LG U+ 유레카 백엔드 과정
1.그리디 알고리즘

그리디 알고리즘 vs 브루트포스 알고리즘 시간 복잡도 차이 그리디: O(n), O(n log n)이라면 브루트포스: O(2^n), O(n!)과 같이 브루트포스가 시간 복잡도가 높음 그리디(모든 경우 탐색x) / 브루트포스(모든 경우 탐색o) 그리디 알고리즘 사용하는
2.구현 알고리즘
구현 문제가 요구하는 내용이 제시된 내용 위에 추가로 작성 시뮬레이션 : data 초기 상태, 규칙이 주어짐 -> 시간의 흐름에 따라 반복문을 쓰게 됨 -> 종료 상태 구하기 문제 요구 내용 읽고 답 int면 N ~100,000 M ~1,000,000 long은 더
3.스택과 큐, DFS와 BFS
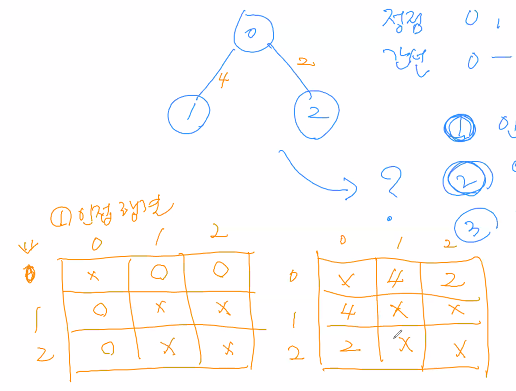
ArrayList쓰레드 세이프 하지 않음 \-> 쓰레드 동시 자원 되면 이상한 결과가 나올 수 있음 \-> 동기화 해서 문제 없게 해야 됨Vector쓰레드 세이프함 \-> 메모리 차지 무거움 stack 대신 ArrayDeque -> 더 가볍고 빨라짐Queue 대신 Ar
4.자바 정렬
정렬 >Item[] itemArray = { new Item(3, "666"), new Item(2, "777"), new Item(5,"444"), new Item(3, "111") }; implements Comparab
5.DFS, BFS, 분할정복 문제 풀이
dfs, bfs 문제 음료수 얼려 먹기 dfs와 bfs 둘다 써봄 문제 N x M 크기의 얼음 틀이 있다. 구멍이 뚫려 있는 부분은 0, 캄낙이가 존재하는 부분은 1으로 표시된다. 구멍이 뚫려있는 부분끼리 상,하,좌,우로 붙어있는 경우 서로 연결되어 있는 것으로 간
6.이진탐색과 DP
순차탐색 정렬되어 있지 않은 배열에서 차례대로 탐색 평균적으로 (n+1)/2번의 비교, 최악의 경우 n번 비교 시간 복잡도 O(n) 이진탐색 정렬 되어있는 데이터에서 특정 값을 찾아내는 알고리즘 중간값 선택해서 탐색 범위를 반으로 나눠 범위를 좁혀가는 방식 O(log
7.그래프 최단 경로(다익스트라, 플로이드워셜)
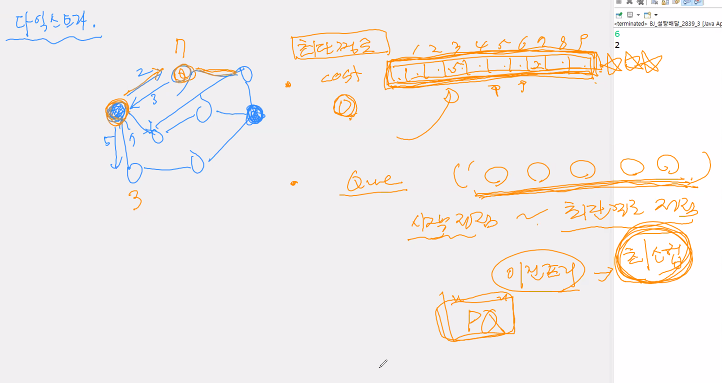
그래프 최단경로 비용, 거리, 무게 한 정점에서 다른 정점 탐색 가중치, 비용이 없다, 비용이 같다 -> bfs로 풀면 됨(코드 더 간결) -> 몇단계 거쳐가는지만 체크하면 됨 -> 다른 알고리즘은 복잡 -> 5번에 갈 수 있다 이러면 bfs는 그걸 반드시 보장해줌
8.MST 최소 신장 트리(크루스칼, 프림)
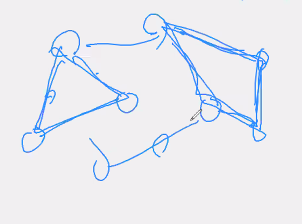
무향(방향이 없다사이클 x\--> 여기서 비용이 최소인 것이 최소 신장 트리(모두 연결 최소 비용)이러한 사이클이 없어야 함.어떻게 연결해야만 사이클이 안생기고 최소로 연결할 수 있는지간선을 따라 최소 비용인 정점을 탐색서로소 집합을 이용해 사이클 여부를 확인할 수 있
9.간단 비트마스킹 연산 메모
하노이의 탑 시작 기둥에서 목표 기둥으로 이동하는 부분에 재귀 호출, 중간 기둥에서 목표 기둥으로 이동하는 부분에 각 재귀 호출 | <<역할(setter 역할) 어느 자리에 1을 넣고 싶으면 그만큼 시프트 하고 or하면 특정 자리에 비트값을 1로 바꿀 수 있다.
10.성능 면에서 조인, 서브쿼리에 관하여
조인 둘 이상의 테이블을 연결하는 것 - inner join : 공통 부분(교집합) 선택됨 - left outer join : 공통 부분 + left쪽 테이블 - right outer join : 공통 부분 + right쪽 테이블 - full outer join
11.Self join
Self join 자신 테이블과 조인을 맺는 것 공통코드 관리에도 많이 사용 - self join 공통 코드 분류할 때 코드를 사용 (일반/외국인이면 "외국인"이라는 문자열을 적지 않음) 만약 수정이 필요할 때 공통 코드 테이블을 따로 만들어 사용하지 않는다면 한번
12.미니 프로젝트 회고(?)
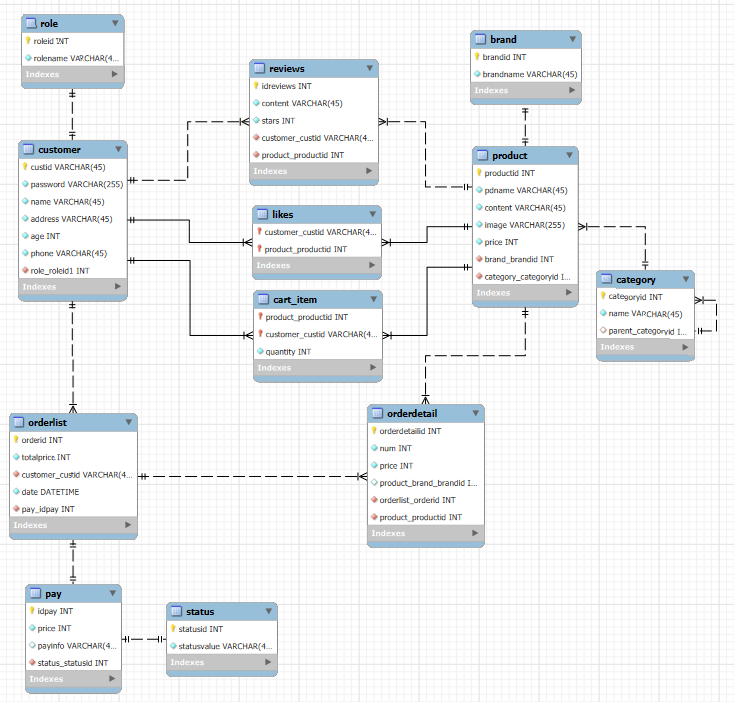
미니 프로젝트를 하면서 고민했던 부분, 공부했던 부분에 대해 정리해보고자 한다.자바만 사용해서 swing과 jdbc로 2일만에 개발한 프로젝트였다. (기간이 짧았음. 사실상 24시간...?)흔한 쇼핑몰보다는 그래도 어느정도 색다른 쇼핑몰을 하고 싶어서 "미니 스팀" 게
13.JDBC
DB 연결 방법 -> DriverManager 클래스의 getConnection() DB 연결 객체 -> Connection 객체 SQL 전달 , 결과 관리 객체 -> Statement 객체, PreparedStatement 객체, CallableStatement 객
14.SQL과 NoSQL
1. Scallability(확장성) Scale Up : 인프라 장비의 개수를 늘리지 않고 내부 부품을 더 좋은 부품으로 업그레이드 RDBMS에 더 유리 JOIN : 분리된 데이터 집합(table)을 다시 유의미한 하나로 만드는 작업 -> 만약 2 table
15.MongoDB
MongoDB -> sql이 아니다 보니 함수형으로 호출하는 방식이 사용됨 출처: Beginersbook.com cmd를 열고 mongosh를 친다. 데이터베이스 조회 show dbs 데이터베이스 삭제 db.dropDatabase() 데이터베이스 선택 (
16.Servlet을 다뤄보며(HTTP/Forward/Redirect/WAS/MVC 개념)
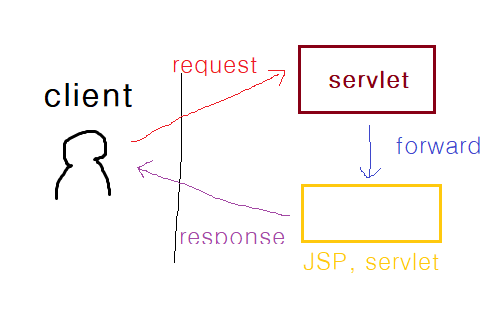
1. stateless server는 client를 기억하지 못한다. client를 기억하기 위한 다양한 기술 cookie, session, jwt 2. Request GET, POST, PUT, DELETE 3. Response 정상적인 request 200 비
17.Spring 기본 개념
Spring 기본 개념 DI : 의존성 주입 하나의 객체에 다른 객체의 의존성을 제공하는 기술 코드 재활용성 높일 수 있어 유지보수 용이 클래스 간 결합도 낮출 수 있음 인터페이스 기반 설계 단위 테스트 쉬워짐 AOP : 부가 기능을 핵심 기능에서 분리해 한 곳으로