조인
둘 이상의 테이블을 연결하는 것
- inner join : 공통 부분(교집합) 선택됨
- left outer join : 공통 부분 + left쪽 테이블
- right outer join : 공통 부분 + right쪽 테이블
- full outer join: 왼쪽 테이블과 오른쪽 테이블 모두
서브쿼리
쿼리 내부에 중첩된 쿼리를 말한다.
서브쿼리가 복수 개의 row를 return하면 ?
서브쿼리가 복수개의 row를 return 할 경우 대응되는 왼쪽의 컬럼에 in을 사용하면 된다.
항상 단 1개의 row만 return 될 경우에만 =를 쓴다.
-- 1개의 row
select ... from ... where price = (서브쿼리);
-- 2개 이상의 row, 가변적일 때
select ... from ...
where (bookid, bookname) in (select bookid, bookname from book); -- 복수개의 row return복수 개의 row를 return할 경우 in을 사용하여 where 조건을 받아야 하고,
서브 쿼리의 return column과 대응되는 왼쪽의 컬럼의 수가 맞지 않으면 갯수를 동일하게 맞춰 줘야 한다. (bookid, bookname)
서브쿼리와 조인
서브쿼리와 조인을 통해 같은 결과를 보여지게 만들 수 있다.
하지만 중복을 제거해야 할 부분이 있는지 생각해야 한다.
-- 서브쿼리
select customer.name from customer where custid in (select custid from orders);
-- 조인(중복 제거 해야됨)
select distinct customer.name from customer, orders where customer.custid = orders.custid;중복을 제거할 부분이 있는지 확인하고 distinct를 사용해 중복 제거를 해야 같은 결과가 나올 수 있다.
또한 아래 코드와 같이 성능면에서 서브쿼리를 메인쿼리에서 distinct를 써야 좋을지, 서브쿼리에서 distinct를 써야 좋을지 고민할 필요가 있다.
-- 중복이 가능한 서브쿼리라면 만약 서브쿼리가 500 고객이 2000번 주문한거면?
-- 서브쿼리에서 distinct를 사용하는 것이 나음
select customer.name from customer where custid in (select distinct custid from orders);서브쿼리 처리 과정
서브쿼리는 메모리에 적재한 후 처리된다.
하지만 서브쿼리가 메모리에 부담이 가는 크기면 I/O에 swaping 되면서 사용된다. (I/O disk swaping)
- 메모리에 적재된 이후 처리가 되므로 매우 빠르게 처리된다
- 동시에 메모리 자원을 낭비하게 된다.(성능이 안좋아지기도 함)
-> 메모리에 올라오는 서브쿼리 내용을 줄이면 성능이 좋아진다!
하지만!
swapping 되는 쿼리는 OLTP에서는 지양 해야 한다.
OLTP: 즉각적인 반응이 필요한 작업일 경우 I/O에 swap되는 쿼리를 만드는 것은 지양
OLAB: 오래 걸리더라도 확실하게 해야하는 작업(청구작업 등)
서브쿼리 종류
1. 스칼라
select 절에 위치하며, 한 레코드당 하나의 값을 반환하는 서브쿼리 (단일 행, 단일 컬럼을 반환)
- 컬럼의 역할을 하기 때문 !
SELECT 이름,(
SELECT 학생학점.학점
FROM 학생학점
WHERE 학생학점.학생ID = 학생.학생ID
)AS 학점
FROM 학생 WHERE 이름 = '김학생';2. 인라인 뷰
from 절에 위치하며, 결과는 반드시 하나의 테이블로 리턴되어야 한다.
- SQL문이 실행될 때 임시적으로 생성되는 동적인 뷰로 Dynamic View 라고 불림
- 쿼리 단순화, 가독성 향상
SELECT 이름, 학점
FROM (
SELECT 학생.학생이름, 학생학점.학점
FROM 학생, 학생학점
WHERE 학생.학생번호 = 학생학점.학생번호
AND 학생학점.학점 = 'A'
);3. 중첩 서브쿼리
where절에 위치하며, 결과 집합을 한정하기 위한 서브쿼리 (단일행, 다중행 반환)
SELECT 학생학점.학점
FROM 학생학점
WHERE 학생학점.학생번호 = (
SELECT 학생.학생번호
FROM 학생
WHERE 학생.이름 = '김학생'
)서브쿼리는 메인쿼리의 컬럼을 모두 사용할 수 있지만 메인쿼리는 서브쿼리의 컬럼을 사용할 수 없다.
질의 결과에 서브쿼리 컬럼을 표시해야 한다면 조인 방식으로 변환하거나, 함수, 스칼라를 사용해야 한다.
https://yunamom.tistory.com/353
Q. 장소를 보여주며 즐겨찾기 했던 내역을 같이 보여주려면 어떻게 해야 할까?
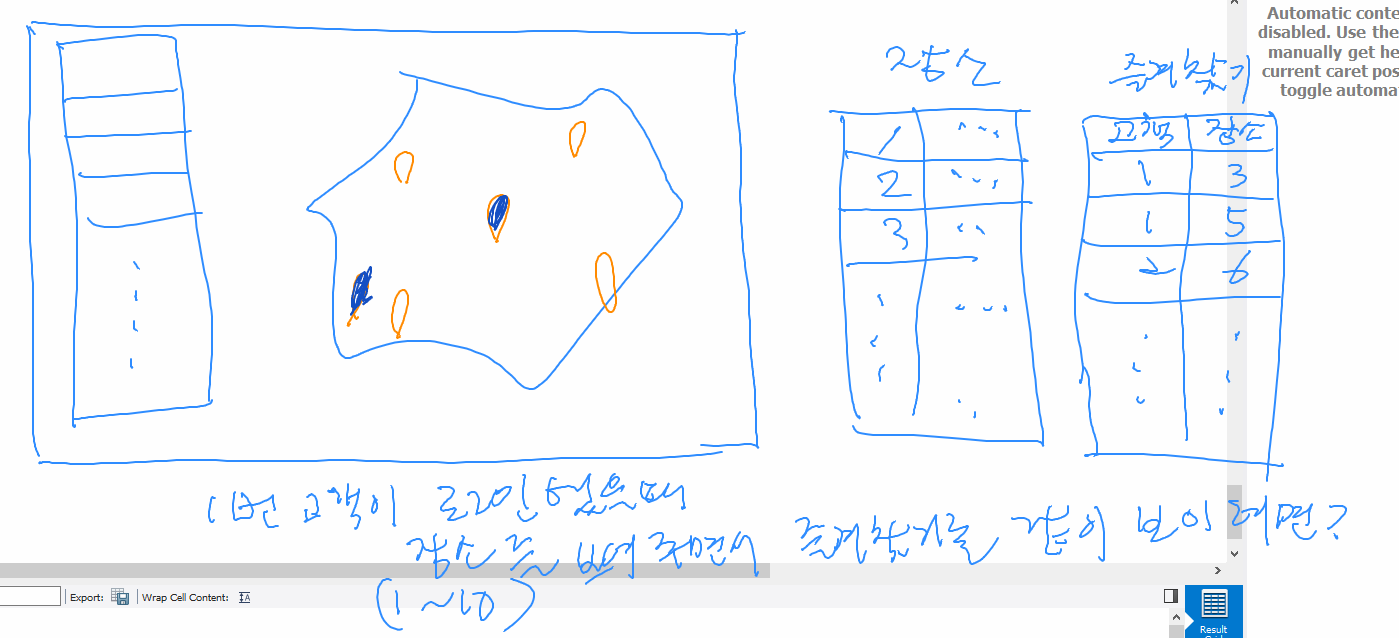
위와 같이 테이블이 있다고 가정한다.
| 장소 ID | 장소 이름 |
|---|---|
| 1 | 장소이름1 |
| 2 | 장소이름2 |
| 3 | 장소이름3 |
| 즐겨찾기ID | 고객ID | 장소 ID |
|---|---|---|
| 1 | 1 | 3 |
| 2 | 1 | 5 |
| 3 | 2 | 6 |
자세하게는 장소를 보여줄 때 즐겨찾기를 했던 내역을 같이 보여주려면 inner join으로 처리가 가능할까?의 질문이었다.
결론
즐겨찾기에 들어가 있지 않은 장소를 보여줘야 하기 때문에 left outer join을 사용해야 한다.
inner join을 사용하면 즐겨찾기에 없는 장소는 join 결과물에서 없는 장소로 뜰 것이기 때문이다.
[장소] left outer join [즐겨찾기] 형태로 처리해야 원래 보여주려던 장소 목록을 출력할 수 있다.
select ... from 장소 left outer join 즐겨찾기 where ... 만약 장소가 100만개, 즐겨찾기 1000만개라면 ?
위와 같이 하면 생성되는 카티션 프로덕트가 너무 많아지게 된다.
100만 x 1000만의 연산이 필요할 것이기 때문이다.
먼저 특정 조건에 맞게 추출하고 조인을 해야 성능이 좋아진다.
(조건에 맞게 추출하는 서브쿼리 사용 -> 각 서브쿼리에 대한 조인)
한 번에 화면에 10개의 row만 보여주게 된다면 아래와 같이 범위를 줄일 수 있다.--- 장소 ( 10개의 row로 줄임 ) select ... (화면에 보여줄 10개의 row만 먼저 추출) from 장소 where ....-- 즐겨찾기 ( 로그인 한 고객만 찾으면서 범위를 줄임 ) select ...(장소) from 즐겨찾기 where 고객 = 로그인한 고객
위와 같이 각각 별도로 추출한 후, left outer join을 해야한다. -> 서브쿼리 활용
select ... from
(select ... (화면에 보여줄 10개의 row만 먼저 추출) from 장소 where .... ,
select ...(장소) from 즐겨찾기 where 고객 = 로그인한 고객)
where 장소id = 장소id각 서브쿼리에 대해 위와 같이 최종 쿼리가 나올 수 있다.
+즐겨찾기 상태를 담는 컬럼을 만든다면 어떨까?
조별 토론 시간때도 나왔던 내용이기도 하고 내가 첫 프로젝트때 고민했던 내용이다.
좋아요 테이블을 (좋아요id, 병원id, 고객id, 좋아요 상태)로 만들면 되지 않을까? 생각했었다.
조별 토론때도 이 내용이 나와서 강사님께 여쭤봐서 답변을 받았다.
위 방식대로 하면 고객에 따라 좋아요 취소한 것들이 쌓여갈 것이기 때문에 garbage data가 너무 많아진다.
생각해보니 당연하다...( 난 바보 ) 사실 플젝에서도 아래와 같이 했었다 ㅎ
만약 좋아요 취소했던 내역을 보여준다면 좋아요 상태를 컬럼으로 가지는 것도 의미가 있다고 하셨다.
하지만 즐겨찾기 취소 테이블을 따로 만들어 관리하는 것이 효율적일 것이라 하셨다.
이 역시 garbage data 때문이라 생각한다.
성능
조인, 서브쿼리 등은 어떤 것이 성능이 좋다고 할 수 없이 DBMS, 키 구성 등에 따라 성능이 달라진다.
조인은 DBMS가 스스로 판단할 수 있지만 서브쿼리는 개발자가 코드 짜는 것에 따라 성능이 달라진다.
1. 일반적으로 조인이 서브쿼리보다 성능이 좋다
많은 경우의 수가 있지만 일반적으로 서브쿼리보다는 조인이 더 성능이 좋다.
하지만 서브쿼리도 execution plan을 실행시켜보며 최적의 쿼리를 선택하는 것이 좋다.
그래서 아래와 같은 순서로 쿼리 튜닝을 시도하면 좋다.
쿼리 튜닝 시도
1. 조인 시도
-> 느리면
2. 서브쿼리나 인덱스 활용하기
만약 서브쿼리로만 이루어진 것이 가장 빠르다면? (상대적으로)
select ... select ... select ...-> 각 서브쿼리의 결과가 작기 때문
그래서 서브쿼리를 사용하는 경우는 각 서브쿼리 결과물들이 작을 때, where절에서 버려도 되는 게 있을 때 유리하다
서브쿼리를 사용할 때 고려할 점
1. 불필요한 join 연산을 수행하지 않는지
2. join 시 불필요한 테이블 접근을 하지 않는지
2. 서브쿼리로 필터링 후 join을 하면 join 레코드 수가 줄어들어 성능이 좋아진다.
서브쿼리를 사용하여 group by 등으로 집약, 필터링을 거친 후에 join을 시도하는 것이 좋다.
집약, 필터링을 거쳐 조인을 하기 전에 데이터를 줄여주면 성능이 좋아진다는 의미이다.
-- join 후 group by(집약, 필터링) 사용
select a.co_cd, district, sum(emp_nbr) emp_nbr
from companies a
join shops b on a.co_cd = b.co_cd
where main_flg = 'Y'
group by 1,2
order by 1,2
-- 서브쿼리로 group by(집약, 필터링) 후 join
select a.co_cd, district, emp_nbr
from companies a
join (
select co_cd, sum(emp_nbr) emp_nbr
from shops
where main_flg = 'Y'
group by 1
) b
on a.co_cd = b.co_cd
order by 1,2위 코드는 아래 링크의 글을 참고하였다.
성능 관점에서 서브쿼리에 관해 잘 정리되어 있다.
아래 코드가 위 코드보다 실행할 row가 줄어들어 실행속도가 빨라지게 된다.
https://schatz37.tistory.com/3
데이터가 많아도 모두 조인하는 경우에는?
만약 A 테이블이 1억 개, B 테이블이 1억 개의 데이터를 가지고 있다면 직접 모두 조인하는 것은 너무 시간이 오래 걸릴 것이다.
하지만 조건을 줄 때 키 값이나 인덱스, unique 같은 것으로 하면 그래도 비교적 빠르게 수행된다.
여기서 키 값은 기본 키, 외래키 등이 될 것이다.
만약 위에 해당하지 않는 컬럼을 주면 엄청 느리게 수행될 것이다. (1억+@ ~ 거의 1억 x 1억)

각 예제와 Execution plan 비교 및 판단해보기
- 이 아래에는 예제와 Execution plan으로 성능을 판단해보는 것을 적었다.
3개의 테이블 서브쿼리, 조인
customer, orders, book 3개의 테이블에 대해 서브쿼리, 조인을 사용해보기.
아래와 같은 방법으로 표현할 수 있다.
비교
- 3개의 테이블 모두 서브 쿼리 사용
-- 3개의 테이블을 모두 사용(SubQuery)
select name from customer where custid in (
select custid from orders where bookid in (
select bookid from book where publisher = '대한미디어'
)
);- 2개의 테이블 조인 후 서브쿼리 사용
-- orders, book join
-- 2개의 테이블 조인 후 서브 쿼리로 사용
select name from customer where custid in (
select o.custid from orders o, book b
where o.bookid = b.bookid and b.publisher = '대한미디어'
);- 3개의 테이블 모두 조인
-- customer, orders, book 모두 조인
select c.name from customer c, orders o, book b
where c.custid = o.custid and o.bookid = b.bookid and b.publisher = '대한미디어';execution plan 비교
- 3개의 테이블 모두 서브 쿼리 사용 - 4.05
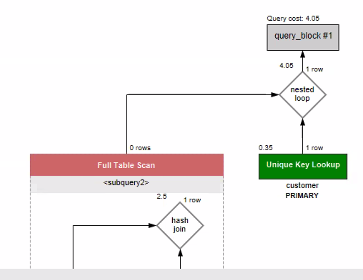
- 2개의 테이블 조인 후 서브쿼리 사용 - 4.05
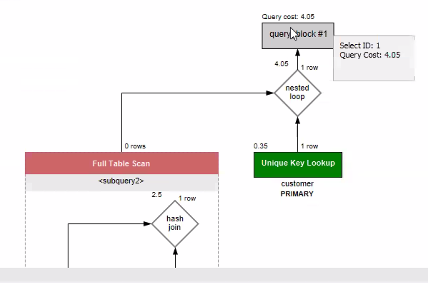
- 3개의 테이블 모두 조인 - 2.85
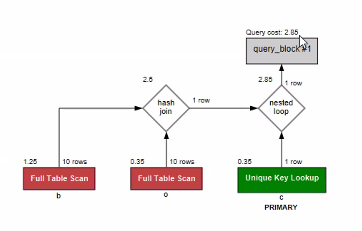
-> 3개의 테이블 모두 조인하는 것이 가장 성능이 좋게 나왔다.
-> 일반적으로도 서브쿼리보다 조인하는 것이 더 성능이 좋다 !
조인, 인라인 뷰 사용
조인과 서브쿼리의 한 종류인 인라인 뷰를 사용하여 아래와 같이 표현할 수 있다.
3-31
출판사별로 출판사의 평균 도서 가격보다 비싼 도서를 구하시오
book 테이블
| bookid | bookname | publisher | price |
|---|---|---|---|
| 1 | 축구의 역수 | 굿스포츠 | 70000 |
-- 3-31
-- 출판사별 평균 가격 테이블이 있으면 그걸 사용,
-- 1. 만약 없다면 아래와 같이 서브쿼리를 사용해서 평균을 구하고 비교
-- 같은 테이블을 사용
select b1.*
from book b1
where b1.price > ( select avg(b2.price) from book b2 where b2.publisher = b1.publisher );
-- 2. 아래 join 에 subquery(인라인 뷰) 가 사용
select b1.*
from book b1, (
select publisher, avg(price) avg_price
from book
group by publisher
) avg_book -- 인라인 뷰, 테이블 형태로 반환
where b1.publisher = avg_book.publisher
and b1.price > avg_book.avg_price;execution plan 비교
-
서브쿼리를 사용해서 평균을 구하고 비교 - 1.25
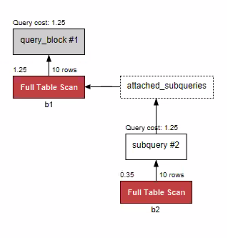
-
join에 인라인 뷰를 사용해 비교 - 8.25
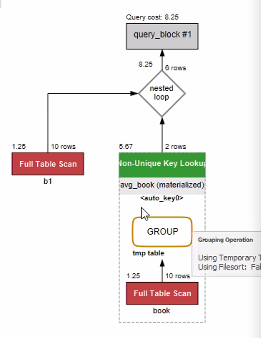
서브쿼리만 사용한 것이 더 빠른 상황이 나왔다.
-> 2번의 group by가 부담이 되고 있다.
-> 인라인 뷰가 부담이 되는 상황이라 조인을 썼을 때 더 성능이 안좋아졌다.
-> 또한 각 서브쿼리의 크기가 작기 때문에 상대적으로 성능이 좋게 나왔다.
-> 조인보다는 서브쿼리가 더 빠른 상황이라 판단할 수 있다.
또 다른 방법 - table을 만드는 방법
-- normal table 생성
create table avg_book
select publisher, avg(price) avg_price from book
group by publisher;
-- 생성한 테이블과 조인
select b1.* from book b1, avg_book -- normal table 사용
where b1.publisher = avg_book.publisher and b1.price > avg_book.avg_price;execution plan
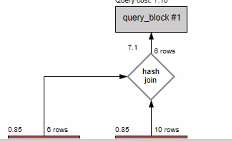
execution plan이 7.1이 나옴
-> 테이블이 정렬이 되어 있지 않아 해시 조인에서 시간이 많이 걸리고 있는 것을 확인할 수 있다.
추가로 exist와 not exist를 구분해서 코딩할 줄 알아야 코딩 좀 짠다 소리 듣는다... 메모
