이번 기회를 경험으로 6개월 정도 제대로 준비해보기.
영어도 제대로 준비할 것!
recruitement process
1.Recruiter screen
2.Technical phone interview (09/19)
2.1 chat for catching up interview (09/20) interviewer feedback 전달 받음. 불합격. 다음 라운드를 통과하기엔 어려워 보임. 좀 더 연습하고 충분하다고 생각되면 다시 연락달라.
3.Onsite interview (5 sessions with 4x DS/Algo, 1x Googleness and leadership)
4.Hiring committee review
5.Hiring manager team match
6.offer review
7.offer delivery
Amazon
1.Recruiter screen
2.Online Assessment (08/28)
3.Technical Phone Screen (09/14)
4.virtual final onsite interview (09/24, 10/03)
5.hiring committe review
일정
8/28 Online Assessment(Amazon)
- 2문제 출제. leetcode medium, hard 수준
- 2문제 pass
9/14 Technical Phone Screen(Amazon)
- 별도 페이지 작성.
9/19 Technical phone interview(Google Korea)
void start(number)
int getAck()
void send()
// 함수 구현 문제.
IDE 아니고 노트패드 같은 것(google interview doc)에 손 코딩.
테스트 시나리오
start(10)
getAck() // return 10
send(10)
getAck() // return 11
send(12)
send(13)
getAck() // return 11
send(11)
getAck() // return 14
1차 구현 후 효율관점에서 개선 요청
not improving time complexity
data structure => list -> dictionary -> set
send() 가 무수히 많이 불리고 getAck() 매우 적게 불리는 상황에서 최적화 요청
최적의 solution 을 제안하지 못 했다고 feedback 받음.
solution 제안 시간도 좀 더 빨라야 할 듯.
recruitor 로 부터 면접관 피드백 전달 받음. 다음 단계를 간다고 해도 쉽지 않을 거라고 함. 좀 더 준비해서 자신있다고 생각될 때 이어서 진행하는 게 어떠냐고 제안함(?). 탈락!
준비
leetcode 75
-
https://leetcode.com/list?selectedList=eqpfz2de (68 problems without premium)
array (7/10)15.3sum152.maximum product subarray (DP?)217.contains duplicate (hashtable?)
binary (3/5)190.reverse bits371.sum of two integers bit manipulation pattern
dp (10/10)55. jump game not dp. greedy..91. decode ways memoization + branching '0', '1'and '2' case139. wordbreak bottom-up style.dp[x+k] = dp[x]
graph (3/5)200.number of islands dfs with set207.course schedule
- heap (2/3)
interval (0/3)linkedlist (4/6)matrix (3/4)string (6/9)49.group anagrams76.minimum window substring sliding window pattern. right pointer to expand, left pointer to contract424.longest repeating character replacement sliding window pattern.
tree (14/14)102.binary tree level order traversal bfs105.construct binary tree from preorder and inorder traversal WIP. see NeetCode video124.binary tree maximum path sum WIP212.word search II WIP. Trie + dfs, see NeetCode video235.lowest common ancestor of a binary search tree WIP. binary search tree 특징 이용하여 traverse 방향 결정. dfs297. serialize and deserialize binary tree572.subtree of another tree WIP. dfs
기타
- 1996. The Number of Weak Characters in the Game bucket sort, greedy
14 patterns to ace any coding interview question
- Sliding window
- Two pointers
- fast and slow pointers
- merge intervals
- cyclic sort
- in-place reversal of linked list
- tree bfs
- tree dfs
- two heaps
- subsets
- modified binary search
- top k elements
- k-way merge
- topological sort
grokking 14 patterns of coding interview
- https://www.educative.io/courses/grokking-the-coding-interview
- https://github.com/cl2333/Grokking-the-Coding-Interview-Patterns-for-Coding-Questions
Top amazon questions by frequency
- Two Sum
- LRU Cache
- Trapping Rain Water
- Number of islands
- Merge intervals
- Product of Array except self
- Integer to English words
- 253 Meeting Rooms II
- Minimum Difficulty of a job schedule
- K closest points to origin
- maximal sqaure
- insert delete getrandom O(1)
- critical connections in a network
- robot bounded in circle
- design in-memory file system
- find median from data stream
- partition labels
- sliding window maximum
- number of provinces
- merge two sorted lists
- copy list with random pointer
- pairs of songs with total durations divisible by 60
- LFU cache
- Top k frequent words
- group anagrams
- reorder data in log files
- word break II
- rotting oranges
- construct binary tree from preorder and inorder traversal
- reorganize string
- analyze user website visit pattern
- word ladder
- binary tree zigzag level order traversal
- all nodes distance k in binary tree
- search 2d matrix II
- course schedule II
- word search II
- subtree of another tree
- design snake game
- asteroid collision
- concatenated words
- prison cells after n days
- number of distinct islands
- break a palindrome
- maximum area of a piece of cake after horizontal and vertical cuts
- most common word
- minimum cost to connect sticks
system design
- https://www.educative.io/courses/grokking-the-system-design-interview
- https://www.educative.io/courses/grokking-modern-system-design-interview-for-engineers-managers
System design problems
Designing an API Rate Limiter
- What is a Rate Limiter?
- Why do we need API rate limiting?
- Requirements and Goals of the System
Functional Requirements:
Limit the number of requests an entity
The APIs are accessible through a cluster
Non-Functional Requirements
The system should be highly available
Our rate limiter should not introduce substantial latencies
- How to do Rate Limiting?
Rate Limiting is a process that is used to define the rate and speed
Throttling is the process of controlling the usage of the APIs by customers during a given period. HTTP status “429 - Too many requests"
-
What are different types of throttling?
Hard Throttling
Soft Throttling
Elastic or Dynamic Throttling -
What are different types of algorithms used for Rate Limiting?
-
High level design for Rate Limiter
-
Basic System Design and Algorithm
-
Sliding Window algorithm
-
Sliding Window with Counters
-
Data Sharding and Caching
-
Should we rate limit by IP or by user?
Designing a URL shortening service like TinyURL
- Why do we need URL shortening?
- Requirements and Goals of the System
- Capacity Estimation and Constraints
- System APIs
- Database Design
Database Schema: - Basic System Design and Algorithm
a. Encoding actual URL
b. Generating keys offline - Data Partitioning and Replication => consistent hashing
- Cache
- Load Balancer (LB)
- Purging or DB cleanup
- Telemetry
- Security and Permissions
Designing Dropbox
- Why Cloud Storage?
- Requirements and Goals of the System
- Some Design Considerations
- Capacity Estimation and Constraints
- High Level Design
- Component Design
a. Client
b. Metadata Database
c. Synchronization Service
d. Message Queuing Service
e. Cloud/Block Storage - File Processing Workflow
- Data Deduplication
- Metadata Partitioning
- Caching
- Load Balancer (LB)
- Security, Permissions and File Sharing
Designing Youtube or Netflix
- Why Youtube?
- Requirements and Goals of the System
- Capacity Estimation and Constraints
- System APIs
- High Level Design
- Database Schema
- Detailed Component Design
- Metadata Sharding
Since we have a huge number of new videos every day and our read load is extremely high, therefore, we need to distribute our data onto multiple machines so that we can perform read/write operations efficiently. We have many options to shard our data. Let’s go through different strategies of sharding this data one by one:
Sharding based on UserID
This approach has a couple of issues:
- What if a user becomes popular? There could be a lot of queries on the server holding that user; this could create a performance bottleneck. This will also affect the overall performance of our service.
- Over time, some users can end up storing a lot of videos compared to others. Maintaining a uniform distribution of growing user data is quite tricky.
To recover from these situations, either we have to repartition/redistribute our data or used consistent hashing to balance the load between servers.
Sharding based on VideoID
Our hash function will map each VideoID to a random server where we will store that Video’s metadata.
This approach solves our problem of popular users but shifts it to popular videos.
We can further improve our performance by introducing a cache to store hot videos in front of the database servers.
-
Video Deduplication
-
Load Balancing => should use Consistent Hashing among cache servers.
will also help in balancing the load between cache servers. -
Cache
-
Content Delivery Network (CDN)
A CDN is a system of distributed servers that deliver web content to a user based on the user’s geographic locations, the origin of the web page, and a content delivery server. -
Fault Tolerance => should use Consistent Hashing
Consistent hashing will not only help in replacing a dead server but also help in distributing load among servers.
Design Basics
Key characteristics of distributed systems
Scalability
Horizontal vs. Vertical Scaling,
Horizontal example: Cassandra and MongoDB
vertical example: mysql
Reliability
redundancy
Availability
Efficiency
Serviceability or manageability
Load Balancing
Caching
Load balancing helps you scale horizontally across an ever-increasing number of servers, but caching will enable you to make vastly better use of the resources you already have as well as making otherwise unattainable product requirements feasible.
Application server cache#
Content Delivery (or Distribution) Network (CDN)
Cache Invalidation
if the data is modified in the database, it should be invalidated in the cache; if not, this can cause inconsistent application behavior.
Cache eviction policies
First In First Out (FIFO): The cache evicts the first block accessed first without any regard to how often or how many times it was accessed before.
Last In First Out (LIFO): The cache evicts the block accessed most recently first without any regard to how often or how many times it was accessed before.
Least Recently Used (LRU): Discards the least recently used items first.
Most Recently Used (MRU): Discards, in contrast to LRU, the most recently used items first.
Least Frequently Used (LFU): Counts how often an item is needed. Those that are used least often are discarded first.
Random Replacement (RR): Randomly selects a candidate item and discards it to make space when necessary.
Data partitioning
Data partitioning is a technique to break a big database (DB) into many smaller parts.
a. Horizontal Partitioning
we put different rows into different tables
The key problem with this approach is that if the value whose range is used for Partitioning isn’t chosen carefully, then the partitioning scheme will lead to unbalanced servers.
b. Vertical Partitioning
we divide our data to store tables related to a specific feature in their own server.
Vertical Partitioning is straightforward to implement and has a low impact on the application.The main problem with this approach is that if our application experiences additional growth, then it may be necessary to further partition a feature specific DB across various servers
c. Directory-Based Partitioning
This loosely coupled approach means we can perform tasks like adding servers to the DB pool or changing our partitioning scheme without having an impact on the application.
Partitioning Criteria
a. Key or Hash-based Partitioning
b. List partitioning
c. Round-robin partitioning
d. Composite Partitioning
indexes
proxies
redundancy and replication
Redundancy is the duplication of critical components or functions of a system with the intention of increasing the reliability of the system
Replication means sharing information to ensure consistency between redundant resources, such as software or hardware components, to improve reliability, fault-tolerance, or accessibility.
SQL vs. NoSQL
SQL: relational, structured and predefined schemas
NoSQL:non-relational databases, unstructured, distributed, dynamic schema
NoSQL
- key-value stores. Redis, Voldemort and Dynamo
- document database: data is stored in documents and documents are grouped in collections. CouchDB, MongoDB
- wide-column database: instead of 'tables', in columnar databases we have column families, which are containers for rows. best suited for analyzing large datasets, Cassandra and HBase
- graph database: used to store data whose relations are best represented in a graph. data is saved in graph structures with nodes, properties and lines. Neo4J and InfiniteGraph.
differences between SQL and NoSQL
Querying: SQL use SQL for defining and manipulating the data which is very powerful.
NoSQL, queries are focused on a collection of documents. called UnQL(Unstructured Query Language)
Scalability: NoSQL databases are horizontally scalable, we can add more servers easily
Reliability or ACID (Atomicity, Consistency, Isolation, Durability):relational databases are ACID compliant.
Most of the NoSQL solutions sacrifice ACID compliance for performance and scalability.
SQL VS. NoSQL - which one to use?
Reasons to use SQL database
- ACID compliance
- data is structured and unchaning
Reasons to use NoSQL database
- storing large volumes of data have littel to no structure.
- making the most of cloud computing and storage
- rapid development. NoSQL is extremely useful for rapid development
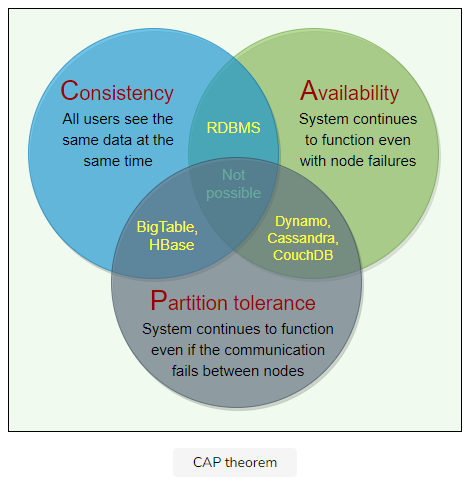
CAP(Consistency, Availability, Partition tolerance) Theorem
it is impossible for a distributed system to provide all three of the following desirable properites:
Consistency(C): All nodes see the same data at the same time
Availability(A): refers to a system's ability to remain accessible even if one or more nodes in system go down.
Partition tolerance(P): partition is a communication break(or a network failure) between any two nodes in the system.
According to the CAP theorem, any distributed system needs to pick two out of the three properties.
In the presence of a network partition, a distributed system must choose either Consistency or Availability.
PACELC Theorem (new)
Consitent Hashing (new)
Data partitioning: It is the process of distributing data across a set of servers. It improves the scalability and performance of the system.
Data replication: It is the process of making multiple copies of data and storing them on different servers. It improves the availability and durability of the data across the system.
Data partition and replication strategies lie at the core of any distributed system
Distributed systems can use Consistent Hashing to distribute data across nodes. Consistent Hashing maps data to physical nodes and ensures that only a small set of keys move when servers are added or removed.
Consistent Hashing stores the data managed by a distributed system in a ring.
Virtual nodes
Instead of assigning a single token to a node, the hash range is divided into multiple smaller ranges, and each physical node is assigned several of these smaller ranges. Each of these subranges is considered a Vnode. With Vnodes, instead of a node being responsible for just one token, it is responsible for many tokens (or subranges).
Consistent Hashing use cases
Amazon’s Dynamo and Apache Cassandra use Consistent Hashing to distribute and replicate data across nodes.
Long-polling vs websockets vs server-sent events
bloom filters (new)
quorum (new)
leader and follower (new)
heartbeat (new)
Heartbeating is one of the mechanisms for detecting failures in a distributed system. If there is a central server, all servers periodically send a heartbeat message to it. If there is no central server, all servers randomly choose a set of servers and send them a heartbeat message every few seconds. This way, if no heartbeat message is received from a server for a while, the system can suspect that the server might have crashed. If there is no heartbeat within a configured timeout period, the system can conclude that the server is not alive anymore and stop sending requests to it and start working on its replacement.
checksum (new)
Background
How can a distributed system ensure data integrity, so that the client receives an error instead of corrupt data?
Solution
Calculate a checksum and store it with data.
When a system is storing some data, it computes a checksum of the data and stores the checksum with the data. When a client retrieves data, it verifies that the data it received from the server matches the checksum stored. If not, then the client can opt to retrieve that data from another replica.