신경망 유형
Fully connected Networks(FCN 완전연결 신경망)
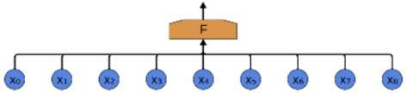
모든 뉴런이 연결되어있고 이전 층의 모든 output이 다음 층의 모든 뉴런의 input으로 각각 연결됨
완전 연결 신경망(FCN)의 문제점
영상과 같은 2차원 이상의 data(다차원 data) 처리시 아래 2가지 문제점 발생
-
매개변수의 폭발적 증가
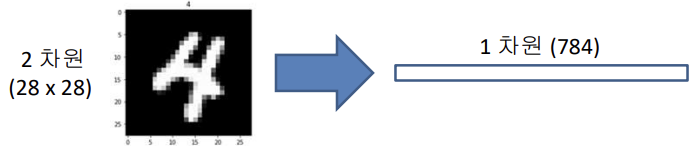
만약 28*28 짜리 입력 영상 벡터가 있다고 할 때
은닉층과 출력층 뉴런이 각각 128,128,10개라면
학습해야하는 매개변수의 개수는
28*28 = 784 이므로
(784+1) * 128 + (128+1) * 128 + (128+1) * 10개로 약 12만개 이다. -
공간(위치,거리) 정보 소실
한 계층의 각 뉴런은 이전 계층의 모든 출력값을 입력으로 받는데
다차원 data를 FCN에서 학습시키기 위해서는 flatten 전처리 과정을 거치게 되어 입력데이터의 위치 혹은 상대적인 거리 정보가 소실된다.
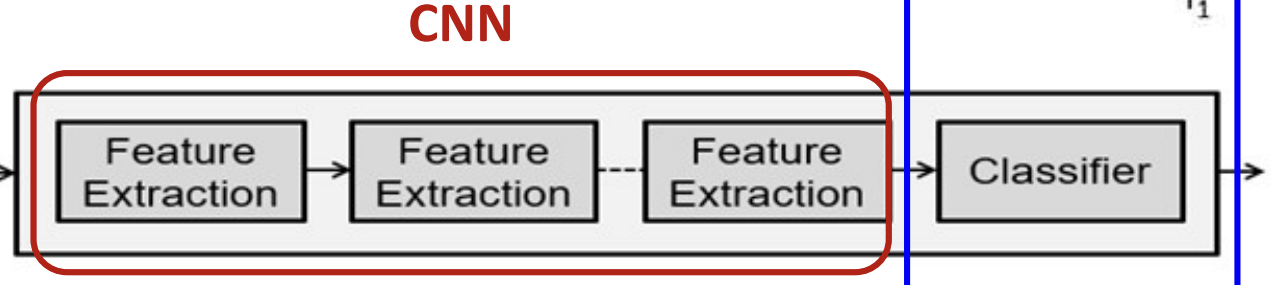
Convolutional Networks (CNN, 합성곱 신경망)
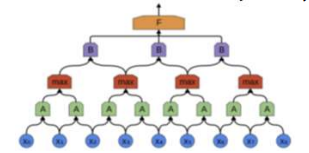
조직도처럼 output중 일부만 input으로 다음 층의 뉴런에 연결됨
각 뉴런은 2차원 입력 data나 이전 계층의 이웃한 특정 지역의 출력값들만 1차원으로 변환없이 입력으로 받아 처리함 지역적 수용 영역에 해당하는 data만 받아들이고 나머지는 받아들이지 않음 마찬가지로 하나의 value가 넓은 범위를 대표하므로 layer가 깊어질수록 high level이 됨
장점: 매개변수 개수의 감소, 데이터의 위치 정보 보존 가능
합성곱 신경망의 전형적인 예
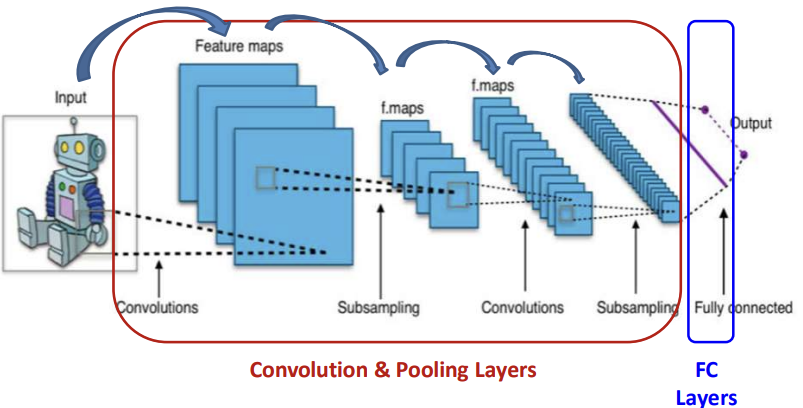
합성곱 신경망은 합성곱계층 + 풀링계층 + 완전연결계층으로 이루어짐
합성곱(convolution) 계층
- 커널/필터: W (2차원 형태의 가중치 data)
이때 커널은 parameter로서 FCN의 간선처럼 학습마다 갱신된다. - 특징 맵(feature map): 합성곱 결과 생성된 특징 맵
- 특징 볼륨(feature volume): 생성되는 특징맵 개수
(서로다른 커널(파라미터) = 서로다른 feature map)
(N개의 커널을 사용 -> N개의 특징 맵 생성됨) - 초매개변수들
: 커널개수N, 커널크기k, 보폭(strides)s, 패딩(padding)p - 합성곱계층 계산법 32 * 32 를 5 * 5 짜리 커널로 합성곱을 진행하면 32-5+1짜리 feature map이 생성된다. 즉 28 * 28짜리 feature map이 생성된다.
- 공식 x * x짜리 feature map을 k크기의 커널로 s 보폭만큼 합성곱을 진행하면
(x-k)/s + 1 = y (이때 y는 생성된 feature map)
3*3 짜리 지역적인 노란 data가 하나의 data가 됨
5 * 5 에서 3 *3 로 size가 작아짐
만약 위 예시에서 strides를 2로 한다면 convolved Feature의 크기는 2 * 2가 된다.
즉 커널크기가 동일하다고 하여도 보폭이 다르면 feature map의 크기가 다름
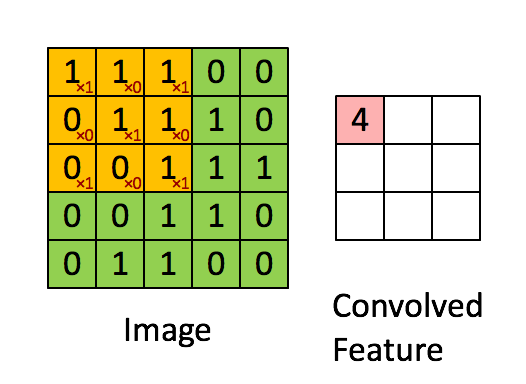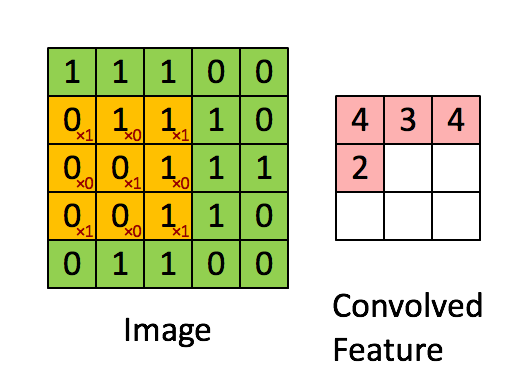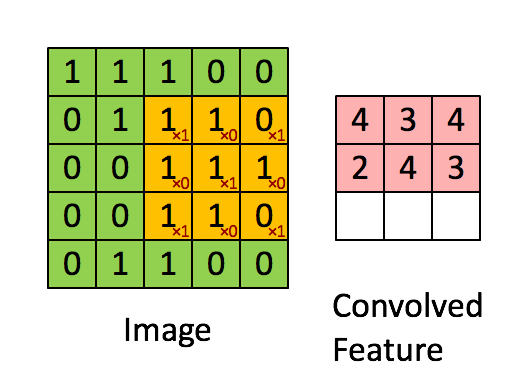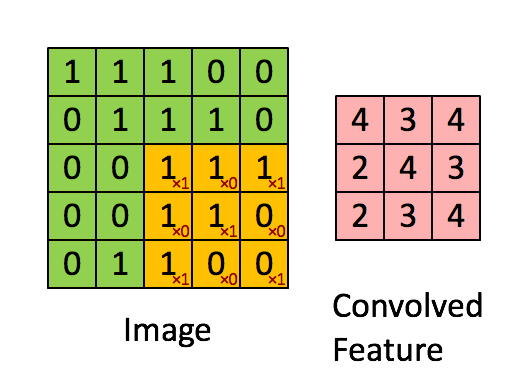
보폭에 따른 feature map 생성결과가 달라진다.
패딩을 하게되면 경계선을 0으로 패딩하여 feature map의 크기가 작아지지 않음
풀링(pooling) 계층
- 이웃한 뉴런들의 출력(feature map, 특징 정보)를 요약한다(summerizing)
- 최대 / 평균 풀링으로 나뉨
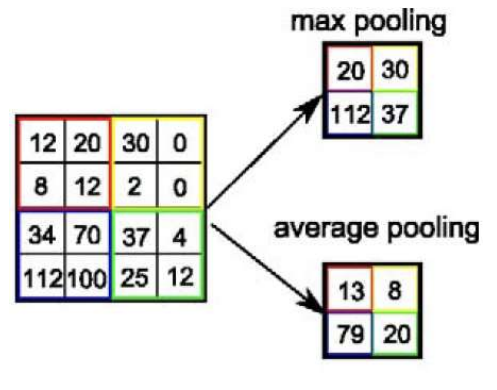 max Pooling과 average Pooling
max Pooling과 average Pooling
padding도 stride가 있을 수 있는데 위 예시에서는 stride가 2라고 볼 수 있다.
합성 곱 신경망 LeNet-5 구현모델
모델의 구조를 앞에서부터 차근차근 살펴보자면
맨처음 32*32 크기의 raw data image가 있다. 이 image가 input이 된다.
LeNet-5 해석
-
conv#1 layer를 통과할때 N=6, k=5, s=1, p=0으로 해석하자면
커널크기:6, 커널 사이즈:5, 보폭:1, 패딩여부:false로 해석된다.
이 계층 결과 feature map은 6개 생성될 것이며 32-5+1하여 28*28크기가 될 것이다.
그러므로 28*28 feature map 6개가 생성된 모습을 볼 수 있다. -
max-pool#1 layer를 통과 할 때 k=2, s=2, p=0으로 해석하자면
커널크기:2, 보폭:2, 패딩여부:false로 해석된다.
이 계층 결과 feature map은 동일하게 6개이고 크기는 (28-2)/2 + 1하여 14*14크기가 될 것이다. 그러므로 14*14로 크기가 줄어든 모습을 볼 수 있다. -
conv#2 layer도 같은 공식으로 14-5 + 1 으로 10*10 크기 feature map 16개가 생성된 모습을 볼 수 있다.
-
max-pool#2 layer의 결과도 마찬가지로 크기가 절반으로 줄어 5*5로 크기가 줄어든 모습을 볼 수 있다.
-
뒷부분 3개의 FC layer는 flatten된 feature map을 기반으로 학습과 classification을 수행하여 10개의 class를 구분한다.
이때 pool layer를 보면 N이 없다. 즉 커널이 없다는 뜻이고 이는 parameter가 없다는 뜻이다.
parameter가 없다는 것은 학습 대상이 없다는 것이며 즉 pool layer는 학습이 이루어지는 계층이 아니다.
보통 conv 와 pool 한쌍을 한 block으로 간주한다.
합성곱 신경망의 지식 전이
새로운 작업을 위한 새로운 신경망 모델을 효율적으로 생성하기 위해, 매우 큰 data 집합을 이용해 미리 사전-학습해둔 신경망의 전체 혹은 부분 구조와 가중치들을 재사용하는 것
새로운 작업용 data를 이용해 이 모델을 다시 미세 조정함
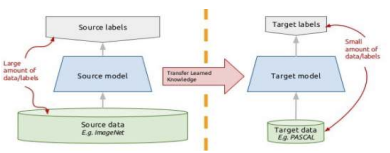
즉 한쪽 domain(task)에서 잘 작동하는 모델을 그대로 끌고와 일부 조정하여 나의 task에 맞게 model을 일부 설계하고 학습하는 것을 의미한다.
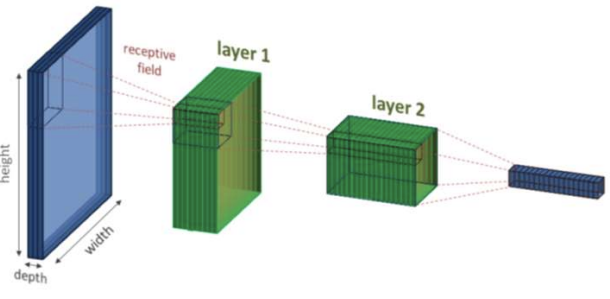
영상처리모델의 low level 부분은 잘만들어진 모델을 따와 만들고 high level 부분을 내가 하고자하는 task에 맞게 조정하는 것이 현명한 방법일 것이다.
Recurrent Networks (RNN, 순환신경망)
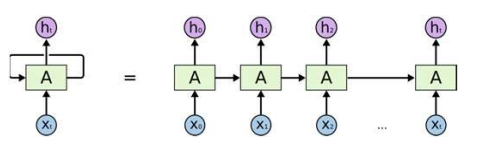
시간의 흐름에 따라 계층이 깊어짐 sequntial한 패턴
Shallow Learning vs Deep Learning
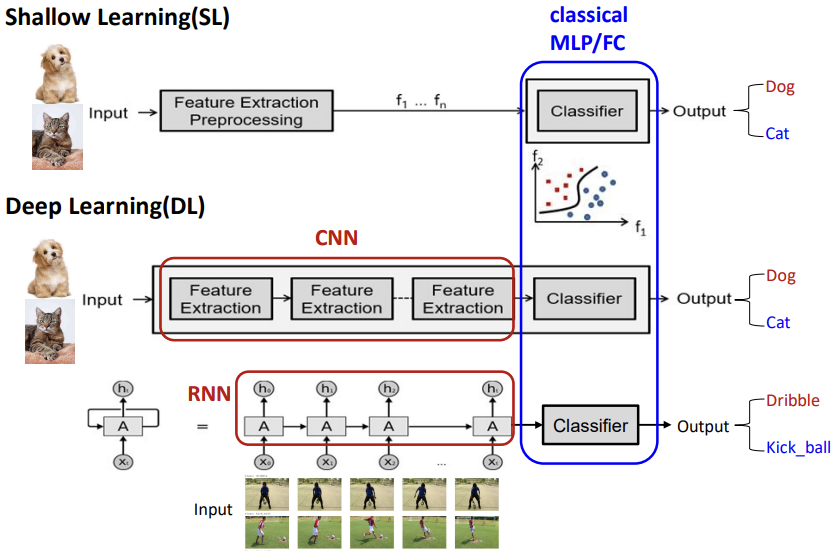
Shallow Learning
data input시 내가 원하는 output으로 보기 쉽게 다듬는다. (Feature Extracting Preprocessing)
전통적인 feature추출 과정에서는 이미 개발된 알고리즘(feature map 알고리즘 제작자가 만든)을 기반으로 원시 data에서 불필요한 정보를 걷어내고 필요한 정보만을 추출하여 feature map을 추출한다.
이러한 feature 추출의 질에 따라 성능에 절대적인 영향을 끼치므로 feature map 제작자는 input data에 대하여 전문적이어야 한다.
또한 classical MLP/FC인 classifier로 output을 결정한다. (feature map을 기반으로 classification을 진행하므로 neural network는 깊을 필요가 없다.)
Deep Learning
딥러닝은 shallow learning과 다르게 feature map을 머신러닝 알고리즘이 생성해준다.
이러한 feature 추출 과정이 neural network로 이루어지기 때문에 전체적으로 network가 깊다.
딥러닝 feature extraction은 input 쪽 layer일수록 low level / output 쪽 layer일수록 high level인데 low level 일수록 모호하고 비슷하여 feature 추출이 어려운 반면 high levle 일수록 더욱 복잡한 문제를 해결할수 있어 특징적이고 분명해진다.
그러므로 hidden layer를 여러개 두면 둘수록 네트워크가 깊어지고 복잡해져 더 high level feature를 학습할 수 있게 된다.
Deep Learning의 성공요인
- 가용가능한 양질의 dataset
- GPU 성능의 상승
- simple activation function (Relu)
- better reqularization methods
