
Andrew Ng 박사님의 딥러닝 강의 영상을 보며 공부하고 작성한 요약 정리 글입니다.
Youtube 전체 강의 재생목록 :
Improving Deep Neural Networks: Hyperparameter Tuning, Regularization and Optimization (Course 2 of the Deep Learning Specialization)
유튜브 전체 강의 재생목록은 총 34개의 영상으로 구성되어 있습니다. 본 글(Part 1)은 영상 1부터 영상 8까지 총 8개의 영상만을 다루었습니다.
1. Train/Dev/Test Sets
Youtube 강의 영상 : Train/Dev/Test Sets (C2W1L01)
훈련, 개발, 테스트 데이터 셋을 어떻게 설정할지에 관한 좋은 선택을 내리는 것은 좋은 성능을 내는 네트워크를 빠르게 찾는데 큰 영향을 준다.
신경망을 훈련시킬 때 결정해야하는 것들은 다음과 같이 매우 많다.
- 층의 수(number of layers)
- 뉴런의 수(number of hidden units)
- 학습률(learning rate)
- 활성화 함수(Activation Function)
하지만 이 모든 것들에 대한 적절한 값을 처음부터 추측하는 것은 거의 불가능하다.
이 외에 다른 하이퍼 파라미터(hyper parameters)도 마찬가지이다.
따라서 실질적으로 머신러닝을 적용하는 것은 매우 반복적인 과정을 거쳐야한다.
1) 처음에는 아이디어로 시작한다.
2) 그리고 특정 개수의 층과 유닛을 가지고 특정 데이터 셋에 맞는 신경망을 만든다.
3) 이를 코드로 작성하고 실행하고 성능을 검사한다.
4) 그 결과에 기반하여 아이디어를 개선하고 몇 가지 선택을 수정하게 된다. 그리고 더 나은 신경망을 찾기 위해 이 과정을 반복한다.
신경망은 자연어 처리, 컴퓨터 비전, 음성 인식 등 여러 분야에 기여를 하였다. 하지만 어떤 분야에 적용되고 사용되는 직관이 다른 영역에도 적용되지는 않는다. 따라서 많은 분야에서 딥러닝에 아주 경험이 많은 사람일지라도 첫 시도에 하이퍼 파라미터에 대한 최고의 선택을 올바르게 추측하는 것은 거의 불가능하다.
매우 반복적인 과정 속에서 빠른 진전을 이루는데 영향을 미치는 것들은 이 사이클을 얼마나 효율적으로 돌 수 있는지와 데이터 셋을 잘 설정하는 것이다. 훈련, 개발, 테스트 셋을 잘 설정하는 것은 과정을 더 효율적으로 만든다.
전통적인 방법으로는 모든 데이터를 가져와서 일부를 잘라서 훈련 셋으로 만들고 다른 일부는 교차 검증(또는 개발=dev) 셋으로 만들고 나머지 부분은 테스트 셋으로 만든다.
머신러닝 이전 시대의 관행적으로는 훈련 데이터 셋을 70%, 테스트 데이터 셋을 30%으로 한다. 혹은 훈련, 개발, 테스트 셋을 각각 60%, 20%, 20%로 나눈다. 데이터 샘플의 수가 100개, 1000개, 혹은 10000개였을 경우에는 합당한 비율이었다. 하지만 총 100만 개 이상의 샘플이 존재하는 현대 빅데이터 시대에는 개발 셋과 테스트 셋을 훨씬 더 작은 비율로 나누는 것이 트렌드가 되었다. 둘은 확인의 용도이므로 성능을 평가하는 정도로만 쓰면 되기 때문이다. 따라서 예를 들어 백만 개의 샘플이 있다면 개발과 테스트 데이터 샘플을 각각 만 개 정도로 설정해도 충분하다. 즉, 98%의 훈련 셋, 1% 개발 셋, 1% 테스트 셋가 된다. 데이터가 더 많다면 개발과 테스트 셋을 이보다 더 적게 설정해도 된다.
결론적으로, 데이터 셋을 나눌 때 데이터의 수가 적다면 전통적인 70/30이나 60/20/20 으로 비율을 설정해도 괜찮지만 훨씬 데이터의 수가 많다면 개발과 테스트 데이터 셋의 비율을 더 적게 설정하는 것도 좋은 방법이다.
2. Bias/Variance (C2W1L02)
Youtube 강의 영상 : Bias/Variance (C2W1L02)
아래의 사례등을 통해 편향(Bias)과 분산(Variance)에 대한 개념을 완벽히 이해하려 한다.
1) 높은 편향(High Bias)
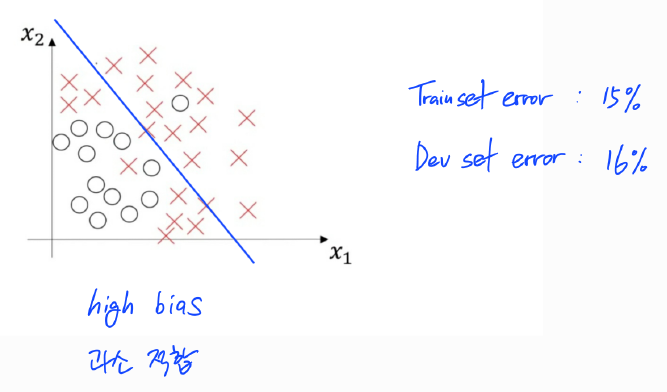
훈련 셋에 대하여 위와 같이 O와 X를 분류하였다면 이는 제대로 분류해내지 못한 과소적합(Underfitting)된 상황임을 알 수 있다. 훈련 셋 오차가 15%이고 개발 셋 오차가 16% 정도 나왔을 경우가 이에 해당한다.
2) 높은 분산(High Variance)
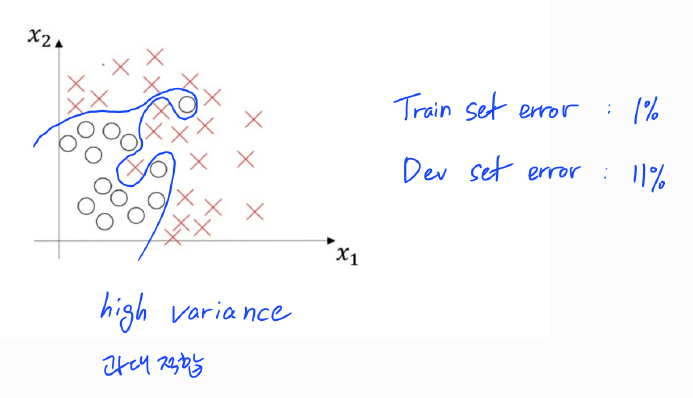
위의 사례의 경우에는 훈련 데이터 셋에 너무 과하게 최적화되고 일반화가 전혀 되지 않은 과대적합(Overfitting)한 상황이다. 훈련 셋 오차가 1%, 개발 셋 오차가 11% 정도 나왔다면 이러한 상황에 처한 것이다.
3) 높은 편향(High Bias) & 높은 분산(High Variance)
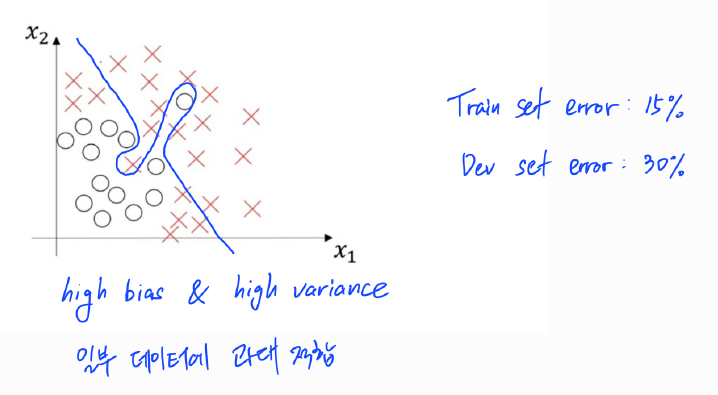
위의 경우에는 편향도 높고 분산도 높은 최악의 상황으로 볼 수 있다. 훈련 데이터 셋 전체에 최적화되지도 못했을 뿐더러 극히 일부 데이터에만 과대적합된 상황이다. 따라서 학습 셋 오차도 높고 개발 셋 오차는 더 높게 나올 것이다.
4) 낮은 편향(Low Bias) & 낮은 분산(Low Variance)
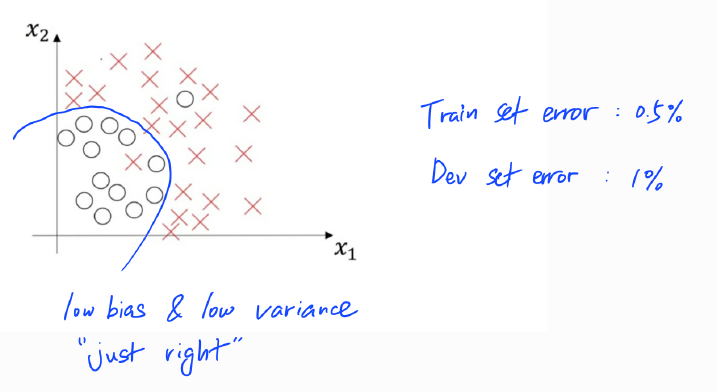
이 사례가 가장 훈련 셋에 최적화도 잘 되고 개발 셋에도 일반화가 잘 될 성능이 가장 좋은 경우이다. 적당히 적합(fit)한 모델이라고 볼 수 있다. 훈련 셋과 개발 셋 모두에서 오차가 매우 작게 나올 것이다.
단, 위의 분석은 인간 수준의 성능의 오차가 거의 0%라는 가정에 근거한다. 더 일반적으로는 최적의 오차, 가끔은 베이지안 오차라고 불리는 베이지안 최적 오차가 거의 0%라는 가정이다. 즉, 인간의 경우 예측의 정확도가 100%라는 것이다. 예를 들어 이미지를 분류할 때 이미지가 흐릿하여 인간 또한 잘 분류하지 못하여 최적 오차 또는 베이지안 오차가 15%인 경우에는 이야기가 달라진다. 이때는 훈련 셋의 오차 약 15%이고 개발 셋 오차가 16% 정도라면 매우 좋은 성능을 가지는 모델이다.
결론적으로 훈련 데이터 셋에서 개발 데이터 셋으로 갈 때 오차가 얼마나 커지는지에 따라서 분산과 편향 문제가 얼마나 심각한지에 대한 감을 잡을 수 있다. 다시 말해, 훈련 데이터 셋에서 개발 데이터 셋으로 일반화를 잘 하느냐에 따라 분산과 편향에 대한 감이 달라진다고 볼 수 있다. 단, 이는 베이지안 오차가 꽤 작고 훈련 셋과 개발 셋이 같은 확률 분포에서 왔다는 가정 아래에 이루어진다. 분산과 편향을 확인하여 현 상황을 진단하고 이후 적절한 조치를 취할 수 있어야 한다.
3. Basic Recipe for Machine Learning (C2W1L03)
Youtube 강의 영상 : Basic Recipe for Machine Learning (C2W1L03)
신경망 훈련 기본 레시피
1. 편향(Bias) 확인
먼저 편향의 정도를 확인한다. 편향을 확인하기 위해서는 훈련(Train) 데이터 셋의 성능(오차)를 확인한다. 편향이 높다면 훈련 셋에도 최적화가 되지 않는다. 높은 편향을 보인다면 다음과 같은 방법을 이용하여 해결할 수 있다.
- (더 많은 은닉층 혹은 은닉 유닛을 갖는) 큰 네트워크 선택
- Train longer or 더 발전된 최적화 알고리즘 사용
- 다른 신경망 아키텍쳐 사용
위와 같은 방법들을 편향 문제를 해결할 때까지 반복한다. 보통 충분히 큰 네트워크라면 훈련 데이터에는 최적화시킬 수 있다. 물론 과대적합 될 수도 있다. 단, 이미지가 흐릿한 경우(베이지안 오차가 높다면)에는 애초에 최적화가 불가능하다.
2. 분산(Variance) 확인
편향 문제를 해결한 다음은 분산 문제가 있는지 확인해야 한다. 즉, 꽤 좋은 훈련 셋 성능에서 꽤 좋은 개발 셋 성능을 일반화할 수 있는지를 평가해야 한다. 이를 평가하기 위해서는 개발(Dev) 데이터 셋의 성능을 확인한다. 높은 분산을 가진다면 다음의 방법들을 시도해 볼 수 있다.
- 더 많은 데이터 확보
- Regularization(정규화)
- 다른 신경망 아키텍쳐 사용
이 방법들을 낮은 편향과 분산을 찾을 때까지 계속 반복하여 시도한다.
편향-분산 트레이드오프(Trade-off)
초기 머신러닝의 시대에는 편향-분산 트레이드오프에 대한 논의가 있었다. 시도할 수 있는 많은 방법들이 편향을 증가시키고 분산을 감소시키거나, 편향을 감소시키고 분산을 증가시키기 때문이다. 그러나 현대의 딥러닝 빅데이터 시대에는 더 큰 네트워크를 훈련시키는 방법(높은 편향 해결)과 더 많은 데이터를 얻는 방법(높은 분산 해결)이 항상 적용되지는 않지만 트레이드오프를 크게 발생시키지 않는다. 즉, 더 큰 네트워크를 사용하면 분산을 해치지 않고 편향만이 감소하며, 더 많은 데이터를 얻는 것도 편향을 해지치 않고 분산만을 감소시킨다.
Regularization(정규화)는 또다른 분산을 줄이는 유용한 기술이다. 정규화를 사용하면 편향을 조금 증가시킬 수 있어 약간의 편향-분산 트레이드오프가 존재한다. 하지만 충분히 큰 네트워크를 사용한다면 그렇게 크게 증가하지는 않는다.
결론적으로, 신경망을 훈련시킬 때 먼저 편향을 확인하고 문제가 있을 시 이를 여러 방법론으로 해결한 뒤, 분산을 확인하고 또 문제가 있을 시 여러 방법들을 시도하여 해결한다. 각각을 해결하기 위한 적절한 방법들은 서로 다를 수 있으니 정확히 상황을 파악하고 적합한 해결책을 사용해야 효율적으로 신경망을 구현할 수 있다.
또한 초기에는 편향-분산 트레이드오프가 매우 중요한 이슈였으나 딥러닝이 매우 발달한 현대에는 편향과 분산이 서로 영향을 미치지는 않는다.
4. Regularization (C2W1L04)
Youtube 강의 영상 : Regularization (C2W1L04)
높은 분산으로 신경망이 데이터를 과대적합(Overfitting)하는 문제가 의심된다면 가장 처음 시도해야할 것은 정규화(Regularization)이다. 높은 분산을 해결하기 위한 다른 방법으로 더 많은 훈련 데이터를 확보할 수도 있지만 비용이 많이 들어 가능하지 않은 방법일 수도 있다. 따라서 이럴 경우 정규화를 시도해볼 수 있다.
정규화의 종류에는 L1 정규화와 L2 정규화가 있다. 모델을 압축하려는 목적이 있지 않는 한 대부분 사람들은 네트워크를 훈련할 때 L2 정규화를 많이 사용한다. 정규화를 하게 되면 손실함수에 추가적인 항을 더해주어 손실을 줄이기 위해 결국 가중치(W) 값들이 작아지게 된다.
(L1 정규화와 L2 정규화의 자세한 공식과 구현하는 방법에 대한 설명은 유튜브 강의 영상 보면 확인할 수 있습니다.)
결론적으로, 높은 분산 문제가 발생하였을 경우 더 많은 훈련 데이터 셋을 확보할 수 없다면 정규화를 시도해볼 수 있다.
5. Why regularization reduces overfitting (C2W1L05)
Youtube 강의 영상 : Why regularization reduces overfitting (C2W1L05)
과대적합(Overfitting)이 발생하는 원인에는 네트워크가 너무 커서 매우 복잡한 비선형 함수를 만들기 때문일 수도 있다. 즉, 다음과 같은 함수의 경우이다.
정규화는 이를 해결하여 과대적합의 가능성을 줄여줄 수 있다. 정규화를 할 경우 아래와 같이 추가적인 항(L2 정규화)을 더해준다.
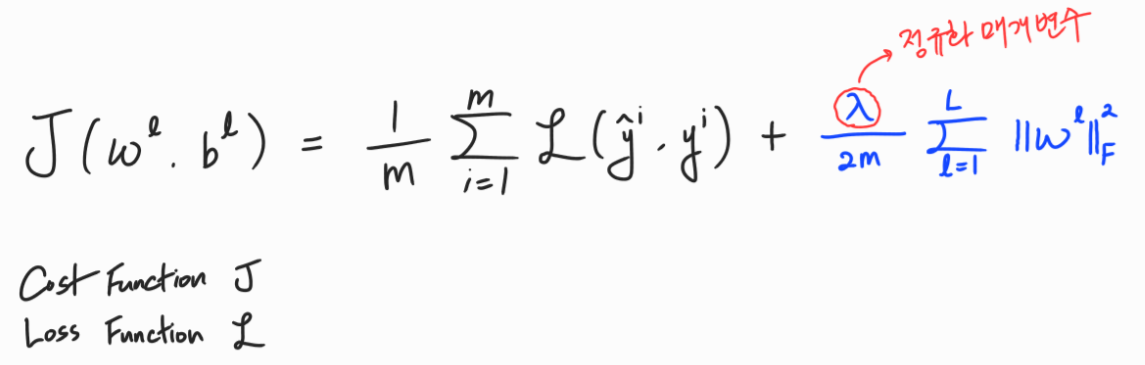
이 때 정규화 매개변수 값을 크게 설정할 경우 손실(Cost)을 줄이기 위해 가중치 행렬(W)이 0에 상당히 가깝게 설정된다. 따라서 많은 은닉층의 유닛을 0에 가까운 값으로 설정하여 각 유닛들의 영향력을 줄이게 된다. 이는 직관적으로 보면 신경망이 훨씬 더 간단하고 작은 신경망의 역할을 하게 되는 것이다. 물론 여전히 층의 개수나 유닛의 수가 바뀐 것은 아니지만 역할은 로지스틱 회귀와 비슷해진다. 따라서 과대적합을 과소적합의 형태에 가깝게 만들어 줄 수 있다. 이 때 명심할 점은 가중치 매개변수를 적당한 값으로 정해야 한다.
왜 정규화가 과대적합을 막는데 도움을 주는지에 관한 또 다른 직관이 있다. 활성화 함수가 tanh일 경우를 생각해보자.
즉, g(Z) = tanh(Z)인 경우이다. 이때 Z가 아주 작은 경우에는 아래의 그림과 같이 tanh 함수의 선형 영역에 위치하게 된다.
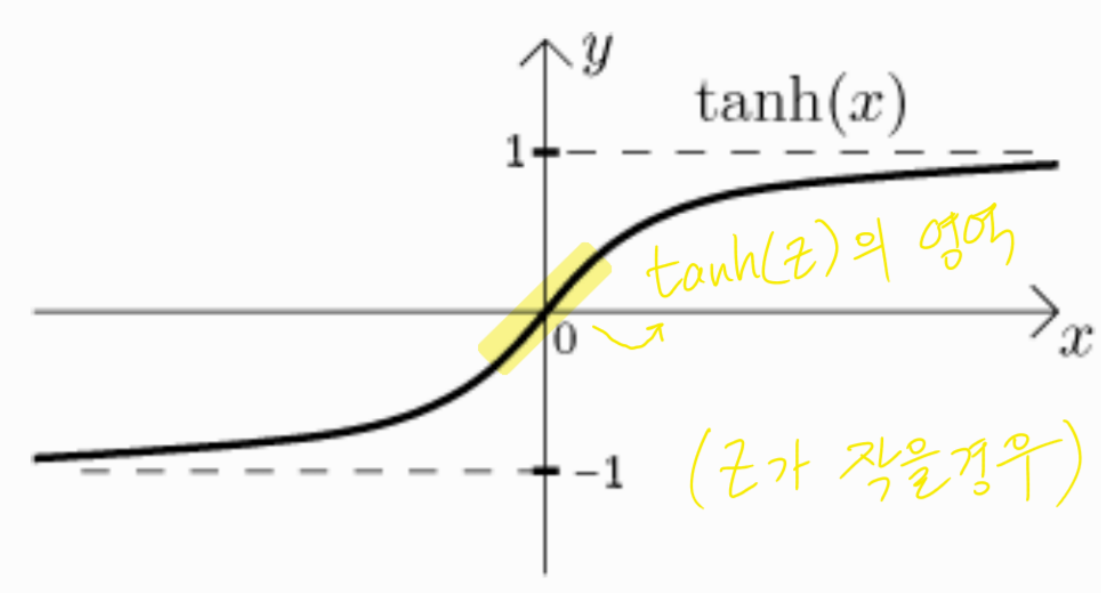
반대로 Z의 값이 커지면 선형 영역을 벗어난다. 위에서 보았듯이 정규화 매개변수가 커질 때 가중치(W)는 작아질 것이고, 가중치가 작아진다면 아래의 식에 의해 Z값 또한 작아질 것이다.
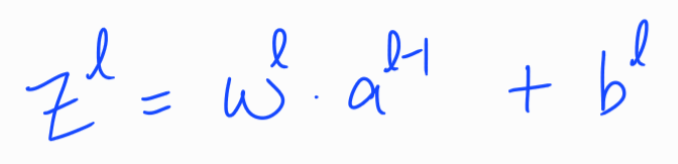
따라서 Z가 상대적으로 작은 값을 갖게 된다면 g(Z) = tanh(Z)는 선형에 가까운 함수가 된다. 모든 층(Layer)이 선형이면 전체 네트워크 또한 선형이다. 따라서 매우 복잡한 비선형 함수를 만들 수 없다. 결국 높은 분산을 해결할 수 있게 된다.
딥러닝에서 가끔 드롭아웃이라는 정규화 기법을 사용하기도 한다. L2나 L1 정규화 기법처럼 가중치가 너무 커지는 것을 막기위해 추가적인 항을 더해주는 것과 비슷한 효과를 볼 수 있다.
정리해보면, 정규화를 하게 되면 정규화 매개변수를 포함한 추가적인 항을 손실함수에 더하게 되고 그럼 결국 가중치(W)가 작아져 은닉층의 유닛들의 영향력이 작아지고 네트워크의 복잡도가 줄어든다. 또한 Z값이 작아져 tanh 활성화함수의 선형구간의 위치하여 선형함수를 만들어 과대적합을 막게 된다.
6. Dropout Regularization (C2W1L06)
Youtube 강의 영상 : Dropout Regularization (C2W1L06)
L2 정규화 외에 또 다른 매우 강력한 정규화 기법에는 드롭아웃(Dropout)이 있다. 아래에 보이는 신경망은 과적합한 결과를 보인 신경망이라고 가정하자.
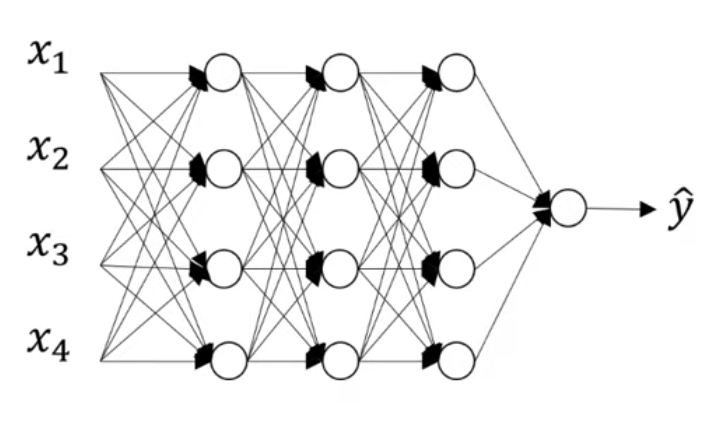
드롭아웃(Dropout)이란 무작위로 신경망의 유닛을 삭제하는 기법이다. 드롭아웃을 사용하기 위해 먼저 신경망의 각각의 층에 대해 노드를 삭제할 확률을 설정한다. 그럼 각각의 층에 대해 각각의 노드마다 특정한 확률로 해당 노드를 유지하거나 삭제하게 된다. 예를 들어, 아래의 경우 각각의 노드마다 0.5의 확률로 해당 노드를 유지하고 0.5의 확률로 노드를 삭제하게 된다.
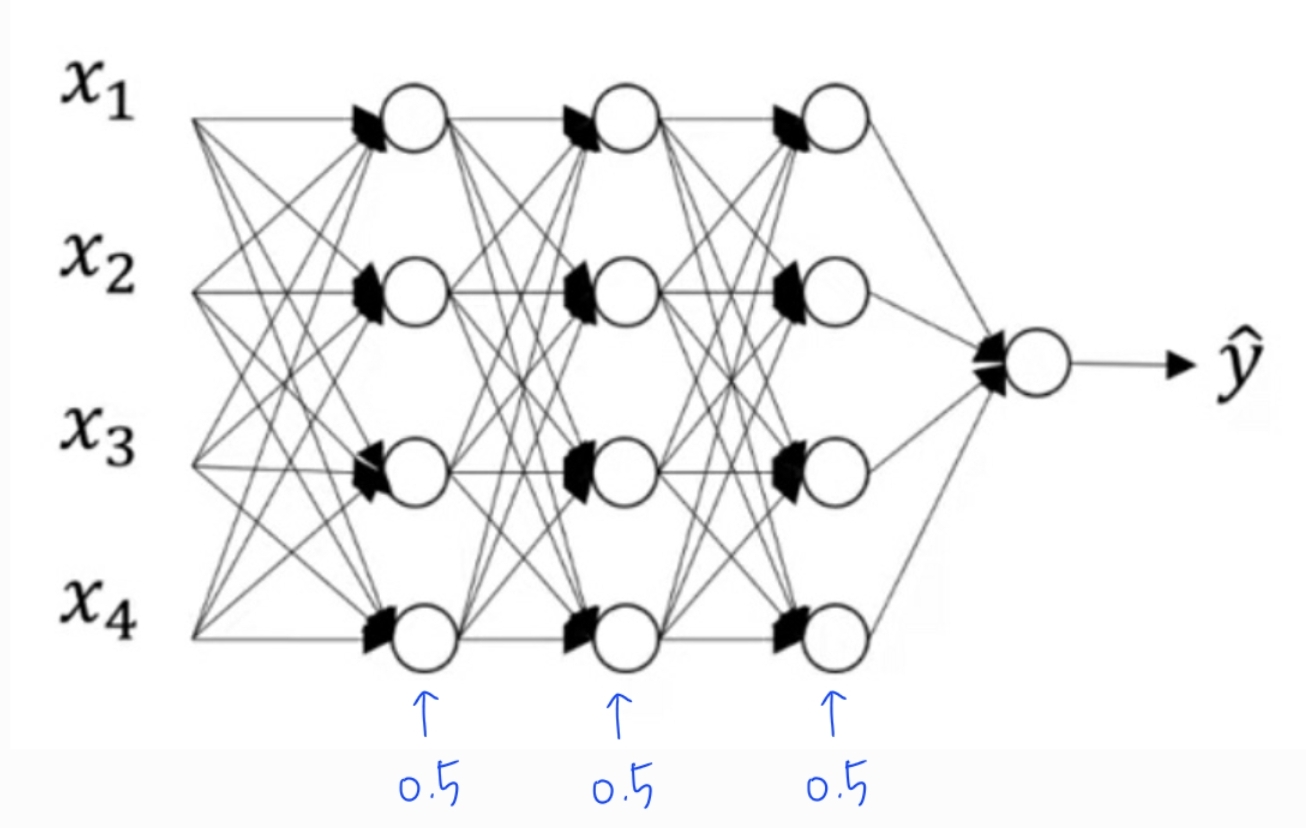
0.5(50%)의 확률상 다음과 같이 노드를 삭제했다고 하자.
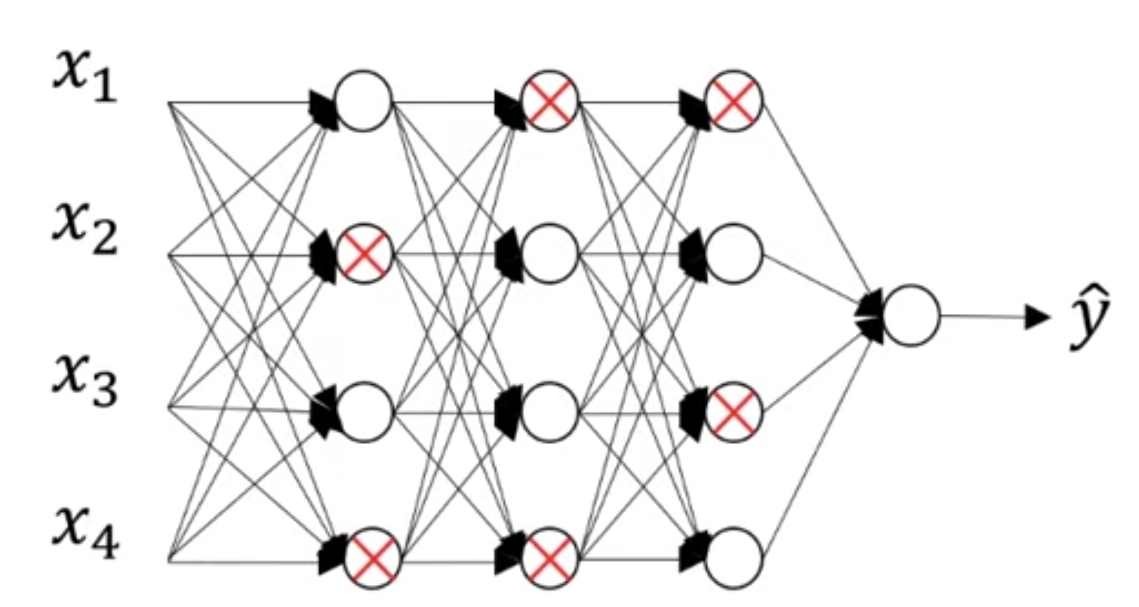
그럼 삭제된 노드의 들어가는 링크와 나가는 링크를 모두 삭제하고 결국 아래와 같은 간소화된 네트워크가 된다.
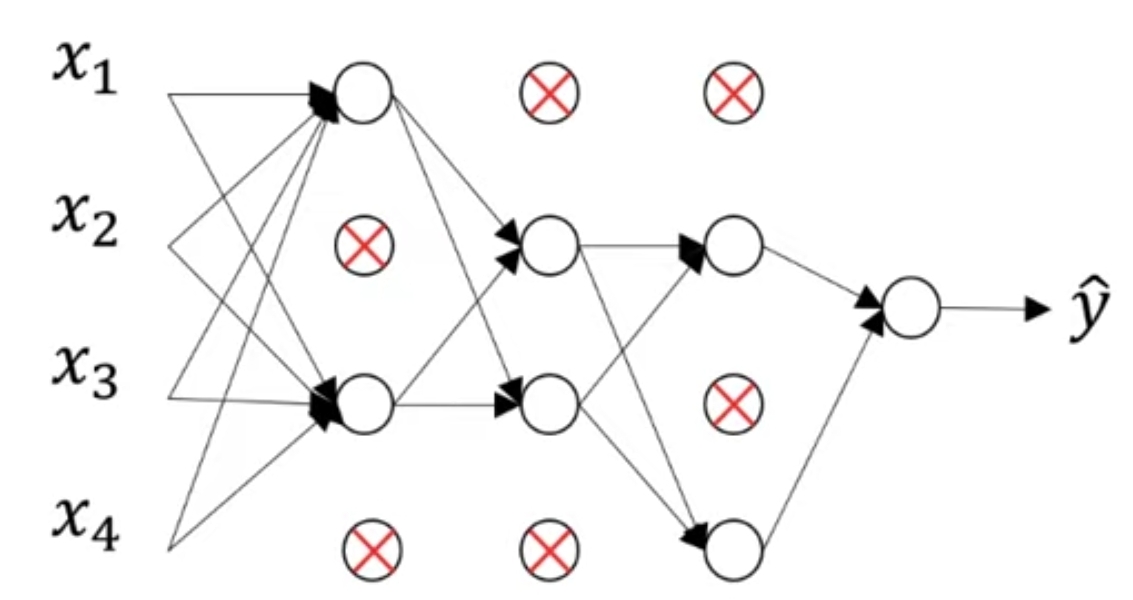
이 간소화된 네트워크에서 역전파도 진행된다. 노드를 무작위로 삭제하는 것이 이상한 기법처럼 보일 수도 있지만 실제로 잘 작동한다고 한다.
(역 드롭아웃을 구현하는 방법에 대한 설명은 유튜브 강의 영상 보면 확인할 수 있습니다.)
모델 훈련 후 테스트할 때 테스트 데이터 셋의 경우에는 드롭아웃을 사용하지 않는다. 왜냐하면 테스트를 할 때 결과가 무작위로 나오면 안되기 때문이다. 테스트 시에 드롭아웃을 할 경우 오히려 노이즈만 증가시킬 뿐이다. 여러 번 반복한 결과를 평균을 낼 수도 있지만 컴퓨터적으로 비효율적이며 결과도 결국 비슷하다고 한다.
7. Understanding Dropout (C2W1L07)
Youtube 강의 영상 : Understanding Dropout (C2W1L07)
왜 드롭아웃(Dropout)이 정규화로 작동을 할까? 왜 정규화한 효과가 날까?
첫 번째 직관은 더 작고 간소한 신경망을 사용하는 것과 같이 작동하여 정규화의 효과를 준다는 것이다. (6. Dropout Regularization 참고)
두 번째 직관은 그림을 그려가며 이해를 해보자. 아래의 그림에는 입력(input)이 4개가 있고 오른쪽에 하나의 단일 유닛이 있다. 이 단일 유닛의 관점에서 살펴보자.
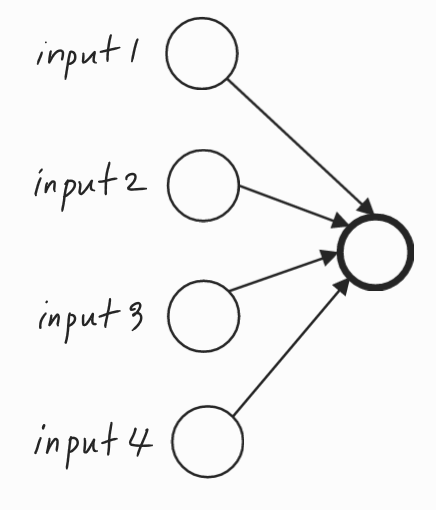
이 단일 유닛이 하는 일은 입력을 받아 의미있는 출력을 생성하는 것이다. 드롭아웃을 통해 입력은 무작위(random)으로 삭제될 수 있다. 삭제할 확률이 0.5일때 아래의 두 가지(A와 B) 모두 가능한 경우이다.
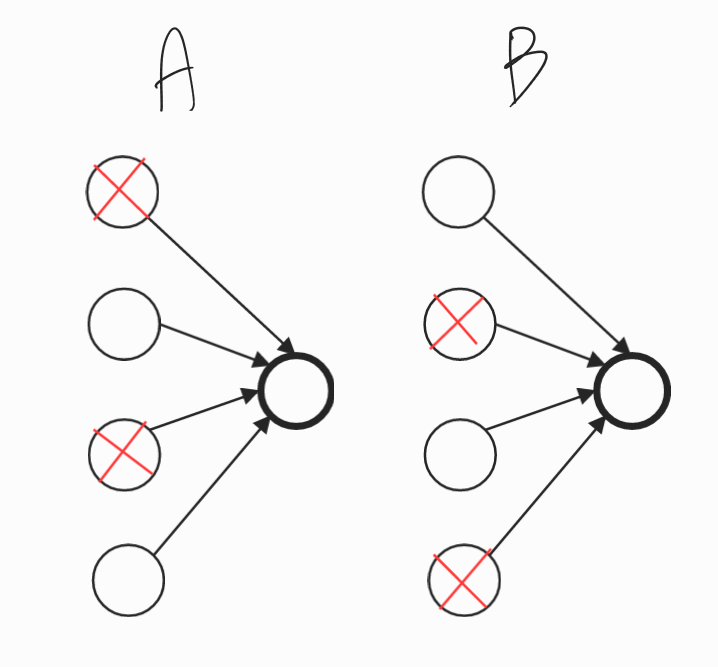
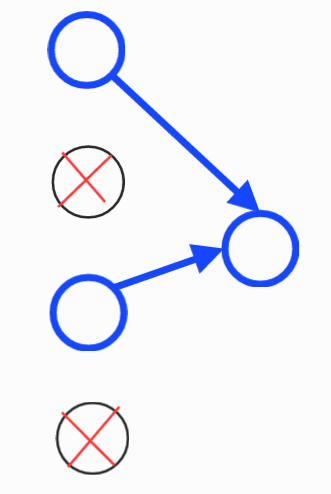
A) 왼쪽 그림인 A의 경우는 input 2와 input 4만이 연결된다.
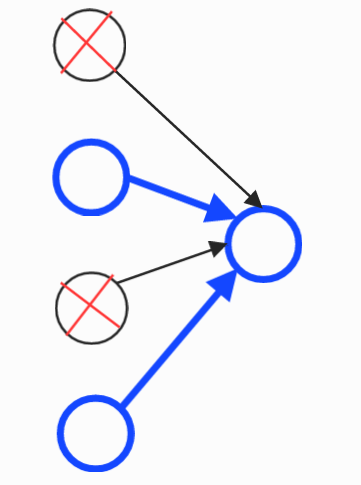
그리고 나머지 링크는 끊어지게 된다.
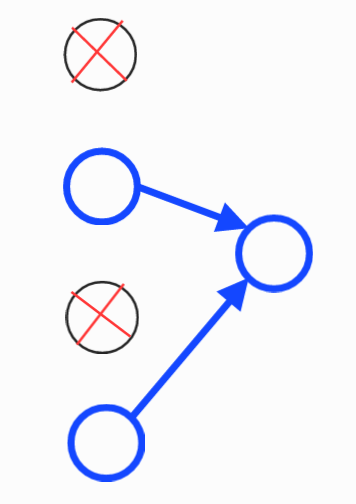
B) 오른쪽 그림인 B의 경우는 input 1과 input 3만이 연결된다.
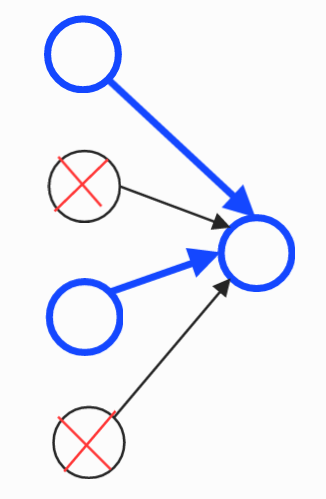
그리고 나머지 링크는 끊어지게 된다.
이런 식으로 드롭아웃을 통해 무작위로 유닛들이 삭제되어 서로 다른 다양한 input을 오른쪽의 단일 유닛은 전달 받게 된다. 따라서 오른쪽의 단일 유닛은 어떠한 입력 특성에도 의존할 수 없다. 하나의 특정 입력에 유난히 큰 가중치를 부여할 수 없으므로 가중치를 4개의 input에 각각 분산시킨다. 즉, 가중치를 분산시킴으로써 가중치의 Norm(L2 정규화)이 줄어들게 된다. 따라서 드롭아웃은 L2 정규화와 같은 효과를 보여 과대적합을 막는데 도움이 된다.
드롭아웃을 할 때 과대적합의 우려가 없는 층, 즉 유닛이 적어 많은 가중치(W)를 가지지 않는 층은 keep_prob(층에서 유닛이 삭제되지 않을 확률)을 1로 주어 드롭아웃을 사용하지 않아도 된다. 반대로 과대적합의 우려가 높은 층, 즉 매개변수가 매우 많은 층은 더 강력한 형태의 드롭아웃을 위해 keep_prob을 작게 설정하는 것이 좋다.
컴퓨터 비전 분야에서는 대부분의 경우 데이터가 부족하다. 따라서 이 분야에서는 드롭아웃이 매우 빈번하게 사용된다. 하지만 드롭아웃은 정규화 기법이고 과대적합을 막는데 도움을 주는 것으로 문제가 생기기 전까지는 사용하지 않는 것이 좋다. 단점이 존재하기 때문이다. 드롭아웃은 비용함수 또는 손실함수가 잘 정의되지 않는다는 단점이 존재한다. 무작위로 노드들이 삭제되므로 비용함수가 경사하강을 하는지 확인하는게 어렵다. 따라서 먼저 모델의 keep_prob을 1로 설정하여 드롭아웃의 효과를 멈추고 비용함수가 단조 감소하는지 확인한다. 그 다음 문제가 있다면 드롭아웃의 효과를 다시 주고 코드는 바꾸지 않도록 한다.
결론적으로, 드롭아웃은 특정 입력 값에 의존하지 못하고 분산되어 가중치 값이 줄어들어 정규화 효과를 보이게 된다. 또한 모든 층에 똑같은 값의 keep_prob을 설정하지 말고 매개변수가 많아 과대적합 우려가 큰 층은 낮은 keep_prob을, 과대적합 우려가 작은 층은 높은 keep_prob을 또는 아예 드롭아웃 효과를 끄기 위해 1로 설정하는 것이 좋다. 마지막으로 과대적합 문제가 발생하였을 경우에만 드롭아웃 기법을 사용하도록 한다.
8. Other Regularization Methods (C2W1L08)
Youtube 강의 영상 : Other Regularization Methods (C2W1L08)
L1, L2 정규화와 드롭아웃 정규화 기법 외에도 다음과 같은 정규화 기법들이 더 존재한다.
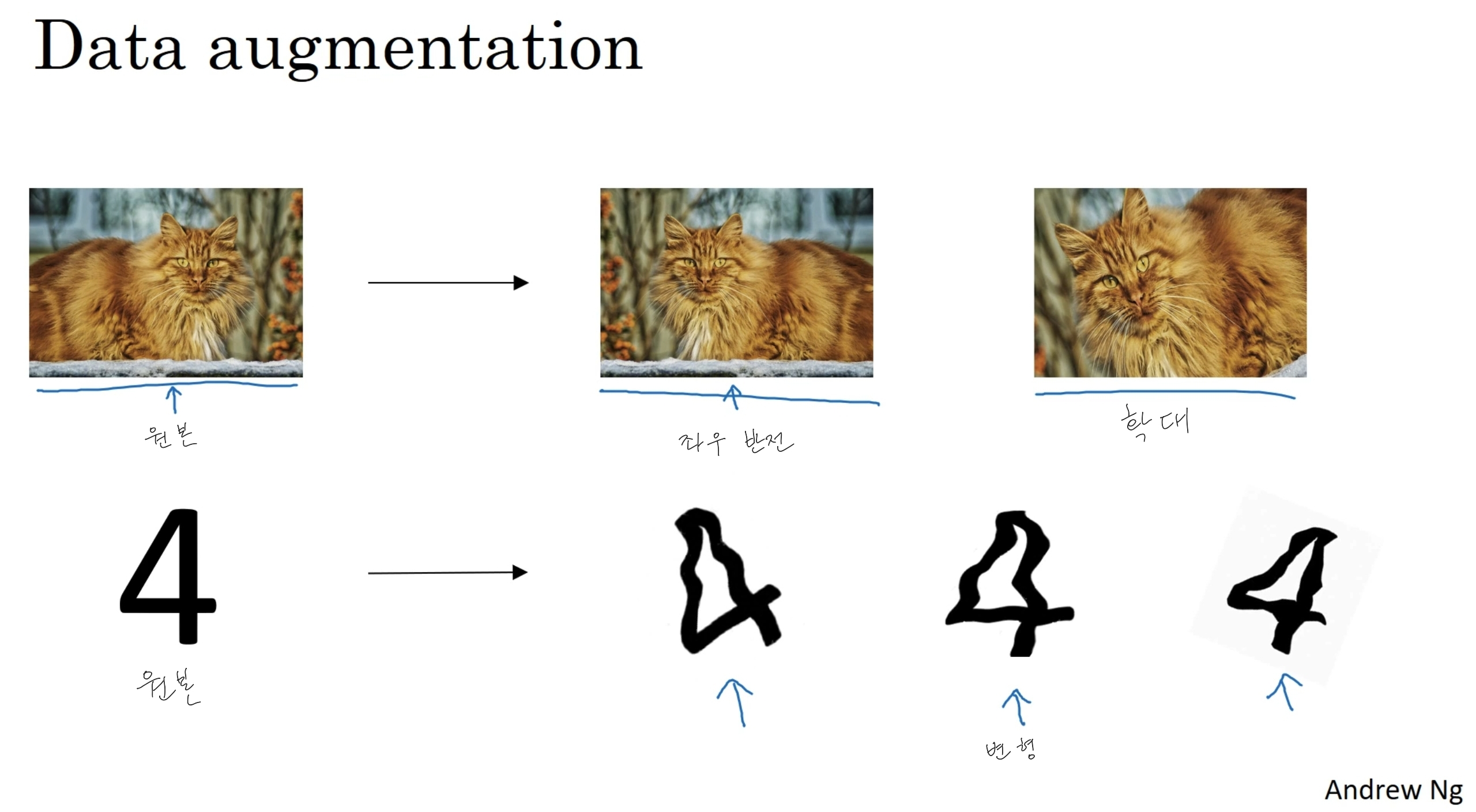
Data augmentation
전혀 다른 새로운 이미지를 확보하는 것이 물론 더 좋겠지만 비용이 많이 들기 때문에 이미지를 수평 방향으로 뒤집거나 확대하거나 회전하거나 왜곡 및 변형하여 샘플에 추가하는 방법도 있다.
!
{kind=link}
이러한 추가적인 가짜 이미지들은 완전히 새로운 독립적인 고양이 샘플을 얻는 것보다 더 많은 정보를 추가해주지는 않을 것이다. 하지만 컴퓨터적인 비용이 들지 않고 할 수 있다는 장점이 있다.
Early Stopping
Early Stopping(조기 종료)라는 또 다른 기법이 있다. 경사 하강법을 실행하면서 훈련 데이터 셋 오차와 개발 데이터 셋 오차를 그래프에 그려보면 다음과 같은 그림이 나온다.
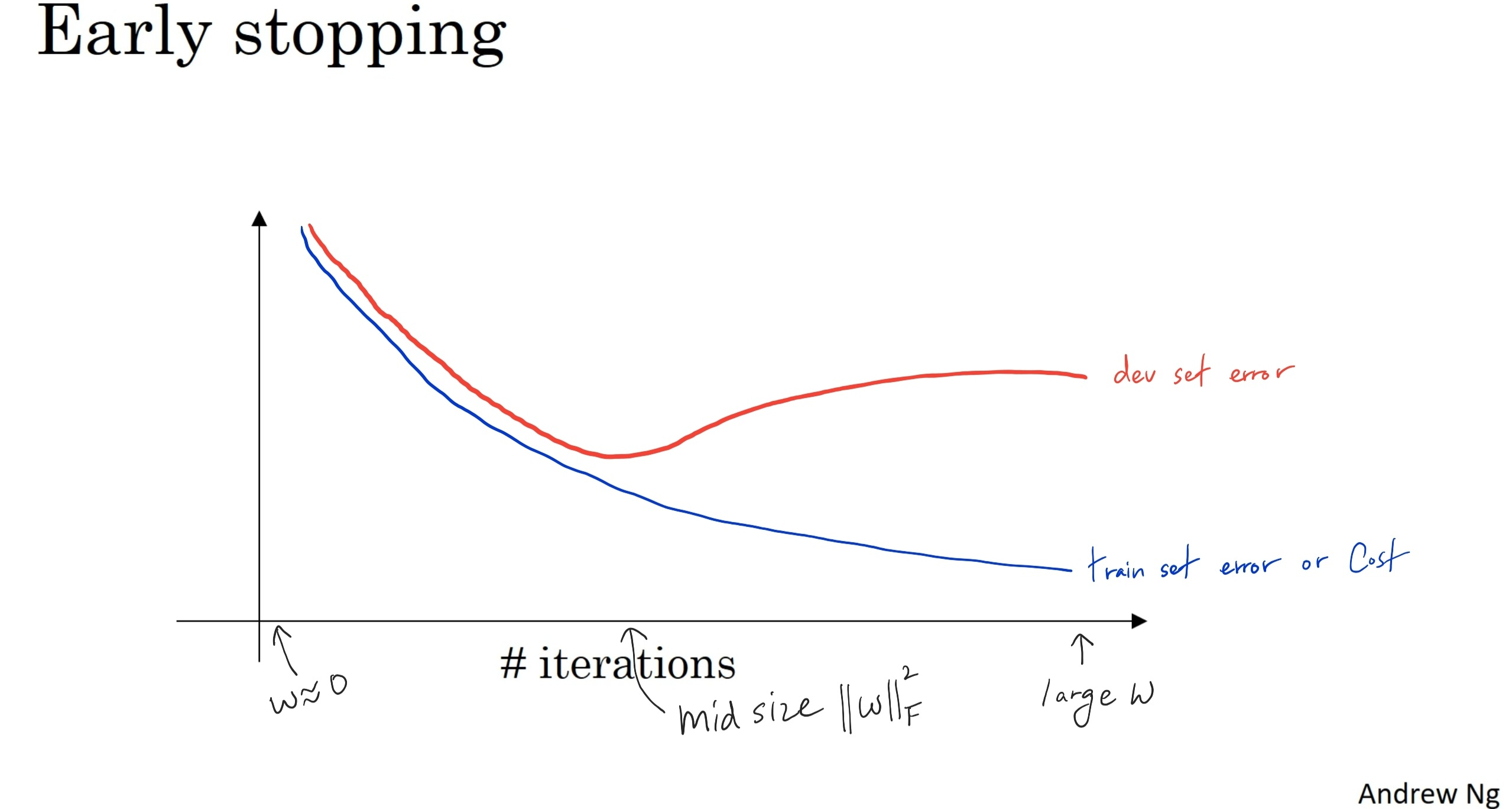
위의 그래프에서 발견할 수 있는 것은 개발 셋 오차함수 곡선이 감소하다가 어느 특정 부분에서 증가한다는 것이다. 조기 종료는 신경망이 이 지점에 위치할 때(개발 셋 오차함수가 증가하기 시작할 때) 작동한다. 중간에 신경망을 훈련시키는 것을 멈추고 이 개발 세트 오차를 만든 매개변수 값들을 최적으로 삼는다.
이 방법이 정규화 효과를 보이는 이유는 처음에 무작위로 매우 작은 값으로 초기화한 가중치(W)는 반복을 실행할수록 커지는데 조기 종료 기법이 이를 멈추었기 때문이다. 멈춘 시점은 여전히 W가 그렇게 크지 않은 시점이다. 따라서 신경망을 덜 과대적합하게 만든다.
조기 종료는 말 그대로 신경망을 조기에 종료시킨다. 하지만 이에는 단점이 존재한다. 비용함수를 최적화하는 것을 멈추게 하여 비용함수를 줄이는 일을 잘 하지 못하게 된다. 동시에 과대적합도 막으려하며 이는 문제를 더 복잡하게 한다. 따라서 조기 종료의 대안으로 L2 정규화를 사용할 수 있다. 그럼 가능한 오래 신경망을 훈련시킬 수 있게 된다. 단, L2 정규화에도 단점이 존재하는데 정규화 매개변수에 많은 값을 시도해야한다는 것이다. 반대로 조기 종료는 많은 값을 시도할 필요가 없다. 여러 정규화 기법에는 각각 장단점이 존재한다는 것을 알 수 있다.
