플 중 다수가 속한 클래스로 설정함.
주의해야할 점은 (2)번 상황에서는 해당 노드의 사후 분포를 사용하는 것이고, (3)번 상황에서는 부모 노드의 샘플 분포를 해당 노드의 사전 분포로 사용하는 것임!
4.2 분할 선택
4.2.1 정보 이득
정보 엔트로피(Information Entropy)는 샘플 집합의 순도를 측정하는 데 가장 자주 사용되는 일종의 지표임. 만약 샘플 집합 의 번째 클래스 샘플이 차지하는 비율이 라고 한다면 D의 정보 엔트로피는 다음과 같이 정의됨
즉 의 값이 작을수록 의 순도는 높아지게 됨을 의미.
만약 이산 속성을 가진 속성 가 취할 수 있는 값이 개가 있다고 가정하면 샘플 수가 많은 분기 노드의 영향력이 더 커지고 따라서 샘플 집합 에 대해 속성 가 분할을 통해 얻은 정보 이득(Information Gain)을 계산할 수 있음.
일반적으로 정보 이득이 크면 속성 a를 사용하여 분할할 때 얻을 수 있는 순도 상승도가 높아지는 것을 의미. 따라서 우리는 정보 이득을 기반으로 의사결정나무의 분할 속성을 선택할 수 있게 됨.

위와 같은 데이터가 존재한다고 할 때, Yes를 +, No를 -로 정의한다면 +는 9개이고 -는 5개가 됨. Wind라는 Feature를 이용했을 때의 정보 이득은 아래와 같이 계산할 수 있음.

위의 방법으로 Humidity Feature를 이용했을 때 정보 이득을 구하면 아래와 같음.
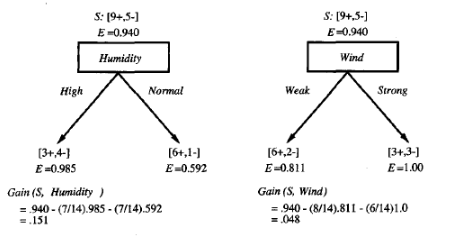
둘을 비교해보면 Humidity를 이용해서 S 집합을 분류할 때가 Wind를 이용해서 분류할 때보다 정보 이득이 크다는 것을 알 수 있으며 같은 방식으로 모든 Feature에 대해서 정보 이득을 구하면 아래와 같음.

이 때, 정보이득이 가장 큰 Feature를 최우선 분할 속성으로 지정한 후 그 다음으로 정보이득이 큰 Feature를 차선 분할 속성으로 지정하는 방식으로 분할을 계속함.
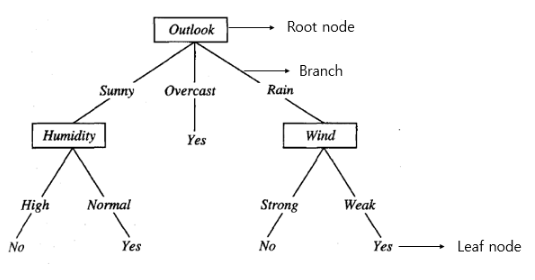
의사결정나무 학습 알고리즘의 핵심은 가장 큰 정보이득을 가지는 Feature를 가장 Root Node에 가깝게 하는 것!
4.2.2 정보이득률
만약 의사결정나무의 결과가 각 Leaf Node마다 한 개의 샘플만을 포함하고 있다면 이 Leaf Node의 순도는 이미 최고치에 도달하였을 뿐 아니라 일반화 성능이 매우 저조하고, 새로운 샘플에 대해 유효한 예측을 할 수 없음.
실질적으로 정보 이득 규칙은 취할 수 있는 값의 수가 비교적 많은 속성에 유리하게 작용하며, 이러한 편향이 모델에 좋지 못한 영향을 끼질 수 있음.
의사결정트리 방법 중 하나인 C4.5는 정보 이득을 사용하는 대신에 정보이득률(Information Gain Rate)이라는 방법을 사용하여 최적의 분할 속성을 선택함.
위 식에서 속성 a의 내재값은 아래와 같이 계산
따라서 속성 a가 취할 수 있는 값의 수가 많아질수록(V가 커질수록), IV(a)의 값은 커지게 됨.
여기서 주의해야할 점은 이득률 규칙은 취할 수 있는 값의 수가 비교적 적은 속성에 편향되어 있다는 것이며 따라서 C4.5 알고리즘은 이득률이 가장 크도록 속성 분할을 진행하는 방법을 사용하지 않음.
C4.5 알고리즘은 휴리스틱한 방법을 사용하여 분할 속성 후보 중 정보 이득이 평균 수준보다 높은 속성을 찾아내 그 중에서 이득률이 가장 높은 것을 선택함.
4.2.3 지니계수
CART 의사결정나무는 지니계수(Gini Index)를 사용하여 분할 속성을 선택함.
직관적으로 는 데이터 세트 에서 임의의 두 개의 샘플을 고르고, 고른 두 개의 샘플이 서로 다른 클래스일 확률을 나타냄. 따라서 가 낮을수록 데이터 세트 의 순도가 증가함.
따라서 우리는 후보 속성 집합 A에서 분할 후 지니계수가 가장 작은 속성을 최적의 분할 속성으로 선택함. 즉 모든 속성들에 대해서 지니계수를 계산한 후 지니계수가 작은 순서로 나눌 때 불순도가 가장 낮아진다고 볼 수 있음.
🔎 수식으로 표현하면,
가 됨.
4.3 가지치기(Pruning)
가지치기는 의사결정나무 학습 알고리즘에서 과적합에 대응하기 위한 주요 수단임. 의사결정나무 학습에서 최대한 정확한 훈련 샘플의 분류를 위해 노드에 대한 분할과정이 지속적을 반복 되는데, 때로 과도한 반복은 가지 수를 지나치게 많이 만들어버림.
이때 발생할 수 있는 문제는 훈련 샘플을 '너무 잘 학습하여 훈련 세트 자체의 어떤 특징들을 모든 데이터가 가지고 있는 일반적인 특성을 착각하게 만드는' 과적합이며, 따라서 자발적으로 가지를 잘라 과적합 위험을 방지할 수 있도록 해야 함.
💡 가지치기란?
의사결정나무에서 과적합을 방지하기 위해 적절한 수준에서 Terminal Node를 결합해 주는 것
4.3.1 사전 가지치기(Pre-Pruning)
사전 가지치기는 의사결정나무가 다 자라기 전에 알고리즘을 멈추는 방법임. 예를 들어 모든 인스턴스가 하나의 클래스에 속하거나 속성값이 같아지면 멈추게 됨. 또는 연구자가 임의로 설정한 숫자보다 인스턴스가 적어지면 나무 그리기를 멈춘다거나 역시 연구자가 임의로 불순도 정도를 설정하여 해당 지니 계수/ 엔트로피에 도달하면 나무 그리기를 멈춤.
4.3.2 사후 가지치기(Post-Pruning)
사후 가지치기는 일단 의사결정나무를 끝까지 그린 후 밑에서부터 가지를 쳐나가는 방법임. 이 때 검증 데이터를 사용하거나 일반화 오차를 예측하며, 만약 일반화 오차가 가지를 친 후 더 좋아진다면 Sub Tree를 Leaf Node로 대체함.
🔎 앞서 소개했던 CART 알고리즘에서 사후 가지치기로 Cost-Complextiy 라는 개념이 나오는데, 식은 다음과 같음.
- CC(T) : Tree의 비용 복잡도
- Err(T) : 오분류율(불순도)
- L(T) : Terminal Node의 수(= 구조 복잡도)
- : Err(T)와 L(T)를 결합하는 가중치(= Complexity Parameter)
여기서 는 Complexity Parameter로 나무의 복잡도를 조정함. 가 커지면 의사결정나무의 Terminal Node가 조금만 많아도 값이 커져버리기 때문에 가지를 많이 쳐내서 단순한 모델을 만들게 되며, 반대로 이 값이 작아진다면 Terminal Node가 많아도 값이 커지지 않기 때문에 조금 더 복잡한 모델이 만들어지게 됨.
.
.
.
Reference
- 단단한 머신러닝 - 머신러닝 기본 개념을 제대로 정리한 인공지능 교과서, Zhou Zhihua
- https://sanghyu.tistory.com/8
