컴퓨터 비전 작업들(CV task)

- 영상 분류 (image classification)
- 의미적 분할 (semantic segmentation)
(픽셀 하나하나를 분류함) - 분류와 위치 추정 (classification & localization)
(single object, classification을 수행하는 동시에 bounding box위치 추정(regression) 수행) - 물체 탐지/검출 (object detection)
(multiple object) - 인스턴스 분할 (instance segmentation)
(의미적 분할과 달리 background에 관심이 없으며 같은 class일지라도 서로다른 instance임을 구분할 수 있다. )
합성곱 신경망은 컴퓨터 비전 분야에 많이 활용된다.
classification & localization (분류와 위치 추정)
single object detection과 classification 기능이 구현되어야한다.
DCNN (심층 합성곱 신경망의 구성)
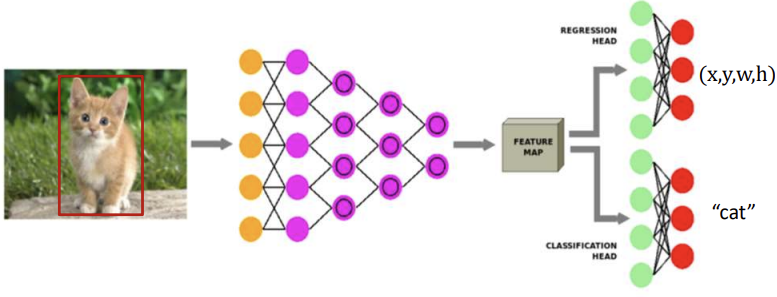
- 회귀 헤드: 물체의 위치추정(x,y,w,h로 이루어진 bounding box)
- 분류 헤드: 물체/영상 분류
- 손실함수 L = a*Lc + (1-a)*Lr
이때 a는 가중치 비율이고 Lc,Lr은 각각 분류와 회귀에서의 loss이다. 분류와 회귀 둘다 잘 이루어져야 하므로 손실함수가 결합된 형태로 이루어진다. - 헤드가 2개라는 뜻은 출력이 2개라는 것을 의미한다.
앞부분 Raw data와 CNN이 연결된 부분은 feature extract 과정으로 feature map을 추출한다.
추출한 feature map이 두개의 FCN (그러므로 헤드도 두개이다)의 input으로 들어가 각각 bouding box와 classification을 진행한다. 물론 FCN이 feature map을 그대로 받아들이지 못해 flatten 전처리를 해주어야한다.
object detection(물체 탐지/검출)
물체 탐지(!= 분류와 위치 추정) (multiple object != single object)
영상속에 존재하는 다수의 물체 위치 정보와 물체 분류를 판정하는 작업, 물체의 개수나 크기는 미리 알 수 없음
single object라면 이미지에 오브젝트가 무조건 있다고 판정하고 bbox와 분류를 수행하면 되지만
multiple object라면 몇개가 이미지의 어느 부분의 어느 클래스인지 분류해야하므로 더 고난이도이다.
R-CNN (영역 기반 합성곱 신경망)

일단 input image로부터 머신러닝 알고리즘은 이미지에 대한 정보가 아예 존재하지 않는 상태이다.
- 외부 프로그램이 물체가 있어보이는 영역을 추천해준다.
- 추천받은 각 영역을 fearue map 추출기에 넣는다.
그러나 이때 추천받은 영역들의 크기가 같은 것을 기대하기는 어렵다. 추천받은 영역은 크기가 각양각색으로 feature map추출기에 input하기에 적절치 않다 그러므로 이러한 영역 조각들을 일정한 크기로 늘이거나 줄이거나 하여 변환해준다. - 영역 조각을 input으로 받을 때 CNN은 그것이 마치 전체 이미지인것 처럼 다루어 feature 추출을 진행한다.
- 생성된 feature map으로 classification을 수행한다.
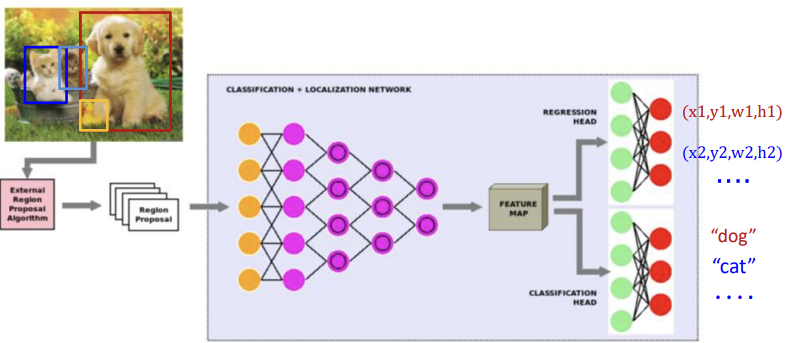 위 그림은 R-CNN을 시각화한 모습이다.
위 그림은 R-CNN을 시각화한 모습이다.
앞서 말했듯이 외부 tool이 추천해준 영역들을 하나의 image인 것 처럼 하나하나 DCNN에 삽입하여 준다. 삽입한 이미지는 하나의 feature map이 될 것이다.
물론 영역추천이 잘되어있다면 bbox의 수정은 필요없겠으나 그렇지 않은경우가 대부분이여서 DCNN에서 한번 더 bbox를 더 정확하게 회귀하여 주고 이러한 feature map을 바탕으로 classification을 수행한다.
이러한 R-CNN의 동작과정은 추천한 영역들을 일일이 DCNN에 넣어주어야 하는 단점이 있다.
Fast R-CNN
- Fast R-CNN은 말 그대로 R-CNN보다 25배 빠른 속도를 가진다.
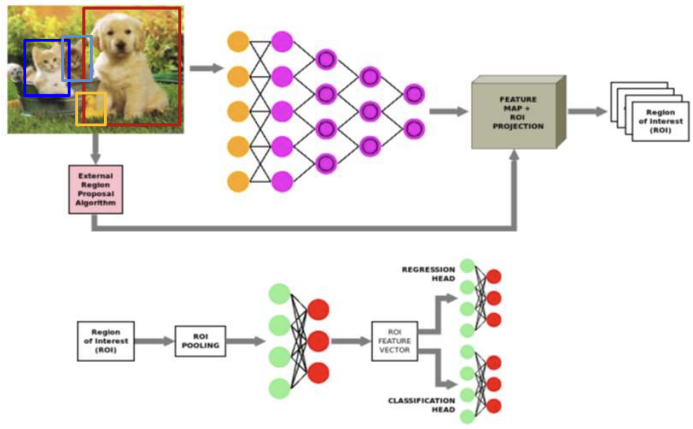
- 외부 프로그램이 물체가 있어 보이는 영역을 추천해준다.
- 이때 1에서 나온 영역을 그대로 집어넣지 않는다. (추천 영역을 DCNN에 넣으면 R-CNN)
- Raw image data를 통채로 CNN에 input하여 영상 통채로 feature map을 추출한다. feature map에서 region을 나눔
- 이때 1번을 통해 얻은 추천영역을 바탕으로 3번에서 나온 feature map을 나눠서 ROI를 추출한다.
- 추출한 ROI를 ROI pooling 과정을 거쳐 bbox를 생성하고 classification을 수행한다.
ROI Pooling
- 다양한 크기의 ROI feature map들을 동일한 고정 크기로 변환 (ROI feature Map이 모두 다르므로)
즉 feature map 수준에서 나눈 object들의 크기를 고정크기로 한다.
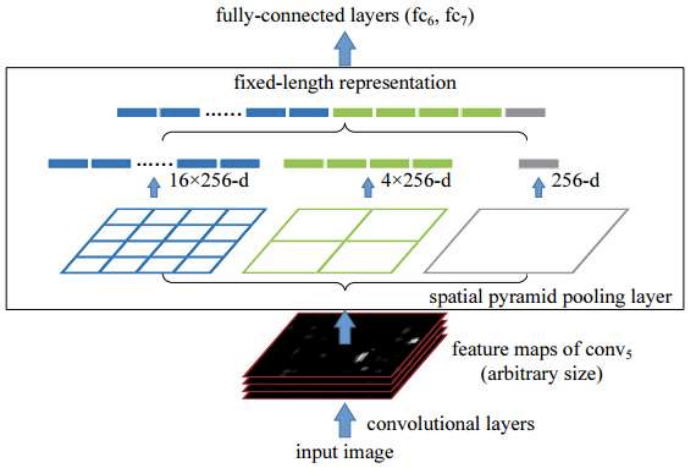
- 파란색 부분은 특정 ROI feature map을 16개의 조각으로 나누고 각 조각에 value를 부여하고
- 녹색부분은 4개
- 회색부분은 1개
총 21개의 조각을 fully connected layer에 input하는 방식이다.
이때 엄청 크거나 작거나 가로로 길거나 세로로 긴 ROI feature map도 ROI pooling 과정을 거치면
fixed-length가 되기 때문에 모든 feature map이 고정크기가 된다.
Faster R-CNN
- R-CNN보다 250배 Fast R-CNN보다 250배 더 빠른 속도
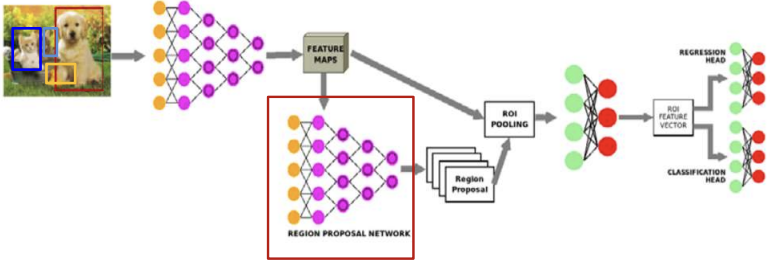
- 위 두개의 CNN과 다르게 외부 프로그램으로 영역 추천을 받지 않는다.
- 우선 Raw data를 CNN으로 feature map을 추출한다.
- 추출한 feature map을 CNN(영역 제안 net)을 통해 영역제안을 받는다.
- 3번에서 생성한 영역제안을 2번에서 추출한 feature map에 적용하여 ROI를 추출하고 ROI pooling을
거쳐 bbox를 생성하고 classification을 수행한다.
하지만 이 방식은 parameter가 너무 많아 많은 양의 data가 필수적이다.
Faster R-CNN 훈련 (2-stage 물체탐지)
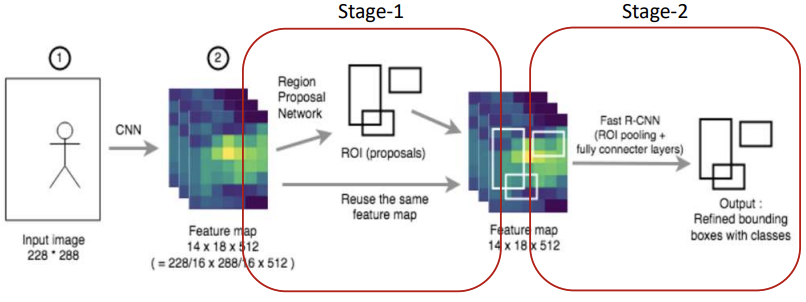
RPN부분과 fast R-CNN 부분을 각각 별도로 훈련
Anchorbox로 대략적 위치 인식 => RPN으로 조정 => R-CNN으로 조정
stage-1에서는 Anchor box를 통해 점수가 높은 ROI를 추출한다.
stage-2에서는 ROI pooling을 통해 전처리한 data에 대해 회귀와 분류를 진행한다.
RPN (Region Proposal Network)
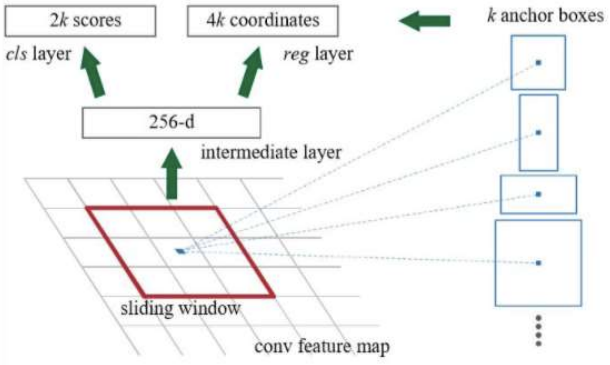
Faster R-CNN에서 3번에서 사용한 영역제안net이다.
- 영상을 일정 크기로 쪼갬 (위 그림에서 작은 격자)
- sliding window를 기준으로 anchor boxes를 대입해봄
(이때 anchor box는 기본틀)(기본적인 후보 모양) - value 매김(후보평가)
이때 평가는 물체가 있는지 없는지 점수를 매김 = 2k / box크기를 얼마나 다시 재조정하는가 = 4k - sliding을 반복
