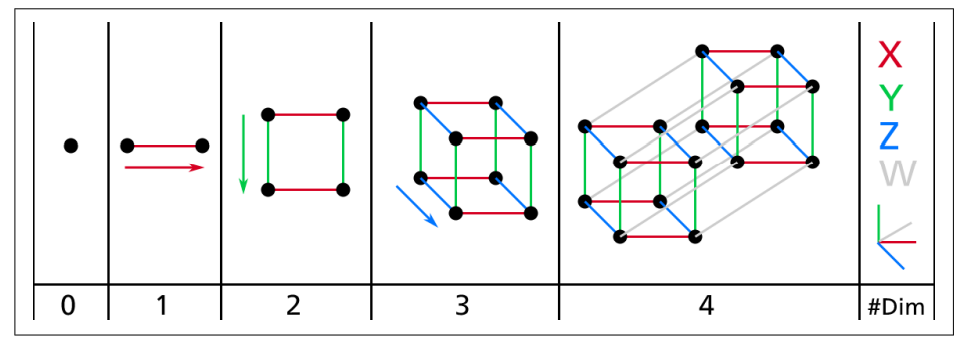
8장 요약
차원 축소의 이점?
- 훈련 속도 증가
- 데이터 시각화
차원 축소에 사용되는 2가지 주요 접근 방법
- 투영 (Projection)
- Manifold learning
인기 있는 차원 축소 기법
- PCA
- Kernal PCA
- LLE
8.1 차원의 저주
- 훈련 세트 (train set)의 차원이 클수록 과대적합 (Over fitting) 위험이 커진다.
- 해결 방법의 예시: 훈련 샘플의 밀도가 충분히 높아질때까지 훈련 세트의 크기를 키우는 것.
8.2 차원 축소를 위한 접근 방법
-> 투영, 매니폴드
8.2.1 투영 (Projection)
-> 모든 훈련 샘플이 고차원 공간 안의 저차원 부분 공간 (subspace)에 놓여있음.
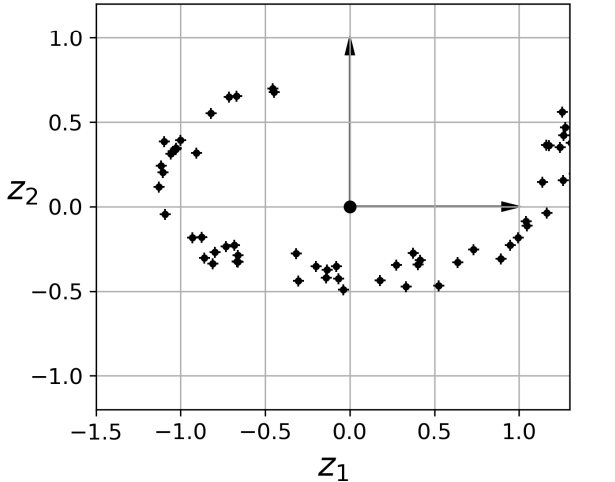
-> 훈련 샘플이 거의 평면 형태로 놓여있음: (고차원 (3D) 공간에 있는 저차원 (2D) 부분 공간.)
-> 샘플과 평면사이의 가장 짧은 직선을 따라 (수직으로) 투영하면 위와 같은 2D 데이터셋을 얻는다.
아래 그림과 같이 표현된 '스위스 롤 (swiss roll)' 데이터셋처럼 부분 공간이 뒤틀리거나 휘어있기도 합니다.
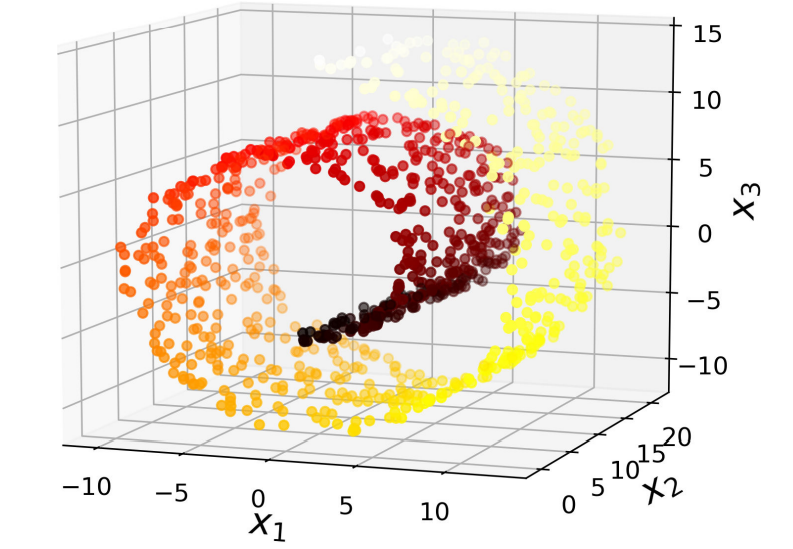
-> 이 데이터를 투영시키면 아래의 그림에서 [왼쪽]과 같은 결과가 나오고, 스위스 롤을 펼쳐서 2D 데이터 셋을 얻기 위해선 [오른쪽]과 같이 해야한다.
8.2.2 매니폴드 학습 (Manifold Learning)
2D 매니폴드 (Manifold)
- 2D 매니폴드: 고차원 공간에서 휘어지거나 뒤틀린 2D 모양
- d 차원매니폴드: 국부적으로 (부분적으로) d차원 초평면으로 보일 수 있는 n차원 공간의 일부 (d<n)
- 스위스 롤의 경우는 d=2, n=3
매니폴드 학습
- 정의: 많은 차원 축소 알고리즘이 훈련 샘플이 놓여 있는 매니폴드를 모델링하는 식으로 작동하는 것
- 이는 매니폴드 가정 또는 매니폴드 가설에 근거함
- 매니폴드 가정(가설): 대부분 실제 고차원 데이터셋이 더 낮은 저차원 매니폴드에 가깝게 놓여있다는 가정
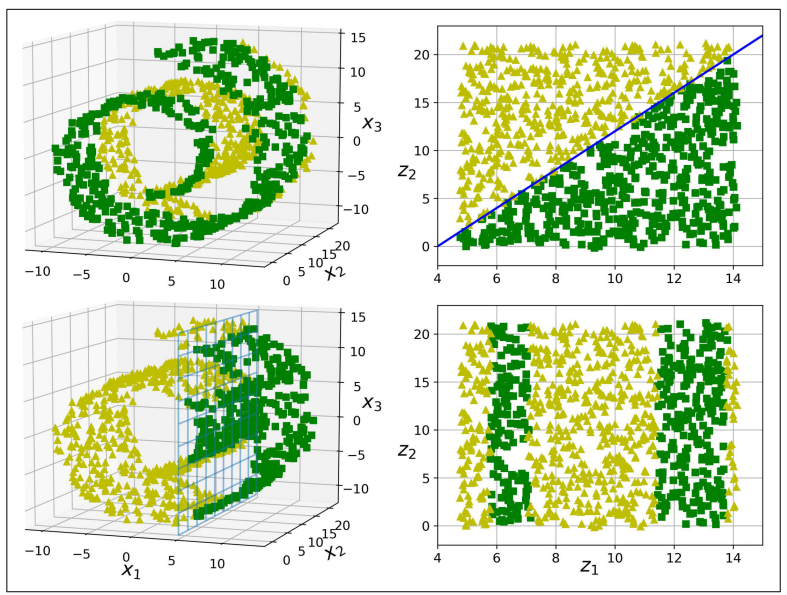
매니폴드 가정은 종종 암묵적으로 다른 가정과 병행되곤 한다.
-
Task들이 (분류, 회귀 등)저차원의 매니폴드 공간에 표현되면 더 간단해질 것이란 가정
-> 항상 유효하지는 않다.
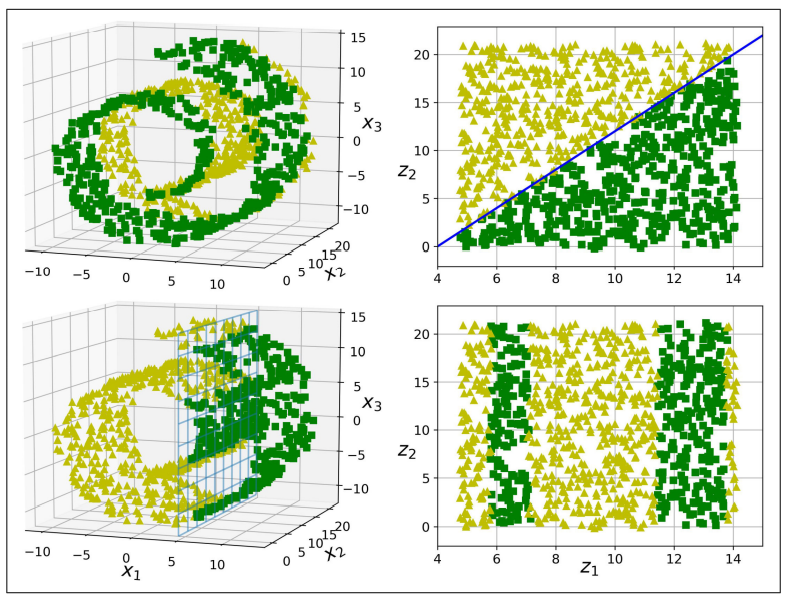
-
1행의 경우 복잡한 3D 공간에서의 데이터가 2D 매니폴드 공간에서는 단순한 직선 경계로 나뉜 것을 볼 수 있다.
-
2행의 경우 3D 공간에서 경계가 매우 단순하지만, 2D로 펼칠 경우에 더욱 복잡해지는 것을 볼 수 있다.
8.3 PCA
PCA: 주성분 분석
- PCA= Principal component Analysis
- 가장 대중적인 차원 축소 알고리즘
- 가장 가까운 초평면을 정의한 다음, 데이터를 이 평면에 투영시키는 것
8.3.1 분산 보존
초평면
- n 차원 초평면의 식:
- n 차원에서의 초평면= n-1 차원의 공간
- ex) 3차원에서의 초평면 = 2차원 평면
- ex) 2차원에서의 초평면 = 1차원 직선
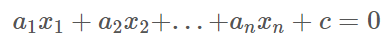
분산
- 값들이 얼마나 퍼져있는지에 대한 값
- 분산이 클수록 넓게 퍼져있고, 분산이 작을수록 좁게 분포한다.
- V(X) = E((X-m)^2)
분산 보존
- 2차원 이상의 데이터에서 투영할 방향을 결정할 때, 분산이 최대로 보존되는 축을 향하여 투영하는 것이 정보가 가장 적게 손실됨.
- 이는 원본 데이터셋과 투영된 것 사이의 평균 제곱 거리를 최소화 하는 축.
오른쪽에서의 첫번째 그림은 C1 축으로 투영된 결과, 가운데 그림은 이름이 붙지 않은 파선으로 투영된 결과, 마지막 그림은 C2 축으로 투영된 결과이다.
8.3.2 주성분
- PCA는 훈련 세트에서 분산이 최대인 축을 찾는다. (바로 위의 그림에선 C1이다.)
- 다음으로 첫 번째 축에 직교하고 남은 분산을 최대한 보존하는 두 번째 축을 찾는다. (C2이다.)
- 만약 고차원의 데이터셋이라면 PCA는 이전의 두 축에 직교하는 세 번째 축을 찾으며 데이터셋에 있는 차원의 수만큼 네 번째, 다섯 번째, ... n번째 축을 찾는다.
- i 번째 축을 이 데이터의 i 번째 주성분 (principal component)라고 한다.
특잇값 분해 (SVD)
- 훈련 세트 행렬 X: UΣVT 로 분해된다.
- 이때 V 행렬의 열벡터들이 주성분이 된다.
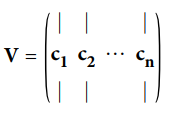
X_centerd = X - Xmean(axis = 0) # 평균을 0으로 맞춘다. U,s,Vt = np.linalg.svd(X_centered) c1 = Vt.T[:, 0] c2 = Vt.T[:, 1]
- 위 코드는 넘파이의 svd() 함수를 사용하여 훈련 세트의 모든 주성분을 구한 후 처음 두개의 PC를 정의하는 두 개의 단위 벡터를 추출한다.
- PCA는 데이터셋의 평균이 0이라고 가정한다.
- 앞으로 볼 사이킷런의 PCA 파이썬 클래스는 이 작업을 대신 처리해준다.
- 위 코드처럼 PCA를 직접 구현하거나 다른 라이브러리를 사용한다면 먼저 데이터를 원점에 맞추는 것을 필요로 한다.
8.3.3 d차원으로 투영하기
- 주성분을 모두 추출했다면 처음 d개의 주성분으로 정의한 초평면에 투영하여 데이터셋의 차원을 d차원으로 축소시킬 수 있다.
- 초평면에 훈련세트를 투영하고 d차원으로 축소된 데이터셋 X_d‐proj 를 얻기 위해서 X에 V의 첫 d열로 구성된 행렬 Wd를 곱하면 된다.
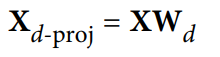
- X: m*n 행렬 (각 데이터 셋의 원소는 n차원)
- Wd: n*d 행렬
- X_d-proj: m*d (즉 m개의 데이터셋의 원소들이 n차원에서 d차원으로 변경됨)
W2 = Vt.T[:, :2] #V 행렬에서 2개의 열벡터만 모은 행렬을 W2로 정의 X2D = X_centered.dot(W2) X와 W2를 곱한다.
8.3.4 사이킷런 사용하기
- 사이킷런의 PCA 모델은 SVD 분해 방법을 사용하여 구현.
- 아래의 코드는 PCA 모델을 사용하여 데이터셋의 차원을 2로 줄이는 코드이다.
- 사이킷런의 PCA 모델은 자동으로 데이터를 중앙에 맞춘다.
from sklearn.decomposition import PCA
pca = PCA(n_components = 2)
X2D = pca.fit_transformation(X)이때 pca.components_ 속성에 Wd의 transpose가 담겨있다.
- k번째 주성분을 정의하는 단위벡터: pca.components_[ : , k-1]
8.3.5 설명된 분산의 비율
- 설명된 분산의 비율: pca.explainedvariance_ratio 에 저장된 주성분
- 각 주성분의 축을 따라 있는 데이터셋의 분산 비율을 나타냄.
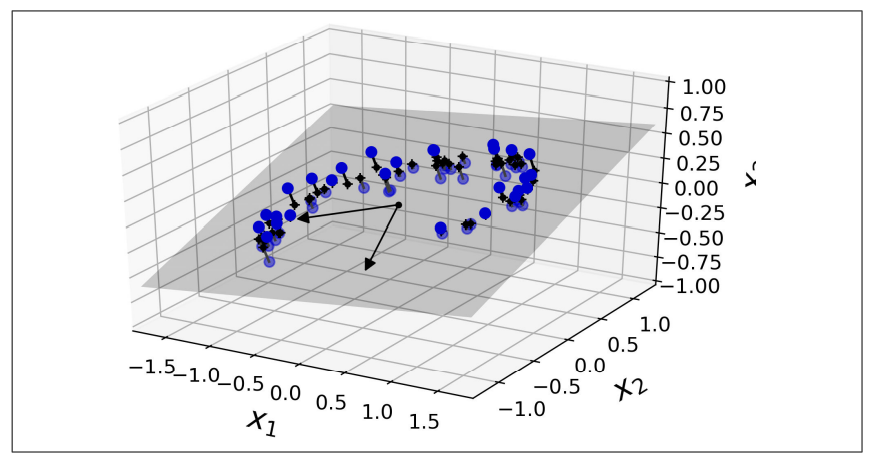
위의 그림에 나타난 3D 데이터셋의 처음 두 주성분에 대한 설명된 분산의 비율을 확인
>>> pca.explained_variance_ratio_
array([0.84248607, 0.14631839])- 즉 데이터셋 분산의 84.2%가 첫 번째 PC를 따라 놓여있고, 14.6%가 두 번째 PC를 따라 놓여있다.
- 세 번째 PC에는 1.2% 미만이 남아 있을 것이므로 아주 적은 양의 정보가 들어있다고 생각해도 됨.
8.3.6 (PCA를 위한) 적절한 차원 수 선택하기
- 차원 수를 임의로 정하기보다 충분한 분산이 될 때까지 더해야 할 차원 수를 선택하는 것이 간단함.
- 아래의 코드는 차원을 축소하지 않고 PCA를 계산한 뒤 훈련 세트의 분산을 95%로 유지하는 데 필요한 최소한의 차원 수를 계산함.
pca = PCA()#default 차원수로 설정됨?
pca.filt(X_train)
cumsum = np.cumsum(pca.explained_variance_ratio_)
d = np.argmax(cumsum>=0.95) + 1- 그런 다음 n_components를 d로 설정하여 PCA를 다시 실행.
- 이때 n_components의 값을 유지하려는 주성분의 수로 지정하기 보다, 보존하려는 분산의 비율을 0.0~1.0 사이로 설정하는 편이 더 낫다.
pca = PCA(n_components = 0.95)
X_reduced = pca.fit_transform(X_train)- 또 다른 방법은 설명된 분산 (explainedvariance_ratio)을 차원 수에 대한 함수로 그리는 것. (누적 합을 나타내는 cumsum을 그래프로 그리면 됨.)
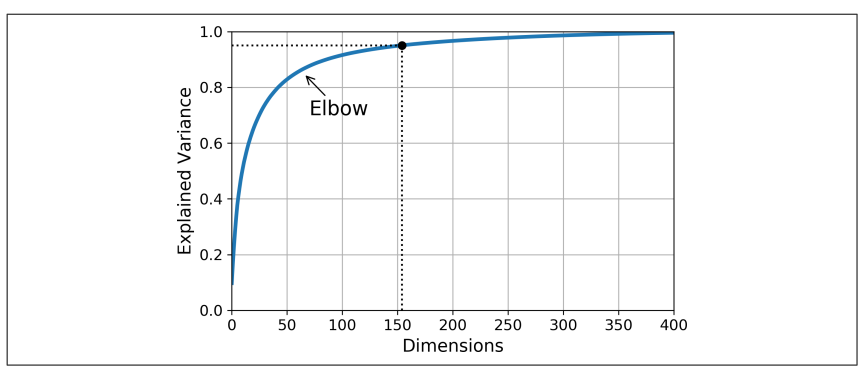
위의 그림에서 차원을 약 100 정도로 축소해도 설명된 분산을 크게 손해보지 않을 것임.
8.3.7 압축을 위한 PCA
-
차원을 축소하고 난 후에는 훈련 세트의 크기가 줄어든다.
-
EX) MNIST 데이터셋에 분산의 95%를 유지하도록 PCA를 적용한다면 각 샘플은 784개의 특성 (28*28)에서 150개 정도로 줄어들 것임.
-
대부분의 분산은 유지되었지만 데이터셋은 원본 크기의 20% 미만 (150/784)이 되었음.
-
이 축소는 SVM같은 Classification 알고리즘의 속도를 향상시킬 수 있음.
-
위에서 본 PCA 투영의 변환을 반대로 적용하여 784개의 차원으로 되돌릴 수도 이씅ㅁ.
-
투영에서 일정량의 정보 (유실된 5%의 분산)를 잃어버렸기 때문에 완전한 원본 데이터셋을 얻을 수는 없음. 하지만 원본 데이터와 매우 비슷할 것.
-
이때 원본 데이터와 재구성된 데이터 사이의 평균 제곱 거리를 재구성 오차 라고 함.
아래의 코드와 그림은 MNIST 데이터셋을 154차원으로 압축하고, inverse_transform() 메서드를 사용하여 784 차원으로 복원하는 코드
pca = PCA(n_components = 154)
X_reduced = pca.fit_transform(X_train)
X_recovered = pca.inverse_transform(X_reduced)
- 역변원 공식은 아래와 같습니다.
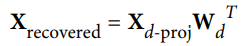
8.3.8 랜덤 PCA
- PCA 함수에서 svd_solver 파라미터를 "randomized"로 지정하면 사이킷런은 랜덤 PCA라 부르는 확률적 알고리즘을 사용해 처음 d개의 주성분에 대한 근삿값을 빠르게 찾는다.
- 이 알고리즘의 계산 복잡도는 완전한 SVD 방식인 O(mn^2)+O(n^3)이 아니라, O(md^2) + O(d^3)임.
- 따라서 d가 n보다 많이 작으면 완전 SVD보다 훨씬 빠르다.
rnd_pca = PCA(n_components=154, svd_solver="randomized")
X_reduced =rnd_pca.fit_transform(X_train)- svd_solver의 기본값은 "auto"임.
- m이나 n이 500보다 크고, d가 m이나 n의 80%보다 작으면, 사이킷런은 자동으로 랜덤 PCA 아고리즘을 사용함. 아니면 완전한 SVD 방식을 사용함.
- 완전한 SVD 방식을 강제하려면, svd_solver 매개변수를 "full"로 지정.
-> 완전한 SVD: mm & mn & nn
-> 축소된 SVD: mm & md & dd
8.3.9 점진적 PCA
기존 PCA의 문제점
- SVD 알고리즘 실행을 위해 전체 훈련 세트을 메모리에 올려야 함.
-----> 해결책: Incremental PCA (IPCA; 점진적 PCA) 알고리즘
-> 훈련 세트를 미니배치로 나눈 뒤, IPCA 알고리즘에 한 번에 하나씩 주입
-> 훈련 세트가 클 때 혹은 온라인으로 새로운 데이터가 준비되는 대로 실시간으로 PCA를 적용할 수 있음.
방법 1)
- 아래의 코드는 MNIST 데이터셋을 numpy의 array_split() 함수를 사용해 100개의 미니배치로 나눔.
- 이후 IncrementalPCA 파이썬 클래스에 주입하여 MNIST 데이터셋의 차원을 154로 줄임.
- 전체 훈련 세트를 사용하는 fit() 메서드가 아닌 parital_filt() 메서드를 미니 배치마다 호출.
- np.array_split(X, n) 메서드: X를 n 분할함.
- [ [ 0th], [1st], [2nd] ... , [n th] ] 이와 같이 분할됨.
from sklearn.decomposition import IncrementalPCA
n_batches = 100
inc_pca = IncrementalPCA(n_components = 154)
for X_batch in np.array_split(X_train, n_batches):
inc_pca.partial_fit(X_batch)
X_reduced = inc_pca.transform(X_train)방법 2)
- numpy의 memmap 파이썬 클래스를 사용하여 하드 디스크의 이진 파일에 저장된 매우 큰 배열을 메모리에 들어있는 것처럼 다루는 것.
- 이 클래스는 필요할 때 데이터를 메모리에 적재.
- IncrementalPCA는 특정 순간에 배열의 일부만 사용하기 때문에 메모리 부족 문제 해결 가능.
- 다음 코드는 이 방식을 적용하여 일반적인 fit() 메서드를 사용한 경우.
X_mm = np.memmap(filename, dtype = "float32", mode = "readonly", shape=(m,n))
batch_size = m//n_batches
inc_pca = IncrementalPCA(n_components = 154, batch_size = batch_size)
inc_pca.fit(X_mm)8.4 커널 PCA
고차원 특성 공간에서의 선형 경계는 저차원 공간에서 봤을 때 복잡한 비선형 계에 해당함.
- 동일한 기법을 PCA에 적용해 차원 축소를 위한 복잡한 비선형 투영을 수행할 수 있음.
- 이를 커널 PCA라고 함.
- 이 기법은 투영된 후에 샘플의 군집을 유지하거나 꼬인 매니폴드에 가까운 데이터셋을 펼칠 때도 유용함.
아래의 코드는 KernelPCA를 사용해 RBF 커널로 kPCA를 적용.
from sklearn.decomposition import KernelPCA
rbf_pca = KernelPCA(n_components = 2, kernel="rbf", gamma = 0.004)
X_reduced = rbf_pca.fit_transform(X)아래의 그림은 선형 커널 (단순 PCA), RBF 커널, 시그모이드 커널을 사용하여 2차원으로 축소시킨 스위스 롤의 모습임.
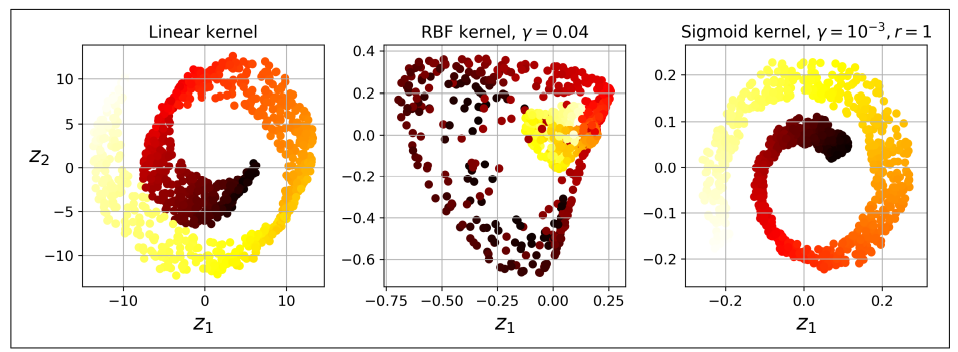
8.4.1 커널 선택과 하이퍼파라미터 튜닝
kPCA: 비지도 학습
- 좋은 커널, 좋은 하이퍼파라미터 선택의 명확한 성능 측정 기준이 부재.
- 하지만 차원 축소는 종종 지도 학습 ( ex) 분류)의 전처리 단계로 활용되므로 그리드 탐색(grid search)을 사용하여 주어진 문제에서 성능이 가장 좋은 커널과 하이퍼파라미터를 선택할 수 있음.
- 아래의 코드는 2 단계의 pipeline을 만듦.
1) kPCA를 이용해 2차원으로 차원 축소
2) 분류를 위해 로지스틱 회귀 적용 - 마지막 단계에서 가장 높은 분류 정확도를 얻기 위해 GridSearchCV를 사용해서 kPCA의 가장 좋은 커널과 gamma 파라미터를 찾는다.
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
clf = Pipeline([
("kpca", KernelPCA(n_components)),
("log_reg", LogisticRegression())
])
param_grid = [{
"kpca__gamma": np.linspace(0.03, 0.05, 10),
"kpca__kernel": ["rbf", "sigmoid"]
}]
grid_search = GridSearchCV(clf, param_gridm cv=3)
grid_search.fit(X, y)이때 가장 좋은 커널과 하이퍼파라미터는 bestparams 변수에 저장됨
>>> print(grid_search.best_params_)
{'kmpca__gamma': 0.043333333335, 'kpca__kernel': 'rbf'}- 완전한 비지도 학습 방법으로, 가장 낮은 재구성 오차를 만드는 커널과 하이퍼파라미터를 선택하는 방식도 존재.
- 재구성은 선형 PCA만큼 쉽지 않음.
아래의 그림은 스위스 롤의 원본 3D 데이터셋 (왼쪽 위)과 RBF 커널의 kPCA를 적용한 2D 데이터셋 (오른쪽 위)을 보여줌.
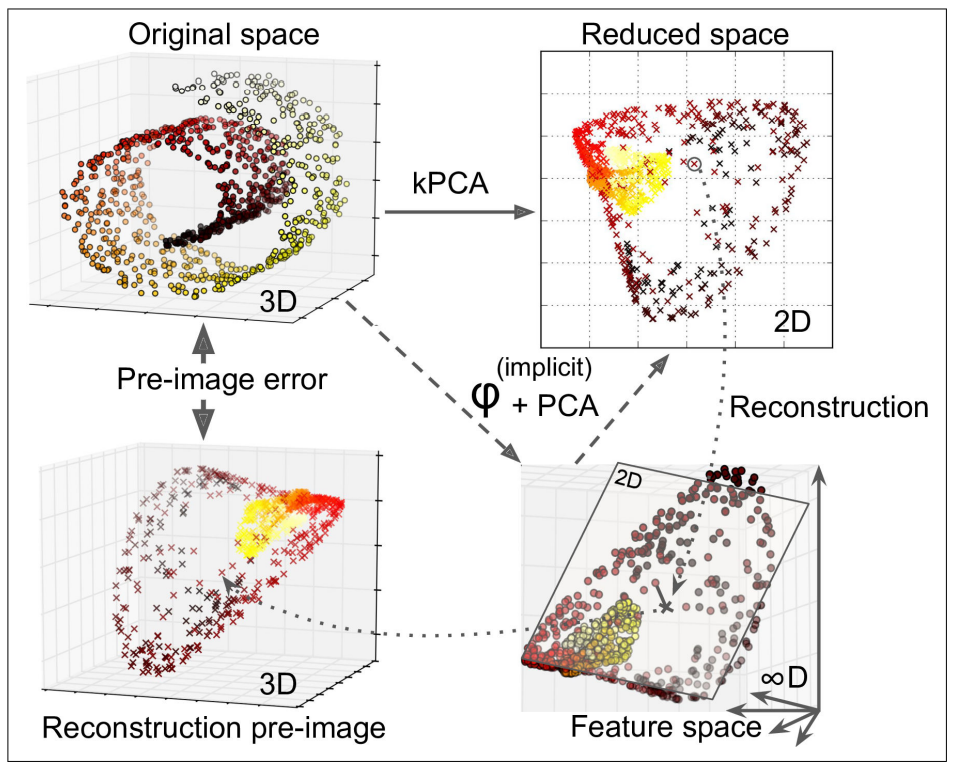
- 커널 트릭 덕분에, 특성맵 φ를 사용하여 훈련 세트를 무한 차원의 특성 공간으로 매핑한 다음 (오른쪽 아래) 선형 PCA를 사용해 2D로 투영한 것과 kPCA를 적용한 2D 데이터 셋은 수학적으로 동일.
(오른쪽 아래 = 오른쪽 위)
재구성 원상
- 축소된 공간에 있는 샘플에 대해 선형 PCA를 역전시켜 재구성한 데이터 포인트는 원본 공간이 아닌 특성 공간에 놓이게 된다. (그림에서 x로 표현한 것 처럼)
- 이 특성 공간은 무한 차원이기 때문에 재구성된 포인트를 계산할 수 없고, 재구성에 따른 실제 에러를 계산할 수 없음.
- 다행히 재구성된 포인트에 가깝게 매핑된 원본 공간의 포인트를 찾을 수 있는데, 이를 재구성 원상 (Pre-image)이라고 한다.
- 원상을 얻게 되면 원본 샘플과 제곱 거리를 측정할 수 있음.
- 따라서 재구성 원상의 오차를 최소화하는 커널과 하이퍼파라미터를 선택하는 것.
재구성 하는 방법?
-> 투영된 샘플을 훈련 세트로, 원본 샘플을 타깃으로 하는 지도 학습 회귀 모델을 훈련 시키는 것
-> 아래의 코드는 fit_inverse_transform = True로 지정하여 위 작업을 자동으로 수행하게 하는 것
rbf_pca = KernelPCA(n_components = 2, kernel = "rbf", gamma = 0.0433,
fit_inverse_transform = True)
X_reduced = rbf_pca.fit_transform(X)
X_preimage = rbf_pca.inverse_transform(X_reduced)
#아래의 코드로 재구성 원상 오차를 게산할 수 있음.
from sklearn.metrics import mean_squred_error
mean_squared_error(X, X_preimage)-> 재구성 원상 오차를 최소화 하는 커널과 하이퍼파라미터를 찾기 위해 교차 검증으로 그리드 탐색을 사용할 수 있게 되는 것.
8.5 LLE, Locally Linear Embedding
Locally linear embedding (지역 선형 임베딩): 또 다른 (강력한) 비선형 차원 축소 (Nonlinear dimensionality Reduction, NLDR) 기술임.
- 이는 투영에 의존하지 않는 매니폴드 학습임.
- LLE는 먼저 각 훈련 샘플이 가장 가까운 이웃(closest neighbor, c.n.)에 얼마나 선형적으로 연관(how?)되어 있는지 측정.
- 그런 다음 국부적인 관계가 가장 잘 보존되는 훈련 세트의 저차원 표현을 찾음.
- 이는 noise가 너무 많지 않은 경우 꼬인 매니폴드를 펼치는 데 잘 작동함.
아래의 코드는 사이킷런의 LocallyLinearEmbedding을 사용해 스위스 롤을 펼친다.
from sklearn.manifold import LocallyLinearEmbedding
lle = LocallyLinearEmbedding(n_components = 2, n_neighbor=10)
X_reduced = lle.fit_transform(X)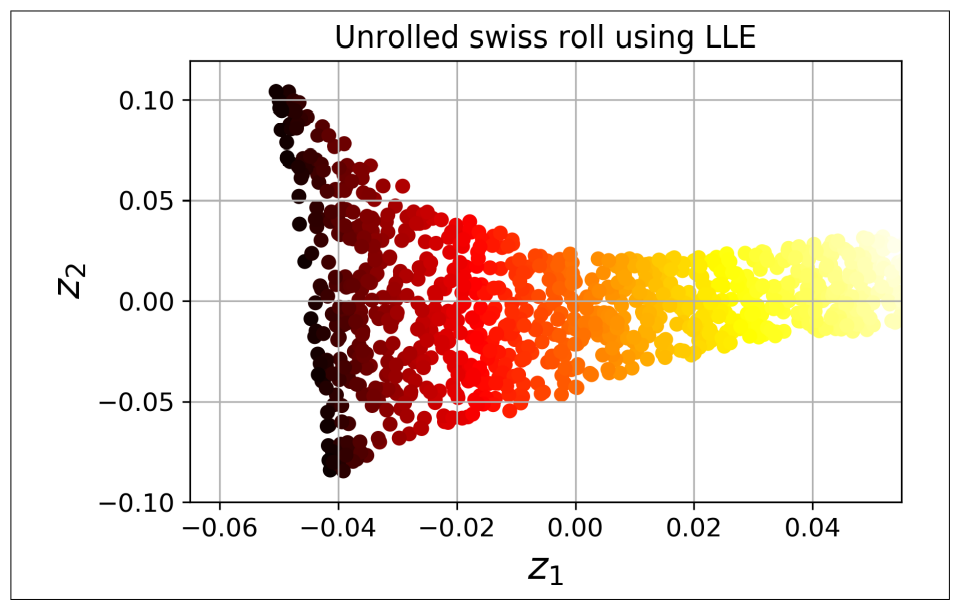
위 그림은 코드 실행 결과를 보여준다.
- 스위스 롤이 완전히 펼쳐졌고, 지역적으로 샘플 간 거리가 잘 보존되어있음.
LLE의 작동 방식 -1
1) 알고리즘이 각 훈련 샘플 에 대해 가장 가까운 k개의 샘플을 찾는다. (위의 코드에서는 k=10)
2) 이 이웃 (가까운 k개의 샘플)에 대한 선형 함수로 를 재구성한다.
3) 구체적으로 말하면 와 사이의 제곱 거리가 최소가 되는 를 찾는 것이 된다.
4) 이때 가 의 가장 가까운 k개 이웃 중 하나가 아닐 경우에는 이 된다.
- 그러므로 LLE의 첫 단계는 위에 적은 식과 같은 제한이 있는 최적화 문제가 되는 것이다.
- 여기서 W는 가중치 를 모두 담은 가중치 행렬이다.
- 두번째 제약 조건은 각 샘플 에 대한 가중치를 단순히 normalization 한 것.
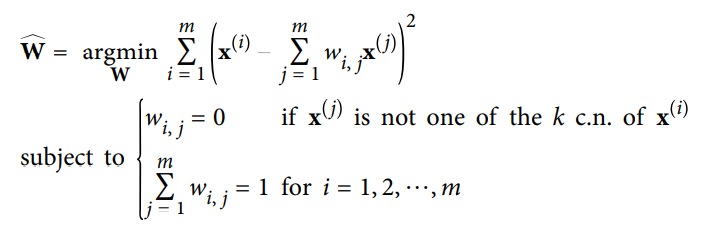
LLE의 작동 방식 -2
1) "LLE의 작동 방식 -1" 을 거치고 난 뒤, (가중치 를 담은 ) 가중치 행렬 는 훈련 샘플 사이에 있는 지역 선형 관계를 담고 있습니다.
--------->(각 샘플 i, j에 대하여 어느 pair가 c.n. 인지에 대한 정보. 0 or 1의 값으로 담고 있음.)
2) 두번째 단계는 가능한 한 이 관계가 보존되도록 훈련 샘플을 d차원 공간 (d<n)으로 매핑합니다. 만약 가 d차원 공간에서 의 상(image)이라면 가능한 한 와 사이의 거리가 최소가 되어야 함.
3) 이 아이디어는 위의 제약이 없는 최적화 문제로 바꿔준다.
4) 첫번째 단계와 비슷해 보이지만, 샘플을 고정하고 최적의 가중치를 찾는 대신, 반대로 가중치를 고정하고 저차원의 공간에서 샘플 이미지의 최적 위치를 찾습니다. Z는 를 포함하는 행렬입니다.
- k개의 이웃 찾기: O(m log(m)n log(k))
- 가중치 최적화: O(mnk3)
- 저차원 표현: O(dm2) -> 이 항에 의해 대량의 데이터셋에 적용하기엔 어렵다.
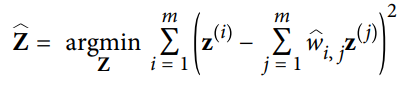
8.6 다른 차원 축소 기법
사이킷런은 다양한 차원 축소 기법을 제공함. 다음의 것들은 그중에서 가장 널리 사용되는 것들임.
랜덤 투영, random projection
- 랜덤한 선형 투영을 사용해 데이터를 저차원 공간으로 투영함.
- sklearn.random_projection 패키지 문서 참고
다차원 스케일링, multidimensional scailing (MDS)
- 샘플간의 거리를 보존하면서 차원을 축소
Isomap
- 각 샘플을 가장 가까운 이웃과 연결하는 식으로 그래프를 만듭니다.
- 그런 다음 샘플 간의 geodesic distance를 유지하면서 차원을 축소합니다.
t-SNE
- 비슷한 샘플은 가까이, 비슷하지 않은 샘플은 머리 떨어지도록 하면서 차원을 축소합니다.
- 주로 시각화에 많이 사용, 특히 고차원 공간에 있는 샘플의 군집을 시각화할 때 사용됨.
선형 판별 분석, Linear Discriminator Analysis (LDA)
- Actually, It is a Classification Algorithm.
- 하지만 훈련 과정에서 클래스 사이를 가장 잘 구분하는 축을 학습한다.
- 이 축은 데이터가 투영되는 초평면을 정의하는 데 사용할 수 있음.
- 이 알고리즘의 장점은 투영을 통해 가능한 한 클래스를 멀리 떨어지게 유지시키므로 SVM 분류기 같은 다른 분류 알고리즘을 적용하기 전에 차원을 축소시키는데 좋다.

와 정말 깔끔하게 설명 잘하셨네요^_^ 좋아요 누르고 갑니다^^~