
컴퓨터는 우리가 생각하는 것 만큼 그렇게 똑똑하지 않다.
아무리 최신 CPU를 장착한다고 하여도 우리의 컴퓨터는 단지 1와 0만 처리할 수 있다.
그렇다면 컴퓨터는 어떻게 "a,b,c"나 "韓" 과 같은 수많은 문자를 처리할 수 있을까?
방법이 있다. 바로 이러한 문자를 숫자에 대응시키는 것이다.
그렇다면 컴퓨터는 어떻게 숫자를 보고 이게 숫자인지 문자인지 알 수 있을까?
물론 컴퓨터는 알 수 없다 단지 숫자를 보고 "숫자" 형태로 사용하거나 "문자" 형태로 사용한다.
문자를 저장하는 변수는 앞서 살짝 살펴본적이 있다. 아래 표를 확인해보자
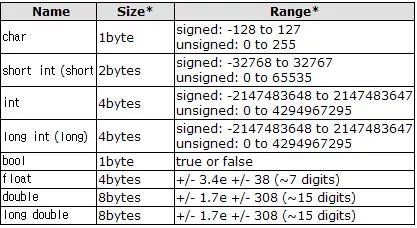
바로 char 이다. 크기는 1바이트이고 위에서 볼 수 있듯이 숫자의 범위는 -128부터 127까지 총 256 가지이다.
(char 는 charactor의 약자이다.)
#include<stdio.h>
int main(){
char a;
a = 'a'; // 쌍따음표 아님
printf("a 의 값과 들어 있는 문자는? 값 : %d , 문자 : %c \n", a, a);
return 0;
}<결과값>
a 의 값과 들어 있는 문자는? 값 : 97 , 문자 : a앞서 컴퓨터는 문자 a 를 보고 이것이 "문자"인지 "숫자"인지 알 수 없다고 했다. 단지 우리가 이것을 문자로 보나 숫자로 보나에 따라 달라진다고 했는데 아래 코드를 보면 알 수 있다.
printf("a 의 값과 들어 있는 문자는? 값 : %d , 문자 : %c \n", a, a);%d 는 a 의 값을 숫자(정수인 10진수)라고 출력하라는 뜻이고 %c 는 a 의 값을 문자로 출력하라는 뜻이다.
그렇다면 %d 에는 무엇이 출력되어야 할까? 앞서 말했듯이 컴퓨터는 문자와 숫자를 일일이 대응시킨다고 했다.
즉 %d 에 출력되는 숫자는 a 에 대응 되는 숫자를 출력한다.
이때 대응 되는 숫자는 아무렇게나 대응되는 것이 아니라 아래의 표를 따른다.
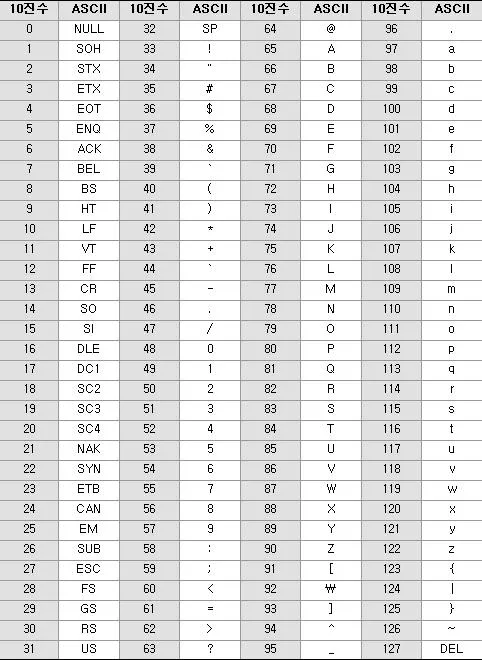
위 표는 미국 표준 학회(ASA)에서 정한 아스키코드(ASCII)로 8비트의 데이터로 문자에 숫자를 붙인 것이다. 위의 숫자가 127까지 밖에 없는 이유는 당시 7비트만으로도 충분하다고 생각했기 때문이다. 하지만 이후에 IBM에서 더 많은 문자의 필요성을 느껴 1비트를 추가하여 확장된 아스키 코드(Extended ASCII Code)를 만들었다. 컴퓨터가 전세계로 보급되면서 256개로도 부족함을 느끼고 결국 유니코드(Unicode)라는 새로운 형식의 문자 체계를 도입하게 된다. 유니코드는 1바이트부터 4바이트까지 다양한 길이로 처리하게 되고 이는 기존의 아스키코드를 유지하면서 새로운 문자를 추가하기 위함이다. 우리는 유니코드에 대해서는 직접 다룰일이 아직 없기 때문에 무시해도 된다.
scaf의 도입
#include <stdio.h>
int main() {
double celsius; // 섭씨 온도
printf("섭씨 온도를 화씨 온도로 바꿔주는 프로그램 입니다. \n");
printf("섭씨 온도를 입력해 주세요 : ");
scanf("%lf", &celsius); // 섭씨 온도를 입력 받는다.
printf("섭씨 %f 도는 화씨로 %f 도 입니다 \n", celsius, 9 * celsius / 5 + 32);
return 0;
}<결과값>
섭씨 온도를 화씨 온도로 바꿔주는 프로그램 입니다.
섭씨 온도를 입력해 주세요 :섭씨 온도를 화씨 온도로 바꿔주는 프로그램 입니다.
섭씨 온도를 입력해 주세요 : 37
섭씨 37.000000 도는 화씨로 98.600000 도 입니다위 코드를 살펴보자. 앞에 부분은 지금까지 했던 부분들과 큰 차이는 없다.
double celsius;먼저 celsius 라는 변수를 선언해주었다.
scanf("%lf", &celsius); // 섭씨 온도를 입력 받는다.그리고 새로운 것이 등장했다 scanf 는 화면(키보드) 로 부터 결과를 받아들이는 입력 함수이다.
scanf 와 printf 를 가리켜 입출력함수라고 한다. 이때 scaf는 우리가 어떤 값을 입력할 때 까지 기다린다.
또한 입력할 때 엔터를 눌러야만 입력이 된다.
scanf 와 printf 이 둘은 이름도 비슷한 뿐 더러 사용하는 방식도 비슷하다. printf 에서 각 포맷(%d, %f, %c 등)을 변수에 따라 다르게 지정하듯이 scanf 도 각 변수의 타입마다 입력하는 포맷을 달리 해야 한다.
위의 경우와 같이 double 형의 변수를 입력받으려면 %lf 로만(영어소문자 lf) 입력해야한다.
printf 는 double 형과 float 형 둘다 %f 로 출력하지만 scanf 같은 경우 float 형만 %f 로 무조건 입력 받아야 한다. (double 형의 변수를 입력받으려면 무조건 %lf 만)
printf("섭씨 %f 도는 화씨로 %f 도 입니다 \n", celsius, 9 * celsius / 5 + 32);앞에 %f 에는 변수celsius 가 들어가고 뒤에 %f 에는 연산된 결과가 들어간다.
#include <stdio.h>
int main() {
char ch; // 문자
short sh; // 정수
int i;
long lo;
float fl; // 실수
double du;
printf("char 형 변수 입력 : ");
scanf("%c", &ch);
printf("short 형 변수 입력 : ");
scanf("%hd", &sh);
printf("int 형 변수 입력 : ");
scanf("%d", &i);
printf("long 형 변수 입력 : ");
scanf("%ld", &lo);
printf("float 형 변수 입력 : ");
scanf("%f", &fl);
printf("double 형 변수 입력 : ");
scanf("%lf", &du);
printf("char : %c , short : %d , int : %d ", ch, sh, i);
printf("long : %ld , float : %f, double : %f \n", lo, fl, du);
return 0;
}<결과값>
char 형 변수 입력 : b
short 형 변수 입력 : 1
int 형 변수 입력 : 2
long 형 변수 입력 : 3
float 형 변수 입력 : 4
double 형 변수 입력 : 5
char : b , short : 1 , int : 2 long : 3 , float : 4.000000, double : 5.000000위 코드를 한번 살펴보자
printf("char 형 변수 입력 : ");
scanf("%c", &ch);char 는 최대 1바이트를 차지하게 되는데 한글은 2바이트이다. 따라서 char 의 변수인 ch 에 한글을 입력하게 되면 오류가 발생하고 이와 같이 허용된 메모리 이상의 데이터를 입력하여 발생하는 오류를 버퍼 오버플로우( Buffer Overflow)라고 하며 보안상 매우 취약하다.
또한 데이터 손상으로 인해 큰 문제까지 이어질 수 있기 때문에 변수를 입력할 때 메모리 이상의 데이터를 넣지는 않는지 검사를 해줘야 한다.
또한 앞으로 char 의 변수를 사용하면 "이 사람은 문자를 보관하는 변수를 사용하는 구나"라고 생각하자.
왜냐하면 보통 정수 데이터를 보관하는 변수로 int 를 사용하지 char 를 잘 쓰지 않을 뿐더러 char 가 "character" 에서 나온 만큼 문자와 관련되어 있기 때문이다.
printf("short 형 변수 입력 : ");
scanf("%hd", &sh);
printf("int 형 변수 입력 : ");
scanf("%d", &i);
printf("long 형 변수 입력 : ");
scanf("%ld", &lo);이 부분은 이해하는데 큰 무리가 없을 것이다. 단지 포맷 %hd %d %ld 들이 낯설 뿐이다.
참고로 shor 형과 long 형은 다루지 않았지만 int 와 똑같은 계열의 정수형 변수라고 생각하면 된다.
