신경망이란?
인공신경망은 기계학습과 인지과학에서 생물학의 신경망에서 영감을 얻은 통계학적 학습 알고리즘이다. 인공신경망은 시냅스의 결합으로 네트워크를 형성한 인공 뉴런이 학습을 통해 시냅스의 결합 세기를 변화시켜, 문제 해결 능력을 가지는 모델 전반을 가리킨다.
(출처 위키백과)
퍼셉트론
하나의 뉴런을 모사한다.
이때 퍼셉트론의 입력으로는
하나의 뉴런의 결과값은 2가지의 표현으로 0,1 혹은 true,false로 출력한다.
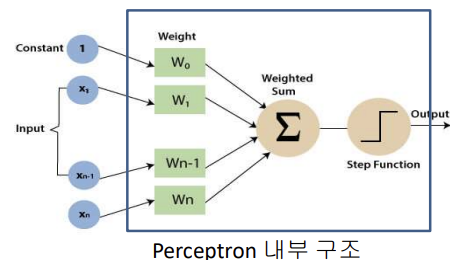
위 그림과 같이 weight와 bias에 따라 출력을 결정하며 wighted sum의 결과에 step function을 적용하여 출력값을 결정한다.
MLP (Multi-Layer Perceptron)
퍼셉트론 계층을 여러층 쌓은 신경망 구조로
FCN이다. (fully connected layer, FC layer)
입력층, 은닉층, 출력층으로 구성된다.
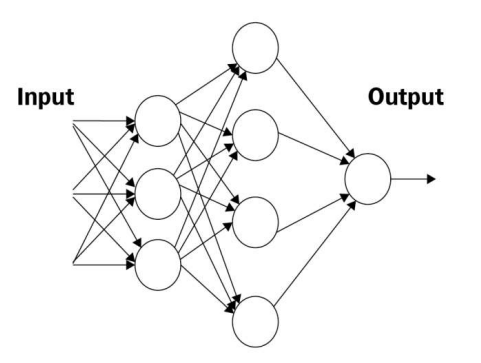
위 그림을 보면 입력층, 은닉층, 출력층 각각 한 layer씩으로 구성되었다고 착각하기 쉬우나 사실이 아니다.
input이 적혀있는 부분은 퍼셉트론으로 이루어진 layer가 아니라 그저 data 그 자체가 입력받아지는 layer로 볼 수 있다.
output이 적혀있는 부분에 있는 하나의 퍼셉트론의 출력값이 그대로 이 FCN의 output이 되므로 출력층으로 보고
나머지 가운데에 위치한 3개,4개짜리 퍼셉트론으로 구성된 layer과 바로 hidden layer로 보여진다.
즉 위 MLP는 입력층 1개, 은닉층 2개, 출력층 1개로 구성되어있다고 하는 것이다.
이때 각각의 퍼셉트론을 살펴보면 모두 앞 계층들의 모든 뉴런의 영향을 받는 다는 것을 볼 수 있는데 이것이 바로 FCN의 특징이라고 볼 수 있다.
또한 앞에서 설명했듯이 퍼셉트론 하나는 true or false로 classification을 수행하는데 위 구조에서는 output layer의 퍼셉트론이 하나이므로 1 혹은 0에 대한 판단만 수행할 수 있다.
퍼셉트론의 한계
초창기 퍼셉트론 활성함수로서 고정 임계치가 적용되어 안정적인 수렴이 어려웠다.
이 말의 뜻은 자그마한 오차에도 가중치(혹은 초평면)가 크게 변화하여 최적의 값으로 안정적으로 수렴할수 없었다는 것이다.
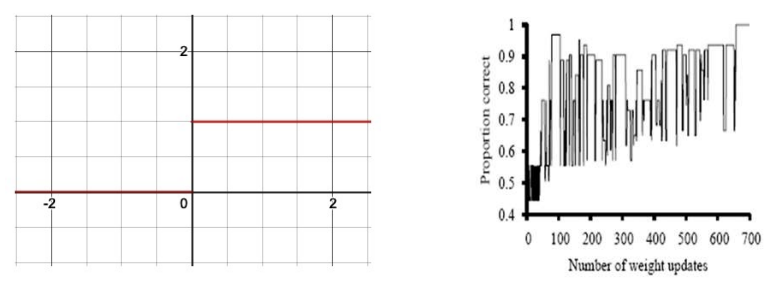
좌측의 그림을 보면 0과 1사이의 경계에서 퍼셉트론의 출력값이 안정적인 수렴을 시도할 때 조그마한 값에도 가중치가 크게 영향을 받는다는 것을 알수 있고
(경계에서 널뛰기해서 수렴이 힘들다)
이러한 이유로 우측의 그림은 가중치 갱신이 반복됨에도 불구하고 최적의 값으로 수렴하지 못하는 현상을 시각적으로 보여준다
이는 출력이 불연속적이고 미분불가능한 활성함수로 인해 발생하였다고 보아 고정임계치 대신 미분가능한 연속함수가 필요함을 느낄 수 있다.
Activation function
고정임계치로 인한 한계를 넘어서고자 미분가능한 연속함수인 활성함수들이 제기되었다.
-
Sigmoid/Logistic
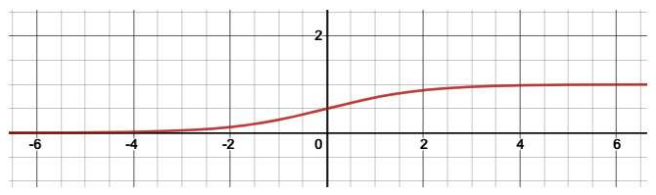
고정임계치 방식보다 값의 널뛰기가 덜하여 좀더 학습에 유리하다고 볼 수 있다.
0과 1사이의 값을 출력한다. -
Tanh

-1과 1사이의 값을 출력한다. -
ReLU
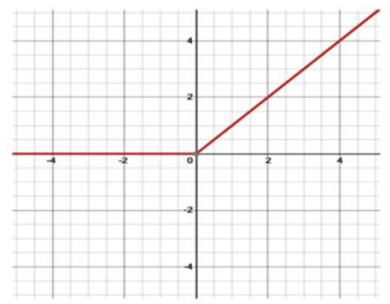
f(x) = max(0,x) 꼴로, 0보다 작으면 0이고 0보다 크면 값 그대로를 출력한다.
(제일 많이 쓰임) -
Softmax
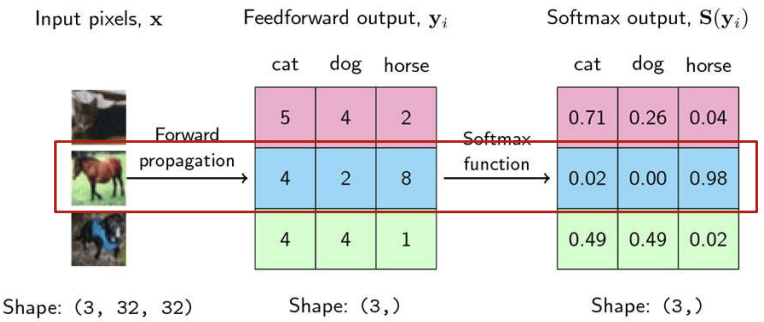
입력값에 대하여 상대적인 확률값으로 변환하여 준다. 어떻게 보면 classfication에 초점을 맞춘 것으로 볼 수있다. 들어온 값에 대하여 확률적으로 어느 class인지 구분하게끔 해준다.
Loss Function
손실함수, 어떤 것에 대한 손실을 알려면 기준점이 있어야한다. loss function도 마찬가지이다. 손실을 알려면 그 data에 대한 정답 즉 label을 알아야한다. 그러므로 supervised learning에서 쓰인다.
손실함수는 현재 parameter들이 얼마나 일을 잘 수행하고 있는지 평가하는 함수이다.
손실이 작으면 작을수록 그 작은 손실을 일으킨 parameter가 최적화된 parameter라고 쉽게 예상할 수있다. 다시 말해 손실함수는 loss를 줄이는 함수인 것이다.
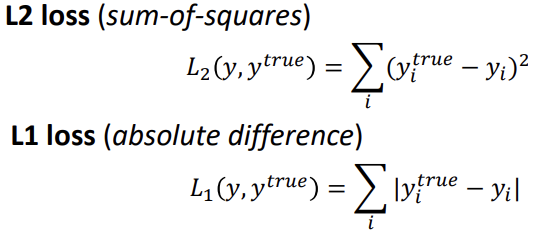
손실함수의 종류는 위와 같이 두개로 나뉘는데 시그마의 괄호나 절대값 안에 위치한 y(true)-y(i)는 예측치와 정답의 차이를 의미한다.
L2(MSE, mean square error)와 L1(MAE, mean absolute error)의 차이는 제곱을 하였느냐 절대값을 하였느냐의 차이 뿐이다.

MSE나 MAE는 숫자값으로 연산이 가능하여 regression에 적절하고

BCE나 CCE는 classification에 적절하다.
이때 BCE는 class가 2개, CCE는 class가 여러개이다.
Back-propagation
다층신경망 학습 알고리즘으로서
입력데이터의 순전파 > 오차의 역전파 > 가중치 갱신 세단계의 학습주기로 이루어진다.
이때 역전파시 loss function의 결과에 따라 역전파를 수행한다.

역전파 알고리즘은 1 epoch마다 이루어지며 epoch값이 늘어날 수록 역전파가 더 자주 일어난다.
입력데이터 = 1000
batch_size = 50
epoch = 100
이때 전체 가중치의 학습(iteration)(역전파)은 총 몇번이 일어날까?
공식은 (입력데이터/batch_size) * epoches이다.
한번의 epoch은 1000개의 data를 50개씩 학습하므로 총 20번 학습한다.
20번의 학습을 100 epoch 만큼 반복하므로 2000번의 학습이 일어난다.
입력 data에 있는 특정 data "a"가 있다고 할 때
epoch이 100번이면 data "a" 는 학습에 100번 사용되는 것이다.
