기본적인 자료구조로 자주 사용되는 스택이지만, 자바의 Stack 클래스는 그렇지 못한 것 같다.
Stack 클래스에게 어떤 사연이 있는지 알아보자.
스택이란?
스택은 아래 그림처럼 데이터를 쌓아 올리듯이 저장하는 자료 구조다.
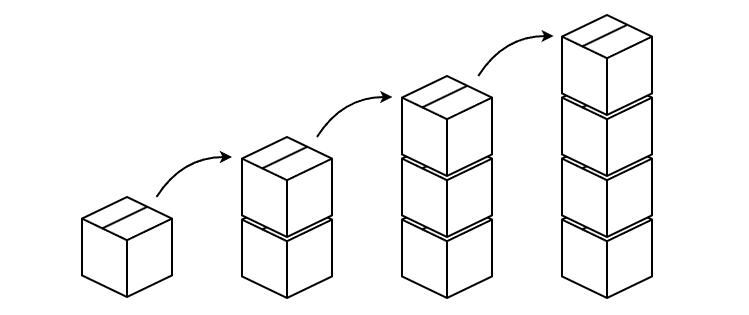
스택은 가장 마지막에 저장한 데이터를 가장 먼저 꺼내는데, 이런 특징을 후입선출(LIFO)이라고 한다.
메서드 호출 또는 웹 브라우저의 앞/뒤로 버튼 등에서 사용되며, JVM 내부 런타임 데이터 영역의 JVM Stack에서도 스택 구조를 사용해 효율적으로 메모리를 관리한다.
그런데 왜 자바에서는 Stack 클래스를 사용하지 않을까?
Stack 클래스는 디자인이 잘못되었다.
자바의 Stack 클래스(이하 Stack)는 대표적으로 상속을 잘못 받은 클래스다. 상위 클래스로 Vector를 상속받는데, 여기서 몇 가지 문제가 발생한다.
Vector는 ArrayList와 같이 List 인터페이스를 구현한 컬렉션 프레임워크이며, 쓰레드 안전 여부를 제외하고는 ArrayList와 거의 동일하다.
synchronized
쓰레드를 안전하게 사용하기 위해 제공하는 자바의 예약어로, 메서드에 선언하거나 블록 형태로 사용할 수 있다. 여러 쓰레드가 동시에 접근하는 경우, 먼저 접근한 쓰레드의 처리가 끝날 때까지 다른 쓰레드의 접근을 제한한다.
synchronized로 인한 성능 저하
사실 이 문제 때문에 Vector도 잘 사용하지 않는다. Vector는 모든 메서드에 synchronized를 사용하기 때문에 간단하게 조회만 하는 경우에도 동기화로 인해 성능 저하가 발생한다. 실제로 Vector의 메서드를 보면 synchronized 키워드가 있는 것을 확인할 수 있다.
public synchronized E get(int index) {
}
public synchronized void addElement(E obj) {
}
public synchronized void removeElementAt(int index) {
}Stack에서 제공하는 메서드 역시 synchronized를 사용해서 동기화 처리하는데, 내부적으로 Vector가 제공하는 메서드를 사용함으로써 이중으로 동기화 처리된다.
| Stack 메서드 | 내부적으로 사용되는 Vector 메서드 |
|---|---|
| push(E item) | addElement(E obj) |
| E pop() | removeElementAt(int index) |
| E peek() | elementAt(int index) |
때문에 단일 쓰레드 환경에서 Stack을 사용하면, 불필요한 동기화 작업으로 인해 성능 저하를 피할 수 없게 된다.
그리고 보통 동기화가 필요한 작업들은 묶어서 처리하기 때문에 메서드 단위로 동기화되어 있으면 멀티쓰레드 환경에서도 효율적으로 사용할 수 없다.
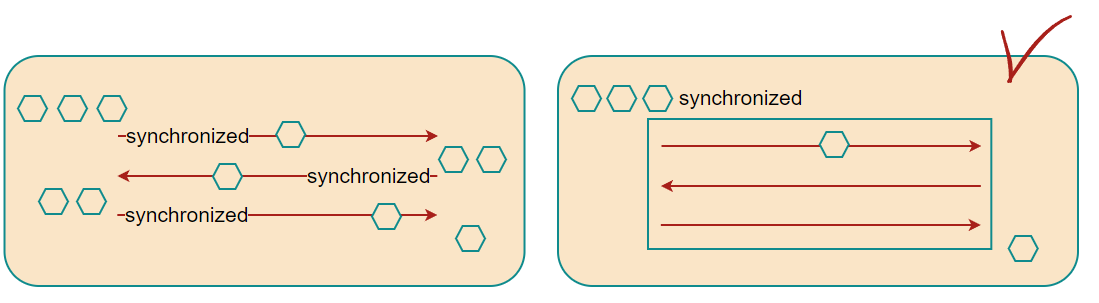
심지어 항상 쓰레드에 안전한 것도 아니다. 메서드 실행에 한해서는 쓰레드에 안전하지만 객체 자체에 대해서는 동기화 처리가 되어있지 않기 때문에 여전히 쓰레드에 안전하지 않다.
결과적으로 어떤 환경이든 Vector와 Stack을 사용할 이유가 없다.
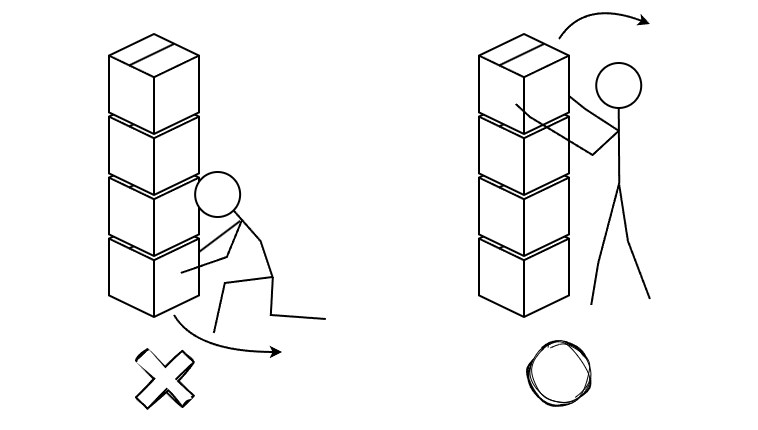
후입선출 구조 위반
앞서 스택의 구조에 대해 알아볼 때, 스택은 후입선출 구조라고 했다. 따라서 해당 구조의 규칙을 위반하는 접근은 불가능해야 한다. 하지만 Stack은 Vector가 제공하는 다음 메서드를 통해 특정 인덱스에 데이터를 추가하거나 제거할 수 있다.
| Type | Method | Description |
|---|---|---|
| void | add(int index, E element) | Inserts the specified element at the specified position in this Vector. |
| void | removeElementAt(int index) | Deletes the component at the specified index. |
스택 구조상 데이터는 최상단을 통해서만 저장되어야 한다. 하지만 아래 예시를 보면 add(int index, E element) 메서드를 통해 원하는 위치에 자유롭게 저장하는 모습을 볼 수 있다.
public class StackTest {
public static void main(String[] args){
Stack stack = new Stack<>();
stack.push(new Integer(1));
stack.push(new Integer(2));
stack.push(new Integer(3));
stack.push(new Integer(4));
stack.push(new Integer(5));
stack.add(2, 10);
int size = stack.size();
for (int i=0; i< size; i++) {
System.out.println("target = " + stack.pop());
}
}
}target = 5
target = 4
target = 3
target = 10 //규칙 위반!
target = 2
target = 1결과적으로 Stack은 Vector를 상속받아 후입선출 구조의 규칙을 위반하게 된다.
초기 크기를 지정하지 못한다.
이 문제는 Stack 자체의 문제인데, 아래와 같이 기본 생성자 하나만 제공하기 때문에 생성 시 초기 크기를 지정하지 못한다.
| Constructor | Description |
|---|---|
| Stack() | Creates an empty Stack. |
따라서 사용하려는 데이터의 크기를 예측할 수 있어도 초기 크기를 지정할 수 없다.
그럼 왜 Vector를 상속받았을까?
Stack과 Vector 모두 자바의 초기 버전부터 제공되었는데, 당시 인터넷 열풍으로 서둘러 출시하다 보니 일부 클래스는 신중하게 설계되지 않았다고 한다. 해당 클래스들은 하위 호환성 때문에 남아있으며, 사용을 지양해야 한다.
- Why Stack extends Vector in JDK? -
Stack의 문서를 보면 다음과 같이 설명하고 있다.
'A more complete and consistent set of LIFO stack operations is provided by the Deque interface and its implementations, which should be used in preference to this class.'
Deque 인터페이스가 보다 완벽하고 일관된 LIFO 구조를 제공하고 있기 때문에 Stack 클래스보다 우선적으로 사용할 것을 권장한다.
Deque
양쪽 끝에서 요소를 저장하거나 제거할 수 있는 컬렉션 프레임워크이며, "double ended queue"의 줄임말로 "deck"라고 발음한다.
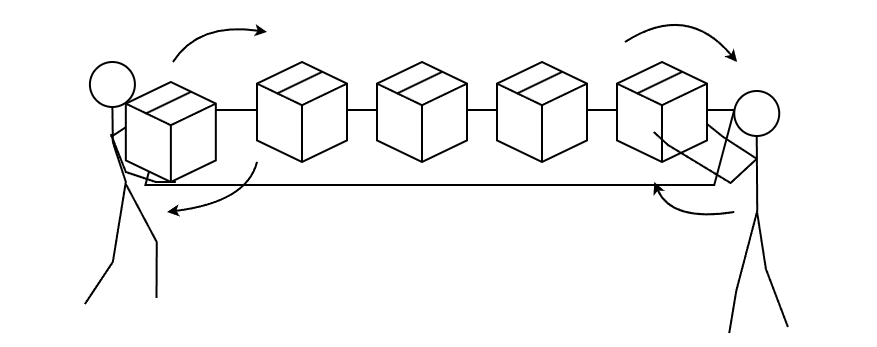
마찬가지로 Deque의 문서에서도 Stack 대신 사용할 것을 권장한다.
'Deques can also be used as LIFO (Last-In-First-Out) stacks. This interface should be used in preference to the legacy Stack class.'
Deque은 시작 지점에서 요소를 저장하고 제거하는 방식으로 스택처럼 사용할 수 있다. Deque에서 지원하는 스택 관련 메서드는 아래와 같다.
| Stack Method | Equivalent Deque Method |
|---|---|
| push(e) | addFirst(e) |
| pop() | removeFirst() |
| peek() | getFirst() |
List 인터페이스와 달리 이 인터페이스는 요소의 인덱스에 접근을 지원하지 않는다. 따라서 특정 위치에 데이터를 저장하거나 제거할 수 없다.
ArrayDeque
Deque의 구현 클래스로 스택에 필요한 모든 작업을 제공하며, Stack보다 빠르다. 또 Stack은 초기 크기를 지정할 수 없었지만 ArrayDeque은 생성자로 초기 크기를 지정할 수 있다.
| Constructor | Description |
|---|---|
| ArrayDeque(int numElements) | Constructs an empty array deque with an initial capacity sufficient to hold the specified number of elements. |
Stack으로 사용할 수 있도록 지원하는 메서드는 다음과 같다.
| Modifier and Type | Method | Description |
|---|---|---|
| void | addFirst(E e) | Inserts the specified element at the front of this deque. |
| E | removeFirst() | Retrieves and removes the first element of this deque. |
| E | getFirst() | Retrieves, but does not remove, the first element of this deque. |
쓰레드에 안전해야 한다면!
ArrayDeque은 Stack보다 빠른 대신 쓰레드에 안전하지 않다. java.util.concurrent 패키지에 있는 ConcurrentLinkedDeque 또는 LinkedBlockingDeque을 사용하면 쓰레드에 안전하게 사용할 수 있다. 자세한 사용법은 이곳에서 확인할 수 있다.
하지만 여전히 완전한 스택은 아니다.
사실 ArrayDeque도 후입선출 구조의 규칙을 위반한다.
ArrayDeque을 스택으로 사용할 때, add(E e) 메서드를 사용하면 어떻게 될까?
'그냥 저장한 거 아닌가?'라고 생각할 수도 있지만 그렇지 않다.
| Type | Method | Description |
|---|---|---|
| boolean | add(E e) | Inserts the specified element at the end of this deque. |
앞서 스택 구조로 사용하려면 시작 지점에서 저장하고 제거해야 한다고 했다. 하지만 add(E e) 메서드는 마지막 지점에 요소를 저장하기 때문에 실수로 해당 메서드를 사용한다면 후입선출 구조를 위반하게 된다.
그래도 인덱스에 대한 접근을 지원하지 않고, Stack에 보다 빠른 성능을 제공하기 때문에 ArrayDeque을 사용하는 것이 최선의 선택이라고 할 수 있다.
정리
Stack을 사용하지 않는 이유와 이를 대체하는 클래스에 대해서 알아보았다. 이제까지의 내용을 간단하게 정리해 보자.
-
스택은 후입선출 자료구조다.
-
Stack을 사용하지 않는 이유는 Vector를 잘못 상속받았기 때문이다.
-
모든 메서드에 synchronized를 사용해 성능 저하가 발생한다.
-
특정 인덱스에 접근할 수 있어 후입선출 구조의 규칙을 위반한다.
-
-
Stack 대신 ArrayDeque을 사용하자.
-
쓰레드에 안전하지 않은 대신 Stack 보다 빠른 성능을 제공한다.
-
특정 인덱스에 접근할 수 없기 때문에 후입선출 구조의 규칙을 위반하지 않는다.
-
초기 크기를 설정할 수 있어 효율적으로 사용할 수 있다.
-
참고
Java API Documents - Stack
Java API Documents - Vector
Java API Documents - Deque
Java API Documents - ArrayDeque
Java API Documents - ConcurrentLinkedDeque
Java API Documents - LinkedBlockingDeque
https://devlog-wjdrbs96.tistory.com/244
https://tecoble.techcourse.co.kr/...
https://stackoverflow.com/...
https://inpa.tistory.com/entry/JCF...
