
프로젝트의 성능 테스트를 진행하며 검색 성능을 최적화한 기록을 정리한 글이다.
이전 과정에서 SQL의 최적화를 통해 검색 성능을 일부 개선했지만 어쩔 수 없는 한계로 더이상의 성능 최적화는 힘들었다.
이 글에서는 외부 자원을 사용해 최적화 하는 방법에 대해 알아본다.
이전 글에서 SQL 최적화를 통해 검색, 카운트 쿼리의 속도를 10배 향상 시켰다.
하지만 아직 카운트 쿼리는 300ms 라는 무시못할 실행 시간을 가진다.
그래서 이를 해결하고자 캐시를 도입해 문제를 해결하고자 한다.
캐시
캐시는 데이터를 임시로 보관하고 있다가, 필요할때 빠르게 제공해주기 위한 방법이다.
캐시는 컴퓨터 과학에서 정말 모든곳에서 사용할정도로 큰 효과를 발휘한다.
예를들어 CPU만 해도 메모리까지 가는 비용을 줄이기 위해 캐시를 사용하고, 웹의 경우에도 웹 서버까지 가는 비용을 줄이기 위해 프록시 서버에서 캐시를 사용한다.
이렇게 캐시를 통해 원본 데이터보다 빠르게 데이터에 접근하는것을 캐시 히트, 캐시에 저장된 데이터가 없어 원본 데이터까지 갔다오는것을 캐시 미스 라고 한다.
이러한 캐시는 시스템의 전체적인 성능을 크게 끌어올릴 수 있어 다양한 분야에서 사용하게 된다.
캐시와 일관성
캐시가 장점만 있는것은 아니다. 데이터를 원본과 복사본으로 이중화해서 보관하게 되는거라 데이터의 일관성(Consistency)이 깨지게 된다.
예를들어 웹서버가 업데이트 되었지만 웹 자원을 캐싱하고 있던 프록시 서버에서는 이를 인지하지 못하게 된다면 실제 데이터는 업데이트 되었지만 캐싱된 예전 데이터를 제공해 줌으로써 데이터의 일관성이 깨지게 된다.
자바에서도 volatile 키워드를 사용해 변수가 CPU 캐시에 캐시되어 일관성이 깨지는것을 막고 가시성을 보장해준다.
즉 모든 문제를 해결해주는 은총알은 없듯이 캐시를 사용할때 성능에서는 이점을 챙길 수 있지만, 데이터의 일관성이 깨지게 된다는 단점도 존재한다.
캐싱 전략
이렇게 캐시는 성능과 일관성이라는 트레이드 오프 관계에서 필요에 따라 잘 사용한다면 큰 이득을 볼 수 있는 기술이지만 잘못 사용한다면 안쓰는이만 못하는 기술이 되어버린다.
다음은 캐시를 사용하기 위한 전략 몇가지를 알아보자.
읽기 전략
Look Aside
캐시에서 데이터를 먼저 읽고, 데이터가 없다면 원본 데이터 소스를 조회한다.
이렇게 가져온 원본 데이터를 캐시에 반영한다.
Read Through
캐시에 데이터가 없다면 캐시가 원본 데이터 소스로부터 데이터를 가져와 캐시에 저장하고 해당 데이터를 반환한다.
Look Aside는 캐시에 데이터를 쓰는 책임이 클라이언트에 있다면, Read Through 는 캐시 쓰기의 책임이 캐시한테 있다는게 차이다.
쓰기 전략
Write Back
데이터를 저장할때 캐시에만 기록한다.
그리고 일정 시간이 지날때 캐시에서 원본 데이터 소스에 저장한다.
데이터를 조회시 캐시를 통하기 때문에 항상 데이터의 일관성이 보장되지만, 캐시에 장애가 생기게 될경우 원본 데이터 소스에 저장되지 않은 데이터를 유실하게 된다.
Write Through
원본 데이터 소스와 캐시에 동시에 데이터를 저장한다.
데이터를 저장할때마다 항상 캐시에 저장하게 되고, 캐시가 바로 원본 데이터 소스로 데이터를 저장한다.
데이터의 일관성이 보장되고, 항상 캐시 -> 원본 데이터 소스 를 거치기 떄문에 데이터 유실의 위험이 적다.
하지만 캐시 -> 원본 데이터 소스 를 거쳐서 데이터가 저장되기 때문에 시간이 오래걸린다는 단점이 있다.
Write Around
데이터를 원본 데이터 소스에만 저장한다.
캐시는 읽기 용도로만 사용되기 때문에 쓰기 작업으로 인해 데이터 일관성이 깨지는것을 방지할 수 있다.
하지만 캐시에 데이터가 있어서 캐시 히트가 되는 상황에서 원본 데이터 소스와 일관성이 깨질 수 있다. 또한 최초 접근시 캐시 미스가 날 확률이 높은 편이다.
제거 전략
LRU (Least Recently Used)
가장 오랫동안 사용하지 않은 데이터를 캐시에서 제거한다.
메모리를 효율적으로 사용할 수 있지만, 가장 오래 사용하지 않은 데이터를 찾기 위한 추가 오버헤드가 생길 수 있다.
LFU (Least Frequently Used)
가장 적게 사용한 항목을 제거하는 전략이다.
자주 사용한 데이터를 남겨 중요한 데이터를 효율적으로 남길 수 있다.
하지만 과거에 사용되다 현재 잘 사용하지 않는 데이터가 캐시에 남아있을 수 있다.
FIFO (First-In, First-Out)
선입선출 전략이다.
간단한 전략이지만, 메모리를 비효율적으로 사용할 수 있다.
TTL (Time-To-Leave)
캐시 항목마다 TTL을 설정해, 일정 시간이 지나면 자동으로 삭제되게 하는 전략이다.
데이터를 자동으로 제거하기 때문에 일관성을 유지하는데 효과적이다. 하지만 적절한 TTL을 정하는것이 어렵다.
Spring Cache
현재 카운트 쿼리는 굉장히 쿼리 수행 시간이 길다는것도 문제지만 사이드 이펙으로 쿼리가 실행되는 동안 CPU와 자원을 너무 점유하고 있어 노드 전체의 부하가 늘어나는 단점도 있다.
이걸 해결하기 위해 스프링의 캐시 추상화 기능에 대해 알아봤다.
스프링의 강력한 장점인 추상화 덕분에 캐시를 편하게 사용할 수 있다.
Spring Cache 와 Redis
스프링 캐시는 기본적으로 Look Aside 읽기 전략을 사용한다.
우선 캐시로부터 데이터를 읽고 캐시에 데이터가 없다면 원본 데이터 소스로부터 데이터를 읽어 이를 캐시에 저장한다.

GET 으로 캐시를 먼저 조회하지만, 데이터가 없자 원본 데이터 소스인 데이터베이스로부터 데이터를 조회해 이를 SET 으로 캐시에 저장한다.
캐시 제거 전략은 Redis 에서 설정해야 한다.
Redis에는 다양한 캐시 정책을 제공한다.
noeviction: 메모리가 부족해지면 오류를 반환하고, 아무것도 제거하지 않습니다.allkeys-lru: 모든 키에서 LRU 정책을 적용하여 제거합니다.volatile-lru: TTL이 설정된 키에서만 LRU 정책을 적용합니다.allkeys-lfu: 모든 키에서 LFU 정책을 적용하여 제거합니다.volatile-lfu: TTL이 설정된 키에서만 LFU 정책을 적용합니다.volatile-ttl: TTL이 가장 짧은 키를 제거합니다.volatile-random: TTL이 설정된 키 중에서 무작위로 제거합니다.allkeys-random: 모든 키 중에서 무작위로 제거합니다.
스프링 캐시 설정
스프링의 캐시 추상화에선 다양한 캐시 구현체들을 사용할 수 있다. 나는 그중에서 Redis를 사용해 캐시를 구현하기로 했다.
Redis를 선택한 이유는 분산락과 Refesh Token 을 위해 이미 사용하고 있었기 때문에 인프라 추가 없이 기존 Redis를 사용하기로 했다.
build.gradle 의존 추가
캐시를 사용하기 위한 의존을 추가한다.
dependencies {
// redis
implementation 'org.springframework.boot:spring-boot-starter-data-redis'
implementation 'org.springframework.boot:spring-boot-starter-cache'
// redis
}application.yml 설정
스프링 부트의 강력한 장점중 하나는 설정 파일만으로 자동 설정이 가능하다는 점이다.
cache 또한 application.yml 의 설정으로 간편하게 사용이 가능하다.
spring:
cache:
type: redis
redis:
time-to-live: 36000000cache.type:redis를 캐시 구현체로 사용cache.redis.time-to-live:redis캐시의 TTL을 지정한다 (ms)
redis 설정이 되어있다면 위와같이 cache 설정만 하게 되면 cache 를 사용할 수 있다.
@EnableCaching
캐싱 기능을 사용하기 위해서 애플리케이션 설정에 @EnableCaching 어노테이션을 추가해준다.
여기까지 하면 캐시 사용을 위한 설정이 끝이다.
진짜 스프링 부트로 인해 개발 편의성이 너무 편해진것 같다.
cache 사용
캐시를 사용하기 위해서 캐싱을 할 메서드위에 @Cacheable 어노테이션을 사용한다.
나의 경우 카운트 쿼리를 캐싱하기 위해 다음과 같이 사용했다.
@Cacheable(value = "search_count_query", key="#condition")
public Long getTotalCount(SearchCondition condition) {#condition 은 SePL 표기법으로 SearchCondition 파라미터를 캐시의 키값으로 사용하겠다는 의미다.
객체를 캐시의 키값으로 사용하기 위해선 ToString 이 제대로 구현되어 있어야 한다.

성능 테스트
이제 이전 단계에서 수행한 인덱싱과, 이번 단계에서 수행한 캐싱까지 적용한 결과를 확인해보자.
기존 테스트 설정대로 테스트를 진행해봤다.
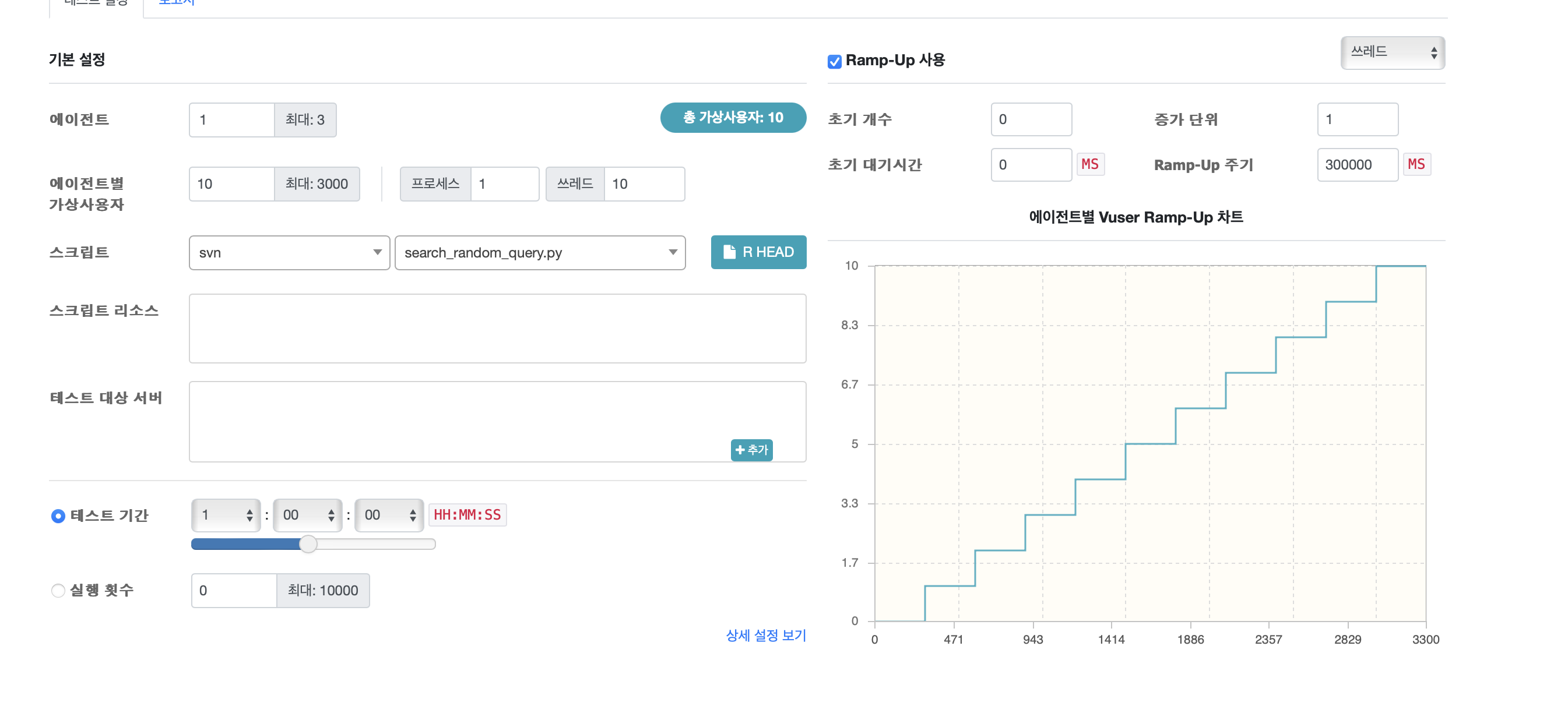
단일 키워드 검색 성능 테스트
가상 사용자는 검색 API로 상품 생성에 사용된 랜덤한 키워드를 날린다.
최대 가상 사용자는 10명, 5분마다 가상 사용자를 늘린다.
1시간동안 테스트 진행
목표 성능
- 평균 응답시간 :
1000ms- 처리량 :
10 RPS- 에러율 :
0.05
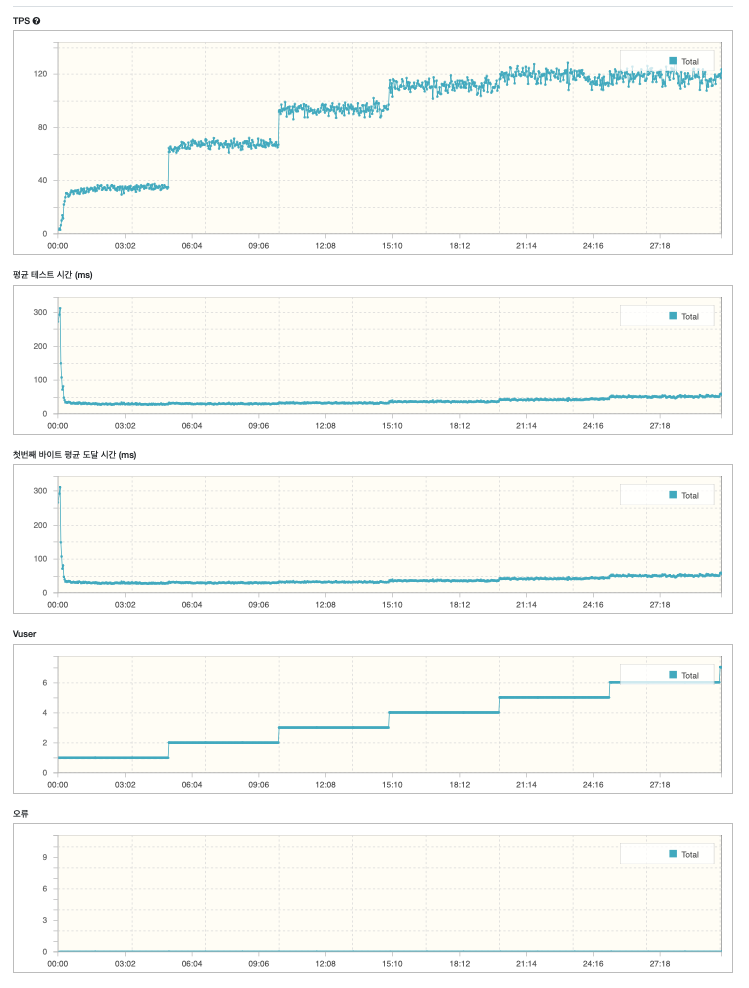
테스트 결과를 보면 시작과 동시에, 빠르게 RPS가 올라간다. 이는 캐시 히트 비율이 올라감으로써 전체 API 수행 속도가 빨라졌기 때문이다.
또한 평균 테스트 시간또한 캐시가 어느정도 데위진 이후로부터 아주 빨라진것을 확인할 수 있다.
vuser 가 늘어남에 따라서 시간이 점점 증가하는 모양을 보여주긴 한다.
그래도 120 RPS 의 성능을 보여주고 있다.
정리
비교적 비용이 비싼 카운트 쿼리를 최적화 하기 위해 Redis를 캐시로 사용했다.
캐시를 사용하지 않고 SQL 최적화만으로도 어느정도 속도 향상이 있었지만, 캐시를 사용하니 더욱 눈에 띄는 속도 향상을 보여줬다.
기존 1 RPS 였던 검색 쿼리를 최종 120 RPS 까지 끌어 올리게 되었다.
다만 캐싱되지 않은 검색 조건이 들어와 캐시 미스가 발생하면 10 RPS 정도의 속도가 나오긴 하지만 이것도 기존 속도보다 10배나 향상된 속도다.
이런 최적화를 위해 미리 어느정도 검색어를 캐시에 넣어두는 작업이 필요할것 같기도 하다.
