
🔎머신러닝의 정의
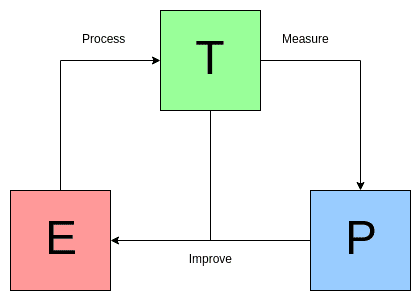
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E. (Mitchell, 1997)
Mitchell의 정의에 의하면 머신러닝은, 작업 T를 수행하기 위한 경험 E로부터 획득한 데이터를 기반으로 모델을 자동으로 구성하여 성능 P를 향상시킬 수 있는 컴퓨터 프로그램이다.
핵심적으로 데이터를 재료로 하여 자동적으로 일정한 규칙을 생성하고, 이 규칙을 기반으로 일정한 문제를 해결하는 것에 초점을 둔 기술이다.
- Feature Extraction (사람 전문가가 결정)
- 학습 데이터 수집 ▶ Feature Vecor화
- 알고리즘 학습 = 모델 형성
- Inference / Prediction (모델 적용)
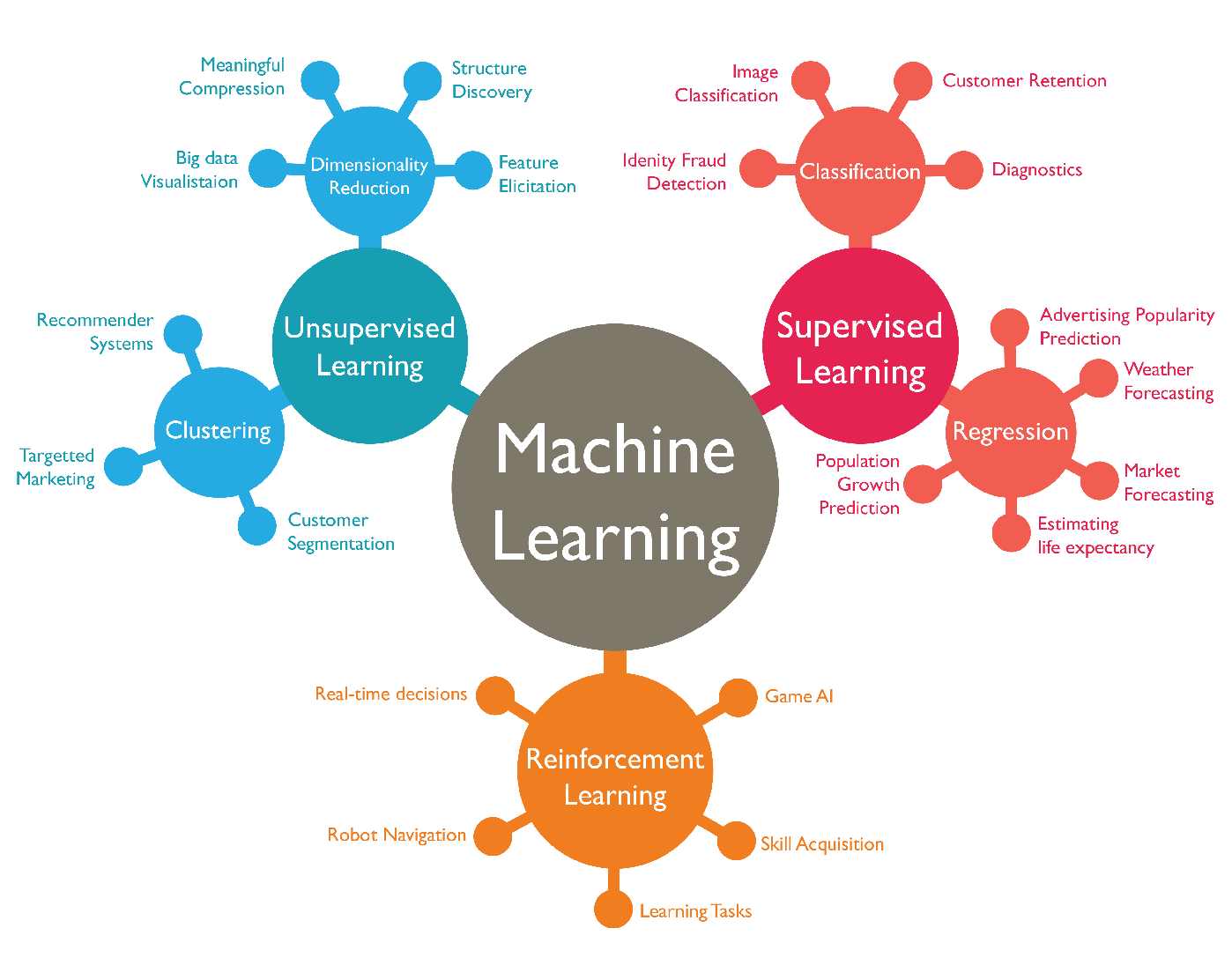
🔎머신러닝의 종류
머신러닝으로 해결 가능한 문제들은 다음과 같은 특징을 갖는다. 명시적 문제 해결 지식의 부재하거나, 프로그래밍이 어려운 문제, 지속적으로 변화하는 문제들이다. 또한 아래와 같은 3가지의 알고리즘으로 분류된다.
- 지도학습(Supervised Learning)
- 비지도 학습(Unsupervised Learning)
- 강화학습(Reinforcement learning)
🔎지도학습
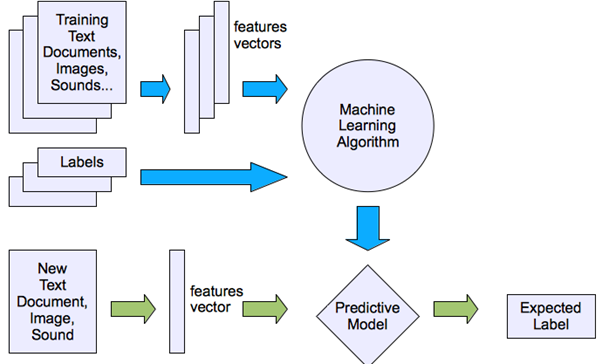
모델을 학습하는 과정에서 데이터와 정답(label)을 함께 제공한다. 입력값에 대응되는 정답 데이터가 항상 존재한다. 크게 학습(Training) 단계와 적용(Inference/Prediction) 단계로 나뉠 수 있다. 학습 단계에서는 주어진 데이터(Input Data)에서 특징(Feature)을 추출하고, 추출된 Feature Vector과 Label을 통해 자동으로 모델을 구성한다. 적용 단계에서 이 모델(Predictive Model)을 기반으로 예측가능한 정답(Label)을 얻는다. 지도학습의 종류로는 분류(Classification), 회귀(Regression)이 있다.
🔔분류(Classification)
주어진 데이터를 정해진 카테고리에 따라 분류해야 하는 문제를 말한다. 예측해야 하는 출력이 미리 정해져 있는 값(finite set of values)일때 사용한다. 둘 중 하나로 분류하는 이진분류와 여러값 중 하나로 분류하는 다중 분류로 나뉜다.
다음과 같은 실생활의 문제에 적용 가능하다.
- 스팸 메일 분류
- 기사 분야 분류
- 이미지 분류
- 인종 분류
- 질병 종류 분류
🔔회귀(Regression)
예측해야 하는 출력이 number(continuous value)인 문제들을 말한다. 데이터들의 특징(Feature)을 토대로 입력에 대한 출력값을 예측한다.
다음과 같은 실생활의 문제에 적용 가능하다.
- 주가 예측
- 기대 수명 예측
- 예상 가격 예측
🔔지도학습 알고리즘
다음은 지도학습(분류와 회귀)에서 사용되는 알고리즘들이다.
- Naive Bayesian
- K-nearest neighbors
- Linear Regression
- Logistic Regression
- Multinomial Logistic Regression
- Suport Vector Machine
- Decision Tree
- Random Forest
- MLP (⊂Neural Network)
🔎비지도학습
비지도 학습이란 정답 라벨이 없는 데이터를 기반으로 학습시키는 것이다. 해결해야 하는 문제의 종류도 정답(Label)이 존재하지 않는다. 비슷한 특징을 갖는 것 끼리 묶어 새로운 데이터에 대한 결과를 예측한다. 데이터의 패턴이나 형태를 찾는 것에 집중한다. 지도 학습의 전처리 방법으로 사용하기도 한다.
🔔군집화(Clustering)
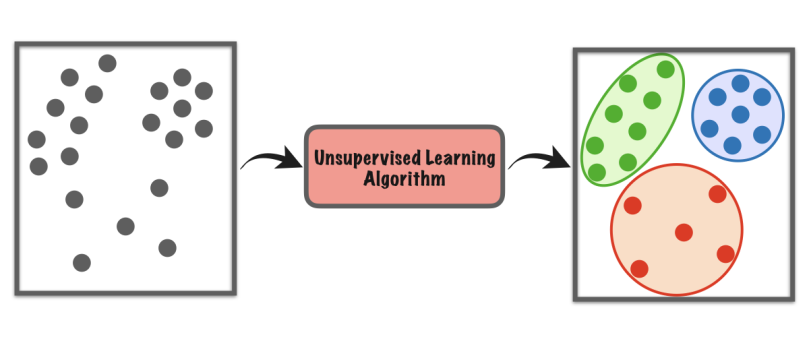
주어진 데이터 집합을 유사한 데이터들끼리 묶어 내는 작업을 군집화(Clustering)라 하고 이렇게 나누어진 유사한 데이터의 그룹을 군집(Cluster)이라 한다.
원래 데이터가 어떻게 군집화되어 있었는지를 보여주는 정답(groundtruth)이 있다고 하더라도, 성능 기준을 만드는 것은 분류 문제보다 더 까다롭다. 애초에 정답 레이블이 존재하지 않기 때문이다. 다음은 실제 군집화의 성능을 파악하기 위해 사용되는 기준들이다.
- 조정 랜드지수(Adjusted Rand Index)
- 조정 상호정보량 (Adjusted Mutual Information)
- 실루엣계수 (Silhouette Coefficient)
🔔연관규칙(Association)
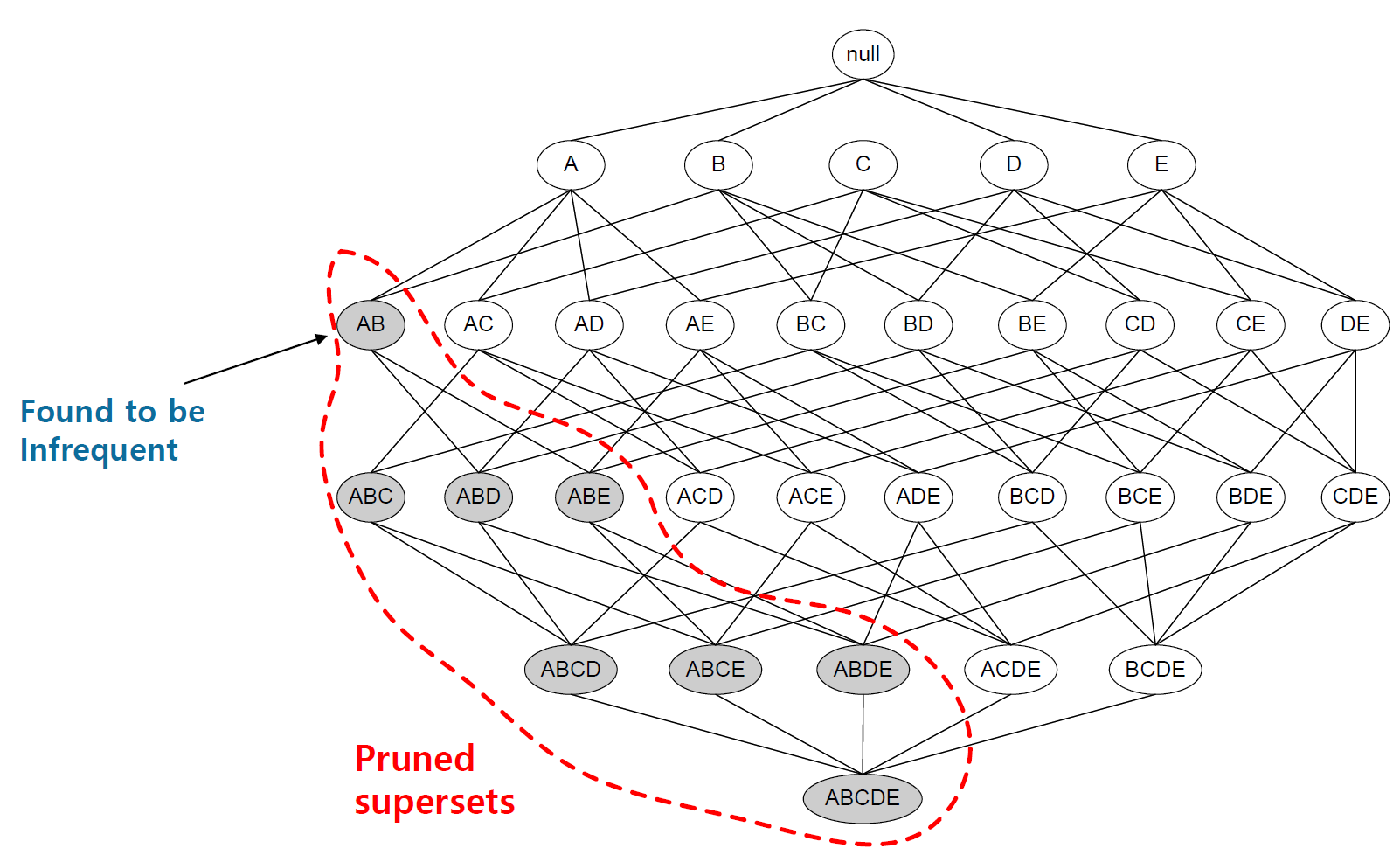
연관규칙(association rule) 학습은 대형 데이터베이스에서 변수 간의 흥미로운 관계를 발견하기 위한 규칙-기반 기계 학습 방법이다. 이것은 흥미로운 측도를 사용하여 데이터베이스에서 발견된 강력한 규칙을 식별하기 위한 것이다.
Agrawal 등(1993)은 강력한 규칙의 개념을 바탕으로 슈퍼마켓 POS(point-of-sale) 시스템에서 기록한 대규모 거래 데이터에서 제품 간의 규칙성을 발견하는 연관 규칙을 소개하였다. 예를 들어,슈퍼마켓의 판매 데이터에서 발견된 “{양파, 감자} ⇒ {버거}” 규칙은 고객이 양파와 감자를 함께 구매하면 햄버거 고기도 사기 쉽다는 것을 알 수 있다.
🔔비지도학습 알고리즘
다음은 비지도학습(군집화와 연관규칙)에서 사용되는 알고리즘들이다.
- K-means
- Spectral Clustering
- Hierarchical Cluster Analysis
- Affinity Propagation Clustering
- DBSCAN Clustering
- Expectation Maximization
- Dimensionality Reduction
- Principal Component Analysis
- Kernel PCA
- Visualization
- Locally-Linear Embedding
- t-distributed Stochastic Neighbor Embedding
- Apriori
- Eclat
- FP-Growth
