- 단지별 등록 차량 수에 영향을 미치는 요인을 분석
1일차
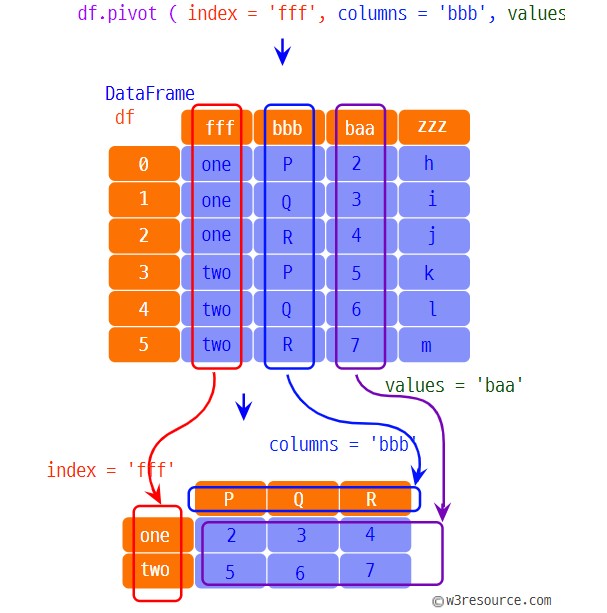
pivot 사용
- 데이터의 열을 기준으로 피벗테이블로 변환시키는 메서드
- DataFrame.pivot(index=None, columns=None, values=None)
code_residents = cut_data.pivot(index='단지코드', columns='전용면적 구간', values='전용면적별세대수') code_residents.reset_index(inplace=True) code_residents.head() => 전용면적 구간 단지코드 전용면적_0_30 전용면적_30_40 전용면적_40_50 전용면적_50_60 전용면적_60이상 0 C0001 0 0 0 78 0 1 C0002 35 0 0 0 0 2 C0003 0 0 0 88 0 3 C0004 0 0 0 150 327 4 C0006 15 0 0 0 0
- 평균 임대보증금/임대료 구하는데 예시파일에는 그냥 평균을 구했고(행별로 나눠서), 필자는 가중평균해서 구해야한다고 생각.
(ex. 3개의 세대의 임대료가 5000이고, 1개의 세대가 6000이라 가정.
임대료 5000인 행과 6000인 행 2개가 존재.
그럼 단지의 임대료 평균은 (5000+6000)/2가 아닌,
(5000*3+6000)/(3+1)과 같이 가중평균으로 구해야 맞다 생각하여 가중평균으로 구해야한다고 생각을 함.)
# 단지별 평균 임대보증금 def average_deposit(dataframe): results = [] for code in dataframe['단지코드'].unique(): filtered_data = dataframe[dataframe['단지코드'] == code] total_deposit = (filtered_data['전용면적별세대수'] * filtered_data['임대보증금']).sum() total_units = filtered_data['전용면적별세대수'].sum() average_deposit = total_deposit / total_units results.append({'단지코드': code, '평균 임대보증금': average_deposit}) return pd.DataFrame(results) average_deposits = average_deposit(data1_detail) average_deposits['평균 임대보증금'] = average_deposits['평균 임대보증금'].round(2) average_deposits.head()
joblib 라이브러리
- 여러 데이터 자료형과 학습한 모델, 피팅한 전처리 함수들을 저장할 수 있다는 이점이 있다.
- dump : 저장 --> joblib.dump(data, 'data_df.pkl')
- load : 불러오기 --> joblib.load('data_df.pkl')
2일차
숫자형 변수 간 상관계수 시각화(히트맵)
- 숫자형 변수들만 받아온 후, df.corr()로 상관계수 계산
- 계산한 상관계수 값들을 저장한 후, heatmap으로 상관계수 시각화
numeric_only_df = base_data.select_dtypes(include='number') corr_matrix = numeric_only_df.corr() plt.figure(figsize=(10,8)) sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', linewidths=0.5) # annot=True -> 실제 값(상관계)을 표시한다는 의미 plt.title('숫자형 변수 간 상관계수 히트맵') plt.show()
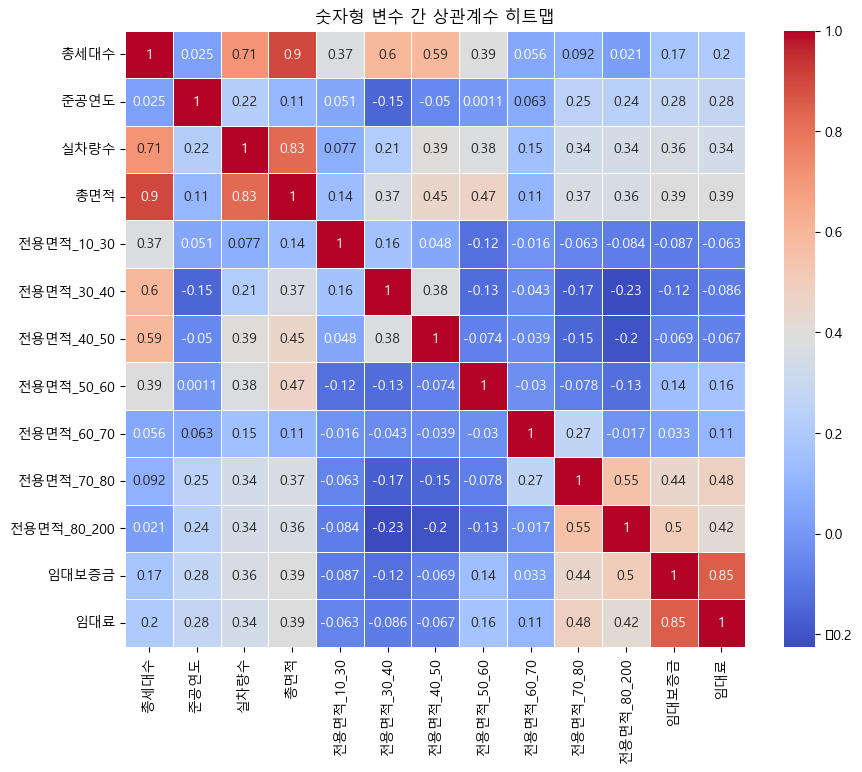
--> 총세대수와 총면적이 강한 상관관계를 보이고 있음을 확인(target은 총차량수)
- 기존 컬럼(feature)외에 다른 추가적인 변수 설정해 상관계수와 산점도로 확인해보았지만 강한 상관관계는 아님을 확인
ex. 세대별 평균 면적 -> 총면적 / 총세대수
('세대별 면적이 크면 세대별 주차 가능 차량수가 많다'라는 가정하에)
면적별 임대보증금/임대료 -> 임대보증금 or 임대료 / 총면적
('땅값이 비싸면 세대별 주차 가능 차량수가 많다'라는 가정하에)
아쉬웠던 점
-
결측치 처리를 어떻게 할 지에 대해 제대로 의논을 못함(시간적 여유X)
- 준공연도, 승강기설치여부, 건물형태, 임대보증금/임대료 등 값이 0이거나 값이 없는 혹은 값이 너무 동떨어진 결측치들이 존재.
- 단순 삭제를 하자는 의견이 대체였는데, 도메인을 조금 더 정확히 파악하여 단순 삭제가 아닌 다른 방식으로 결측치를 대체하는 방안이 더 낫지 않을까라는 생각을 하였음
- 단순 삭제말고 결측치를 채우는 방안들에도 여러 가지 방법들이 존재
- ex. 보간법(interpolate), SimpleImputer(평균/중앙값 등 특정 값으로 대체), KNNImputer(KNN알고리즘 통해 대체) 등등)
-
제한된 시간때문에 추가적으로 시도/분석해고픈 feature가 있었으나 하지 못함
- target인 총차량수와 강한 상관관계를 가진 총세대수/총면적을 가지고 지역별로, 준공연도별로 분석하고자 했으나 하지 못함
- 준공연도나 지역을 좀 더 구간을 나누어(지역은 수도권, 전라권, 충청권... 혹은 광역시/특별시/도 와 같은 방식으로) target과의 상관관계를 파악해보았으면 어땠을까라는 생각.
