
메모리 동적할당
우리가 프로그램을 만들어보면서 이러한 문제에 봉착한 적이 있을 것이다.
배열의 크기를 자유 자재로 다룰 수 있으면 얼마나 좋을까?
맞다. 우리는 지금까지 배열을 정의할 때 배열의 크기를 컴파일 시간에 확정해야 했다. 즉, 컴파일러가 배열의 크기를 추측할 필요 없이 명확하게 나타나 있어야 했다. 이는 참으로 고역스러운 일이 아닐 수 없었다. 예를 들어 우리가 컴퓨터로 학생들의 수학 점수를 입력 받아 평균을 내는 프로그램을 만든다고 생각해보자. 반마다 학생의 수가 다르기 때문에 우리는 배열의 크기를 명확하게 정할 수 없다. 따라서 배열의 크기를 '충분히 크게' 잡게 되는게 그러면 메모리가 낭비가 된다.
컴퓨터에서 낭비가 된다는 말은 비효율적인 프로그램이라고 말할 수 밖에 없다. 이렇게 쓸데 없는 낭비되는 자원을 막기 위해서 '학생의 수'를 입력 받고 학생의 수 만큼 배열의 크기를 지정하면 얼마나 좋을까? 하지만 놀랍게 그렇게 할 수 있는 방법이 있다.
바로 동적 메모리 할당 이라는 방법이다. 말 그대로 메모리를 '동적'으로 할당한다는 말이다. 동적이라는 말은 딱 정해진 것이 아니라 가변적으로 변할 수 있다는 말이다. 또한 메모리를 '할당'한다는 말은 우리가 배열을 정의하면 배열에 맞는 메모리 상의 특정한 공간에서 배열이 나타내는 것 처럼 메모리의 특정한 부분을 사용할 수 있게 된다. 참고로 할당 되지 않는 메모리는 절대로 사용할 수 없다.
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char **argv) {
int SizeOfArray;
int *arr;
printf("만들고 싶은 배열의 원소의 수 : ");
scanf("%d", &SizeOfArray);
arr = (int *)malloc(sizeof(int) * SizeOfArray);
// int arr[SizeOfArray] 와 동일한 작업을 한 크기의 배열 생성
free(arr);
return 0;
}실행 결과
만들고 싶은 배열의 원소의 수 : 5일단 위 예제부터 살펴보자.
printf("만들고 싶은 배열의 원소의 수 : ");
scanf("%d", &SizeOfArray);먼저 위 과정을 통해서 우리가 원하는 int 배열의 원소의 개수를 입력 받았다. 그리고
arr = (int *)malloc(sizeof(int) * SizeOfArray);바로 이녀석이 우리가 원하는 일을 해주는 녀석이다. 이 함수의 이름은 malloc 이며 memory allocation 의 약자이다.
이 함수는 <stdlib.h> 에 정의 되어 있기 때문에 #include <stdlib.h> 를 추가 해야 한다.
이 함수는 인자로 전달될 크기의 바이트 수 만큼 메모리 공간을 만든다. 즉, 메모리 공간을 할당하게 되는 것이다. 우리가 원소의 개수가 SizeOfArray 인 int 형 배열을 만들기 위해서는 당연히 (int의 크기) * (SizeOfArray) 가 될 것 이다. 이 때, int 타입의 크기를 정확하게 알기 위해서 sizeof 키워드를 사용한다. sizeof 는 이 타입의 크기를 알려준다. 따라서 sizeof(int) * SizeOfArray 를 인자로 전달해주면 된다.
이 함수가 리턴하는 것은 자신이 할당한 메모리의 시작 주소를 리턴한다. 이 때, 리턴형이 (void *) 형 이므로 우리는 이를 (int *) 형으로 형변환을 하여 arr 에 넣어주면 된다. 이렇게 보면 malloc 함수는 공원에서 돗자리를 까는 역할을 하는 것 같다. 사람이 바글바글한 공원에서 malloc 함수는 '우리가 원하는 크기의 돗자리'를 깔아주고 이 돗자리로 사람들이 올 수 있게 손을 흔들어주는 역할을 하는 것 같다.
free , 메모리 누수
따라서 arr 에는 malloc 이 할당해준 메모리를 사용할 수 있게 된다. 즉, arr[SizeOfArray] 만큼 사용할 수 있는 것이다.
free(arr);그리고 마지막에 free 는 우리가 다 쓰고 남은 할당된 메모리 공간을 다시 컴퓨터에게 돌려주는 역할을 하게 된다. 이를 해제(free) 한다고 하는데 이 free 를 제대로 하지 않는다면 딱히 사용하지도 않는 메모리를 쓸데 없이 자리만 차지하게 된다.
이렇게 free 를 제대로 하지 않아 발생하는 문제를 메모리 누수(memory leak) 라 한다. 이는 마치 공원에 돗자리를 깔아놓고 그대로 집에 가는 것과 똑같은 일이다. (이러한 일이 계속 반복 된다면 나중에 다시 공원에 왔을 때 공원에 돗자리를 깔 공간이 하나도 없을 것이다.)
malloc 은 어디에 할당할까?
우리는 이전에 메모리 구조에 대해서 배울 때 메모리에는 다음과 같은 구조들이 있다고 하였다.
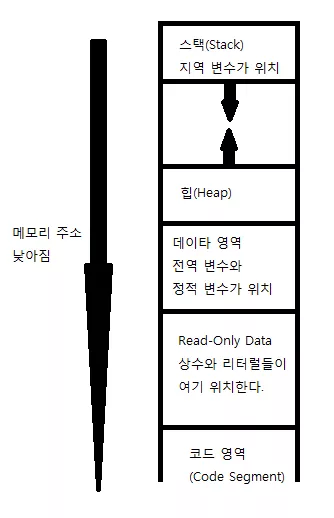
이 때 힙(heap) 부분은 나중에 다룬다고 하였는데 지금 알아보자.
스택이나, 데이터 영역, Read Only Data 부분은 당연하게도 malloc 함수가 결코 건드릴 수 없는 부분이다. 이 부분은 반드시 컴파일 때 100% 추호의 의심의 여지도 없이 정해져야 한다.
하지만 힙은 경우는 다르다. 메모리의 힙 부분은 사용자가 자유롭게 할당하거나 해제할 수 있다. 따라서 malloc 함수도 이 힙을 이용한다. 우리가 만들어낸 arr 또한 힙에 위치하게 된다.
힙의 할당과 해제가 자유로운 만큼 제대로 사용해야 한다. 만일 힙에 할당하였는데 해제를 하지 않았다면 공간이 낭비 될 것이다. 다른 메모리 부분의 경우는 컴퓨터가 알아서 처리하기 때문에 문제가 발생할 여지가 적지만 힙은 인간이 다루는 만큼 철저히 해야 한다.
예제 1
다음은 동적 할당을 활용한 예제이다.
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char **argv) {
int student; // 입력 받고자 하는 학생 수
int i, input;
int *score; // 학생 들의 수학점수 변수
int sum = 0; // 총점
printf("학생의 수는? : ");
scanf("%d", &student);
score = (int *)malloc(student * sizeof(int));
for (i = 0; i < student; i++) {
printf("학생 %d 의 점수 : ", i);
scanf("%d", &input);
score[i] = input;
}
for (i = 0; i < student; i++) {
sum += score[i];
}
printf("전체 학생 평균 점수 : %d \n", sum / student);
free(score);
return 0;
}실행 결과
학생의 수는? : 3
학생 0 의 점수 : 100
학생 1 의 점수 : 90
학생 2 의 점수 : 95
전체 학생 평균 점수 : 95score = (int *)malloc(student * sizeof(int));위 과정을 통해서 우리는 배열의 개수가 student 인 int 형 배열을 만들었다. 따라서 score 를 마치 int arr[student] 를 한 것 마냥 사용할 수 있게 된다.
2 차원 배열의 동적 할당
그렇다면 좀 더 높은 난이도의 문제를 도전해보자. 2 차원 배열을 동적으로 할당할 수 있을까? 물론 가능하다. 2 차원 배열을 동적 할당 하는 방법으로는 크게 두 가지 방법을 생각할 수 있다.
- 포인터 배열을 사용하여 2 차원 배열 처럼 동작하는 배열 만들기
- 실제로 2 차원 배열 크기의 메모리를 할당한 뒤 2 차원 배열 포인터로 참조하는 방법
먼저 전자의 방법을 이용해보자.
포인터 배열을 이용하여 2 차원 배열 할당하기
포인터 배열은 이전에 말했듯이 각각의 원소들이 모두 포인터인 배열이다. 따라서, 각각의 원소들이 다른 일차원 배열들을 가리킬 수 있다. 따라서 우리가 해야할 일은 먼저 포인터 배열을 동적으로 할당한 뒤에 다시 포인터 배열의 각각의 원소들이 가리키는 일차원 배열을 다시 동적으로 할당해주면 마치 2 차원 배열을 만든 것 같은 효과를 낼 수 있다.
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char **argv) {
int i;
int x, y;
int **arr; // 우리는 arr[x][y] 를 만들 것이다.
printf("arr[x][y] 를 만들 것입니다.\n");
scanf("%d %d", &x, &y);
arr = (int **)malloc(sizeof(int *) * x);
// int* 형의 원소를 x 개 가지는 1 차원 배열 생성
for (i = 0; i < x; i++) {
arr[i] = (int *)malloc(sizeof(int) * y);
}
printf("생성 완료! \n");
for (i = 0; i < x; i++) {
free(arr[i]);
}
free(arr);
return 0;
}실행 결과
arr[x][y] 를 만들 것입니다.
3
5
생성 완료!잘 실행된 것 같은데 한 번 하나씩 살펴보자.
int **arr; // 우리는 arr[x][y] 를 만들 것이다.일단 이 부분을 보자. 우리가 만약에 int arr[3]; 을 이란 배열을 만들었다면 arr 는 무슨 형일까? 바로 int * 이다. 그렇다면 int *arr[3]; 이라는 배열을 만들었다면 arr 는 무슨 형일까? 바로 int ** 이다. 따라서 우리는 int **arr 라고 선언한 것이다.
arr = (int **)malloc(sizeof(int *) * x);따라서 위와 같이 int * 형 배열을 동적 할당 할 수 있다. 위 과정을 거치면 arr 는 다음과 같을 것이다.
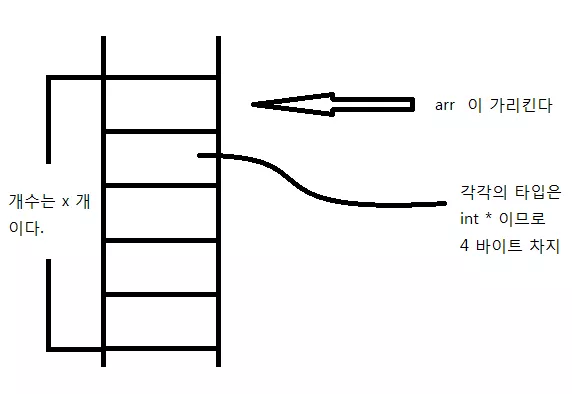
그러면 배열의 각각의 원소는 int * 형 이므로 다른 int 형 배열을 가리키기를 갈망하고 있을 것이다. 그러면 우리가 그 욕구를 해결주자. 각각의 원소들에 대해 원하는 메모리 공간을 짝 지어 주자.
for (i = 0; i < x; i++) {
arr[i] = (int *)malloc(sizeof(int) * y);
}각각의 원소들에 대해 메모리 공간을 할당해주었다. arr[i] 는 malloc 이 정의한 또 다른 공간을 가리킬 것이다.
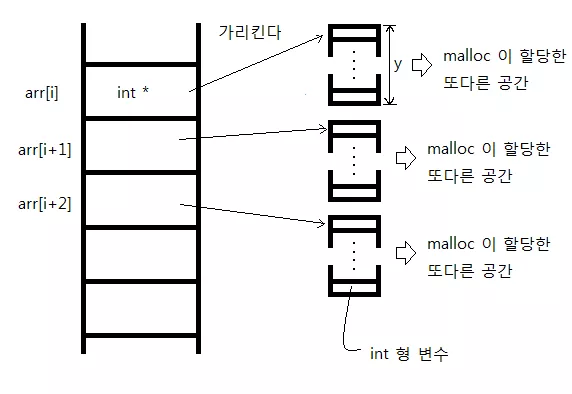
따라서 arr 의 하나의 원소가 크기가 y 인 배열을 가리키고 있다. 그런데 arr 의 원소가 x 개 이므로 전체적으로 x * y 배열을 가진 셈이다. 하지만 이렇게 만들어진 배열은 정확하게 말하자면 2 차원 배열이라고 말하기 어렵다. 왜냐하면 2 차원 배열은 메모리에서 연속적으로 있어야 하기 때문이다. 예를 들자면

와 같이 말이다. 하지만 우리가 만든 배열은 메모리에서 연속으로 존재한다고 보장할 수 없다. 또한 한가지 재미있는 점은 우리가 만든 '2 차원 배열 처럼 생긴' 포인터 배열은 2 차원 배열과 달리 함수의 인자로 쉽게 넘겨줄 수 있다. 예를 들면
int array(int **array);이렇게 말이다. 이러면 array(arr); 를 하게 되면 우리가 만든 배열을 함수에 넘길 수 있게 된다. 이게 가능한 이유는 사실 우리가 만든 배열은 1 차원 배열들이지 2차원 배열이 아니기 때문이다. arr 는 단순히 int * 형 원소들을 가지는 1 차원 배열이다. 1 차원 배열을 함수의 인자로 넘겨줄 때는 배열의 크기를 써주지 않아도 된다. 사실 main 함수의 인자로 전달되는 argv 역시 이와 같은 성격을 띈다.
그렇다고 해서 2차원 배열의 성질을 잃어버리는 것은 아니다. 이 배열도 2차원 배열처럼 arr[3][4] 과 같이 원소에 접근할 수 있다(그렇기 때문에 2차원 배열이라고 부르는 것이다). 왜냐하면 arr[3][4] 는 *(*(arr+3)+4) 로 해석 되는데 *(arr+3) 를 통해 arr 의 네번째 원소에 접근하게 되고 *(arr+3) 는 자신이 가리키는 int 형 배열의 주소값을 의미하므로 +4 를 해주면 int 형 배열의 5 번째 원소에 접근하는 것 같다.
아무튼 이렇게 2 차원 배열을 생성하였다(물론 정확히는 2차원 배열이 아니지만) 우리가 이 배열을 힙에 할당했으면 사용이 끝나면 역시 돌려줘야 한다. 해제하는 순서는 할당하는 순서와 반대로 하면 된다. arr[i] 들이 가리키고 있던 int 형 배열들을 해제 해준 다음에 arr 를 해제해주면 된다. 만일 arr 를 먼저 해제해주면 arr[i] 들이 메모리상에서 사라지므로 arr[i] 들이 가리키고 있던 int 형 배열들을 해제할 수 없게 되므로 오류가 발생 한다.
예제
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char **argv) {
int i, j, input, sum = 0;
int subject, students;
int **arr;
// 우리는 arr[subject][students] 배열을 만들 것이다.
printf("과목 수 : ");
scanf("%d", &subject);
printf("학생의 수 : ");
scanf("%d", &students);
arr = (int **)malloc(sizeof(int *) * subject);
for (i = 0; i < subject; i++) {
arr[i] = (int *)malloc(sizeof(int) * students);
}
for (i = 0; i < subject; i++) {
printf("과목 %d 점수 --------- \n", i);
for (j = 0; j < students; j++) {
printf("학생 %d 점수 입력 : ", j);
scanf("%d", &input);
arr[i][j] = input;
}
}
for (i = 0; i < subject; i++) {
sum = 0;
for (j = 0; j < students; j++) {
sum += arr[i][j];
}
printf("과목 %d 평균 점수 : %d \n", i, sum / students);
}
for (i = 0; i < subject; i++) {
free(arr[i]);
}
free(arr);
return 0;
}실행 결과
과목 수 : 3
학생의 수 : 2
과목 0 점수 ---------
학생 0 점수 입력 : 90
학생 1 점수 입력 : 100
과목 1 점수 ---------
학생 0 점수 입력 : 80
학생 1 점수 입력 : 70
과목 2 점수 ---------
학생 0 점수 입력 : 60
학생 1 점수 입력 : 100
과목 0 평균 점수 : 95
과목 1 평균 점수 : 75
과목 2 평균 점수 : 80이렇게 잘 나온다.
위 예제에서 우리는 2 차원 배열을 사용하였다. 즉, arr[sbject][students] 를 만든 것이다. 이를 위해
arr = (int **)malloc(sizeof(int *) * subject);
for (i = 0; i < subject; i++) {
arr[i] = (int *)malloc(sizeof(int) * students);
}를 사용하였다. arr 는 엄연히 말하자면 2 차원 배열은 아니지만 2 차원 배열과 똑같이 행동하므로 arr[i][j] 와 같은 문장을 사용할 수 있다.
이를 이용하여 각각 값을 대입하였고 평균을 내는 함수를 만들어서 평균도 출력하였다.
그리고 마지막으로 할당 받은 메모리의 사용이 끝났기 때문에 for 을 이용하여 해제를 하였다.
진짜 2차원 배열
주의 사항
애석하게도 이 방법은 비주얼 스튜디오에서는 작동하지 않습니다. 비주얼 스튜디오의 C 컴파일러가 VLA 를 지원하지 않기 때문입니다. 하지만 GCC 나 Clang 같은 컴파일러에서는 사용 가능한 방법입니다. 참고로 VLA 는 C99 에 표준으로 들어갔습니다만, 비주얼 스튜디오의 C 컴파일러는 C90 을 사용하고 있습니다.
앞서 사용했었던 방법으로는 진짜 2 차원 배열처럼 메모리상에 쭈르륵 존재하는 배열을 만들 수 없었다. 왜냐하면 1 차원 배열이 쭈르륵 할당 되면서 메모리상에 여기저기 퍼져서 만들어질 것이기 때문이다.
따라서 메모리상에서 연속적으로 존재하는 진짜 2 차원 배열을 만들기 위해서는 반드시 malloc 을 통해서 해당 크기의 공간을 확보해야 한다. 예를 들어서
int arr[height][width];와 같은 배열을 할당하고자 하면 메모리의 크기는
height* width * sizeof(int)가 될 것이다. 이렇게 메모리가 할당 되었다면 이제 해당 메모리를 2 차원 배열 처럼 생각해라! 라고 컴파일러에게 알려줘야 한다. 이 경우 메모리 주소값을 2 차원 배열을 가리키는 포인터로 전달해주면 된다.
이전에 2 차원 배열을 만들 때 배웠듯이 2 차원 배열 포인터의 경우 포인터 연산을 처리하기 위해선 반드시 포인터 타입 안에 행 길이 가 들어가야 한다고 했다. 따라서 아래와 같이 2 차원 배열 포인터 arr 를 정의할 수 있다.
int (*arr)[width] = (int (*)[width])malloc(height * width * sizeof(int));이제 컴파일러는" **arr 가 행의 크기가 width 인 2 차원 배열을 가리키는구나!"** 라고 생각하게 된다. 한 가지 주의해야할 점은 arr 를 정의할 때 반드시 width 에 실제 배열의 넓이 값이 들어간 후에 정의해야 한다.
int width;
int (*arr)[width] = (int (*)[width])malloc(height * width * sizeof(int));
scanf("%d", &width);예를 들어서 위와 같이 arr 가 제대로 2 차원 배열을 참고할 수 없다. 따라서 아래와 같이 해줘야 한다.
int width;
scanf("%d", &width);
int (*arr)[width] = (int (*)[width])malloc(height * width * sizeof(int));주의 사항
arr 을 정의할 때 반드시 width 에 실제 배열의 넓이 값이 들어간 후에 정의합시다.
예제
#include <stdio.h>
#include <stdlib.h>
int main() {
int width, height;
printf("배열 행 크기 : ");
scanf("%d", &width);
printf("배열 열 크기 : ");
scanf("%d", &height);
int(*arr)[width] = (int(*)[width])malloc(height * width * sizeof(int));
for (int i = 0; i < height; i++) {
for (int j = 0; j < width; j++) {
int data;
scanf("%d", &data);
arr[i][j] = data;
}
}
for (int i = 0; i < height; i++) {
for (int j = 0; j < width; j++) {
printf("%d ", arr[i][j]);
}
printf("\n");
}
free(arr);
}실행 결과
배열 행 크기 : 3
배열 열 크기 : 2
1 2 3 4 5 6
1 2 3
4 5 6와 같이 잘 나온다.
arr 의 모든 데이터가 메모리상에서 연속적으로 존재하므로 free 도 arr 에 대해서 한 번만 해주면 된다.
한 가지 주의해야할 점은 위 배열 포인터를 함수의 인자로 전달할 때 이다.
예를 들어서 2 차원 배열의 모든 원소를 출력하는 함수를 만든다고 생각해보자. 그렇다면 아래와 같이 함수를 만들 수 있을 것이다.
void print_array(int (*arr)[width], int width, int height) {
for (int i = 0; i < height; i++) {
for (int j = 0; j < width; j++) {
printf("%d ", arr[i][j]);
}
printf("\n");
}
}그런데 문제가 있다. 컴파일러가 int (*arr)[width] 를 보고 width 가 무엇인지 알 수 없다는 것이다. 실제로 컴파일시에 다음과 같은 컴파일 오류가 발생한다.
컴파일 오류
test.c:12:29: error: ‘width’ undeclared here (not in a function)
12 | void print_array(int (*arr)[width], int width, int height) {해결책은 간단하다. 컴파일러가 arr 의 정의를 볼 때 width 의 정체를 알아볼 수 있게, width 의 정의가 arr 의 정의 앞에 오도록 자리를 바꾸면 된다. 아래와 같이 말이다.
void print_array(int width, int (*arr)[width], int height) {
for (int i = 0; i < height; i++) {
for (int j = 0; j < width; j++) {
printf("%d ", arr[i][j]);
}
printf("\n");
}
}그러면 컴파일시 잘 작동하는 것을 볼 수 있다.
그래서 어떤 방법을 사용해야할까?
되도록 메모리상에서 연속된 공간에 2 차원 배열을 할당하는 후자의 방법을 사용하는 것이 좋다. 이유는 다음과 같다.
malloc은 상당히 느린 함수중 하나이다. 따라서malloc의 호출 횟수는 최소한으로 하는게 좋다. 따라서 배열의 높이 만큼malloc을 호출해야하는 전자의 방법은height가 커질수록 상당히 느려진다.- 전자의 방법은 메모리공간에 접근하기 위해서 두 단계의 메모리 접근이 필요하다. 예를 들어서
arr[2][3]을 하는 경우 먼저arr[2]를 읽은 뒤에 해당 공간에서 다시[3]연산을 해야한다. 후자의 경우 컴파일러가 다이렉트로 메모리arr[2][3]에 접근할 수 있다. - 메모리가 연속적으로 있을 경우 접근이 더 빠르다.
구조체 동적 할당
#include <stdio.h>
#include <stdlib.h>
struct Something {
int a, b;
};
int main() {
struct Something *arr;
int size, i;
printf("원하시는 구조체 배열의 크기 : ");
scanf("%d", &size);
arr = (struct Something *)malloc(sizeof(struct Something) * size);
for (i = 0; i < size; i++) {
printf("arr[%d].a : ", i);
scanf("%d", &arr[i].a);
printf("arr[%d].b : ", i);
scanf("%d", &arr[i].b);
}
for (i = 0; i < size; i++) {
printf("arr[%d].a : %d , arr[%d].b : %d \n", i, arr[i].a, i, arr[i].b);
}
free(arr);
return 0;
}실행 결과
원하시는 구조체 배열의 크기 : 2
arr[0].a : 1
arr[0].b : 2
arr[1].a : 3
arr[1].b : 4
arr[0].a : 1 , arr[0].b : 2
arr[1].a : 3 , arr[1].b : 4이번에는 구조체를 사용해보았다. 구조체에 대해서는 앞서 얘기 했듯이 전혀 특별하게 생각할 필요가 없다. 그냥 '하나의 타입' 으로 생각하면 된다. int 처럼 사용할 수 있다는 말이다. 따라서 malloc 으로 지지고 볶아도 전혀 이상할 일이 아니다.
struct Something *arr;일단 1 차원 구조체 배열을 가리키기 위해서 arr 를 선언하였다. int 형 배열을 만들기 위해서 int *arr 를 했던 것과 정확히 일치한다.
arr = (struct Something *)malloc(sizeof(struct Something) * size);그리고 malloc 함수를 이용하여 arr 공간을 할당해준다. 이에 필요한 크기는 sizeof(struct Something) * size 인데 여기서 sizeof 대신 구조체 크기를 실제로 계산해서 넣는 사람도 있는게 이는 오류를 발생시킬 수 있다. 예를 들어서 위 Somehting 구조체의 경우 1 개당 8 바이트를 차지한다고 볼 수 있는데 사실 그렇지 않을 수 도 있다.
물론 위 경우는 조금 특별하지만 예를 들어 구조체의 크기가 10 바이트일 경우 컴퓨터가 더블워드 경계(double word boundary) 에 놓음으로 속도를 향상시키는 경우가 있는데 이 경우 구조체의 크기는 12 바이트로 간주될 수 있다. 사실 자세한 내용은 여기서 생략하기로 하고 아무튼 기억해야 할 점은 언제나 sizeof 를 사용해야 한다는 점이다. 따라서 무턱대고 구조체의 크기를 추정하면 안된다.
for (i = 0; i < size; i++) {
printf("arr[%d].a : ", i);
scanf("%d", &arr[i].a);
printf("arr[%d].b : ", i);
scanf("%d", &arr[i].b);
}위와 같이 for 문을 열심히 돌려 입력을 받으면 된다.
free(arr);그리고 마지막으로 위와 같이 free 로 깔끔하게 메모리를 정리해주는 것 또한 까먹으면 안된다.
노드
우리는 지금까지 여러가지 자료형에 대해서 배웠다. 변수를 무식하게 나열하는 것을 막기 위해서 배열을 배웠고 배열의 한계점을 느껴 구조체를 배웠다. 또한 구조체 한 개, 한 개를 다루는데 한계를 느껴 구조체 배열을 이용하였고 결국 배열로 다시 돌아왔다. 동적할당을 함으로써 사용자가 원하는 만큼의 크기의 입력을 다룰 수 있게 되었다. 하지만 아직 문제점을 느끼고 있다. 만일 사용자가 마음이 변해서 한 개를 더 입력받고 싶다면 어떨까? 새롭게 동적할당을 하면 되지만 예컨대 1000000000개의 데이터가 있는데 1 개의 추가적인 데이터를 위해서 1000000001개를 위한 공간을 새롭게 잡으면 너무 아깝다.
이를 해결하기 위한 것이 '노드' 이다.
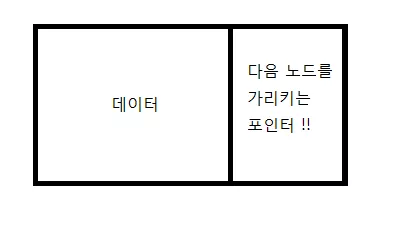
아무튼 이렇게 생겼다. 이를 코드로 나타내면 다음과 같다.
struct Node {
int data; /* 데이터 */
struct Node* nextNode; /* 다음 노드를 가리키는 부분 */
};이렇게 생긴 노드는 어떻게 사용할까?
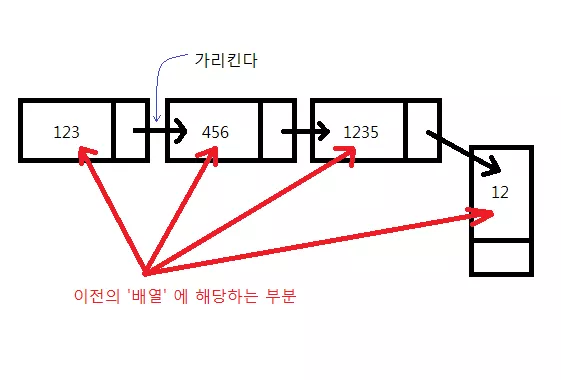
위와 같이 사용한다, 첫 번째 노드는 다음 노드를 가리키고 다음 노드는 그 다음 노드를 가리키고 마지막 노드는 아무것도 가리키지 않는다. 또한 각각의 노드는 데이터를 하나 씩 가지고 있다. 다시말해서 나중에 데이터 한 개를 더 추가하려면 마지막 노드에서 새 노드를 만들어 이어주기만 하면 된다.
뿐만 아니라 기존의 배열에서는 거의 불가능 했던 작업인 '배열 중간에 새 원소 집어 넣기' 가 가능하다. 다시 말해 기존에 노드 사이에 새로운 노드를 끼워 넣을 수 있다.
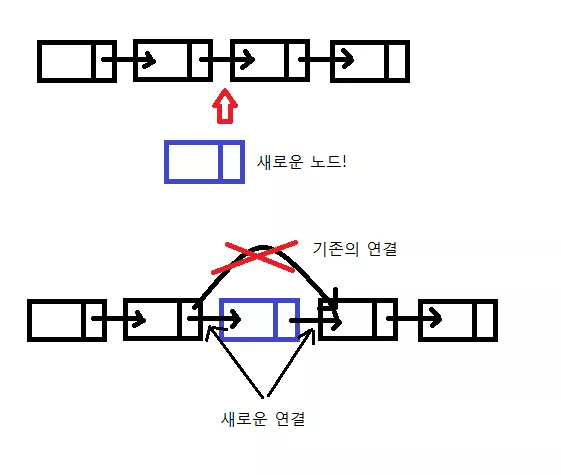
위와 같이 기존에 있었던 연결을 끊어주고 그 사이에 새롭게 연결해주면 된다. 이러한 사실을 바탕으로 노드를 만들어보자. 가장 먼저 새로운 노드를 만들기 위해 데이터와 이 노드가 가리키는 다음 노드가 필요한데 이 함수는 단순히 첫번째 노드를 만드는 역할을 한다고 하고 nextNode 를 NULL 로 주자.
/* 새 노드를 만드는 함수 */
struct Node* CreateNode(int data) {
struct Node* newNode = (struct Node*)malloc(sizeof(struct Node));
newNode->data = data;
newNode->nextNode = NULL;
return newNode;
}따라서 CreateNode 함수를 다음과 같이 만들 수 있다. 일단 malloc 을 통해 노드를 메모리를 할당한 다음에 이 노드는 newNode 가 가리키게 하였고 이제, newNode->data 에 data 를 집어 넣고 이 노드가 가리키는 다음 노드를 NULL 로 주면 된다.
사실 이 함수는 노드를 생성만 할 뿐 노드를 어떻게 관계짓지는 못한다. 따라서 어떠한 노드 뒤에 새로운 노드를 생성하는 함수를 만들어야 한다. 이 함수를 InsertNode 라고 하자. 따라서 어떠한 노드 뒤에 올지 '앞에 있는 노드' 에 관한 정보와 '새로운 노드를 위한 데이터' 가 필요하다. struct Node *cureent, int data 를 인자로 가져야 한다.
/* current 라는 노드 뒤에 노드를 새로 만들어 넣는 함수 */
struct Node* InsertNode(struct Node* current, int data) {
/* current 노드가 가리키고 있던 다음 노드가 after 이다 */
struct Node* after = current->nextNode;
/* 새로운 노드를 생성한다 */
struct Node* newNode = (struct Node*)malloc(sizeof(struct Node));
/* 새 노드에 값을 넣어준다. */
newNode->data = data;
newNode->nextNode = after;
/* current 는 이제 newNode 를 가리키게 된다 */
current->nextNode = newNode;
return newNode;
}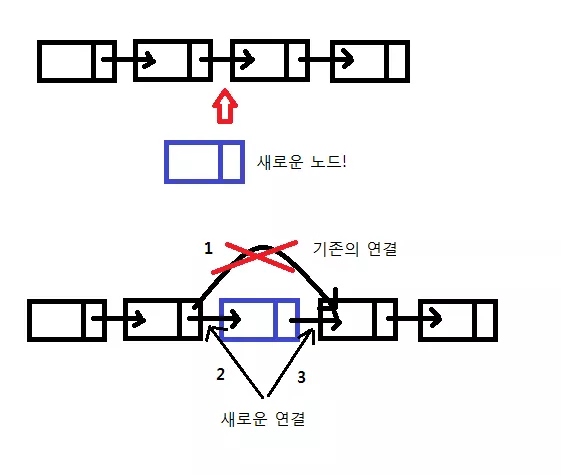
위 함수는 이 그림을 보면서 생각해보자.
/* 새로운 노드를 생성한다 */
struct Node* newNode = (struct Node*)malloc(sizeof(struct Node));일단 새로운 노드 newNode 를 만들고 메모리상에 할당해주었다.
/* 새 노드에 값을 넣어준다. */
newNode->data = data;
newNode->nextNode = after;그리고 newNode 에 nextNode 를 넣어주었다.
/* current 는 이제 newNode 를 가리키게 된다 */
current->nextNode = newNode;그리고 current 노드 뒤에 after 이 아니라 newNode 가 들어 왔으니 위와 같이 바꿔줘야 한다.
이렇게 노드를 잘 만들어주었다면 이제는 노드를 파괴하는 함수를 만들어보자. 이러한 함수를 만들기 위해선 우리가 삭제할 노드를 가리키고 있는 이전 노드를 찾아야 한다. 이러한 노드를 찾기 위해선 맨 처음 노드부터 뒤져나가야 하는데 맨 처음 노드를 헤드라고 하며 우리의 DestoryNode 함수는 헤드를 인자로 받아야 한다. 물론 파괴 하고자 하는 노드도 인자로 받아야 한다.
/* 선택된 노드를 파괴하는 함수 */
void DestroyNode(struct Node *destroy, struct Node *head) {
/* 다음 노드를 가리킬 포인터*/
struct Node *next = head;
/* head 를 파괴하려 한다면 */
if (destroy == head) {
free(destroy);
return;
}
/* 만일 next 가 NULL 이면 종료 */
while (next) {
/* 만일 next 다음 노드가 destroy 라면 next 가 destory 앞 노드*/
if (next->nextNode == destroy) {
/* 따라서 next 의 다음 노드는 destory 가 아니라 destroy 의 다음 노드가
* 된다. */
next->nextNode = destroy->nextNode;
}
/* next 는 다음 노드를 가리킨다. */
next = next->nextNode;
}
free(destroy);
}이와 같이 만들면 된다. head 노드부터 차례대로 다음 노드와 비교해가면서 찾는 모습이다. 이 과정은
while (next) {
/* 만일 next 다음 노드가 destroy 라면 next 가 destory 앞 노드*/
if (next->nextNode == destroy) {
/* 따라서 next 의 다음 노드는 destory 가 아니라 destroy 의 다음 노드가 된다.
*/
next->nextNode = destroy->nextNode;
}
/* next 는 다음 노드를 가리킨다. */
next = next->nextNode;
}여기서 잘 나타나 있다. 만일 next->nextNode == destroy 라는 말은 "다음 노드가 우리가 파괴할 노드 라면" 이라는 뜻이다. 만약 이 노드를 그냥 파괴하면 노드 사이가 끊기기 때문에 파괴할 노드가 가리키고 있는 노드와 파괴할 노드 이전의 노드를 연결하기 위해서 next->nextNode = destroy->nextNode; 를 통해 현재 노드(파괴할 노드 바로 앞 노드)가 파괴할 노드 다음에 오는 노드를 가리키게 하였다. 그리고 마지막에 free 를 통해서 파괴하였다.
이 과정을 하나의 소스 코드로 나타내면 다음과 같다.
#include <stdio.h>
#include <stdlib.h>
struct Node* InsertNode(struct Node* current, int data);
void DestroyNode(struct Node* destroy, struct Node* head);
struct Node* CreateNode(int data);
void PrintNodeFrom(struct Node* from);
struct Node {
int data; /* 데이터 */
struct Node* nextNode; /* 다음 노드를 가리키는 부분 */
};
int main() {
struct Node* Node1 = CreateNode(100);
struct Node* Node2 = InsertNode(Node1, 200);
struct Node* Node3 = InsertNode(Node2, 300);
/* Node 2 뒤에 Node4 넣기 */
struct Node* Node4 = InsertNode(Node2, 400);
return 0;
}
void PrintNodeFrom(struct Node* from) {
/* from 이 NULL 일 때 까지,
즉 끝 부분에 도달할 때 까지 출력 */
while (from) {
printf("노드의 데이터 : %d \n", from->data);
from = from->nextNode;
}
}
/* current 라는 노드 뒤에 노드를 새로 만들어 넣는 함수 */
struct Node* InsertNode(struct Node* current, int data) {
/* current 노드가 가리키고 있던 다음 노드가 after 이다 */
struct Node* after = current->nextNode;
/* 새로운 노드를 생성한다 */
struct Node* newNode = (struct Node*)malloc(sizeof(struct Node));
/* 새 노드에 값을 넣어준다. */
newNode->data = data;
newNode->nextNode = after;
/* current 는 이제 newNode 를 가리키게 된다 */
current->nextNode = newNode;
return newNode;
} /* 선택된 노드를 파괴하는 함수 */
void DestroyNode(struct Node* destroy,
struct Node* head) { /* 다음 노드를 가리킬 포인터*/
struct Node* next = head; /* head 를 파괴하려 한다면 */
if (destroy == head) {
free(destroy);
return;
} /* 만일 next 가 NULL 이면 종료 */
while (next) { /* 만일 next 다음 노드가 destroy 라면 next 가 destory 앞 노드*/
if (next->nextNode == destroy) { /* 따라서 next 의 다음 노드는 destory 가
아니라 destroy 의 다음 노드가 된다. */
next->nextNode = destroy->nextNode;
} /* next 는 다음 노드를 가리킨다. */
next = next->nextNode;
}
free(destroy);
}
/* 새 노드를 만드는 함수 */
struct Node* CreateNode(int data) {
struct Node* newNode = (struct Node*)malloc(sizeof(struct Node));
newNode->data = data;
newNode->nextNode = NULL;
return newNode;
}실행 결과
노드의 데이터 : 100
노드의 데이터 : 200
노드의 데이터 : 400
노드의 데이터 : 300일단 추가적으로
void PrintNodeFrom(struct Node *from) {
/* from 이 NULL 일 때 까지,
즉 끝 부분에 도달할 때 까지 출력 */
while (from) {
printf("노드의 데이터 : %d \n", from->data);
from = from->nextNode;
}
}from 이후의 모든 노드가 출력 되는 함수를 다음과 같이 만들었다.
struct Node* Node1 = CreateNode(100);
struct Node* Node2 = InsertNode(Node1, 200);
struct Node* Node3 = InsertNode(Node2, 300);
/* Node 2 뒤에 Node4 넣기 */
struct Node* Node4 = InsertNode(Node2, 400);그리고 메인함수에 위와 같이 노드를 정의했다. 첫 헤드는 CreateNode 를 통해 만들었고 그 다음 부터는 InsetNode 함수를 사용하였다.
이렇게 노드를 만들어보았다. 노드는 배열과 달리 삽입/삭제/추가 등이 월등히 편리하다. 그렇다고 노드가 배열보다 월등히 좋다고 할 수 있을까? 꼭 그렇다고 말할 수는 없다. 왜냐하면 배열의 경우 3 번째 원소를 찾기 위해서 단순히 arr[3] 을 하면 되지만 노드의 경우 헤드로 부터 3번째 까지 일일히 찾아가야 하기 때문이다. 따라서 노드가 N 개 있다면 최악의 경우 N 번 동안 찾아야 한다. 배열의 경우 특정한 상수 시간 내에 찾아갈 수 있기 때문에 이부분에서는 배열이 월등히 좋다고 할 수 있다. 또한 노드의 경우 데이터의 공간 뿐만 아니라 다음 노드를 가리키기 위한 8바이트의 공간이 더 필요하기 때문에 공간적으로도 약간 손해를 본다고 생각할 수 있다.
메모리 관련 함수
이 단원이 메모리에 관한 것인 만큼 메모리에 대해서 빠삭하게 알아보자. C 표준 라이브러리에서 지원되는 메모리 관련 함수들에 대해서 알아보자. 대표적으로 memmove, memcpy, memcmp, memset 등이 있는데 우리는 대표적인 memmove, memcpy, memcmp 만 알아보자. 이 함수들은 string.h 에 정의 되어 있다.
memcpy
/* memcpy 함수 */
#include <stdio.h>
#include <string.h>
int main() {
char str[50] = "I love Chewing C hahaha";
char str2[50];
char str3[50];
memcpy(str2, str, strlen(str) + 1);
memcpy(str3, "hello", 6);
printf("%s \n", str);
printf("%s \n", str2);
printf("%s \n", str3);
return 0;
}실행 결과
I love Chewing C hahaha
I love Chewing C hahaha
hello이 memcpy 함수는 메모리의 특정 부분으로 부터 얼마 까지의 부분을 다른 메모리 영역에 복사해주는 함수이다. 위와 같이 문자열을 복사하는데 사용할 수 있다. 물론 문자열 복사를 전문적으로 하는 함수는 strcpy 이지만 위와 같이 memcpy 를 사용하는 것도 나쁘지 않다.
memcpy(str2, str, strlen(str) + 1);" str 로 부터 strlen(str) + 1 만큼의 문자를 str2 로 복사해라" 라는 뜻이다. strlen 함수는 문자열 길이 만큼 리턴해주는 함수이다. 그러나 NULL 문자는 세지 않기 때문에 마지막에 +1 을 해주는 것이다.
memcpy(str3, "hello", 6)마찬가지로 hello 의 5문자와 NULL 을 위해 총 6 문자를 hello 의 시작 주소로 부터 복사하게 된다. 더 자세한 내용은 여기 에서 확인하자
memmove
/* memmove 함수 */
#include <stdio.h>
#include <string.h>
int main() {
char str[50] = "I love Chewing C hahaha";
printf("%s \n", str);
printf("memmove 이후 \n");
memmove(str + 23, str + 17, 6);
printf("%s", str);
return 0;
}실행 결과
I love Chewing C hahaha
memmove 이후
I love Chewing C hahahahahahachar str[50] = "I love Chewing C hahaha";
memmove(str + 23, str + 17, 6);memmove 함수는 str + 17 에서 6 문자를 str + 23 에 복사했다. 따라서 str 뒤에 hahaha 가 추가된 셈이다. memmove 함수의 장점은 memcpy 와 하는일이 많이 비슷해 보이지만 memcpy 과 달리 메모리 공간이 겹쳐도 된다. 위 경우 str 과 복사하는 부분이 겹쳤지만 성공적으로 복사가 수행되었다. 덕분에 나중에는 memove 함수가 아주 많이 사용하게 될 것이다.
memcmp
이 함수는 예상할 수 있듯이 두 개의 메모리 공간을 비교하는 함수이다.
/* memcmp 함수 */
#include <stdio.h>
#include <string.h>
int main() {
int arr[10] = {1, 2, 3, 4, 5};
int arr2[10] = {1, 2, 99999, 4, 5};
if (memcmp(arr, arr2, 5) == 0)
printf("arr 과 arr2 는 일치! \n");
else
printf("arr 과 arr2 는 일치 안함 \n");
return 0;
}실행 결과
arr 과 arr2 는 일치!memcmp 함수는 매우 유용하게 사용할 수 있다. 이 함수는 두 메모리를 원하는 만큼 비교하고 같으면 0을 같지 않다면 0이 아닌 값을 리턴한다.
if (memcmp(arr, arr2, 5) == 0)arr 와 arr2 를 비교해 처음 5 개의 바이트가 같다면 0을 리턴한다. 여기서 주의해야할 점은 '5 개의 원소' 가 아니라 ' 5 개의 바이트' 라는 점이다. 만일 arr 와 arr2 의 전체를 비교하고 싶다면 마지막 인자로 5 가 아니라 sizeof(int) *5 를 해야할 것이다.
