개요
RAG 같은 시스템을 만들다 보면 "임베딩"이라는 단어를 꽤 자주 듣게 된다.
임베딩이란 인공지능 분야에서 이미지, 오디오, 텍스트 같은 비정형 데이터를 연속적인 실수 벡터로 변환하는 아주 중요한 기법이다.
이렇게 변환해 두면 비정형 데이터를 연산하기 편리할 뿐 아니라, 그 데이터가 원래 담고 있던 의미와 맥락을 최대한 반영해줄 수 있다.
그런데 임베딩을 단순하게 설명할때 데이터를 특정한 차원에 "점"을 찍는다 라고 설명하여도 크게 이상하다고 느껴지지 않았다.
하지만 왜 굳이 점이 아니라 벡터로 표현해야할까?
임베딩(Embedding)이란?
임베딩은 차원이 높은 데이터를 고정된 차원의 벡터로 매핑하는 과정이다. 즉 비정형 데이터들을 연산가능한 벡터로 만드는 것이다.
위 애니메이션 이미지를 보면, 여러 이미지들이 공간 상에 특정 지점에 매핑되어 있는 걸 볼 수 있다.
쉽게 말해, 이미지가 비슷하면 서로 가깝게, 다르면 서로 떨어진 위치로 놓이게 되는 식이다.
이렇게 이미지를 벡터로 만들어 놓으면, 벡터 간 유사도를 계산하거나, 벡터를 조합하고 비교하는 게 훨씬 쉬워진다.
벡터(Vector)란
스칼라와 벡터의 차이
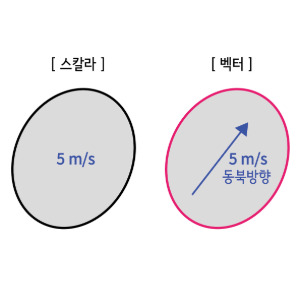
벡터는 스칼라와 함께 비교하며 말해야한다.
스칼라는 하나의 값, 예를들면 온도나 길이처럼 딱 하나의 숫자로 표현된다.
벡터는 여러 차원으로 이루어져있고 각각의 차원에 따라 값이 다르게 들어간다.
"강아지" 라는 단어를 "0.61"과 같은 단순 스칼라로 표현해버리면 해당 단어가 지닌 여러 의미나 뉘앙스 등을 제대로 반영하기 어렵다. 하지만 다차원 벡터로 표현하면 훨씬 풍부한 정보를 담아낼 수 있다
점과 벡터의 차이
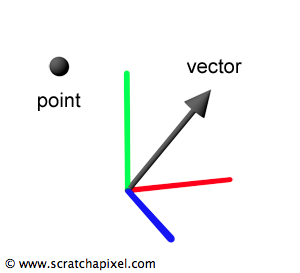
2차원 평면에서 점이라 하면, 보통 (x, y) 좌표를 단순히 위치로만 본다.
그런데 임베딩에서 말하는 벡터는 좌표 위치 이상의 방향과 크기 같은 속성을 같이 담는다.
결국 벡터가 되면, 여러 개의 축(차원)을 통해 데이터 간의 유사도, 관계, 거리를 다양하게 볼 수 있게 된다.
단어 임베딩에서 벡터로 표현하는 이유
단어간 의미 유사도 계산
벡터로 표현되어 있으면, 단어끼리 얼마나 비슷한지 수치화가 가능하다.
예컨대 강아지와 고양이 벡터 간 코사인 유사도를 구하면, 둘의 의미나 쓰임새가 비슷한지 어느 정도 숫자로 판단할 수 있다.
그냥 점 하나에 스칼라 하나만 있었다면 이런 비교가 훨씬 어렵거나 불가능하다.
단어 의미 연산 가능
벡터끼리는 덧셈, 뺄셈 같은 연산이 가능하다.
유명한 예가 바로 King - Man + Woman = Queen이라는 벡터 연산이다.
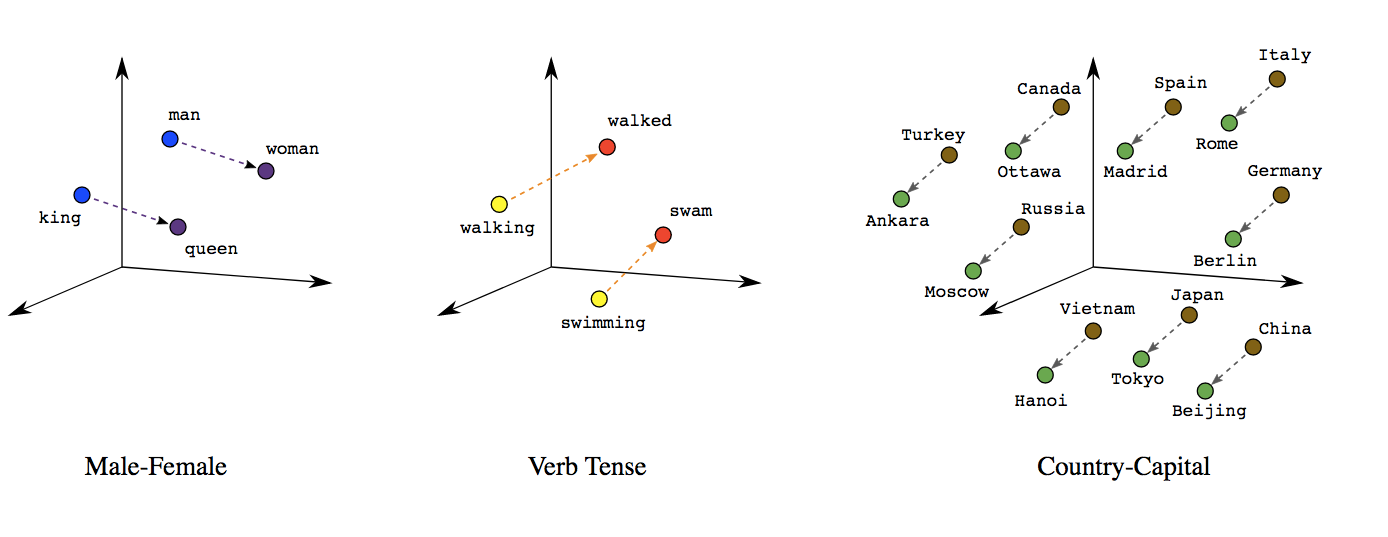
이건 “왕”과 “여성” 사이의 의미 차이가 “여왕”으로 이어진다는 거다.
물론 실제로 완벽하게 맞아떨어지진 않을 때도 있지만, 대체로 이런 식의 “의미 계산”이 가능하다.
맥락 정보와 다의어 처리
BERT, GPT 같은 모델들은 단어가 놓인 맥락(Context)에 따라 벡터가 달라지게 한다.
예컨대 눈이 하늘에서 내리는 눈인지, 사람의 시각기관 눈인지 맥락에 따라 벡터가 달라지는 식이다.
결국 이렇게 벡터로 만들어 놓으면, 똑같은 단어라도 상황에 따라 다른 의미를 표현할 수 있고, 그 유연함이 임베딩을 통해 실현된다.
실제 벡터공간에서의 예시
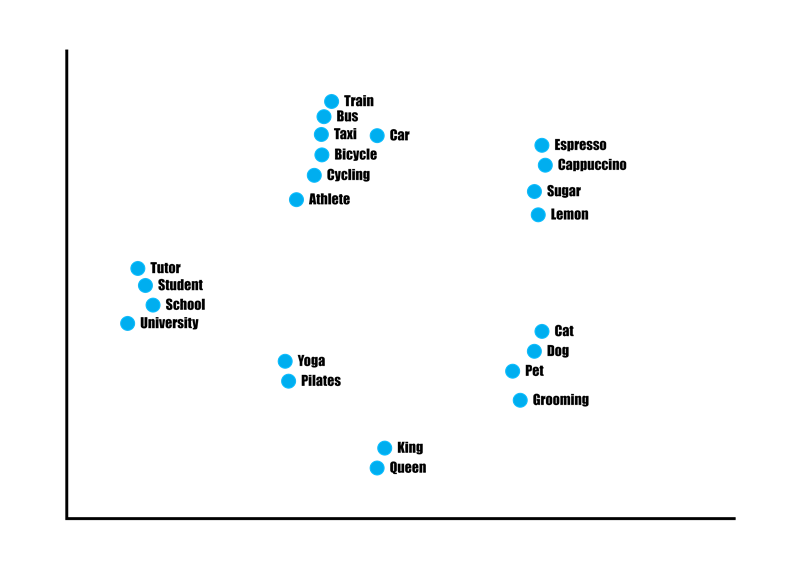
위 이미지를 보면 서로 비슷한 의미를 가진 단어끼리 가깝게 위치하며 각 단어간의 의미론적 차이가 벡터를 통해서도 표현이 되어있는 모습을 볼 수 있다.
분산 표현
위 글을 전부 읽고나면 임베딩 벡터의 각 차원이 특정의미를 담고있을것이라고 보기 쉽다.
예를들어 1번째 차원은 긍정/부정, 2번째 차원은 시제, 3번째 차원은 남성형,여성형 과 같이 각 차원마다 딱딱 떨어지는 의미를 담고 있을거라고 생각하기 쉬운데 실제로는 단순하게 구분하기 힘들다.
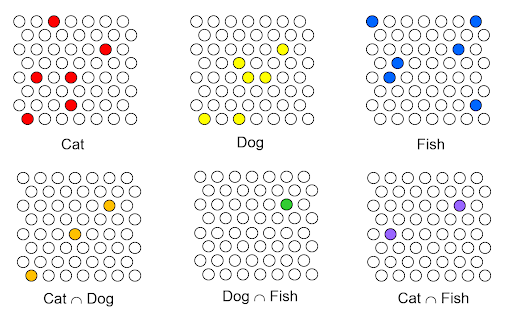
위 이미지에서 보듯 고양이, 강아지, 생선끼리의 교집합을 통해 얼마나 가까운지에 대해서는 확인할 수 있으나 어떤 점이 색칠되어있는지 안다고 해서 해당 데이터를 전부 이해할수는 없다.
벡터 차원별 의미 표현법
벡터의 여러 차원이 모여서 집단적으로 왕(King)이나 사랑(Love) 같은 단어가 가진 의미를 표현한다.
즉, 한 차원이 하나의 의미를 단독으로 담당하는 게 아니라, 의미가 여러 차원에 걸쳐 분산되어 있다. 이를 분산표현이라 한다
따라서 "[0] 이 남성/여성을 완벽히 나타내고, [1] 이 존경/혐오 감정을 나타낸다…" 이렇게 해석하기는 어렵다.
오히려 여러 차원이 함께 만들어내는 패턴(조합)을 통해 해당 단어가 어떤 맥락, 어떤 분위기, 어떤 주제를 가지고 있는지 판단하게 된다.
학습 과정에서 차원이 자동으로 결정됨
Word2Vec 이나 딥러닝을 사용한 다른 알고리즘들은 모델이 데이터를 학습하면서 차원별로 어떤 정보를 분산해서 담을지 자동으로 결정한다.
그러다보니 사람이 직접 임베딩된 벡터를 눈으로 봤을때 하나의 차원만을 보고 뚜렷한 하나의 해석을 하기에는 불가능하다.
요약
- 점이 아닌 벡터로 표현하는 이유는 단순 위치정보인 점보다 크기와 방향을 가지고 있는 벡터가 다양한 의미를 풍부하게 표현하기에 적합하다.
- 벡터간의 유사도 계산이나 벡터 연산을 통해 데이터(단어, 이미지, 오디오)를 수학적으로 다룰 수 있음
- 임베딩 벡터는 각 차원이 단독으로 의미를 갖는게 아니라, 여러 차원이 "분산 표현" 형태로 의미를 함께 담는다.
참고
https://developers.google.com/machine-learning/crash-course/embeddings?hl=ko
https://www.youtube.com/watch?v=OzTHZ0SIulg
