
문자열은 영어로 string 이라고 한다. 그런데 string 의 사전적인 뜻은 '실'이다. 왜 실 일까?
그 이유는 문자열들이 정말로 실 처럼 문자들이 쭈르륵 나열되어 있기 때문이다.
그렇다면 컴퓨터는 문자열을 어떻게 저장할까? 앞서 문자들이 쭈르륵 나열되어 있다고 말했던 사실을 생각해보면 문자열은 문자들의 배열, 즉 char 배열에 저장되어 있다고 알 수 있다.
널 - 종료 문자열 (Null-terminated string)
위에서 문자열은 char 배열에 저장한다고 했다. 마치 아래의 그림처럼
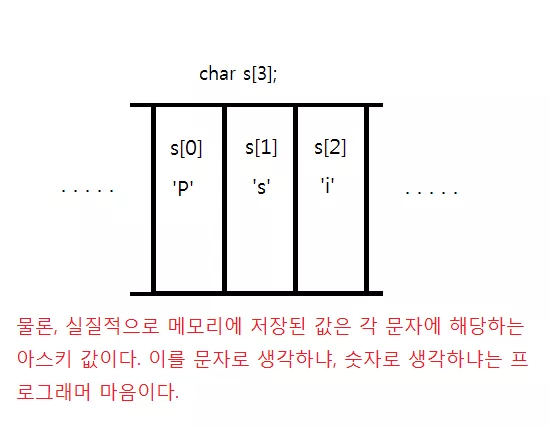
그런데 위 처럼 문자열 s 를 정의하면 무언가 불편한 마음이 든다. 만일, 우리가 문자열 s 에 정의된 문자들을 화면에 출력한다고 생각해보자. 이상적인 상황으로는 컴퓨터에게 "s의 문자열들을 출력해!" 라고 하면 알아서 출력해주는 것이다. 그런데 위 처럼 배열 s 에 문자를 저장 한다면 컴퓨터에게 "s의 문자열을 출력해! 그런데 그 문자들은 아마 3 문자일 것이야" 라고 말해주어야 하는 불편함이 생기는 것이다.
문자열들은 말 그래도 문자들이 하나로 뭉쳐서 다닌다. 우리가 s 의 문자열을 이용한다고 첫글자 P 만 사용하는게 아닌것 처럼 말이다. 우리는 상식적으로 Psi 전체를 하나로 이용하는 것이다. 문자열을 이용할 때 마다 문자열의 길이를 알아야 한다면 정말로 불편할 것이다. 그래서 C 언어 개발자들이 다음과 같은 멋진 대안을 내놓았다.
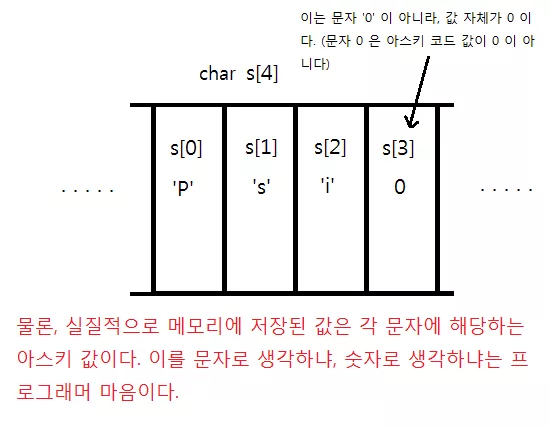
위와 같이 문자열 끝에 종료 문자를 넣어서" 여기까지가 문자열이였습니다." 라고 알려주는 것이다. 이 종료 문자는 아스키 값이 0이고 '\0'이라고도 나타낸다. 주의할 점은 문자 '0' 과는 헷갈리면 안된다는 것이다. 문자 0은 아스키 코드 값이 0 이 아니라 48이다. 흔히 이 문자는 널(Null) 이라고 부른다. 이제 이 소단원의 제목을 이해할 수 있을 것이다. 말 그대로 널로 끝나는 문자라는 의미이다. 이것이 C 언어의 문자열의 기본적인 형태이다.
널 문자가 들어갈 공간이 필요하기 때문에 3 글자라고 하여도 배열의 4 칸이 필요하게 된다. 위와 같이 s[3] 이 아니라 s[4] 와 같이 말이다. 이와 같이 하면 편한 이유는 컴퓨터가 문자열의 끝을 쉽게 구할 수 있기 때문이다. 우리는 더 이상 "이 s 문자열은 3문자야 출력해줘" 라고 할 필요 없이 그냥 "문자열 s 를 출력해줘" 라고만 해도 알아서 컴퓨터는 "널 값이 나올 때 까지 출력해야지"라고 생각하여 출력한다는 것이다.
#include <stdio.h>
int main() {
char null_1 = '\0'; // 이 3 개는 모두 동일하다
char null_2 = 0;
char null_3 = (char)NULL; // 모두 대문자로 써야 한다
char not_null = '0';
printf("NULL 의 정수(아스키)값 : %d, %d, %d \n", null_1, null_2, null_3);
printf("'0' 의 정수(아스키)값 : %d \n", not_null);
return 0;
}실행 결과
NULL 의 정수(아스키)값 : 0, 0, 0
'0' 의 정수(아스키)값 : 48NULL 의 값은 모두 0이 출력된 것을 볼 수 있고, 문자 '0' 은 48 이 나왔다.
char null_1 = '\0'; // 이 3 개는 모두 동일하다
char null_2 = 0;
char null_3 = (char)NULL;위의 3 문장은 모두 동일한 값인 0 이 들어가게 된다. 위에서 null_3 에는 NULL 값이 들어가는데 NULL 은 0이라고 정의되어 있는 상수이다.
char not_null = '0';반면 위의 not_null 의 경우에는 문자 '0' 의 아스키코드 값이 들어가는데 그 값은 48 이다.
컴파일 오류
warning C4047: '초기화 중' : 'char'의 간접 참조 수준이 'void *'과(와) 다릅니다.참고로 이와 같은 오류가 발생하는 사람도 있을 것이다. 왜 이러한 오류가 나오는지에 대해서는 뒤에서 확인해보자
다음 예제를 통해서 앞서 배운 것을 확실히 확인해보자
#include <stdio.h>
int main() {
char sentence_1[4] = {'P', 's', 'i', '\0'};
char sentence_2[4] = {'P', 's', 'i', 0};
char sentence_3[4] = {'P', 's', 'i', (char)NULL};
char sentence_4[4] = {"Psi"};
printf("sentence_1 : %s \n", sentence_1); // %s 를 통해서 문자열을 출력한다.
printf("sentence_2 : %s \n", sentence_2);
printf("sentence_3 : %s \n", sentence_3);
printf("sentence_4 : %s \n", sentence_4);
return 0;
}실행 결과
sentence_1 : Psi
sentence_2 : Psi
sentence_3 : Psi
sentence_4 : Psi모두 동일하게 "Psi" 가 출력되었다.
sentence_1 부터 sentence_3 는 각 원소로 'P', 's', 'i' 가 들어가고 마지막으로 종료 문자가 들어가 있는 크기가 4인 char 배열이다. 그렇다면 sentence_4 를 보자
char sentence_4[4] = {"Psi"};이전에 보았던 형태와는 좀 다르다. 사실 각 문자에 따음표를 쓰고 표시해서 배열에 저장하는 방식은 배우 귀찮다. 따라서 C 언에서는 위와 같이 문자들을 쭉 나열한 것을 따음표로 묶어주면 알아서 각각의 문자로 넣어준다.
이 때, 종료 문자(널 문자) 는 자동으로 맨 마지막에 추가 되어 굳이 큰 따음표 안에 명시해줄 필요가 없다.
흔히 초보자들이 많이 하는 실수는 위와 같이 "Psi"를 정의하고 크기가 3으로 잡는 것이다. 이렇게 되면 sentence 끝에 NULL 이 들어가지 않게 되어서 sentence 의 문자열을 출력하라고 했을 때 NULL 이 언제 나올지 모르기 때문에 허용하지 않은 메모리 공간까지 읽게 되는 문제가 발생한다.
따라서 반드시 널 문자를 위해 공간 하나를 더 추가하는 것을 잊지 말자.
아무튼 이와 같이 정의 하면 이전에 sentence_1 부터 sentence_3 까지 정의했던 것과 똑같이 정의된다.
%s
printf("sentence_4 : %s \n", sentence_4);위는" sentence_4 부터 들어 있는(sentence_4 가 배열의 시작 주소를 가리킨다는 사실은 알고 있을 것이다. 모르면 배열부분을 다시 보자) 문자열들을 출력해달라" 라는 의미로 %s 를 사용하였다. %c 는 한 문자만 출력하라는 의미이지만 %s 를 사용하면 sentence_4 부터 널 값이 나올 때 까지 문자를 계속 출력한다.
따라서 위 문장은 깔끔하게 Psi 가 출력된다.
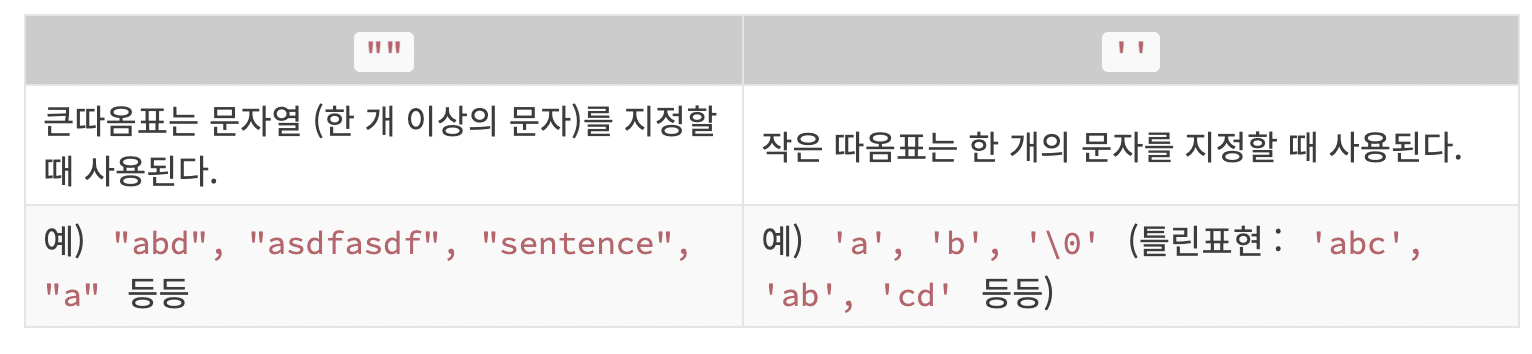
'' 와 "" 의 차이
여기까지 도달하셨으면 약간 헷갈리는 것이 '' 와 "" 의 차이점이다. 다음은 둘의 차이점을 깔끔하게 정리한 표니까 참고해보자
포인터 활용
#include <stdio.h>
int main() {
char word[30] = {"long sentence"};
char *str = word;
printf("%s \n", str);
return 0;
}실행 결과
long sentence그러면 이전에 배웠던 포인터를 활용하여 위의 예제를 확인해보자
사실 위 예제는 간단하다. 이전에 배운 내용을 활용하면 char * 를 활용하여 우리는 char 배열을 가리키는 포인터를 사용할 수 있다. 위는 이를 그대로 적용시킨 것으로 str 이라는 char 을 가리키는 포인터가 word 배열을 가리키고 있다.
따라서
printf("%s \n", str);에서 str 이 가리키는 것을 문자열로 출력하여(NULL 값이 나올 때 까지) 위와 같이 long sentence 가 나오는 것이다.
이제 다음 예제를 보자
#include <stdio.h>
int main() {
char word[] = {"long sentence"};
printf("조작 이전 : %s \n", word);
word[0] = 'a';
word[1] = 'b';
word[2] = 'c';
word[3] = 'd';
printf("조작 이후 : %s \n", word);
return 0;
}실행 결과
조작 이전 : long sentence
조작 이후 : abcd sentence사실 위 예제도 정말 간단한 것이다. 우선 다음 문장을 먼저 확인해보자
char word[] = {"long sentence"};여기서는 원소의 개수를 지정해주지 않았다. 만약에 이전에 배열강좌를 잘 보았다면 별로 이상하게 느껴지지 않을 것이다. 만약 배열의 크기를 빈칸으로 놔둔다면 컴퓨터가 알아서 원소의 개수를 세어서 빈칸에 넣으라는 의미이기 때문이다. (물론 배열의 정확한 크기를 알아야 할 상황이 온다면 특별히 값을 명시해 주어야 겠지만..)
word[0] = 'a';
word[1] = 'b';
word[2] = 'c';
word[3] = 'd';위와 같이 word 배열의 첫 4 개의 원소를 각각 a,b,c,d 로 변경하였다. 따라서 결과가 abcd sentence 로 변경 되었다.
문자의 개수를 세자
나중에 프로그래밍을 하다 보면 특정 문자열에 들어있는 문자의 개수를 세는 일이 많이 생길 것이다. 이를 수행하는 함수를 만들어보자. 아래의 코드를 보기전에 각자 만들어 보는 것을 추천한다.
#include <stdio.h>
int str_length(char *str);
int main() {
char str[] = {"What is your name?"};
printf("이 문자열의 길이 : %d \n", str_length(str));
return 0;
}
int str_length(char *str) {
int i = 0;
while (str[i]) {
i++;
}
return i;
}실행 결과
이 문자열의 길이 : 18지금까지 잘 따라 왔다면 위의 예제를 이해하는데 큰 무리는 없겠지만 일단 확인해보자
int str_length(char *str) {
int i = 0;
while (str[i]) {
i++;
}
return i;
}위 str_length 함수는 인자는 char 형을 가리키는 포인터 형태이므로 char 배열을 취할 수 있음을 알 수 있다. 이전에 배웠겠지만 일차원 배열을 가리키는 포인터는 (그 배열의 형)* 라는 것을 알고 있을 것이다. 아무튼 str 를 통해서 배열을 가리킬 수 있다.
while (str[i]) {
i++;
}위의 while 문의 조건에는 str[i] 가 들어 있는데 이 말은 즉 str[i] 가 0이 될때 까지(False 의 값이 0이기 때문) i 의 값을 증가시킨다는 의미이다. 그런데 str[i] 가 0이 되는 순간이 언제일까? 바로 NULL 문자일 때(종료 문자)이다. 즉, 문자열의 끝 부분에 도달 했을 때 0이 된다. 따라서 그때 i 의 값이 증가하는 것을 멈춘다는 의미이다.
따라서 i 에는 맨 마지막 NULL 값을 제외한 나머지 문자들의 총 개수가 되는 것이다.
문자열 입력받기
#include <stdio.h>
int main() {
char words[30];
printf("30 자 이내의 문자열을 입력해주세요! : ");
scanf("%s", words);
printf("문자열 : %s \n", words);
return 0;
}실행 결과
30 자 이내의 문자열을 입력해주세요! : WhySoSerious?
문자열 : WhySoSerious?위의 예제를 살펴보자
char words[30];일단 최대 29자의 문자열을 입력 받을 수 있는 문자 배열 word 를 생성했다. 왜 29자인지에 대해서는 앞서 누누히 말했지만 끝에는 NULL 이 들어가기 때문이다.
printf("30 자 이내의 문자열을 입력해주세요! : ");
scanf("%s", words);이제 입력한 값을 word 에 저장하는 부분인데, sacnf 가 앞서 우리가 자주 보았던 형식과는 조금 다르다.
char c;
scanf("%c", &c);원래는 이와 같이 & 주소 연산자를 사용하여 변수의 주소값을 전달하였는데 위에서는 그냥 배열의 이름만 사용하였다. 왜 배열의 이름만 사용한지는 앞서 배열을 공부한 사람이라면 알 수 있을 것이다. word 라는 배열의 이름 자체가 배열을 가리키고 있는 포인터이기 때문에 배열의 시작 주소값이 전달되기 때문이다.
띄어쓰기가 포함된 문자열
scanf 는 잘 알다 싶이 엔터가 나올 때 까지 입력을 받는다. 그런데 우리가 문자열을 입력할 때 띄어쓰기를 포함하여 전달한다면 아래와 같은 일이 발생한다.
실행 결과
30 자 이내의 문자열을 입력해주세요! : what is your name
문자열 : what분명히 scanf 는 엔터가 나오면 입력을 종료하는데 왜 what is your name? 에서 what 부분만 입력이 되었을까? 이에 대한 얘기는 뒤에서 이어서 하자
버퍼(Buffer)
#include <stdio.h>
int main() {
int num;
char c;
printf("숫자를 입력하세요 : ");
scanf("%d", &num);
printf("문자를 입력하세요 : ");
scanf("%c", &c);
return 0;
}실행 결과
숫자를 입력하세요 : 1
문자를 입력하세요 :위를 실행해보면 순간 당황했을 것이다. 우리는 숫자를 입력하고 문자를 입력하려는 순간 컴파일이 끝나버렸다.
우리는 분명히 scanf 를 활용하여 숫자를 입력받고 "문자를 입력하세요 : " 를 출력한 다음에 문자를 입력받으라고 했다. 그런데 위는 scanf("%c", &c); 명령이 완전히 무시된 것 같다. 왜 그럴까? 이를 이해하기 위해서는 scanf 에 대해서 자세히 알아볼 필요가 있다.
우리가 컴퓨터에 문자를 입력하면 컴퓨터는 어떻게 처리할까?? 예를 들어서 우리가 abcde 를 입력한다고 했을 때 컴퓨터가 각 문자가 입력 되었을 때 마다 문자를 처리한다면 어떨까? 즉 우리가 a 를 누르는 순간 a 라는 문자를 변수에 저장하고 b 를 누르면 b 라는 문자를 변수에 저장하고.. 만약 이런식으로 처리한다면 매우 비효율 적일 것이다.
하지만 이러면 어떨까? 우리가 문자를 입력한다면 잠시 어딘가에 보관했다가 입력이 끝나면 잠시 저장했던 곳에서 정보를 한꺼번에 처리하는 것이다. 따라서 우리가 abcde 를 입력하면 어딘가에 abcde 를 잠시 보관했다가 입력이 끝나면 한꺼번에 처리하는 것이다.
사실 이 두가지의 방법에 무슨 차이가 있냐고 할 수 있지만 아래에 예시를 보면 이해하기 수월할 수 있다.
우리가 만일 약수터에서 3L의 물을 가져온다고 생각해보자. 물을 가져오는 방식이 2가지 있다고 생각해보자. 첫 번째는 손으로 물을 조금씩 받아서 약수터까지 수십번 왔다갔다 하는거고 두 번째는 양동이를 가지고 가서 3L를 채운 뒤에 양동이를 가지고 오는 방식이 있다.
어느 방식이 더 효율적일까? 당연히 후자일 것이다. 컴퓨터는 실제로 원리는 이것보다 더 복잡하지만 후자의 방식을 채택하고 있다.
그렇다면 컴퓨터의 양동이에 해당하는 부분이 무엇일까? 바로 버퍼(Buffer) 이다. 또한 수 많은 버퍼 중에서 키보드의 입력을 처리하는 버퍼는 바로 입력 버퍼, 혹은 **stdin** (흔히 입력 스트림)이라고 부르는 것이다.
다시 말해서 우리가 키보드로 문자를 입력했을 때의 모든 정보를 stdin 에 저장하였다가 입력이 종료되면 한꺼번에 처리하는 것이다. 그런데 우리가 입력이 종료되었는지 어떻게 컴퓨터가 알까? 바로 엔터를 치면 된다. 왜냐하면 이전에도 우리가 엔터를 치면 입력이 종료되고 프로그램이 실행되었던 것을 보았을 것이다.
다시말해서 컴퓨터는 개행 문자, 즉 \n 을 입력하면 "입력을 종료했으니까 버퍼에 들어있는 내용을 가지고 처리해라" 라는 뜻으로 받아 들인다.
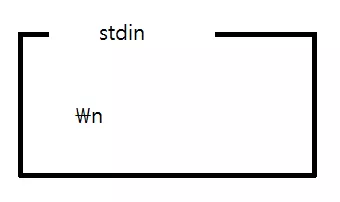
그런데 컴퓨터는 \n 까지 버터에 저장한다. 즉, 우리가 1 을 치고 엔터를 누르면 아래의 그림과 같은 상태가 된다.

이렇게 입력이 끝났으면 컴퓨터는 scanf 함수를 이용하여 stdin 으로 부터 숫자를 얻어온다. 왜 숫자이냐면
scanf("%d", &num);이렇게 하였기 때문이다. 즉, 오직 숫자 데이터만 stdin 에서 얻어 오겠다는 말이다. 그렇다면 scanf 함수는 언제까지 stdin 으로 부터 데이터를 얻어올까? 바로 공백 문자( ' ', '\n', '\t' )를 만날 때 까지이다.
' ': 띄어쓰기 한 칸(space bar)'\n': 엔터'\t': 탭 키
다시 말해서 scanf 함수는 위의 3가지중 하나라도 만나게 되면 "아 여기서 입력은 끝이구나" 하고 입력을 종료하게 되는 것이다.
참고적으로 %d 계열의 것들 ,즉 수를 입력 받는 형식은 다음과 같은 특징이 있다.
- 수가 아닌 데이터가 와도 입력을 종료하게 된다.
- 처음부터 공백 문자가 나타나면 종료되는게 아니라 수가 나타날 때 까지 계속 입력을 받는다.
1 번의 경우 만약에 1 대신 a 를 입력을 하면 num 에는 아무런 정보가 들어가지 않아 치명적인 결과를 초래할 수 있다. 2 번의 경우 수를 입력하는 대신 엔터를 친다고 해도 수를 입력하기 전까지 다음으로 넘어가지 않는다.
아무튼 scanf 함수는 공백 문자( ' ', '\n', '\t' ) 를 만나기 전까지 stdin 에서 데이터를 가져간 후 버퍼에서 삭제해 버린다. 다시말해서 위 scanf 함수가 num 에 1을 저장하고 난 후 버퍼의 모습은 다음과 같다.
자, 이제 우리의 말을 잘 듣는 컴퓨터는
scanf("%c", &c);를 실행하게 된다.
그런데 %c 는 이유를 불문하고 stdin 에서 딱 한 개의 문자만을 가져오게 된다. 만일 stdin 에 아무것도 없으면 사용자의 입력을 기다리겠지만 stdin 에 무언가 있다면 그 것을 냉큼 가져오게 된다. 그런데 공교롭게도 위의 그림처럼 \n 을 버퍼에 남겨두었기 때문에 scanf 는 이것을 냉큼 c 에 저장하게 된다. 즉, c 에는 사용자의 입력을 받지 않고 '\n' 을 집어 넣은 것이다.
따라서 우리가 printf("%c 출력", c); 를 하면 '출력'이 한 칸 개행(엔터가 쳐져서) 되어서 나타난다.
%s 로 scanf 에서 받을 경우
#include <stdio.h>
int main() {
char str[30];
int i;
scanf("%d", &i);
scanf("%s", str);
printf("str : %s", str);
return 0;
}실행 결과
1
asdfasfasdf
str : asdfasfasdf%c 말고 %s 를 해보았는데 다행이 이번에는 무사히 컴퓨터가 사용자로 부터 입력을 잘 받았다. 사실 그 이유는 간단하다. 우선,
scanf("%d", &i);를 이용하여 사용자로부터 수를 입력 받게 되면 역시 stdin 에 \n 가 남게 된다. 그리고
scanf("%s", str);를 실행하게 되면 수 데이터를 입력받았던 형식과 마찬가지로 실질적인 데이터(공백이 아닌 데이터)가 나오기 전 까지는 버퍼에 남아 있는 공백 문자들을 무시하고 실질적인 문자들이 나타나면 그 다음부터 등장하는 공백 문자에서는 종료가 된다. 즉, 기존에 1 을 입력하고 남았던 \n 는 사라지고 내가 asdfasfasdf 를 입력하고 난 뒤, 엔터를 쳤을 때 들어가는 \n 을 인식하게 되는 것이다.
결론적으로 말하자면 다음과 같다.
%s나%d, 그리고 다른 모든 수 데이터를 입력 받는 형식은 버터에 남아있는 공백 문자에 신경쓰지 않고 사용할 수 있다.
하지만 %c 의 경우는 버퍼에 무엇이 남아있는지 잘 고려해야 한다. 이는 정말 번거로운 일이 아닐 수 없다. 이에 대한 좋은 대한이 있는데 그건 뒤에서 확인해보고 일단 다음 예제를 보자.
#include <stdio.h>
int main() {
char str1[10], str2[10];
printf("문자열을 입력하세요 : ");
scanf("%s", str1);
printf("입력한 문자열 : %s \n", str1);
printf("문자열을 입력하세요 : ");
scanf("%s", str2);
printf("입력한 문자열 : %s \n", str2);
return 0;
}실행 결과
문자열을 입력하세요 : hello
입력한 문자열 : hello
문자열을 입력하세요 : baby
입력한 문자열 : baby여기까지 잘 따라왔으면 위 예제를 이해하는데 문제가 없을 정도로 매우 평범하다. 그렇다면 다음과 같이 입력해보자.
실행 결과
문자열을 입력하세요 : hello baby
입력한 문자열 : hello
문자열을 입력하세요 : 입력한 문자열 : baby이번에는 두 번째 scanf 가 완전히 무시되어 지나갔다. 왜 이렇게 되었을지 조금만 생각해보면 왜 str1 에는 'hello' 가 들어가고 str2 에는 'baby' 가 들어간지 알 수 있을 수도 있다.
우리가 'hello baby' 라고 입력했을 때 stdin 의 상태를 살펴보자.
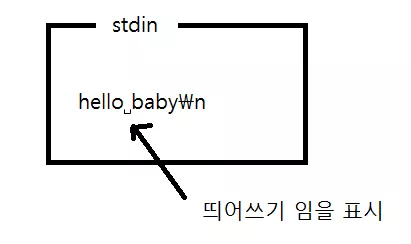
scanf("%s", str1);scanf 함수는 stdin 에서 의미있는 데이터(공백 문자가 아닌 데이터)가 올 때 까지 모든 공백 문자들을 무시한다. 위의 경우에는 바로 의미있는 데이터가 오기 때문에 바로 stdin 으로 부터 데이터를 가져올 것이다. 그리고 공백 문자가 오면 입력을 중지 할 것이다. 위의 경우 hello 뒤의 공백 ' '가 공백 문자이기 때문에 입력을 중지하고 str1 에는 'hello'가 들어가게 된다.
첫번째 scanf 함수가 지나가고 난 뒤에 stdin 의 상태는 다음과 같다.

이제 두번째 scanf 가 지나갈 차례이다.
scanf("%s", str2);scanf 함수는 만약 stdin 에 아무것도 없거나 공백 문자만 있으면 사용자가 입력을 할 때 까지 대기를 할 것이지만 위의 경우는 조금 다르다. 일단 처음에 있는 공백 문자인 띄어쓰기는 가볍게 무시하지만 그 뒤에 의미있는 데이터가 있으므로 입력을 쭉 받기 시작한다. 그러다가 마지막에 공백 문자인 엔터가 있으니 입력을 중지하게 된다. 따라서 버퍼에는 다음과 같이 \n 만 덩그러니 남게 된다.

따라서 입력하기도 전에 입력을 끝내고 'baby' 라는 문자가 str2 에 들어가게 되는 것이다.
이처럼 sanf 함수는 상당히 이해하기가 복잡하다. 가뜩이나 어려운데 %c 를 이용하면 고려해야할 것이 더 많아져 짜증이 난다. 그러나 이러한 문제를 해결할 수 있는 방법도 있고 실질적으로 %c 는 많이 안쓰여서 다행이다.
도대체 이 문제를 어떻게 해결 할까?
하지만, 아무리 %c 를 잘 사용하지 않는다고 하여도 필연적으로 사용할 일이 생기게 된다. 그렇다면 그럴 때 마다 이처럼 버퍼에 \n 이 남아 있는지 고려하는 일은 번거로운 일이 아닐 수 없다. 하지만 역시 이를 위한 해결방법이 여러 가지가 있다.
해결방법 1. fflush
/*
버퍼 비우기
주의하실 점은 반드시 MS 계열의 컴파일러로 컴파일 해주세요. 즉, Visual Studio
계열의 컴파일러로 말이죠. 이 말이 무슨 말인지 모르면 그냥 늘 하던대로 하면
됩니다.
gcc 에서는 정상적으로 작동되지 않는 위험한 코드 입니다.
*/
#include <stdio.h>
int main() {
int num;
char c;
printf("숫자를 입력하세요 : ");
scanf("%d", &num);
fflush(stdin);
printf("문자를 입력하세요 : ");
scanf("%c", &c);
return 0;
}실행 결과
숫자를 입력하세요 : 1
문자를 입력하세요 : c주석만 보면 무시무시하지만 일단 다음을 보자
printf("숫자를 입력하세요 : ");
scanf("%d", &num);위 까지 실행하면 stdin 안에는 아직 \n 이 남아 있다. 그런데
fflush(stdin);새로운 문장이 등장했다. 위의 의미는 'stdin 을 비워버려라' 라는 의미이다. 따라서 버퍼가 완전히 비워지게 된다.
scanf("%c", &c);따라서 위의 함수가 실행되었을 때는 버퍼에는 아무런 공백 문자도 있지 않아 컴퓨터는 사용자의 입력을 기다리게 된다. 즉, 우리가 원하는 문자를 c 에 넣을 수 있다는 말이다. 하지만 주석에서 읽을 수 있듯이 상당히 무서운 함수이다. 왜냐하면 fflush 가 표준으로 '무슨 역할을 한다.' 라고 정해진 것이 아니다. 다시 말해 Visual Studio 에선 fflush 함수가 버퍼를 비우는 훌륭한 역할을 하지만 다른 것 - 예를 들면 gcc 같은 데에서는 이러한 작업을 하지 않을 가능성이 매우 매우 크다.(Visual Studio 2015 부터는 표준을 따라서 fflush 가 위와 같이 작동하지 않는다.)
해결방법 2. getchar
#include <stdio.h>
int main() {
int num;
char c;
printf("숫자를 입력하세요 : ");
scanf("%d", &num);
getchar();
printf("문자를 입력하세요 : ");
scanf("%c", &c);
return 0;
}실행 결과
숫자를 입력하세요 : 1
문자를 입력하세요 : c이번에도 무사히 작동한다. 그리고 새로운 함수가 보인다.
getchar();getchar 함수의 역할은 'stdin에서 한 문자를 읽어와서 그 값을 리턴한다'이다. 읽어온 문자는 stdin 에서 사라지게 된다. 따라서 위 함수를 호출하면 첫번째 scanf 함수뒤에 생긴 \n 를 지울 수 있게 되는 것이다.
만일 우리가
ch = getchar();
prinf("%c", ch);를 해서 getchar 함수의 리턴 값을 확인해보면 화면상에 한 칸 엔터가 쳐진 것을 확인 할 수 있다.
아무튼 getchar 함수를 이용하여 stdin 을 비운 상태에서 scanf 함수를 호출하면 정상적으로 사용자가 입력한 값을 받게 된다.
getchar 함수를 호출하는 방법은 여러 모로 많이 사용되는 방법이다. 기본적으로 scanf 로 %c 형식을 사용하는 것을 추천하지는 않지만 만약 정 사용해야 한다면 getchar 함수를 사용하여 버퍼를 비우는 것을 추천한다. 하지만 이러한 방법에도 문제점은 존재한다. 만약 버퍼에 한 문자가 아니라 여러 문자가 남아 있는 경우라면 어떻게 할까? 한 번 숫자를 입력할 때 123abc 를 쳐보자
#include <stdio.h>
int main() {
int num, i;
char c;
printf("숫자를 입력하세요 : ");
scanf("%d", &num);
getchar();
printf("문자를 입력하세요 : ");
scanf("%c", &c);
printf("입력한 문자 : %c", c);
return 0;
}실행 결과
숫자를 입력하세요 : 123abc
문자를 입력하세요 : 입력한 문자 : b혹시나 했는데 scanf 가 사용자의 입력을 기다리지 않고 지나쳐버렸다. 또한 c 에도 우리가 원하지 않던 b 가 들어 있다. 도대체 왜 이런일이 발생 했을까? 차근차근 확인해보자.
printf("숫자를 입력하세요 : ");
scanf("%d", &num);여기서 우리는 숫자만 입력하지 않고 사악하게 123abc 를 입력하였다. 그러면 버퍼에는 다음과 같은 상태 일것이다.

이제 scanf 함수가 데이터를 차례대로 읽어온다. 그런데 앞서 %d 형태는 수 데이터가 아닌 값을 만나거나 공백 문자를 만나면 입력을 중지한다고 했다. 따라서 'a'를 만나는 순간 입력을 중지하고 '123'이 num 에 들어간다. 아마도 stdin 은 다음과 같은 모습일 것이다.
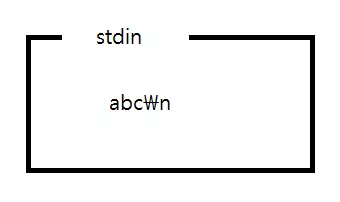
getchar();그리고 getchar 함수가 실행되어 stdin 에서 한 문자를 가져와 리턴하고 stdin 에서는 사라지게 된다. 따라서 'a'를 가져와 리턴하고 사라진다.
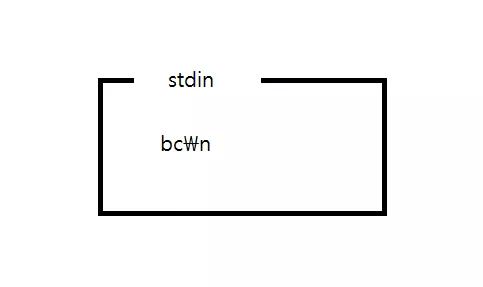
그리고 위와 같은 상태가 된다. 보기만 해도 알 수 있듯이 버퍼가 깔끔하게 지워지지 않았다. 따라서
printf("문자를 입력하세요 : ");
scanf("%c", &c);위와 같이 다음에 오는 scanf 는 버퍼에서 한 문자를 가져가고 그게 'b'가 되는 것이다. 따라서 c 에는 우리가 바라지도 않았던 'b'가 들어가게 되는 것이다.
아무튼 여기서 우리가 내릴 수 있는 결론은 "되도록이면 %c 를 사용하지 말자" 이다. scanf 에서 %c 를 사용하는 것은 정말로 추천하지 않는다. 만약에 한 문자만 입력 받는 프로그램을 만들려면 차라리 scanf 에서 %s 를 통해 문자열을 입력받고 맨 앞에 한 문자만 취하는 형식으로 만드는 것을 추천한다.
문자열은 문자열의 주소?
#include <stdio.h>
int main() {
char str[] = "sentence";
char *pstr = "sentence";
printf("str : %s \n", str);
printf("pstr : %s \n", pstr);
return 0;
}실행 결과
str : sentence
pstr : sentence다음을 살펴보자
char str[] = "sentence";
char *pstr = "sentence";여기서 위 문장을 보고 이상하다고 생각했을 것이다. 일단 첫번째 문장은 평범한 문장이다. 'sentence' 라는 문자열을 str 이라는 배열 안에 집에 넣었다. 그런데 두번째 문장은 상당히 이상하다. 왜냐하면 'sentence'는 문자열이고 어떤 변수의 주소값이 아니다. pstr 은 char 형을 가리키는 포인터이므로 char 형 변수의 주소값이 들어가야 하기 때문이다.
그런데 위에서는 'sentence'가 마치 특정한 주소값 마냥 사용되었다. 그런데, 'sentence'는 주소값이 맞다. 그렇다면 누구의 주소값일까? 바로 'sentence'라는 문자열이 저장된 주소값 (시작 주소값) 이다. 정말로 놀라운 사실이 아닐 수 없다.. 의심스럽다면 아래의 문장을 넣어서 실행해보자
printf("%d \n", "sentence");그러면 정말 특정한 수가 출력됨을 알 수 있다. 그렇다면 이 'sentence'는 도대체 뭘까? 이를 이해하기 위해서는 다음 예제를 보자
#include <stdio.h>
int main() {
char str[] = "hello";
char *pstr = "goodbye";
str[1] = 'a';
pstr[1] = 'a';
return 0;
}위 예제를 실행하면 오류가 발생할 것이다. 왜 오류가 났을까? pstr[1] = 'a'; 를 제외하고 실행하면 위 코드는 잘 실행이 된다. 따라서
pstr[1] = 'a';이것이 문제인 것을 알 수 있다. 근데 왜 문제가 발생 했을까? 앞선 예제에서는 pstr 를 읽기만 하였을 때(printf 함수는 읽기만 하지 변경은 하지 않는다) 문제가 없었는데 pstr[1] = 'a'; 와 같이 변경을 하려고 하면 오류가 발생하는 것으로 보아 마치 상수처럼 컴퓨터가 값을 변경하는 것을 허락하지 않는 것 같다.
리터럴 (literal)
프로그래밍 언어에서 리터럴(literal) 이란, 소스 코드 상에서 고정된 값을 가지는 것을 일컫는다. 특히 C 언어의 경우 큰 따음표 (")로 묶인 것들을 문자열 리터럴(string literal)이라 부른다.
char *pstr = "goodbye";
printf("why so serious?");
scanf("%c", str[0]);위의 경우 문자열 리터럴은 무엇일까? goodbye, why so serious?, %c 모두 문자열 리터럴이다.
컴퓨터는 이러한 리터럴들을 따로 모아서 보관한다. 즉, 프로그램을 실행하게 되면 특별한 공간에 goodbye, why so serious?, %c 같은 리터럴들이 쭈르륵 보관되어 있는 공간이 생긴다는 것이다.
따라서 char *pstr = "goodbye"; 를 하게 되면 컴퓨터는 "goodbye의 시작 주소값을 가져와서 pstr 에 대입해라" 라는 의미의 작업을 실행하게 된다. 따라서 pstr 은 'goodbye' 라는 리터럴을 가리키고 printf("%s", pstr) 을 했을 때 goodbye 를 성공적으로 리턴할 수 있게 된다.
그리고 앞서 리터럴은 소스 코드 상에서 고정된 값을 가지고 있다고 했듯이 리터럴의 값은 절대로 변경 되어서는 안된다.
아까도 말했듯이 만일 hello 라는 리터럴의 값을 실수로 (물론 내가 했을 수도 있고 컴퓨터의 버그로 그랬을 수 도 있고) hi 로 변경하였다면 사용자는 분명히 str 에 hello 라는 값을 넣으라고 명령했지만 hi 가 들어가게 되어 큰 문제를 야기할 수 있게 된다.
따라서 리터럴은 오직 읽기만 가능한 곳이 된다. 만일 이곳을 함부로 변경하려는 시도가 있다면 프로그램은 강제로 종료될 것이다.
그렇기 때문에 우리는 char str[] = "hello"; 를 했다면 str 에는 hi 가 아니라 hello 가 들어가고 printf("why so serious?"); 를 하면 why so serious? 가 출력될 것이라고 보장 할 수 있는 것이다. 왜냐하면 이 모든 문자열들이 "문자열 리터럴"이라는 이름 하에 메모리상에 특정한 공간에서 보호 받고 있기 때문이다.(사실 이건 운영체제, 환경에 따라서 다를 수 있다.)
char *pstr = "goodbye";
pstr[1] = 'a';그러면 위 코드를 살펴보자. "goodbye"는 문자열 리터럴 이기 때문에 '리터럴들의 세상'(정확하게는 리터럴들 뿐만 아니라 프로그램상에 정의한 모든 상수도 여기에 들어간다 )에 저장이 된다. 그런데 이곳은 오직 읽기만 가능하기 때문에 pstr[1] = 'a'; 와 같은 변경을 시도하면 컴퓨터는 오류를 내뿜고 종료되는 것이다.
반면에
printf("pstr : %s \n", pstr);이와 같이 오직 '읽기' 작업만 수행하는 printf 의 경우에는 문제 없이 실행이 된다.
그렇다면 아래의 코드는 어떨까?
char str[] = "hello";사실 위의 "hello"는 리터럴이라고 말하기 애매하다. 사실 위 배열의 정의는 컴파일러에서 아래와 같이 해석되기 때문이다.
char str[] = {'h', 'e', 'l', 'l', 'o', '\0'};이는 그냥 str 이라는 배열에 hello 라는 문자열을 복사하게 될 뿐이다. 그리고 위의 배열은 텍스트 세그먼트가 아니라 스택(Stack) 이라는 메모리 수정이 가능한 영역에 정의 된다 따라서 str 안에 문자열들은 수정이 가능하다.
주의 사항
참고적으로 VS 2017 이상에서는 리터럴을 char* 가 가리킬 수 없습니다. 반드시 const char* 가 가리켜야 하며, 덕분에 리터럴을 수정하는 괴랄한 짓을 컴파일 단에서 막을 수 있습니다.문자열 다시 가지고 놀기
C언어에서 문자열을 다루는 일은 생각보다 불편한 일이다. 예를 들어 int 형의 경우
int i, j =0;
i = j + 3;위가 가능하지만 문자열의 경우
char str1[] = {"abc"};
char str2[] = {"def"};
str1 = str1 + str2; 를 한다고 해서 str1 이 "abcdef" 가 되는 것이 절대 아니다. str1 + str2 는 각 배열의 주소값을 더하겠다는 의미인데, 이전에 말했듯이 배열의 이름은 포인터 상수 이기 때문에 대입 연산 수행시 오류가 발생한다.
또한 다음과 같은 문자열의 비교도 불가능하다.
if (str1 == str2)왜냐하면 이미 예상할 수 있듯이 위의 문장의 의미는 " str1 문자열의 메모리 상의 (시작)주소와 str2 문자열의 메모리 상의 (시작)주소를 비교해라 " 따라서 우리가 원하던 기능을 사용할 수 없다. 물론 다음과 같은 문장도 우리가 원하는 대로 실행하지 않는다.
if (str1 == "abc")잘 알겠지만 "abc"는 문자열 리터럴이다. 따라서 위 문장의 의미는 " str1 문자열의 메모리 상의 (시작)주소값과 abc 라는 문자열 리터럴이 보관된 메모리 상의 주소값을 비교해라"라는 의미이기 때문에 절대로 우리가 원하는 " str1 와 abc 를 비교한다" 라는 뜻을 가질 수 없다.
가장 짜증나는 문제는 문자열을 우리가 원하는 대로도 복사할 수 없다는 것이다. 다시말해 int 형 변수처럼 원하는 값을 "대입" 할 수 없다는 것이다. 만일 우리가
str1 = str2;라는 문장을 사용한다면 " str2 의 값을 str1 에 대입해라" 라는 의미인데 역시 str1 의 값은 바뀔 수 없는 포인터 상수 이기 때문에 오류가 발생한다. 따라서 이와 같이 문자열을 다루는데는 제약이 너무나도 많다. 그러나 다행이도 함수를 이용하면 그나마 편하게 다룰 수 있다.
일단 위와 같은 제약들을 바탕으로 문자열들을 자유롭게 다루려면 다음과 같은 함수들이 필요하다.
- 문자열 내의 총 문자의 수를 세는 함수
- 문자열을 복사하는 함수
- 문자열을 합치는 함수(더하는)
- 문자열을 비교하는 함수
위의 함수들을 모두 구현해볼건데 맨 첫번째 함수는 이전에 위에서 구현한 적이 있기 때문에 생략하겠다.
문자열을 복사하는 함수
문자열을 복사하는 함수는 어떻게 하면 만들 수 있을까? 우리가 무언가 작업하는 함수를 만들기 전에 반드시 고려해야 하는 사항들은 다음과 같다.
- 이 함수는 무슨 작업을 하는가? (자세할 수록 좋다.)
- 함수의 리턴형이 무엇이 좋을까?
- 함수의 인자로는 무엇을 받아야 할까?
특히 ① 번에 경우 매우 중요하다. "무슨 함수를 만들어야 겠다"라고 정의하지 않고 무턱대고 만들다 보면 소스 코드가 상당히 난잡해지고 이해하기 힘들게 된다.
우리의 경우 ① 번은 말 그대로 문자열을 복사하는 함수, 즉 a 라는 문자열이 있으면 a 문자열의 모든 내용을 b 로 복사하는 함수이다.
두번째로 함수의 리턴형은 무엇이 좋을까? 한번 생각해보자 필자의 경우는 복사가 성공적으로 완료되면 1을 리턴하도록 만들고 싶다. 즉 int 형 함수를 만들 것이다.
세번째로 함수의 인자형에 대해서 생각해보자. 당연히 두개의 문자열을 받아야 하므로 포인터를 인자로 받아야 할 것이다. 이 때 문자열들은 char 형 배열이기 때문에 char * 을 인자로 2개 가지는 함수를 만들 것이다.
/*
int copy_str(char *dest, char *src);
src 의 문자열을 dest 로 복사한다. 단, dest 의 크기가 반드시 src 보다 커야 한다.
*/
int copy_str(char *dest, char *src) {
while (*src) {
*dest = *src;
src++; // 그 다음 문자를 가리킨다.
dest++;
}
*dest = '\0';
return 1;
}위 함수를 활용해서 함수를 만들어보자.
#include <stdio.h>
int copy_str(char *src, char *dest);
int main() {
char str1[] = "hello";
char str2[] = "hi";
printf("복사 이전 : %s \n", str1);
copy_str(str1, str2);
printf("복사 이후 : %s \n ", str1);
return 0;
}
int copy_str(char *dest, char *src) {
while (*src) {
*dest = *src;
src++;
dest++;
}
*dest = '\0';
return 1;
}실행 결과
복사 이전 : hello
복사 이후 : hi위를 이해하는데 수월할 것이다. 그래도 혹시 모르니 다음 부분만 확인해보자
while (*src) {
*dest = *src;
src++;
dest++;
}while 의 조건이 *src 이다. 문자열을 다룰때 많이 사용하는 방법인데, NULL 문자의 값이 0이기 때문에 *src 의 값이 NULL 문자에 도달하기 전까지 반복문이 반복된다. (문자열의 마지막은 NULL 값이기 때문이다)
그리고 *dest = *src; 를 통해서 src 의 문자를 dest 에 대입하였다. 그리고 각각 1식 더했는데 포인터 연산에서 1을 더하는 것은 주소값에 단순히 1을 더하는게 아니라 포인터가 가리키는 타입의 크기를 곱한 만큼 더해진다는 사실, 즉 다시말해서 배열의 그 다음 원소를 가리킬 수 있다는 사실을 기억할 것이다.(모르면 꼭 복습하자)
*dest = '\0';그리고 마지막에 dest 에 '\0' 즉, NULL 문자를 집어 넣었다. 위의 조건문에서 src 가 NULL 이 된다면 while 문이 종료되었기 때문에 마지막에 널값을 dest 에 넣을 틈이 없었는데 마지막 처럼 처리하므로써 마지막에 널값을 넣어주었다.
cf. 단순하게 배열에 문자열 대입이 안되는 이유
그런데 여기까지 하면서 아마도 굳이 함수로 만들어야 하나 의문이 들 수 있다. 그런 사람들을 위해 다음을 보자.
char str[100];
str = "abcdefg"; /* str 에 abcdefg 가 복사되지 않을까? */컴파일 오류
error C2106: '=' : 왼쪽 피연산자는 l-value이어야 합니다.
이렇게 하면 컴파일 오류가 발생한다. 왜그럴까? 아마도 리터럴과 배열에 대해서 완전히 이해한 사람은 이해 할 수 있을 것이다. 일단 str = "abcdefg" 라는 문장은 str 에 문자열 리터럴 abcdefg 가 위치한 곳의 주소값을 넣어라는 의미이다. 그런데 이전에 배열에 대해 공부한 바로는 배열의 이름은 포인터 상수이다. 즉, 배열의 주소값을 바꿀 수 없다는 의미이다.
따라서 위 코드는 상수에 값을 대입하기 떄문에 오류가 발생한다.
char str[100] = "abcdefg";그런데 위는 왜 문제가 없을까? 이는 단순히 C언어에서 사용자의 편의를 위해서 제공하는 방법이라고 생각하면 된다. 오직 정의 부분에서만 사용할 수 있다.기억해라! 오직 배열의 정의에서만 위 방법을 사용할 수 있다. 위처럼 하면 str 의 각 원소에 a 부터 g 까지 들어가게 된다.
문자열을 합치는 함수
문자열을 합치는 함수는 다음과 같다.
char str1[100] = "hello my name is ";
char str2[] = "TACAN";
stradd(str1, str2);
// str1 은 "hello my name is TACAN" 가 된다.한 번 스스로 만들어보자.
완성된 코드는 아래와 같다.
/*
stradd 함수
dest 에 src 문자열을 끝에 붙인다.
이 때 dest 문자열의 크기를 검사하지 않으므로 src 가 들어갈 수 있는 충분한 크기가
있어야 한다.
*/
int stradd(char *dest, char *src) {
/* dest 의 끝 부분을 찾는다.*/
while (*dest) {
dest++;
}
/*
while 문을 지나고 나면 dest 는 dest 문자열의 NULL 문자를 가리키고 있게 된다.
이제 src 의 문자열들을 dest 의 NULL 문자 있는 곳 부터 복사해넣는다.
*/
while (*src) {
*dest = *src;
src++;
dest++;
}
/* 마지막으로 dest 에 NULL 추가 (왜냐하면 src 에서 NULL 이 추가 되지
* 않았으므로) */
*dest = '\0';
return 1;
}위 함수를 써먹자
#include <stdio.h>
int stradd(char *dest, char *src);
int main() {
char str1[100] = "hello my name is ";
char str2[] = "TACAN";
printf("합치기 이전 : %s \n", str1);
stradd(str1, str2);
printf("합친 이후 : %s \n", str1);
return 0;
}
int stradd(char *dest, char *src) {
/* dest 의 끝 부분을 찾는다.*/
while (*dest) {
dest++;
}
/*
while 문을 지나고 나면 dest 는 dest 문자열의 NULL 문자를 가리키고 있게 된다.
이제 src 의 문자열들을 dest 의 NULL 문자 있는 곳 부터 복사해넣는다.
*/
while (*src) {
*dest = *src;
src++;
dest++;
}
/* 마지막으로 dest 에 NULL 추가 (왜냐하면 src 에서 NULL 이 추가 되지
* 않았으므로) */
*dest = '\0';
return 1;
}실행 결과
합치기 이전 : hello my name is
합친 이후 : hello my name is TACAN이와 같이 무사히 출력이 된다. 위 함수는 간단하다.
while (*dest) {
dest++;
}이와 같이 해서 먼저 dest 의 끝부분에 도달한 다음에 거기에서 부터
while (*src) {
*dest = *src;
src++;
dest++;
}src 가 끝 부분에 도달할 때 까지 추가해주는 것이다.
*dest = '\0';그리고 마지막에 널값을 넣어준다.
문자열을 비교하는 함수
이 함수는 다음과 같은 작업을 하는 함수를 말한다.
if (compare(str1, str2)) {
/*
만일 str1 과 str2 가 같다면 이 부분이 실행되고 아니면 지나갑니다.
참고로 if 문에서 0 이 아닌 값만 들어가면 무조건 참으로 처리되는 사실은 알고
계시죠?
*/
}한 번 스스로 만들어보자.
완성된 소스 코드는 다음과 같다.
int compare(char *str1, char *str2) {
while (*str1) {
if (*str1 != *str2) {
return 0;
}
str1++;
str2++;
}
if (*str2 == '\0') return 1;
return 0;
}위 함수를 써먹어 보자
#include <stdio.h>
int compare(char *str1, char *str2);
int main() {
char str[20] = "hello every1";
char str2[20] = "hello everyone";
char str3[20] = "hello every1 hi";
char str4[20] = "hello every1";
if (compare(str, str2)) {
printf("%s 와 %s 는 같다 \n", str, str2);
} else {
printf("%s 와 %s 는 다르다 \n", str, str2);
}
if (compare(str, str3)) {
printf("%s 와 %s 는 같다 \n", str, str3);
} else {
printf("%s 와 %s 는 다르다 \n", str, str3);
}
if (compare(str, str4)) {
printf("%s 와 %s 는 같다 \n", str, str4);
} else {
printf("%s 와 %s 는 다르다 \n", str, str4);
}
return 0;
}
int compare(char *str1, char *str2) {
while (*str1) {
if (*str1 != *str2) {
return 0;
}
str1++;
str2++;
}
if (*str2 == '\0') return 1;
return 0;
}실행 결과
hello every1 와 hello everyone 는 다르다
hello every1 와 hello every1 hi 는 다르다
hello every1 와 hello every1 는 같다위 함수를 이해하는데 큰 어려움은 없을 거지만 조금만 살펴보면
while (*str1) {
if (*str1 != *str2) {
return 0;
}
str1++;
str2++;
}반복문에서 str1 이 끝날 때 까지 두 문자열이 같은지 확인하고 틀린 부분이 있으면 바로 0을 리턴한다. 만약 0이 리턴되면 if 구문은 실행이 안되고 두 문자열이 다르다고 출력할 것이다.
if (*str2 == '\0') return 1;만약 반복문을 무사히 건너가면 마지막으로 str1 의 끝부분과 str2 의 끝부분이 같은지 확인하여 진짜로 두 문자열이 같은지 확인한다.
여기까지 함수를 만들어 보았다 문자열 함수를 가지고 문자열들을 적절히 가지고 노는 건 각자의 노력이다. 부디 이러한 함수들를 가지고 문자열을 재미있는 문자열 프로그램을 만들어보기를 권한다.
