
프로젝트의 성능 테스트를 진행하며 검색 성능을 최적화한 기록을 정리한 글이다.
이 글에선 검색에 사용된 SQL(카운트 쿼리)을 분석해보고 좀 더 효율적인 쿼리 방법을 찾는 과정을 설명한다.
타임아웃 원인 분석
JVM의 응답속도를 봐도 응답시간이 1초는 가볍게 넘어가고, 분단위까지 넘어가는것을 확인할 수 있었다.

원인을 파악하기 위해 가장 먼저 SQL을 분석해봤다.
SQL 분석
아래는 애플리케이션에서 발생한 검색 로그에 찍힌 SQL 이다.
2024-08-06 19:31:40.580 [http-nio-8080-exec-2] [INFO] p6spy - [statement] | 10 ms |
select
pd1_0.product_detail_id,
p1_0.name,
c1_0.name,
p1_0.manufacturer,
p1_0.description,
pd1_0.price,
pd1_0.attribute
from
product_detail pd1_0
left join
product p1_0
on p1_0.product_id=pd1_0.product_id
left join
category c1_0
on c1_0.category_id=p1_0.category_id
where
p1_0.name like '%Chair%' escape '!'
and pd1_0.is_deleted=false
limit
0, 30
2024-08-06 19:31:45.043 [http-nio-8080-exec-2] [INFO] p6spy - [statement] | 4445 ms |
select
count(pd1_0.product_detail_id)
from
product_detail pd1_0
left join
product p1_0
on p1_0.product_id=pd1_0.product_id
where
p1_0.name like '%Chair%' escape '!'
and pd1_0.is_deleted=false 로그를 확인해보면 검색 쿼리에는 10ms 정도, 카운트 쿼리에 4초 정도 걸리는것을 확인할 수 있다.
카운트 쿼리 에서 상당히 많은 시간이 걸린다는것을 알 수 있다.
두 쿼리의 실행 계획 분석을 해보자.
실행 계획 분석
검색 쿼리
사실 검색 쿼리는 10ms 정도로 아주 짧게 수행된다. 이유는 limit 의 최적화가 동작하기 때문이다.
DBMS는 옵티마이저를 이용해 쿼리를 최대한 최적화시켜 실행하기를 원한다.
때문에 limit 가 있다면 제한된 행 이후 연산은 불필요한 연산 이므로 DBMS는 수행하지 않는다.
때문에 조회 결과가 아주 많더라도 limit 에 의해 30건만 제공되기 때문에 빠른 속도로 수행되는 것이다.
검색 쿼리의 실행 계획을 분석해봤다.

type: 조회 타입product: 상품 이름으로 검색을 하는product테이블의 경우 풀스캔이 발생한다.category: 상품이 카테고리의 기본키를 외래키를 통해 조회하기 때문에 빠른 단일행 조힌이 발생한다.product_detail: 상품의 키를 외래키로 가지고 있는 상세 상품을 조회하기 때문에ref으로 조회한다.
key: 검색 인덱스product: 풀스캔이기 떄문에 인덱스가 없다.category: 기본키를 사용해 조회하기 때문에 프라이머리키 인덱스가 사용된다.product_detail: 상품의 키를 외래키로 가지고 있기 때문에 이것이 사용된다.
쿼리를 분석해본 결과 상품의 이름으로 product 테이블을 풀스캔해 상품을 찾고 이와 관련된 category, detail 정보를 조인해서 가져오게 된다.
이때 조인한 테이블은 외래키 인덱스 덕분에 빠르게 데이터를 찾아올 수 있다.

즉 검색쿼리에서 가장 많이 소요되는 작업은 product 테이블의 풀 스캔이다.
카운트 쿼리
카운트 쿼리의 실행 계획을 분석해 봤다.

결과를 보면 product 테이블을 풀스캔으로 스캔해 상품을 찾고, 그와 연관된 상세 상품을 조인을 통해 가져오는것을 알 수 있다.
즉 product 테이블의 풀스캔 시간을 줄이게 된다면 전체 쿼리 수행 시간이 짧아질 것이다.
SQL 최적화
원인을 찾았으니 최적화를 해보자.
검색 쿼리
검색쿼리는 like 로 검색하던 where 절을 FULLTEXT INDEX를 적용하는걸로 바꿨다.
그리고 join에 참여하는 드라이브 테이블을 인덱스가 적용된 product 테이블로 변경했다.
변경된 쿼리는 다음과 같다.
이전 검색 쿼리
explain
select
pd1_0.product_detail_id,
p1_0.name,
c1_0.name,
p1_0.manufacturer,
p1_0.description,
pd1_0.price,
pd1_0.attribute
from
/* 변경 1 */
product_detail pd1_0
left join
product p1_0
on p1_0.product_id=pd1_0.product_id
left join
category c1_0
on c1_0.category_id=p1_0.category_id
where
/* 변경 2 */
p1_0.name like '%Chair%' escape '!'
and pd1_0.is_deleted=false
limit
0, 30 변경 후 검색 쿼리
explain
SELECT
p1_0.name AS product_name,
c1_0.name AS category_name,
p1_0.manufacturer,
p1_0.description,
pd1_0.price,
pd1_0.attribute
FROM
/* 변경 1 */
product p1_0
LEFT JOIN
product_detail pd1_0
ON p1_0.product_id = pd1_0.product_id
LEFT JOIN
category c1_0
ON c1_0.category_id = p1_0.category_id
WHERE
/* 변경 2 */
MATCH(p1_0.name) AGAINST ('Chair')
AND pd1_0.is_deleted = false
LIMIT
0, 30;실행계획을 분석하면 원하던대로 인덱스를 타고 조회하는것을 확인할 수 있다.

카운트 쿼리
카운트 쿼리도 like 검색 where 절을 FULLTEXT 를 사용하도록 변경하고, join 드라이브 테이블을 인덱스가 적용된 proeuct 로 변경했다.
변경 전 카운트 쿼리
select
count(pd1_0.product_detail_id)
from
product_detail pd1_0
left join
product p1_0
on p1_0.product_id=pd1_0.product_id
where
p1_0.name like '%Chair%' escape '!'
and pd1_0.is_deleted=false 변경 후 카운트 쿼리
select
count(pd1_0.product_detail_id)
from
product p1_0
left join
product_detail pd1_0
on p1_0.product_id=pd1_0.product_id
where
MATCH(p1_0.name) AGAINST ('Chair')
and pd1_0.is_deleted=false ;카운트 쿼리도 like 대신 MATCH ... AGAINST 을 사용하고 실행계획을 분석해보면 풀스캔에서 FULLTEXT INDEX 스캔으로 줄어들은것을 확인할 수 있다.

실행 시간 비교
이제 변경된 쿼리의 실행 시간을 비교해보자.
특히 오래 걸리던 카운트 쿼리의 실행 시간을 비교해 봤다.
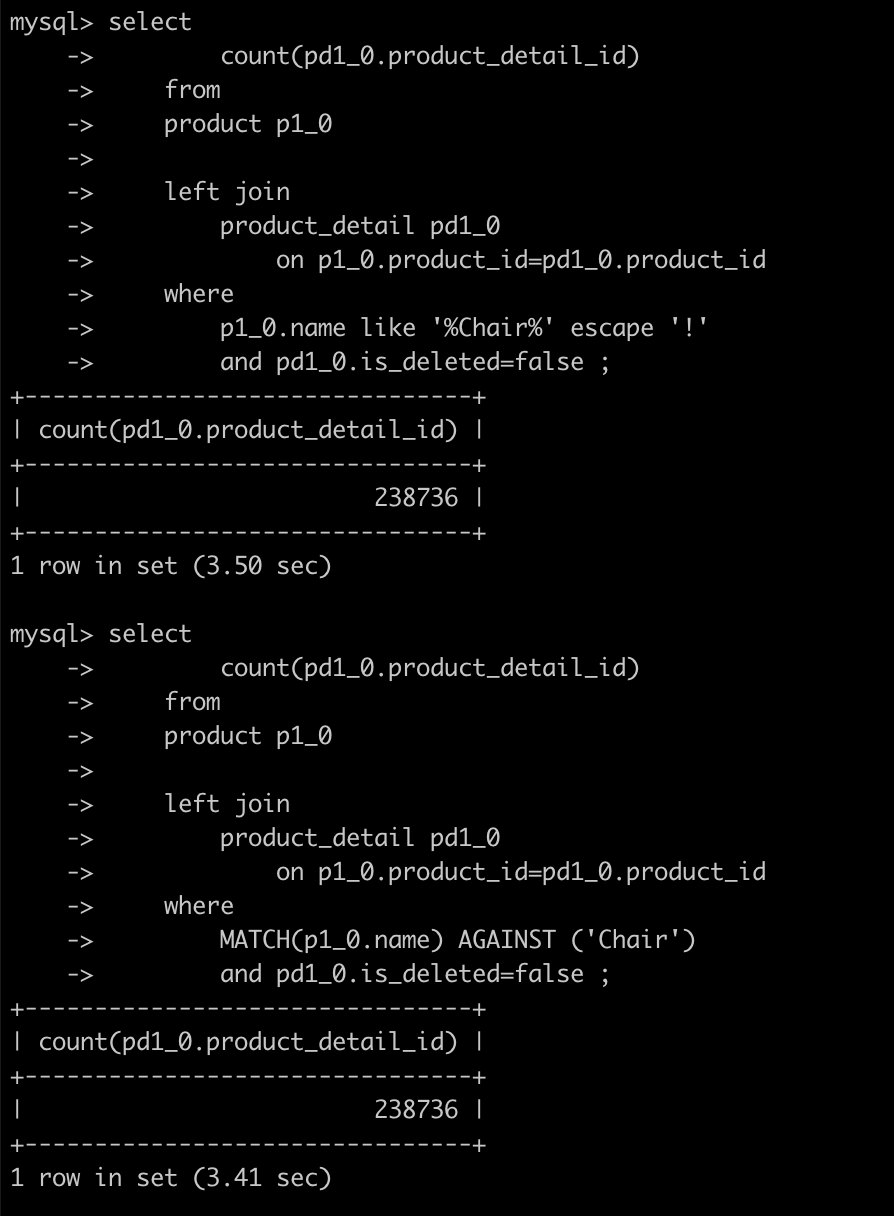
수행 시간을 보면 인덱스를 적용하기 전과 후 사이에 큰 차이가 없다는것을 알 수 있다.
왜 이런 결과가 나왔을까??
인덱스 비교
어떤점이 문제인지 확인해보기 위해 그냥 product 테이블만 조회를 해봤다.
인덱스를 거는 쿼리와, 걸지 않는 쿼리로 각각 카운트 쿼리를 날려봤다.
인덱스
select
count(*)
from
product p1_0
where
MATCH(p1_0.name) AGAINST ('Chair')인덱스 없이
select
count(*)
from
product p1_0
where
p1_0.name like '%Chair%'직접 수행해보면 인덱스를 탈때 조회 시간이 압도적으로 빠른것을 확인할 수 있다.
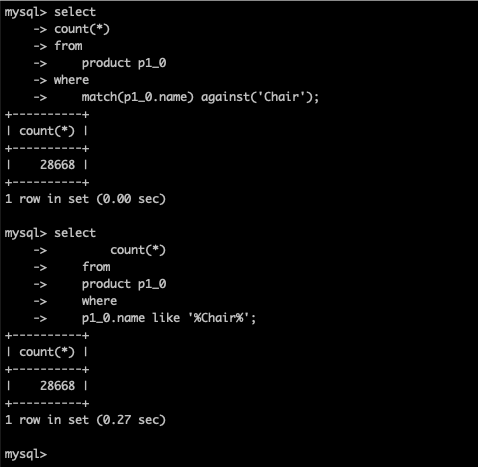
하지만 왜 join이 들어가면 별차이가 없어질까??
이 문제를 알아보기 위해 좀 더 자세히 알아보았다.
EXPLAIN ANALYZE 실행 계획 분석
EXPLAIN ANALYZE는 실제 실행을 바탕으로 쿼리를 분석한다. 또한 실행 시간까지 같이 제공해주기 때문에 훨씬 정확한 분석이 가능하다.
이쯤부터 카운트 쿼리 실행에 총 1000ms 가 걸렸는데, 이는 하도 실행을 해서 버퍼풀에 캐싱된 결과인듯 하다.
실제로 테스트 코드를 실행해 버퍼풀에 다른 데이터를 채우면 다시 4 ~ 5000ms 정도로 걸리는것을 확인할 수 있었다.
explain analyze {query} 로 분석할 수 있다.
기존 카운트 쿼리 EXPLAIN ANALYZE 결과
-> Aggregate: count(pd1_0.product_detail_id) (cost=319751 rows=1) (actual time=1045..1045 rows=1 loops=1)
-> Nested loop inner join (cost=294054 rows=256964) (actual time=0.12..1036 rows=238736 loops=1)
-> Filter: (p1_0.`name` like '%Chair%') (cost=68492 rows=62035) (actual time=0.0841..364 rows=28668 loops=1)
-> Table scan on p1_0 (cost=68492 rows=558375) (actual time=0.0781..182 rows=570553 loops=1)
-> Filter: (pd1_0.is_deleted = false) (cost=2.81 rows=4.14) (actual time=0.0157..0.023 rows=8.33 loops=28668)
-> Index lookup on pd1_0 using idx_product_detail_product_id (product_id=p1_0.product_id) (cost=2.81 rows=8.28) (actual time=0.0156..0.0224 rows=8.33 loops=28668)간단하게 설명하면
cost: 예상 비용을 말한다rows: 예상 결과 행수를 말한다.actual time = N ... M: 작업을 시작하는데까지N ms, 작업을 종료하는데까지M ms가 걸린다actual rows: 실제 읽은 행 수actual loopgs: 실제 루프 수
를 의미한다.
즉 위의 결과를 말로 설명하자면
-
count집계 작업- 첫 행을 읽는데까지
1045ms를 기다렸다. - 그리고 마지막 행을 작업하는데까지
1045ms가 걸렸다. - 즉 실질적인 수행시간은 거의
0ms인것임. - 첫행 수행시까지 오래걸린건, 루프를 돌며 조인을 처리하는데 걸린 시간이다.
- 모든 결과가 나오고 나서 이를 집계하는것은 거의
0ms라는 의미. - 작업의 결과로 1개의 행이 나왔다.
- 첫 행을 읽는데까지
-
Nested Loop inner Join작업- 첫행 수행시간까지
0.12ms가 걸림. - 마지막행 작업하는데까지
1036ms가 걸림. - 즉 두 테이블을 조인하는데 걸린 총 시간이
1036ms - 결과로
238,736행이 나오게 되었다.
- 첫행 수행시간까지
-
p1_0.name like '%Chair%필터링- 내부적으로 테이블 풀 스캔을 한다.
- 테이블 풀 스캔의 결과를 가지고
like '%Chair%'필터링을 수행한다. 570,553개의 테이블을 풀스캔 하는데 첫 행을 읽기까지0.0781ms가 걸리고 마지막 행을 읽는데까지182ms가 걸림- 이 풀스캔 결과를 필터링 하는데 첫행을 필터링하는데까지
0.0841ms가 걸리고 마지막 행을 필터링하는데까지364ms가 걸림 - 결과로
28,668행이 나오게 됨.
-
pd1_0.is_deleted = false필터링- 모든 테이블을 풀스캔하며 필터링 하는것이 아닌
product_id=p1_0.product_id작업의 결과만 필터링을 한다. product_id=p1_0.product_id작업은 인덱스를 사용해 검색하게 된다.- 인덱스를 통해
pd1_0에서 한 행을 읽는데 시작하기 까지0.0156ms가 걸리고, 모든 행을 읽는데까지0.0224ms가 걸린다. - 이 결과 평균
8.33개행을 읽고, 이 과정을28,668번 반복한다. - 인덱스를 통해 읽은
8.33개의 행을 필터링 하는데0.023ms가 수행된다.
- 모든 테이블을 풀스캔하며 필터링 하는것이 아닌
즉 %Chair% 인덱스를 통한 검색에 364ms 가 걸리고, 이 결과를 조인하는데 0.23 * 28668 = 659ms 가 걸려 총 1000ms가 걸리는 것이다.
explain analyze의 결과는 작업 순서를 말하는게 아니다.
작업 순서는 논리적인 순서와 의존성등으로 해석할 수 있다.
mysql-workbench로 플로우를 그려보면 다음과 같다.
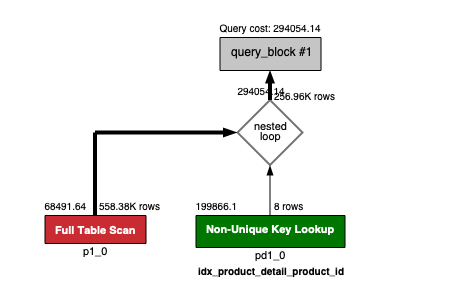
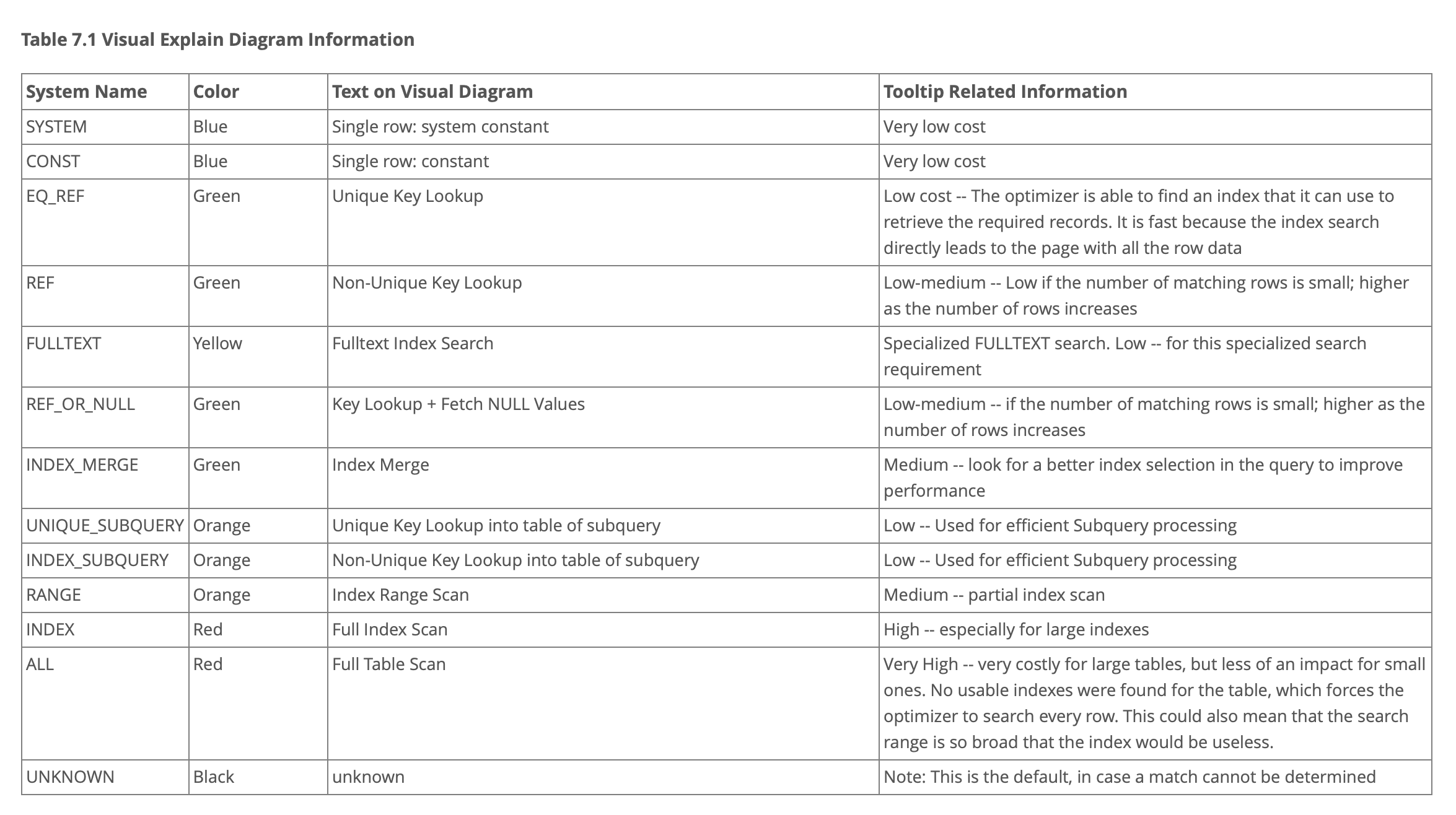
작업의 색깔의 의미는 다음 표와 같다.
빨강 -> 파랑 으로 갈수록 부하가 적다는것을 의미한다.
수정된 카운트 쿼리 EXPLAIN ANALYZE 결과
-> Aggregate: count(pd1_0.product_detail_id) (cost=5.15 rows=1) (actual time=1059..1059 rows=1 loops=1)
-> Nested loop inner join (cost=4.74 rows=4.14) (actual time=5.36..1050 rows=238736 loops=1)
-> Filter: (match p1_0.`name` against ('Chair')) (cost=1.1 rows=1) (actual time=5.3..161 rows=28668 loops=1)
-> Full-text index search on p1_0 using name (name='Chair') (cost=1.1 rows=1) (actual time=5.29..158 rows=28668 loops=1)
-> Filter: (pd1_0.is_deleted = false) (cost=3.22 rows=4.14) (actual time=0.0219..0.0305 rows=8.33 loops=28668)
-> Index lookup on pd1_0 using idx_product_detail_product_id (product_id=p1_0.product_id) (cost=3.22 rows=8.28) (actual time=0.0218..0.0299 rows=8.33 loops=28668)수정된 카운트 쿼리의 경우에도 결국 Chair 를 인덱스로 검색하는데 161ms 가 걸리지만, join 하는데 약 0.03 * 28668 = 860ms 가 걸리는 것이다.
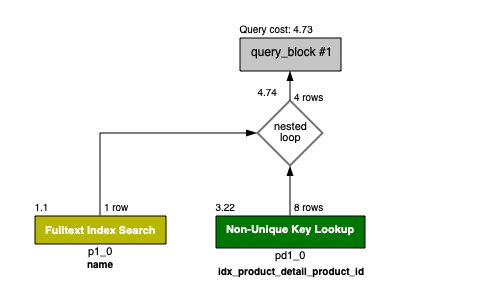
왜 join 에 이렇게 오래 걸릴까??
분석 결과
인덱스를 통해 검색 시간을 줄어들었지만 상품과 실제 상품을 join 하는데에 엄청난 시간이 걸린다.
이 join 시간을 줄이기 위한 노력을 해야한다.
JOIN 시간 줄이기
일반적으로 쿼리는 다음 순서대로 실행된다.
- FROM (JOIN)
- WHERE
- GROUP BY
- HAVING
- SELECT
- DISTINCT
- ORDER BY
- LIMIT, OFFSET
즉 나의 카운트 쿼리에서 JOIN 이후 WHERE 로 인덱스를 탔기 때문에 인덱스를 타기전 JOIN 에서 많은 시간이 소요된 것이다.
이 병목이 되는 JOIN 시간을 줄이기 위해 많은 시도를 해봤다.
1. FROM 절 서브쿼리
MATCH 로 검색을 먼저 수행하고, 그 결과 테이블을 JOIN 의 드라이브 테이블로 사용해 JOIN 시간을 줄여보려는 전략이다.
explain analyze
select
count(*)
from
(
select
*
from
product p
where
match(p.name) against ('Chair')
) as p
left join
product_detail pd
on pd.product_id = p.product_id
where
pd.is_deleted = false;-> Aggregate: count(0) (cost=5.06 rows=1) (actual time=862..862 rows=1 loops=1)
-> Nested loop inner join (cost=4.64 rows=4.14) (actual time=4.16..854 rows=238736 loops=1)
-> Filter: (match p.`name` against ('Chair')) (cost=1.1 rows=1) (actual time=4.12..94.8 rows=28668 loops=1)
-> Full-text index search on p using name (name='Chair') (cost=1.1 rows=1) (actual time=4.11..93 rows=28668 loops=1)
-> Filter: (pd.is_deleted = false) (cost=3.13 rows=4.14) (actual time=0.0178..0.0261 rows=8.33 loops=28668)
-> Index lookup on pd using idx_product_detail_product_id (product_id=p.product_id) (cost=3.13 rows=8.28) (actual time=0.0177..0.0255 rows=8.33 loops=28668)하지만 실행 시간에는 큰 차이가 없었다. (800ms로 줄어든것 같지만 캐싱이 없다면 다른 쿼리들과 동일한 시간으로 수행된다.)
역시 동일하게 index 검색에는 시간이 많이 소요되지 않았지만, 조인에서 엄청난 시간이 들었다.
2. JOIN 없이 실행
JOIN 에 시간이 많이 드는것 같아 JOIN 없이 in, exists를 사용해 시간을 줄여보려 했다.
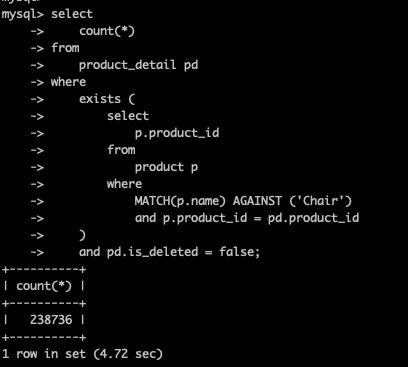
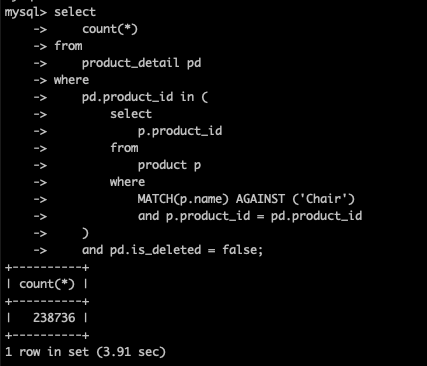
하지만 이역시도 큰 효과를 보지 못했다.
3. where문 수정
현재 상품의 소프트 삭제 때문에 is_deleted 라는 컬럼을 유지하고 있고, 조회시에도 이를 체크하게 된다.
혹시나 싶어서 이 체크 없이 실행을 해봤더니, 눈에 띄는 성능 향상이 있었다.
explain analyze
select
count(pd1_0.product_detail_id)
from
product p1_0
left join
product_detail pd1_0
on p1_0.product_id=pd1_0.product_id
where
MATCH(p1_0.name) AGAINST ('Chair'); -> Aggregate: count(pd1_0.product_detail_id) (cost=3.77 rows=1) (actual time=187..187 rows=1 loops=1)
-> Nested loop left join (cost=2.94 rows=8.28) (actual time=3.99..179 rows=239410 loops=1)
-> Filter: (match p1_0.`name` against ('Chair')) (cost=1.1 rows=1) (actual time=3.96..79.9 rows=28668 loops=1)
-> Full-text index search on p1_0 using name (name='Chair') (cost=1.1 rows=1) (actual time=3.96..78.4 rows=28668 loops=1)
-> Covering index lookup on pd1_0 using idx_product_detail_product_id (product_id=p1_0.product_id) (cost=1.84 rows=8.28) (actual time=0.00196..0.003 rows=8.33 loops=28668)조인 결과에서 is_deleted 컬럼 검사를 뺀것만으로 한 행을 읽는데 0.03ms 에서 0.003ms 로 10배의 속도 향상이 있었다.
즉 is_deleted 컬럼 비교가 성능에서 많은 시간을 잡아먹고 있는 것이다.
is_deleted 컬럼에 인덱스도 추가해 봤지만, 카리널리티가 너무 낮은 탓에 (true, false) 인덱스를 타지도 않았다.
4. 다중 컬럼 인덱스 추가
카운트 쿼리에서 가장 시간을 많이 먹는 부분은 상품이 삭제되었는지 확인하기 위한 is_deleted 컬럼 비교다.
게다가 카디널리티가 너무 낮은 탓에 인덱스를 탈수도 없어서 모든 데이터를 하나하나 비교해야 한다. 그러다 보니 많은 시간과 비용(CPU) 가 들어가는 것이다.
하지만 현재 비즈니스 로직이나, 전체적인 시스템에서 is_deleted 컬럼을 삭제하기에는 힘들기 때문에 다른 방법을 찾아봤다.
그러던중 다중 컬럼 인덱스를 알게되었고 현재
product_id로 조인을 하고 있기에product_id와is_deleted를 하나의 인덱스로 만들면 두개의 조건을 동시에 보기 때문에 효율적으로 처리할 수있지 않을까? 라는 생각이 들었다.
바로 다중 컬럼 인덱스를 적용해 봤다.
create index idx_product_id_is_deleted on product_detail (product_id, is_deleted);그리고 카운트 쿼리를 테스트 했더니 놀라운 성능 향상이 있었다.
바로 분석을 해봤다.
-> Aggregate: count(pd1_0.product_detail_id) (cost=3.58 rows=1) (actual time=287..287 rows=1 loops=1)
-> Nested loop inner join (cost=2.76 rows=8.26) (actual time=4.16..279 rows=238736 loops=1)
-> Filter: (match p1_0.`name` against ('Chair')) (cost=0.916 rows=1) (actual time=4.14..154 rows=28668 loops=1)
-> Full-text index search on p1_0 using name (name='Chair') (cost=0.916 rows=1) (actual time=4.14..152 rows=28668 loops=1)
-> Covering index lookup on pd1_0 using idx_product_id_is_deleted (product_id=p1_0.product_id, is_deleted=false) (cost=1.84 rows=8.26) (actual time=0.00279..0.00389 rows=8.33 loops=28668)기존 에는 product 테이블의 결과를 product_detail 테이블에서 join 하기 위해 product_id 인덱스로 조인을 수행하고, is_deleted 컬럼을 하나하나 비교했다.
하지만 다중 컬럼 인덱스를 적용하니 두 동작이 한번에 이루어져 300ms 라는 엄청난 성능 향상이 있었다.
최적화된 쿼리로 테스트
최적화된 SQL로 동일 테스트를 진행해 봤다.
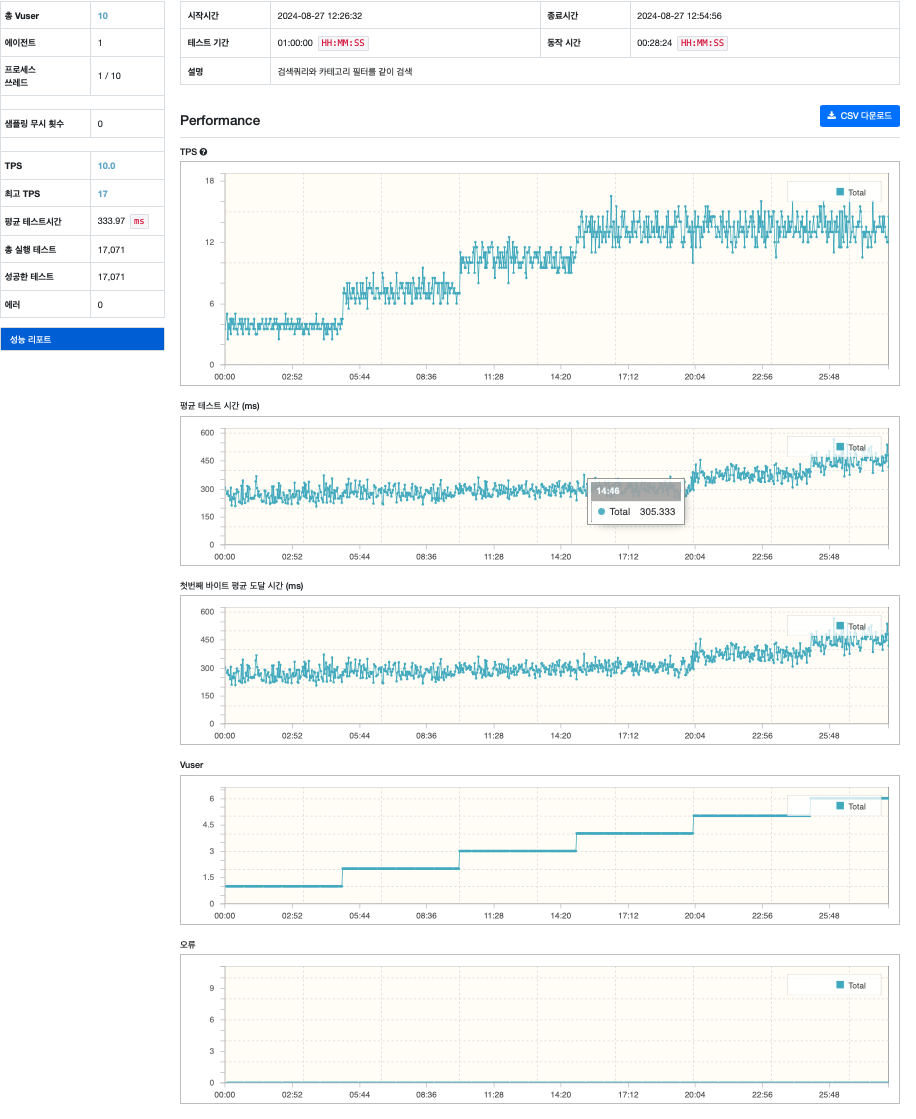
- RPS :
1 → 13 - 응답시간 :
4000ms => 400ms
쿼리 최적화 전보다 성능이 약 10배 정도 향상된것을 확인할 수 있다.
정리
검색 API에서 한번 검색에 약 5초씩 걸리는 문제가 있었다.
이 문제를 해결하기 위해 SQL문을 분석해본 결과, 검색 쿼리는 limit 를 통해 쿼리의 양을 조절하기 때문에 비교적 빠른 속도로 수행이 가능했지만 카운트 쿼리는 해당하는 모든 상품을 필터링 해야하는 특성상 약 4~5초 정도 걸리게 되었다.
FULLTEXT INDEX를 적용해 검색에 소요되는 시간을 줄였지만 가장 큰 병목인 카운트 쿼리의 join 에 걸리는 시간은 줄일 수 없었다.
카운트 쿼리의 join 의 성능을 분석해보니 소프트 삭제를 위한 is_deleted 필드 때문에 join 이후 is_deleted 필드 검사가 일어나고 그러다 보니 엄청난 성능 저하가 있게 된다는것을 알게되었다.
그래서 다중 컬럼 인덱스를 적용해 join 에 참여하는 컬럼과 is_deleted=false 인 컬럼을 한번에 찾음으로써 성능 향상을 이끌어낼 수 있었다.
그 결과 약 카운트 쿼리 수행속도를 약 4000ms 에서 400ms 로 큰 성능 향상을 이끌어 낼 수 있었다.
ref
