실습수업
이번수업에선 아나콘다, 텐서플로우, 주피터 노트북을 설치하고 사용하는법에 대해서 수업하고 실습을 진행했다.
anaconda prompt를 관리자 권한으로 실행한뒤에
conda install tensorflow
명령문 기입
쥬피터 노트북은 웹브라우저 상에서 파이썬 프로그램을 작성하고 실행할 수 있게 해주는 프로그램이다. 아나콘다에 포함되어있다.
jupyter notebook
명령어로 anaconda prompt에서 실행가능
New-> python3로 새로운 노트북파일이 생성되어 거기서 코드를 입력할수 있다.

사진에는 파이썬2라 나와있지만 우리는 파이썬 3!
ctrl + Enter 키로 실행결과 표시
처음부터 다시 코드를 실행하려면
Kernel -> Restart&Clear Output'
을 선택하면 커널 재시작과 기존 출력내용도 삭제됨
퍼센트론 프로그래밍
AND 개념의 학습


이함수는 x를 통해서 넘어오는 입력사례를 입력시키며 입력된 data의 실제 출력을 계산하고 목표출력과 차이를 계산하고 가중치를 변경한다. n_epoch만큼 반복


위의 코드들을 쥬피터노트북에서 실행하면 결과값이 이렇게 나온다. 4번에 3번째 에포크에서부터 오차가 0이된다는 것을 알 수있다.
XOR 개념의 학습
XOR은 AND의 학습에서 목표 출력만 [0,1,1,0]으로 바꾸어주면 된다.
하지만 XOR는 실행하면 에폭을 100번 반복해도 오류가 4.000으로 계속나타난다. -> 학습이 잘되지않은다.
sklearn으로 퍼셉트론 실습
sklearn은 파이썬을 위한 기계학습 라이브러리다.
from sklearn.linear_model import Perceptron
X=[[0,0,[0,1],[1,0],[1,1]]
y= [0,0,0,1]
clf = Perceoptron(tol = 1e-3, random_state =0
clf.fit(X,y)
print(clf.predict(X))
3번째 줄은 퍼센트론을 생성하는 코드이고 tol은 종료조건, random_state는 난수의 시드이다.
4번째 줄을 학습을 수행하는 코드이다
5번째 줄 학습된 결과를 확인
다층퍼셉트론을 이용한 실습
퍼셉트론에서는 선형분류만 학습할수 있어서 xor같은것은 학습이 되지 않는다. 따라서 은닉층을 추가한 다층퍼셉트론으로 학습하면 비선형분류 문제를 해결할수있다.
역전파 학습 알고리즘을 사용한다.
import numpy as np
def actf(x):
return 1/(1+np.exp(-x))
def actf_deriv(x):
return x*(1-x)
X = np.array([[0,0,1], [0,1,1], [1,0,1], [1,1,1]])
y = np.array([[0], [1], [1], [0]]) actf - 뉴런의 출력을 계산해주는 함수이다. 시그모이드 함수를 활성화 함수로 사용함
actf_deriv - 시그모이드 함수의 미분값을 반환해준다. 오차 기울기를 구할때 필요하다.
X= np.array - 4개의 사례에 대한 data저장 마지막 열은 임계값을 위한 열이다.
y - 목표 행렬
np.random.seed(5)
inputs = 3 # 입력층의 노드 개수
hiddens = 3 # 은닉층의 노드 개수
outputs = 1 # 출력층의 노드 개수
# 역전파 학습 알고리즘의 1단계 : 초기화와 관련된 부분
weight0 = 2*np.random.random((inputs, hiddens))-1 # 가중치를 -1.0에서 1.0
weight1 = 2*np.random.random((hiddens, outputs))-1 # 사이의 난수로 초기화 한다.
for i in range(20000):
# 역전파 학습 알고리즘의 2단계: 활성화와 관련된 부분
layer0 = X # 입력을 layer0에 대입한다.
net1 = np.dot(layer0, weight0) # 행렬의 곱을 계산한다.
layer1 = actf(net1) # 활성화 함수를 적용한다.
layer1[:,-1] = 1.0 # 마지막 열은 임계값을 위한 열. 1.0으로 만든다.
net2 = np.dot(layer1, weight1) # 행렬의 곱을 계산한다.
layer2 = actf(net2) # 활성화 함수를 적용한다. 5~6번째 줄 - 가중치를 random함수를이용해서 초기화한다.
역전파 알고리즘의 2단계와 3단계를 반복한다. 여기서는 2단계 입력에 대해 은닉층의 출력값을 구하고 출력층의 출력값을 계산한다.
#역전파 학습 알고리즘의 3단계: 가중치 학습과 관련된 부분
layer2_error = layer2-y # 출력층에서의 오차를 계산한다.
# 출력층에서의 델타값을 계산한다.
layer2_delta = layer2_error*actf_deriv(layer2)
# 은닉층에서의 오차를 계산한다.
# 여기서 T는 행렬의 전치를 의미한다.
# 역방향으로 오차를 전파할 때는 반대방향이므로 행렬이 전치되어야 한다.
layer1_error = np.dot(layer2_delta, weight1.T)
# 은닉층에서의 델타를 계산한다.
layer1_delta = layer1_error*actf_deriv(layer1)
# 은닉층->출력층을 연결하는 가중치를 수정한다.
weight1 += -0.2*np.dot(layer1.T, layer2_delta)
# 입력층->은닉층을 연결하는 가중치를 수정한다.
weight0 += -0.2*np.dot(layer0.T, layer1_delta)
print(layer2) # 현재 출력층의 값을 출력한다. 역전파 알고리즘의 3단계 과정 코드
마지막 문장은 반복문에 들어있지 않고 마지막 사례에 대해서 최종적으로 출력해준다.
위 코드들을 실행하면 [[0.02508453][0.97180987]
[0.97195977][0.02267364]] 의 값이 결과값으로 나온다.
사례 4개에 대해서 출력층이 출력하는 최종값이다. 0에 가까운 값과 1에 가까운 값을 출력한다.
Keras
Keras는 python으로 작성되었으며 고수준 딥러닝 API를 제공하는 라이브러리이다. 텐서플로우 안에 포함
특징
쉽고 빠른 프로토타이핑이 가능
순방향 신경망, 컨볼루션 신경망과 순환 신경망은 물론 여라가지의 조합도 지원한다.
cpu 및 gpu에서 원할하게 실행된다.
Keras의 핵심 데이터 구조는 모델(model)이며 이것은 레이어를 구성하는 방법을 나타낸다. 가장 간단한 모델 유형은 sequential 선형 스택 모델이다.
신경망 구조 결정
from tf.keras.models import Sequential
model = Sequential() # Sequential 선형 스택 모델 생성
from tf.keras.layers import Dense # Dense는 완전 연결된 레이어를 다루는 클래스
# 모델에 레이어를 쌓으려면 add() 함수 사용
model.add(Dense(units=64, activation='sigmoid', input_dim=100))
model.add(Dense(units=10, activation='sigmoid'))Dense가 층을 다룰때 사용됨.
4번째 문장 - 신경망 노드의 갯수가 64개 활성화 함수는 시그모이드 함수로 input node가 100개 있는 층을 만들어준다.
5번째 문장- 4번째 문장 위에 시그모이드 노드 10개를 가진 레이어를 하나더 만들어준다.
학습과정 결정
# 모델 완성 후 compile() 함수로 학습 과정 구성
model.compile(loss='mse', # 손실함수를 평균 제곱 오차(MSE)로 지정
optimizer='sgd', # 최적화 방법으로 확률적 경사 하강법(SGD)
metrics=['accuracy']) # metrics는 정확도로 지정
model.fit(X, y, epochs=5, batch_size=32) # 학습은 fit()함수를 호출하여 진행
# 모델의 성능은 evaluate() 함수로 평가
loss_and_metrics = model.evaluate(X, y, batch_size=128)
# 새 데이터에 대한 예측은 predict() 함수 사용
classes = model.predict(new_X, batch_size=128)
1번째 - 손실함수를 평균 제곱 오차로 지정
2번째 - 최적화 알고리즘을 sgd사용
3번째 - metrics는 정확도로 지정
4번째 - X는 사례에대한 data y는 목표출력, batch_size 는 가중치를 조절할때 32개의 사례를 처리하고 조절하라는 것이다.
5번째 - evaluate()함수로 성능 평가
6번째 - 새 데이터 예측은 predict() 함수 사용
Keras XOR해결
import tensorflow as tf
import numpy as np
X = np.array([[0,0],[0,1],[1,0],[1,1]])
y = np.array([[0],[1],[1],[0]])
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Dense(2, input_dim=2, activation='sigmoid'))
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
sgd = tf.keras.optimizers.SGD(lr=0.1)
model.compile(loss='mean_squared_error', optimizer=sgd)
model.fit(X, y, batch_size=1, epochs=1000)
print(model.predict(X))X - 4개의 사례
Y - 목표 출력
임계값을 위한 노드를 추가할 필요가 없다.
은닉층 node의 갯수는 2개
출력층 node의 갯수는 1개
학습을 진행하고 사례 X에 대해서 predict()값을 출력해준다.
학습이 잘되었다면 0,1,1,0이 나올것이다.
에폭시가 1000이면 약간 애매하게 나오고 10000으로 늘리면 예측결과와 비슷해진다.

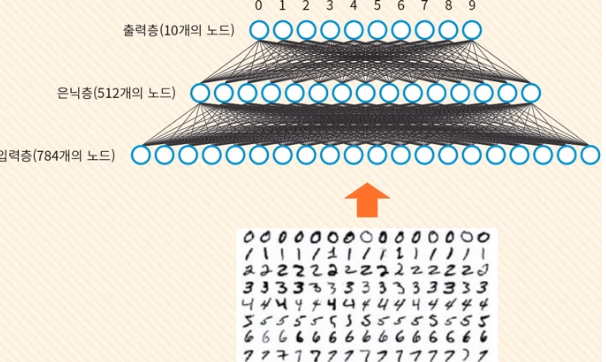
MLP를 사용한 MNIST 숫자인식
MNIST는 필기체 숫자 이미지를 모아둔 데이터 세트이다.
입력층의 node는 784개
은닉층의 node는 512개
출력층의 node는 10개
data 준비과정
import tensorflow as tf
batch_size = 128 # 가중치를 변경하기 전에 처리하는 샘플의 개수
num_classes = 10 # 출력 클래스의 개수
epochs = 20 # 에포크의 개수
# 데이터를 학습 데이터와 테스트 데이터로 나눈다.
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train = x_train.reshape(60000, 784) # 입력 이미지를 2차원에서 1차원 벡터로
x_test = x_test.reshape(10000, 784) # 변경한다.
x_train = x_train.astype('float32') # 입력 이미지의 픽셀 값이 0.0에서 1.0
x_test = x_test.astype('float32') # 사이의 값이 되게 한다.
x_train /= 255
x_test /= 255다층 퍼셉트론에서 사용할려면 2차원에서 1차원 벡터로 변경해야된다. 그리고data값을 0~1 사이의 값으로 만들어 준다.
# 클래스의 개수에 따라서 하나의 출력 픽셀만이 1이 되게 한다.
# 예를 들면 1 0 0 0 0 0 0 0 0 0과 같다.
y_train = tf.keras.utils.to_categorical(y_train, num_classes)
y_test = tf.keras.utils.to_categorical(y_test, num_classes)
# 신경망의 모델을 구축한다.
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Dense(512, activation='sigmoid', input_shape=(784,)))
model.add(tf.keras.layers.Dense(num_classes, activation='sigmoid'))
model.summary()
sgd = tf.keras.optimizers.SGD(lr=0.1)은닉층과 출력층의 선언
model.summaray()는 모델의 정보들을 요약해놓은걸 보여준다.
optimizers - 확률적 경사하강법을 이용한다.
# 손실 함수를 제곱 오차 함수로 설정하고 학습 알고리즘은 SGD 방식으로 한다.
model.compile(loss='mean_squared_error',
optimizer=sgd,
metrics=['accuracy'])
# 학습을 수행한다.
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs)
# 학습을 평가한다.
score = model.evaluate(x_test, y_test, verbose=0)
print('테스트 손실값:', score[0])
print('테스트 정확도:', score[1])compile() 함수로 학습과정을 지정한다.
fit()함수로 학습을 수행.
evaluate()함수로 학습을 평가.

처음에 나오는 값들이 summary() 함수의 결과들이다.
컨볼류션 신경망
컨볼류션 신경망을 이용한 MNIST숫자 인식 문제의 해결 예
Conv2D와 MaxPooling2D층을 쌓아서 컨볼류션 신경망을 구축 (CNN텐서플로우 프로그램 참조)
앞선 신경망과의 차이를 알아두자!!!
import tensorflow as tf # 필요한 라이브러리를 포함시킨다.
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras import datasets, layers, models
mnist = keras.datasets.mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()필요한 데이터와 test를 위한 사례를 나누어서 저장한다.
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))
train_images = train_images / 255.0
test_images = test_images / 255.0
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))사례를 2차원의 형태로 다룰수 있다. 결국에는 사례를 4차원 tensor로 만들어야된다.
픽셀의 값을 0~1사이로 바꾸어준다.
컨볼루션 신경망도 sequential()사용
6번째 - 합성곱층이다. Conv2D()로 만든다. 32는 필터의 개수,(3,3)은 필터의 크기이다. input은 2차원 이미지
7번째 - MaxPooling층 가로 세로 가장층 값을 도출
8번째- 합성곱층 추가 필터의 갯수 64개
9번째 - MaxPooling층 추가
10번째 - 합성곱층 하나더 추가.
심층신경망에서는 마지막 합성곱층이 없다!
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
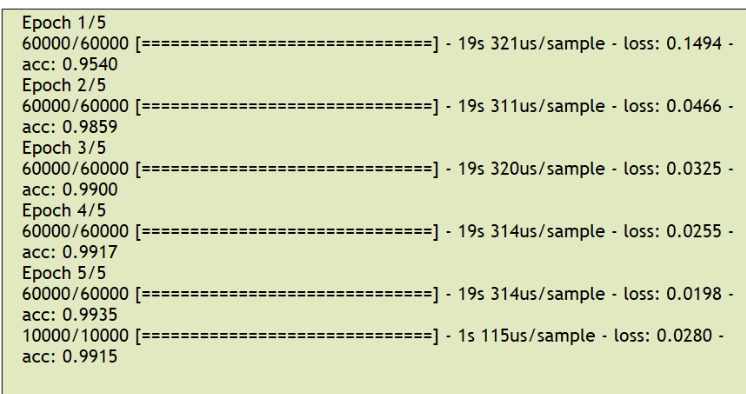
model.fit(train_images, train_labels, epochs=5)
test_loss, test_acc = model.evaluate(test_images, test_labels)1번째 - 마지막 합성곱층에서 나온 특징지도를 펼친다. 다층 퍼셉트론의 입력층
2번째 - 다층 퍼셉트론의 은닉층이다.
3번째 - 다층 퍼셉트론의 출력층
4번째 - 학습과정에 대해 정함. adam 최적화 알고리즘 사용(기본적으로 역전파 알고리즘,but 개선됨) 손실함수는 크로스 엔트로피
5번째 - 학습시킴.
6번째 - 결과 평가.
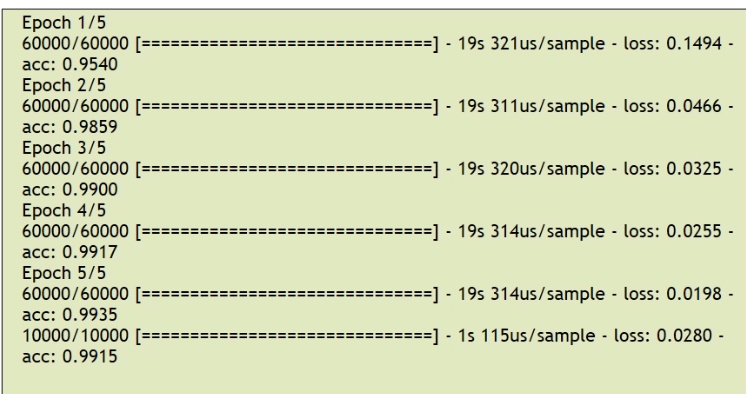
마지막에 정확도가 99프로에 가까운 신경망이 만들어진다.
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
먼가 굉장히 많은 코드를 보았지만 구조는 거의비슷한거 같다. 서로 어떤식으로 다른지 파악하는게 중요한듯!
