Overfitting (과적합)
model training이란 훈련 data에 model을 fit하게 만드는 학습을 의미한다.
즉 훈련 data에 대한 loss를 최소화 하는 일련의 과정들을 말한다.
하지만 훈련 data에 대한 모델의 loss가 작으면 작을수록 좋은 것일까?
정답은 그렇지 않다.
supervised learning은 data에 대한 학습이 필연적인데 학습 data에 편향된 과하게 복잡한 모델을 학습하는 것을 과적합이라고 한다. (즉 훈련 data에 대한 과한 학습)
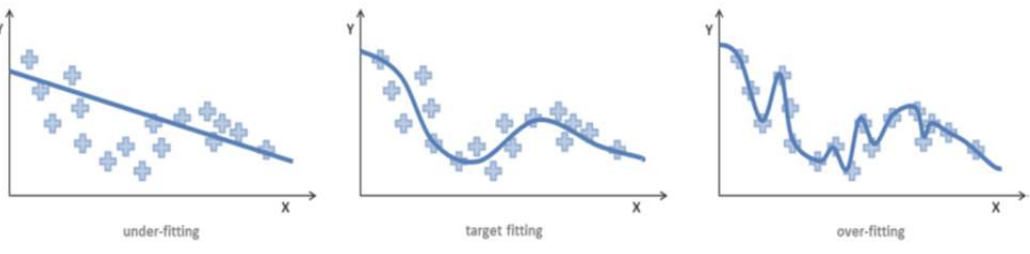
각각 under fitting, target fitting, over fitting이다.
가장 우측 모델을 보면 훈련 data에 대하여 과하게 학습되었다는 것을 효과적으로 보여준다.
분명 model training의 설계에 따라 훈련 data에 대한 loss를 충분히 줄였지만 실상은 역효과가 난다. 왜일까?
1. data에 missing,error가 포함됨
data에 noise가 껴있어 noise를 포함하여 학습을 진행한다면 깔끔한 data에 대하여 잘못된 판단을 내릴 수 있다.
2. 훈련 data가 전체 data를 대표하지 못함
간단히 말해서 경상도를 표본으로한 출구조사 결과가 전국을 대표하지는 못한다.
만약 아무리 전체를 대표하도록 표본을 뽑아도 그 표본 data에 대한 편향정도, 대표성은 그 누구도 알 수 없으므로 제자리 걸음이 될 뿐이다.
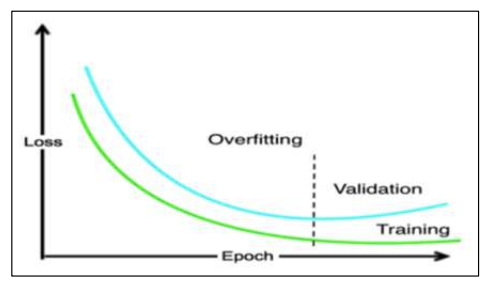
위 그림을 보면 overfitting을 직관적으로 볼 수 있다. 연녹색 그래프는 train data에 대한 loss 그래프로 epoch에 따라 점점 감소하는 것을 볼 수 있다. 즉 아까 말했듯 loss가 줄어드는 쪽으로 학습을 진행하는 것이다.
그러나 validation data에 대해서는 오하려 성능이 저하한다. 즉 일반화 능력이 떨어진다는 뜻이다.
overfitting이 일어나기 위해서는 긴 학습시간과 대용량의 학습 data가 필요하다.
과적합 문제를 위한 기술들
overfiting을 어떻게 줄일까?
Dropout
역전파시 무작위 뉴런의 갱신을 하지 않는 기술
드롭아웃은 구조 설계가 끝난 상태에서 학습능력을 향상하는(즉 과적합을 줄이는) 방법으로
일시적으로 뉴런이 없는 것처럼 취급하여 학습 진행마다 역전파시 갱신을 하지 않는다.
이러한 dropout은 batch마다 random하게 일어난다.
model = Sequntial([ #...
Dense(120, activation = 'relu'),
Dropout(0.2) # batch마다 20%의 뉴런은 일시적으로 없는 취급
])Regularization (모델 정규화)
신경망 model의 복잡도가 낮게끔 학습을 진행하는 것, 가중치의 값이 커지지 않도록 제한
모델의 복잡도는 weight의 개수로 정해진다고 볼 수 있는데 (이미 설계가 끝난 모델)
이 weight들이 작은 값을 가질 수록 모델이 간단해진다. (weight가 0이 되게끔 간소화)

그러므로 위와 같이 손실함수를 낮추는(학습의 main)동시에
모델의 복잡도를 낮추도록(sub) 학습을 진행하면 과적합이 줄어들 것이다.
data가 아닌 신경망 model에 대한 정규화

시그마 부분은 모델의 복잡도(weight들의 절대값의 합)를 나타낸 것으로 이 값들이 0에 가깝게 조절하면 모델 정규화가 일어난다.

위 예제에서는 l2정규화를 사용하였고 정규화 꼐수는 0.01로 설정하였다.
Normalization (데이터 정규화)
네트워크의 각 계층의 입력 분포가 크게 변화함으로써, 학습의 불안정성 야기
그러한 문제를 해소하기 위한 방안의 하나
머신러닝은 학습을 진행함으로서 data가 가진 feature들의 패턴을 파악하여 정답을 내놓는다.
그런데 이러한 다양한 feature들의 절대적인 값이 feature의 특성에 따라 크게 차이가 날 수도 있다는 점이다.
이를테면 머신러닝이 사람에 대한 학습을 진행한다고 하자 사람 data에 feature는 여러가지가 있지만
시력, 몸무게, 키 이 3개의 feature를 가지고 학습을 한다고 할때
인간은 각 feature에 대한 배경지식을 가지고 있다.
(즉 각 필드의 고유 속성에 대한 수치판단을 대강 할 수 있다. 물론 이러한 수치판단은 필드마다 다름)
이를테면 시력이 0.2인 사람과 2.0인 사람은 시력의 차이가 굉장히 크다는 것을 인지하고 있고 키가 173.2인 사람과 175인 사람의 키의 차이는 그다지 크지 않다는 것을 인지하고 있다.
그러나 머신러닝 알고리즘이 볼때는 두 feature data의 차이는 1.8로 동일하다.
이렇게 되면 머신러닝 알고리즘은
1. 173에 시력 2.0인 사람 <-> 키 173에 시력 0.2인 사람
2. 키 173에 시력 2.0인 사람 <-> 키 175에 시력 2.0인 사람
이 두가지 경우에 각 두 data에 거리가 비슷해져 버린다.
실제로는 1번의 경우의 data는 더 멀어져야만 한데 말이다.
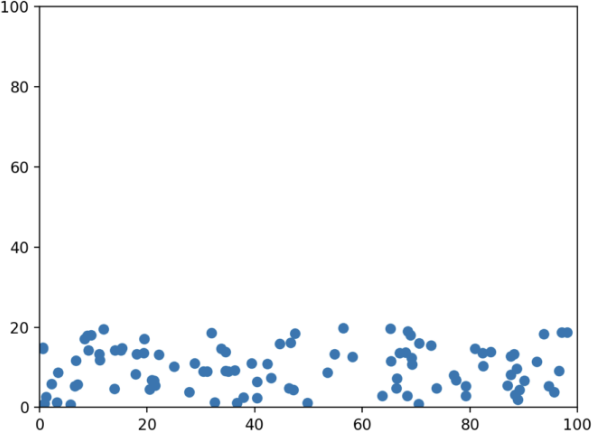
위 그래프 같은 경우에 x축이 키 y축이 시력이라고 가정하면
머신러닝 알고리즘은 y축에는 큰 영향을 받지 않고 x축 data만을 바탕으로 학습을 진행할 것이다. 이러한 그래프를
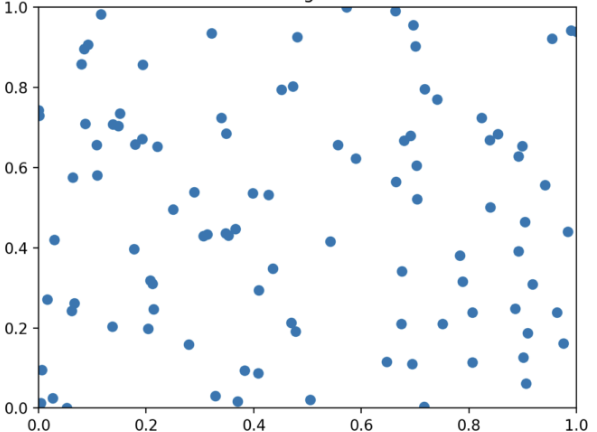
이처럼 평균과 분산을 이용해 0과 1사이 값으로 정규화를 진행하여 안정화(data가 너무 크거나 작지 않게) 시켜 학습을 진행하면 우리가 기대하는 학습이 진행될 것이다.
Batch Normalization(배치 정규화)
mini-batch 단위로 각 특징값의 평균과 분산을 구해 정규화 한 후 scale factor, shift factor를 이용하여 새로운 값으로 변환
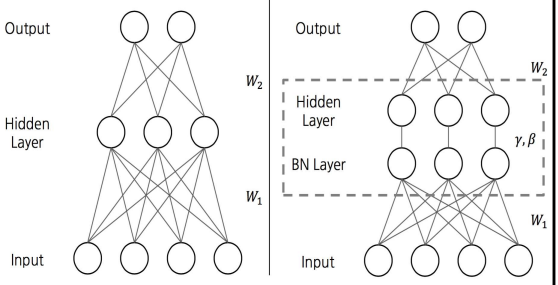
왼쪽은 BN-layer가 없어 data를 그대로 받지만
오른쪽은 BN-layer에서 특정 feature에 대한 정규화를 진행하여 data를 hidden layer에 넘겨준다.
(input으로 넣기 전, output을 한 직후 data를 다듬어 준다.)
Layer Normalization(계층 정규화)
하나의 계층에 동시에 입력되는 서로 다른 feature(특징값)들의 평균과 분산을 구해 각 feature값을 정규화
배치 정규화에서는 서로다른 feature 값에 스케일 차이를 알고리즘이 이해하기 쉽게끔 정규화 했다면
계층 정규화에서는 한 data안에서 정규화를 진행하여 하나의 data의 각 feature가 0과 1 사이의 분포를 지니도록 정규화 했다고 볼 수 있다. 이때 정규화시 평균 분산은 하나의 data의 각각의 feature 값을 바탕으로 한다.
Batch Normalization vs Layer Normalization
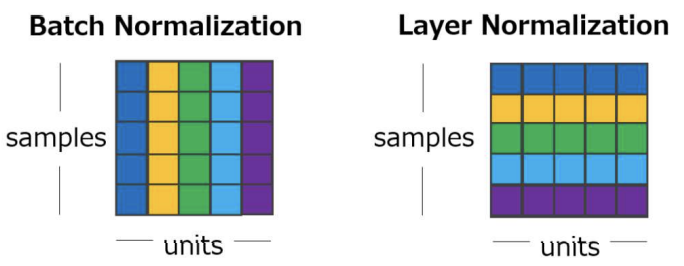
위 그림에서 samples는 batch-size를 나타내고 units는 data의 feature를 나타낸다.
즉 가로줄은 data 단위로 자른 선, 세로줄은 feature 단위로 자른 선이다.
이때 동일한 색으로 칠해진 값끼리 정규화를 진행하는 것이다.
Hyperparameter tuning
parameter = 머신러닝이 학습해야하는 값 (weights + bias)
hyperparameter = 설계자가 정해줘야하는 값
- Number of hidden neurons(은닉 뉴런 수)
- batch size(배치 크기)
- number of epochs(학습 반복 횟수) 등등
optimizer (최적화기)
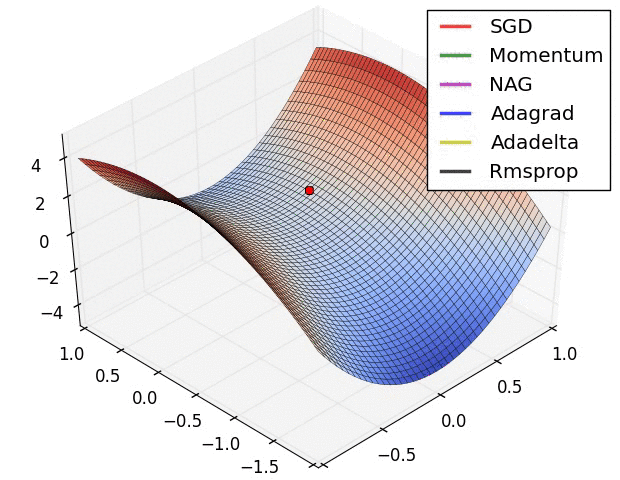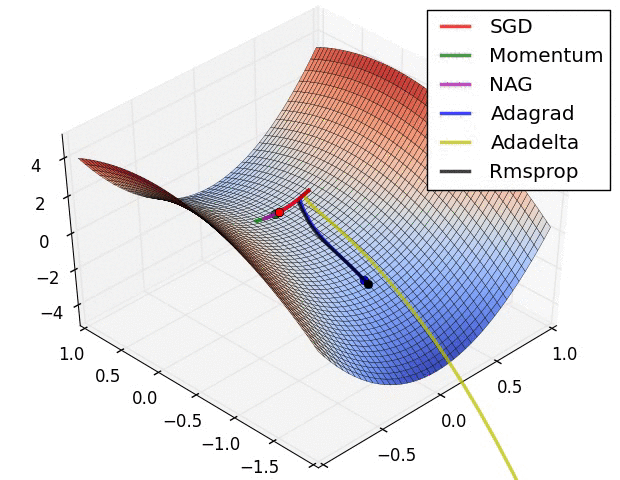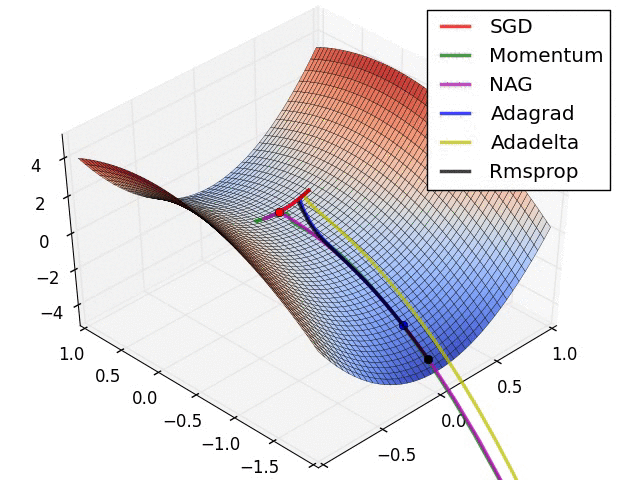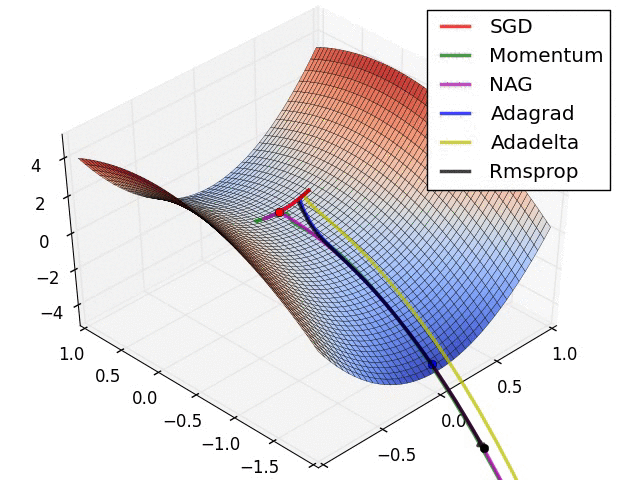
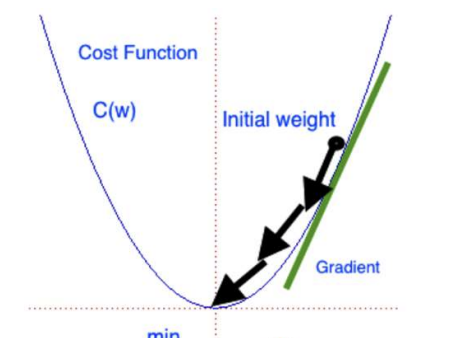
최적화란 아래와 같은 loss function에 대한 그래프가 있다고 할 때 loss를 최소화 하는 모델의 인자를 찾는 것
최적화기는 이러한 최적화를 진행하는 다양한 방법들을 의미한다.
Learning Rate (학습율)
걸음의 보폭으로 이해하면 쉽다. 보폭이 크다면 loss 최소화 지점을 빠르게 찾아가는 대신 수렴하기 어렵고
보폭이 작다면 loss 최소화 지점을 느리게 찾아가는 대신 섬세하게 찾아가 수렴이 쉽다.
그래서 보통 학습율을 초기엔 크게 갈수록 작게 가변적으로 지정하여 둘의 장점을 모두 가질 수 있다.
local minimum 문제
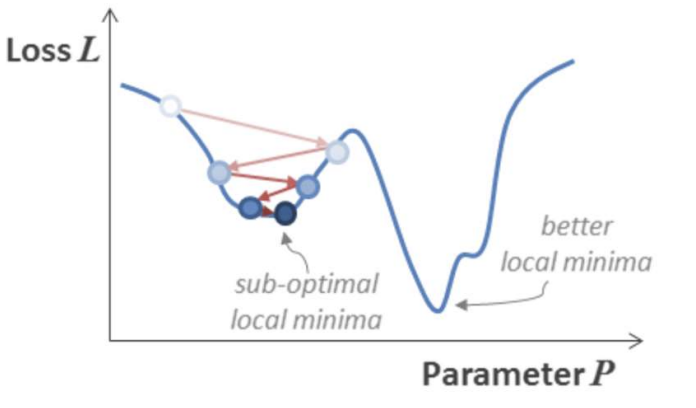
위 그래프에서 보면 loss가 낮은 쪽으로만 이동하여 나름의 최적화 지점을 찾았지만 이는 local minumum으로 gloabal minimum에 도달하지 못하는 경우가 생긴 걸 볼 수 있다. 이런 global minimum에 도달하기 위해서는 bad move 즉 기울기를 거스르는 move를 허용해야할 것이다.
optimizer의 종류
Gradient Descent (경사하강)
gradient의 반대방향으로 parameter 업데이트
SGD
GD에서 임의의 하나의 data의 대해 기울기를 계산하여 parameter 업데이트
Momentun
경사하강(GD)에 일종의 관성을 추가
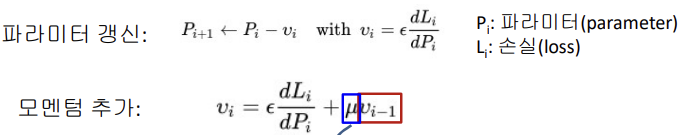
모멘텀 추가 부분에서 이전단계 vi값에 의해 관성계수에 따라 관성을 추가하여 적용

즉 가파를 수록 더욱 파라미터가 많이 갱신된다.
Ada Optimizer
Adaptive learning rate(적응적 학습률)
- 각 뉴런의 민감도와 활성 빈도에 따라 각 파라미터의 갱신을 위한 학습율을 적응적으로 다르게 조절
- 즉 학습율을 늘이기도 줄이기도 함
Adam (Adaptive Moment estimation)
적응적 학습율 + 모멘텀
최적화기끼리의 관계 (발전과정)

