성능 테스트에 필요한 가짜 유저를 만들기 위해 데이터베이스로 더미 유저 생성을 요청했다.
그 과정에서 데이터 베이스를 최적화하고 테스트 데이터의 삽입을 빠르게 할 수 있는 최적화 방법에 대해 고민해보고 적용한 글이다.
환경 구성
현재 구성한 인프라는 다음과 같다.
https://velog.io/@jhkim31/series/테스트-인프라-구축
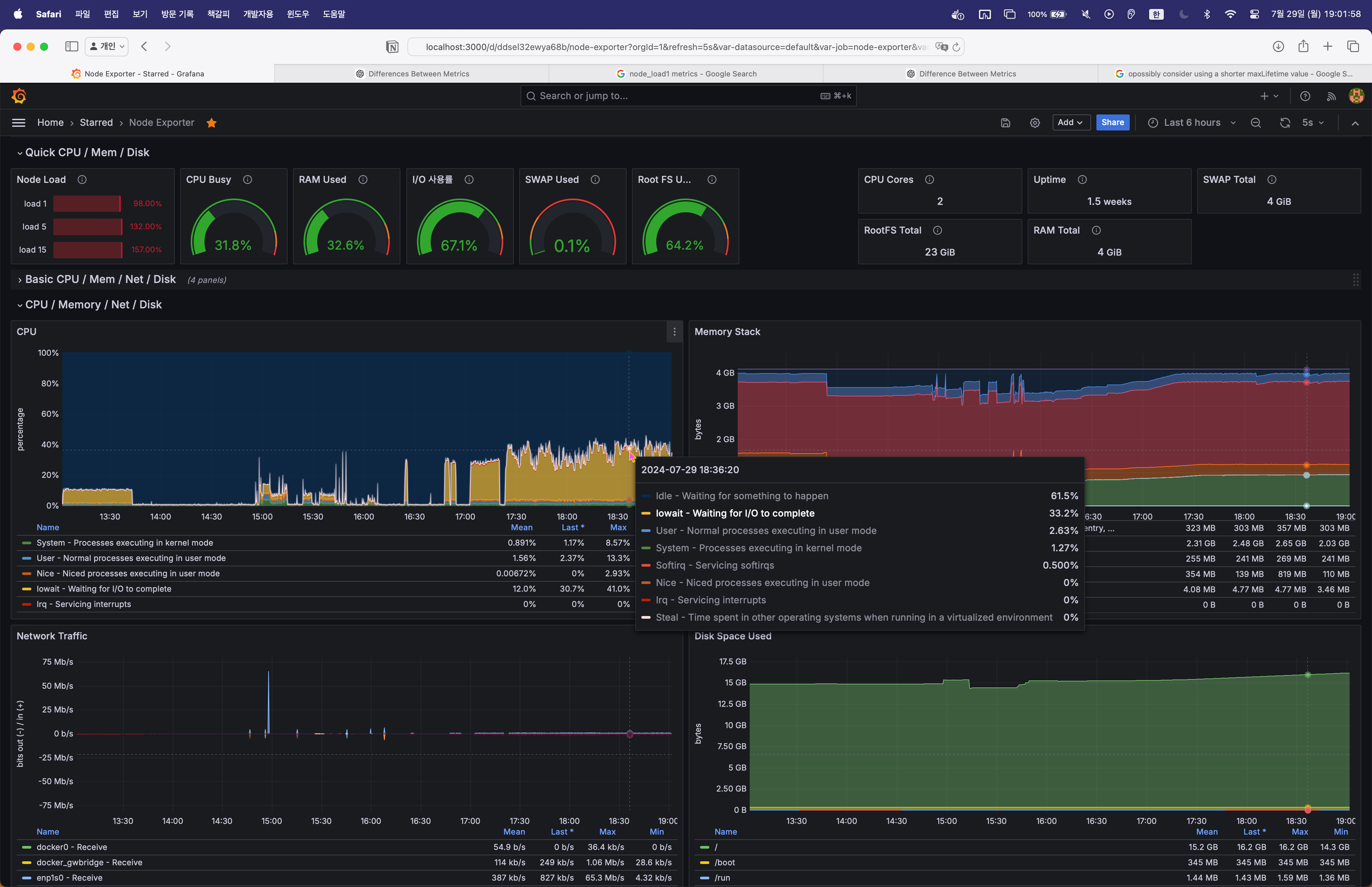
아직은 하나의 MYSQL 서버에 데이터를 삽입하고 있는 중이다.
그리고, mysql-exporter를 사용해 mysql 서버의 데이터를 prometheus, grafana 로 수집해 모니터링 했다.
간단한 회원 가입 스크립트를 작성하고 이를 테스트 서버에 실행시켜 가짜 데이터를 생성하고 그 과정을 모니터링 해봤다.
@Override
public void run(String... args) throws Exception {
for (int i = 0; i < 1_000_000; i++) {
if (i % 1000 == 0) {
log.warn("{}", i);
}
UserType userType = Math.random() < 0.001 ? UserType.SELLER : UserType.USER;
JoinUserRequest joinUserRequest = JoinUserRequest
.builder()
.email("user" + i + "@email.com")
.username("user" + i)
.password("password")
.userType(userType)
.build();
userService.joinUser(joinUserRequest);
}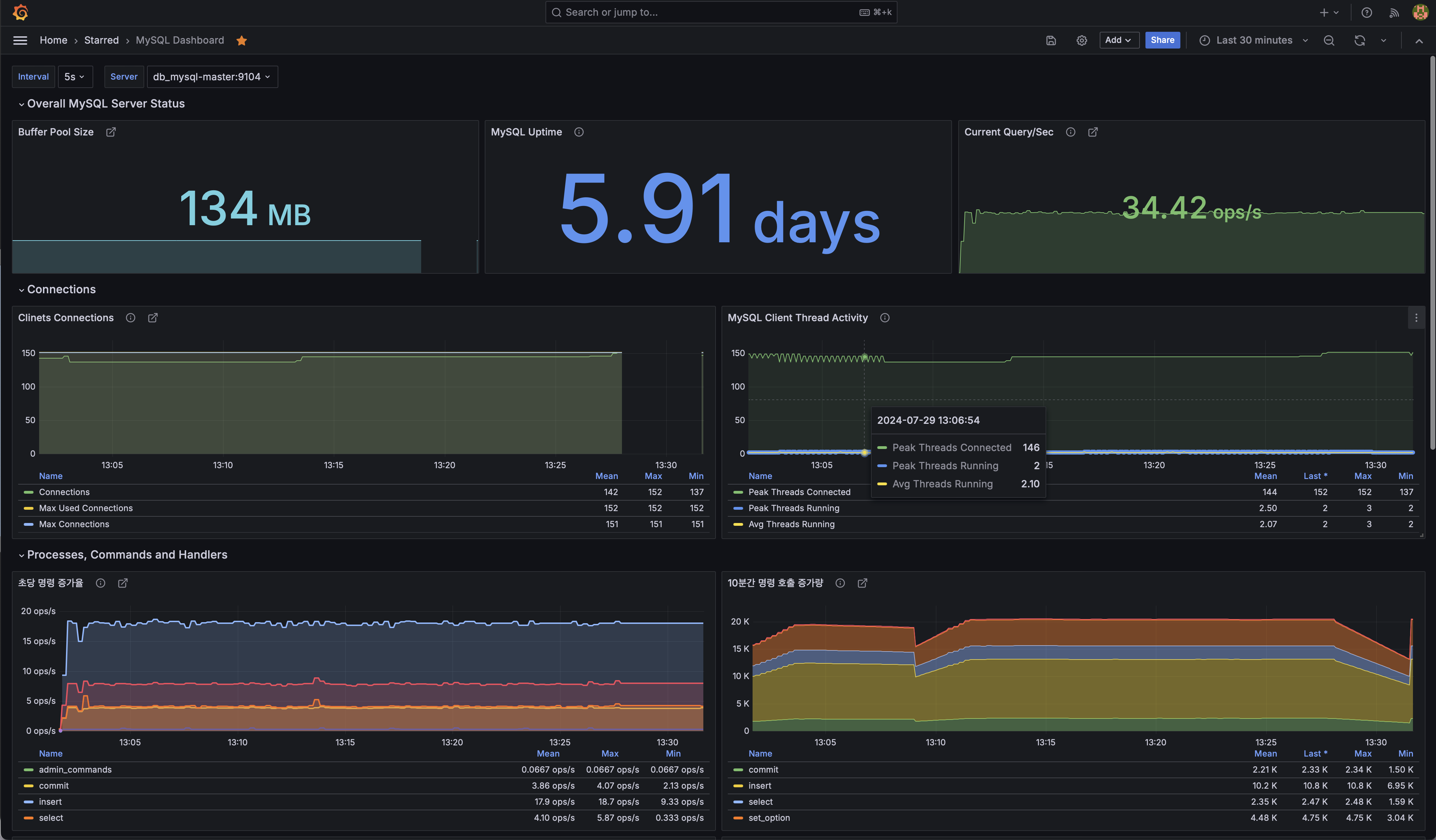
모니터링 결과 초당 약 20건의 INSERT 쿼리가 동작하고 있었다.
솔루션
하지만 초당 20건의 Insert는 내가 원하는 수만큼의 데이터를 삽입하기에는 너무 느린 속도였다.
속도를 개선시키기 위해 다방면으로 분석을 해봤다.
1. Sleep 커넥션 정리
그중 가장 먼저 눈에 들어온것이 커넥션의 수였다.
커넥션의 수가 약 150개로 너무나 많은 수가 잡혔다.
현재 테스트서버에서 실행중인 (별도의 작업은 없이 실행중이기만 함) JVM인스턴스 한개당 HikariCP로 10개씩, 인스턴스가 3개 있으니 30개는 이해가 가지만 나머지 120개의 커넥션의 행방은 알 수 없었다
커넥션을 확인해보기 위해 db쿼리를 날려 확인해봤다.
SELECT * FROM information_schema.PROCESSLIST;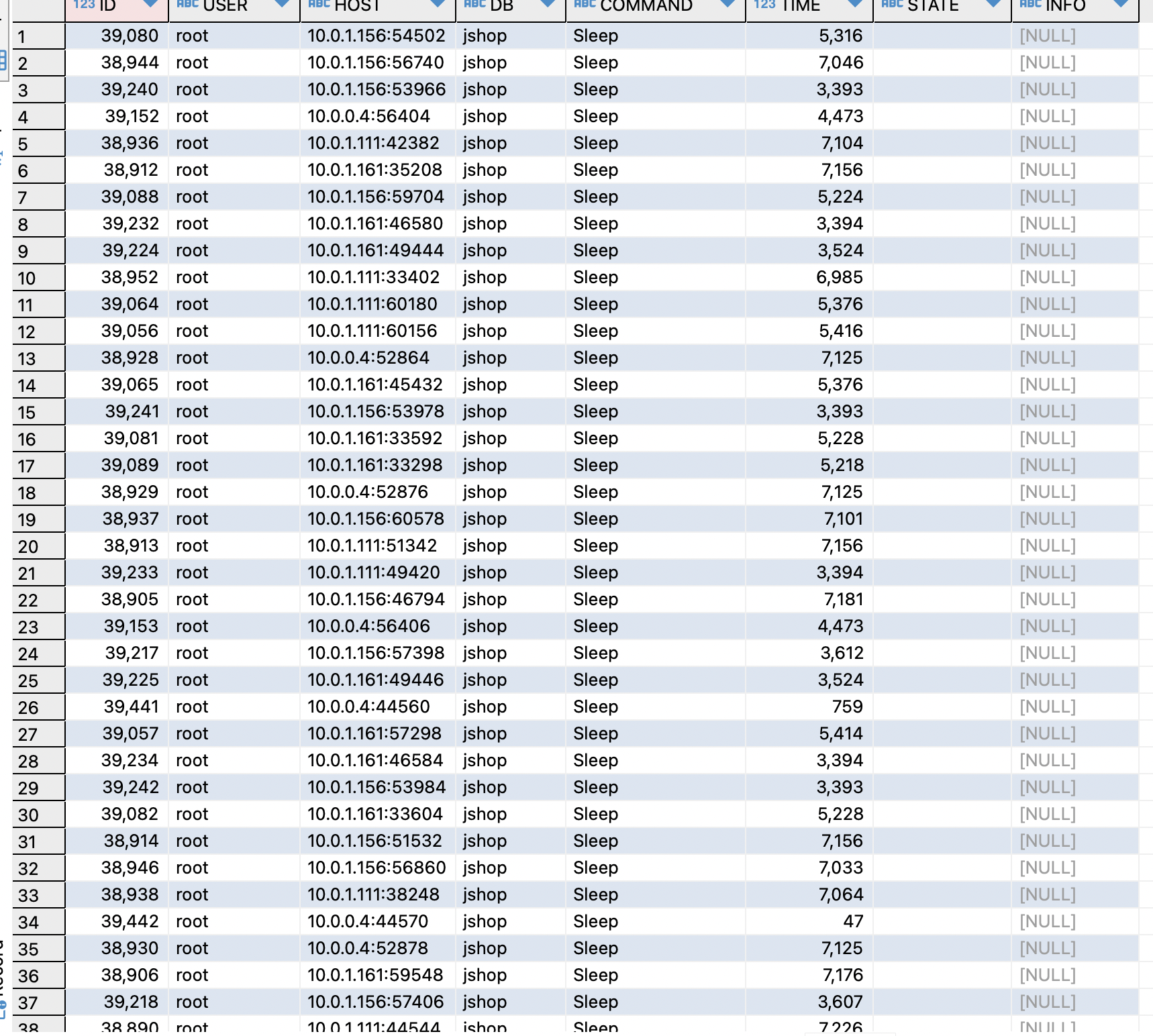
알 수 없는 Sleep 커넥션이 120개 가량 되는것을 확인할 수 있었다.
Sleep 커넥션의 원인
Sleep 이 생길 수 있는 원인을 살펴보니, 애플리케이션측에서 비정상적인 종료를 함으로써 이렇게 쌓일 수 있다고 한다.
게다가 MySQL의 기본 설정은 이런 sleep 커넥션을 8시간동안 살아있게 해두기 때문에 이렇게 Sleep 커넥션이 쌓일경우 서버에 안좋은 영향을 주게 된다.
해결 방안
우선 이 Sleep 커넥션이 쌓이지 않도록 wait_timeout, interactive_timeout 값을 설정해 sleep 시간을 조절해보자.
my.cnf
[mysqld]
wait_timeout = 300
interactive_timeout = 300그리고 재시작을해 비정상 커넥션을 모두 정리시키고 설정을 적용해주었다.
이제 비정상적인 커넥션들이 모두 정리되었다.
2. 멀티 스레드
현재는 하나의 스레드에서 스크립트를 실행해 데이터를 삽입하고 있었다.
하지만 멀티 스레드를 지원하고, 커넥션 풀을 지원하는 환경에서 단일 스레드로 돌릴 이유는 전혀 없었다.
커넥션 풀을 20개로 늘리고, 스레드풀을 18개로 설정해, 다시 수행을 해봤다.
그리고 멀티 스레드 환경에서 유저ID의 동시성 문제를 해결하기 위해 AtomicInteger 를 사용했다.
@Override
public void run(String... args) throws Exception {
ExecutorService executors = Executors.newFixedThreadPool(18);
for (int i = 0; i < 1_000_000; i++) {
executors.submit(() -> {
int userId = userIndex.getAndIncrement();
if (userId % 1000 == 0) {
log.warn("{}", userId);
}
UserType userType = Math.random() < 0.001 ? UserType.SELLER : UserType.USER;
JoinUserRequest joinUserRequest = JoinUserRequest
.builder()
.email("user" + userId + "@email.com")
.username("user" + userId)
.password("password")
.userType(userType)
.build();
userService.joinUser(joinUserRequest);
});
}
}이제 변경한 코드를 직접 실행해보자.
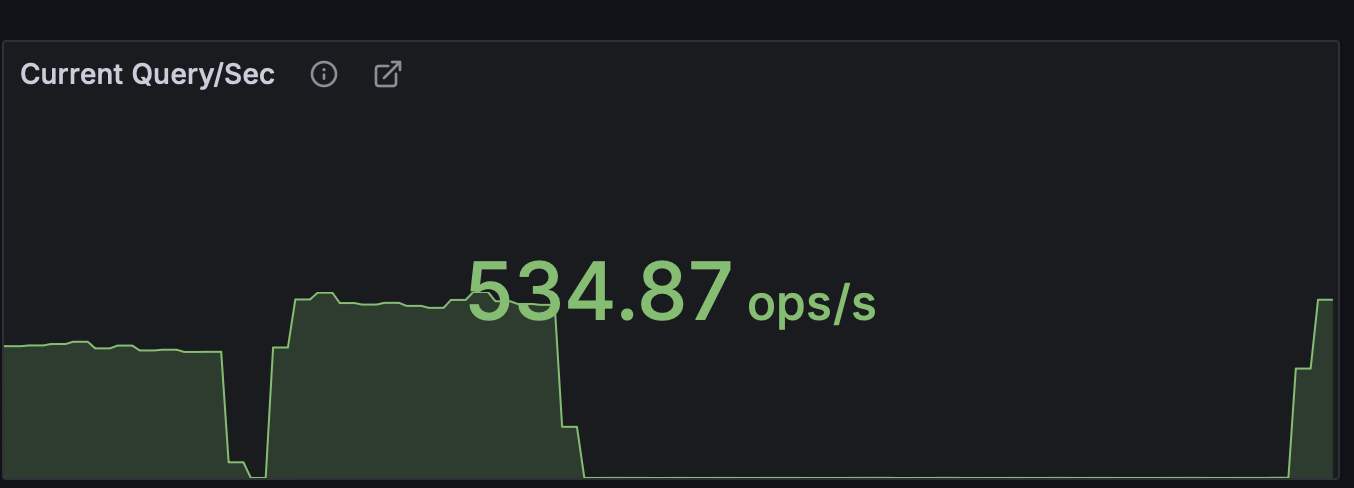
DB의 커넥션 정리와 멀티 스레드만으로 초당 40건 -> 500건의 쿼리 실행 까지 향상시킨것을 확인할 수 있었다.
3. 배치처리
추가적인 속도 향상에 대해 고민하다가, 데이터를 배치로 밀어넣는 방법에 대해 생각해봤다.
현재는 하나의 작업이 하나의 유저를 만들어 하나의 쿼리로 넣기 때문에 매 각 스레드마다 유저를 생성하고 유저 생성 SQL이 날라가게 된다.
이 과정을 하나의 작업에서 여러개의 유저를 만들고 쿼리를 한번만 날려 쿼리가 날라가는 과정에서 발생하는 오버헤드를 줄여보는것이다.
현재 로그를 보면 유저 10000명을 생성하는데 약 3분이 소요된다.
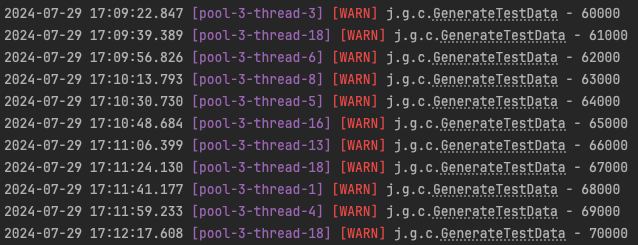
스크립트를 수정하여 한번에 50명의 유저를 만들고 쿼리를 내보내는 식으로 변경해보자.
@Override
@Transactional
public void run(String... args) throws Exception {
ExecutorService executors = Executors.newFixedThreadPool(10);
for (int i = 0; i < 20_000; i++) {
executors.submit(() -> {
List<User> users = new ArrayList<>();
for (int j = 0; j < 50; j++) {
int userId = userIndex.getAndIncrement();
if (userId % 1000 == 0) {
log.warn("{}", userId);
}
UserType userType = Math.random() < 0.001 ? UserType.SELLER : UserType.USER;
JoinUserRequest joinUserRequest = JoinUserRequest
.builder()
.email("user" + userId + "@email.com")
.username("user" + userId)
.password("password")
.userType(userType)
.build();
User user = User.of(joinUserRequest, bCryptPasswordEncoder.encode("password"));
users.add(user);
}
userRepository.saveAll(users);
});
}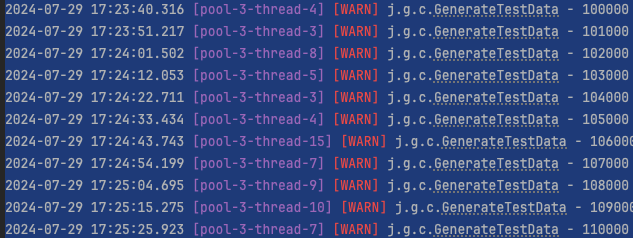
배치 처리로 변경하자 유저 10000명당 생성 시간이 1:40 로 약 절반 가까이 줄어든것을 확인할 수 있다.
4. I/O 바운드
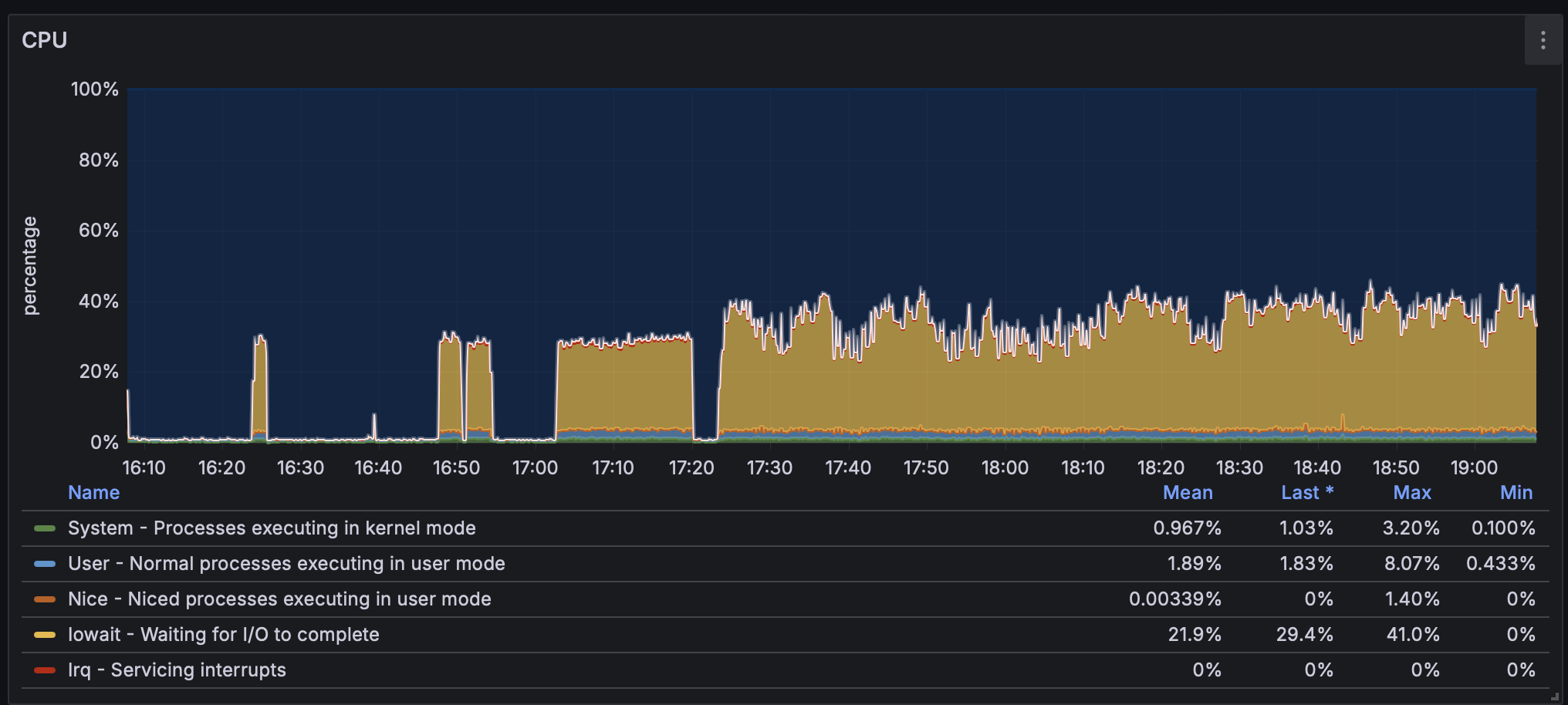
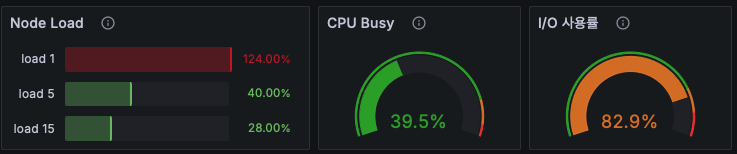
MySQL의 노드를 모니터링 해보면 다음과 같은 양상을 볼 수 있다.
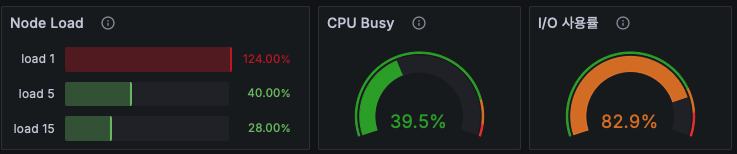
부하는 높지만, 실제 사용중인 CPU의 사용량은 낮은 모습이다.
왜 이런 현상이 나타날까??
node_load1
왼쪽 그래프에 사용된 node_load1 메트릭은 시스템의 1분 평균 부하를 나타낸다.
부하가 높다는것은 프로세스가 CPU를 할당받기 위해 오래 기다려야 한다는 것을 의미한다.
irate(node_cpu_seconds_total[1m])
반면에 우측 그래프에 사용된 irate(node_cpu_seconds_total[1m]) 메트릭은 실시간 CPU 사용률을 나타낸 지표다.
초당 CPU Idle 타임을 1에서 뺌으로써, 값을 구할 수 있다.
이 값이 크다는 것은 CPU가 일을 한 시간이 그만큼 많다는것을 말한다.
즉 이상황에서 프로세스는 CPU를 할당받기까지 오래 대기하지만, 막상 CPU는 그렇게 까진 바쁘지 않다는것을 말한다.
그럼 이 프로세스들은 CPU를 할당받지 않고 뭘 하는걸까??
현재 작업은 DB에 데이터를 왕창 밀어넣고 있는 작업이다. 이런 작업의 특성상 I/O 작업의 비율이 아주 높다.
즉 I/O 작업을 하기 위해 대기중인 프로세스가 많아 이러한 양상이 나오게 되는 것이다.
실제로 같은시간 I/O 사용률을 보면 7~80 % 대로 아주 높은것을 확인할 수 있고 CPU 사용량을 분석해봐도 I/O wait 의 비율이 아주 높게 나오는것을 확인할 수 있다.
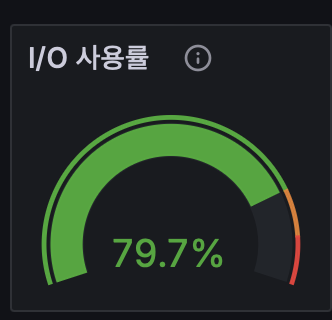
4.1 버퍼풀
innodb의 버퍼풀은 쓰기작업시 버퍼풀에 있는 페이지에 기록한다.
페이지
InnoDB 스토리지 엔진의 데이터 저장 단위. 하나의 페이지에는 여러 데이터가 저장될 수 있다. InnoDB는 페이지 단위로 데이터를 읽고 씀으로써, I/O를 최소화 하고 성능을 향상시킨다.
이 버퍼풀의 크기가 작다면, 디스크 플러시가 빈번하게 일어나 성능에 저하가 발생하게 된다.
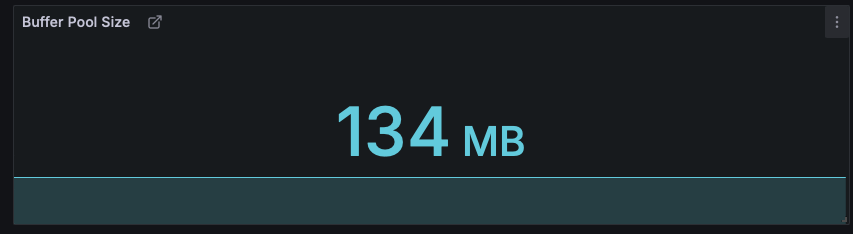
버퍼풀의 크기는 아래 쿼리로 확인할 수 있다.
SHOW VARIABLES LIKE 'innodb_buffer_pool_size';나의 경우 grafana로 확인한 버퍼풀의 크기는 134MB다.
그리고 버퍼풀 사용량을 봐도 꽉꽉 들어차있는것을 확인할 수 있다.

버퍼풀은 통상 메모리의 50% 정도로 설정하는것이 좋다.
지금은 I/O 바운드도 심한 데다가, 메모리의 여유또한 있으니 버퍼풀의 크기를 500MB 정도까지만 올려보자.
버퍼풀 조정은 다음 명령으로 할 수 있다.
SET GLOBAL innodb_buffer_pool_size = 536870912;아래는 설정 파일 설정 방법이다.
my.cnf
[mysqld]
wait_timeout = 300
interactive_timeout = 300
innodb_buffer_pool_size = 500MB버퍼풀 크기는 핫스왑을 지원하기 때문에 곧바로 버퍼풀크기가 늘어난것을 확인할 수 있다.
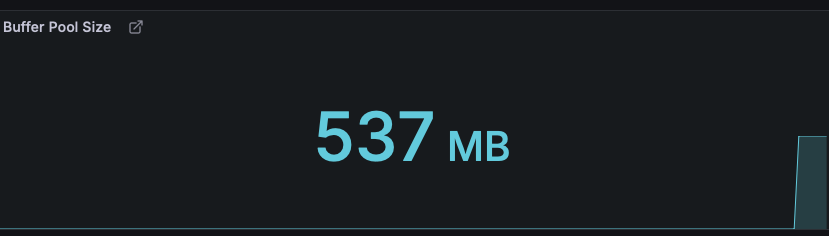
버퍼풀 사용량도 점점 늘어나고 있다.

4.2 innodb_flush_log_at_trx_commit
트랜잭션은 데이터베이스의 작업 단위다. 이 트랜잭션이 발생하면 데이터베이스는 트랜잭션 로그를 기록하게 된다.
이 로그는 추후 데이터베이스에서 장애가 발생할때 복구를 할때도 사용할 수 있고, 분산 복제에도 사용할 수 있는등 데이터의 무결성을 책임지는 중요한 역할을 한다.
innodb_flush_log_at_trx_commit 은 innodb 의 스토리지 엔진에서 로그를 디스크에 어떻게 플러시 할지를 나타내는 설정이다.
정
트랜잭션이 발생할때마다 로그를 디스크로 바로 쓰게된다면, 매 트랜잭션마다 I/O가 발생해 성능 저하가 심하기 때문에 이를 방지하기 위한 설정이다.
설정 가능한 값은 3가지가 있다.
innodb_flush_log_at_trx_commit = 0
트랜잭션 로그가 발생하면 MySQL의 메모리 영역인 로그 버퍼에 저장된다.
로그 버퍼의 트랜잭션 로그는 초당 한번 디스크에 플러시 된다.
성능 위주의 설정이지만 MySQL서버에 손상이 갈 경우 데이터 손실의 위험이 있다.
예를들어 로그 버퍼에 저장되었지만 아직 디스크까지 가지 못한 트랜잭션 로그가 있을때 MySQL 서버가 다운되면 로그 버퍼에 있던 트랜잭션 로그는 유실된다.
즉 세가지 설정중에 가장 내구도가 낮은 설정이다.
innodb_flush_log_at_trx_commit = 1 (default)
트랜잭션이 커밋될때마다 로그가 디스크까지 플러시된다.
데이터의 내구성을 위한 설정이지만, I/O 바운드가 많다는 단점이 있다.
MySQL의 InnoDB 스토리지 엔진의 기본 설정이다.
innodb_flush_log_at_trx_commit = 2
트랜잭션 로그가 발생하면 OS 버퍼에 플러시 된다.
초당 한번 OS 버퍼에서 디스크로 플러시 된다.
성능 위주의 설정이지만 OS에 손상이 갈경우 데이터 손실의 위험이 있다.
OS 버퍼를 사용하기 때문에 MySQL 메모리에 저장하는 0 설정보다 성능은 낮다. 하지만 비교적 안전한 OS 버퍼를 사용한다는 장점이 있다.
각 설정들은 성능과 무결성에서 트레이드 오프가 있기 때문에 목적에 따라 사용을 해야 한다.
이번 최적화에는 innodb_flush_log_at_trx_commit = 2 를 사용해 I/O 바운드를 줄여보기로 했다.
아래 명령으로 설정할 수 있다.
innodb_flush_log_at_trx_commit = 2
DB 튜닝후에는 동일한 작업에서 I/O 부하가 크게 줄어들은것을 확인할 수 있다.

정리
테스트 데이터를 DB에 밀어넣는중, 성능 최적화를 위해 데이터베이스, spring 설정들을 여러가지 살펴보았다.
-
애플리케이션과 DB의 커넥션이 제대로 끊어지지 않는다면 Connection이 남게 된다. 이 커넥션은 기본 설정으론 8시간동안 유지되기 때문에 관리가 필요하다.
-
데이터 삽입시 I/O 버스트 작업이 대부분이기 때문에 멀티 스레드를 적극적으로 사용해 CPU를 효율적으로 사용할 수 있다.
-
데이터를 배치처리로 밀어넣음으로써 트랜잭션와 네트워크 오버헤드를 크게 감소시켜줄 수 있다.
-
버퍼풀은 MySQL이 메모리에 띄워둘 수 있는 데이터 페이지의 크기를 결정하기 때문에 적당한 크기를 잡아주는것은 성능에 큰 도움이 된다.
-
트랜잭션 로그는 트랜잭션의 영속성을 보장하고, 분산 복제를 위해 사용된다. 하지만 너무 빈번한 I/O를 하게된다면 성능에 안좋은 영향을 줄 수 있다. 또한 메모리나 버퍼에 트랜잭션 로그를 띄워둘 경우에는 성능상 이점은 있지만 MySQL서버가 다운되거나, OS가 다운될경우 트랜잭션 영속성이 보장되지 않을 수 있음으로 트레이드 오프를 유의해야 한다.
직접 모니터링 환경을 세팅해두고 여러가지 환경을 바꿔서 실험을 진행해보니 성능 최적화가 되는것이 눈에 확 와닿았다. 또한 이렇게 성능 최적화를 진행하며 유의해야 할점들에 대해 배운것 같다.
