Pandas 소개
Pandas는 데이터 분석 및 조작을 위한 파이썬 라이브러리이다
Numpy를 기반으로 개발되어 다양한 형태의 데이터를 처리할 수 있으며, 특히 표 형태의 데이터를 다루기 유리하다.
Pandas의 핵심 데이터 구조는 Series와 DataFrame이다. Series는 1차원 배열과 유사한 구조이며, 엑셀의 열을 의미한다. DataFrame은 2차원 테이블 형태의 데이터 구조이고, 엑셀에서 보는 화면을 의미한다.
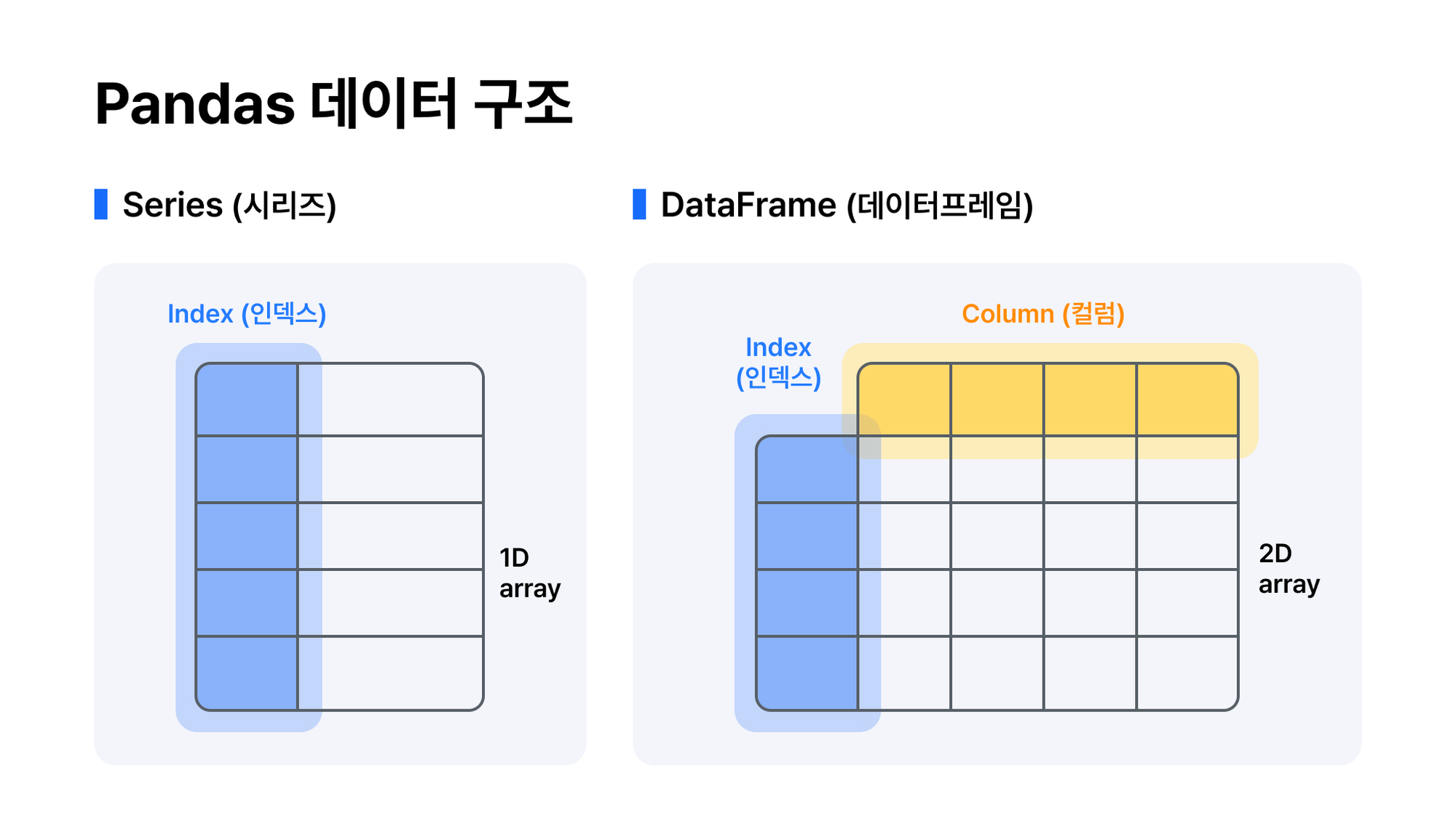
데이터 프레임 생성 예시
import pandas as pd
# 딕셔너리 형태로 가져온다.
data = {'이름': ['홍길동', '임꺽정', '이순신'],
'나이': [30, 35, 40],
'도시': ['서울', '부산', '광주']}
# DataFrame 함수 활용
df = pd.DataFrame(data)시리즈 생성 예시
import pandas as pd
names = pd.Series(['홍길동', '임꺽정', '이순신'])csv파일 읽어오기
import pandas as pd
df = pd.read_csv("/content/sample_data/california_housing_train.csv")위의 코드는 코랩에 기본으로 있는 캘리포니아 집값에 대한 csv파일을 불러온다.
head와 tail
df.head()
df.tail() head()로는 데이터의 상위 5개행, tail()로는 하위 5개행을 파악할 수 있다. 이를 통해, 데이터를 빠르게 점검할 수 있고 요구정의서/칼럼에 대한 히스토리(의미)를 파악한 뒤에 봐야 확실하게 이해할 수 있다.
info
데이터프레임의 요약된 정보를 보고 싶다면 info함수를 사용하면 된다.
df.info()info함수를 통해 Null값이 존재함을 확인한다면 이 Null값을 최대한 제거하고 분석하는 것이 좋다고 한다. 왜냐하면 Null값이 있으면 머신러닝/딥러닝 모델의 대부분을 돌리지 못하고 임의의 값으로 치환한다면 데이터의 신뢰성에 문제가 생긴다. 따라서 Null값은 최대한 제거하되, 그 전에 Null을 포함한 데이터가 다른 데이터와 어떻게 다른지 파악하고 제거하도록 하자.
describe
데이터프레임의 통계적 요약 정보를 확인하고자 할 때에 쓰인다.
- Min / Max -> 999999 / -999999 / *** 등의 이상한 문자로 된 값을 파악하는데 사용
- Mean -> 평균이 내가 아는 수치와 비슷한지 확인
- 25% 50% 75% -> 데이터가 편중되어 있는지 or 잘 분포되어 있는지 확인한다. 표준편차를 보는 것.
간단한 예시로, 1 1 1 1 1 1 1 1 2 3 4 5라는 어플 사용량이 있을 때, 이러한 경우를 확인하기 위해 분위값을 본다.
df.describe()inplace
df = df.dropna()
df.dropna(inplace=True)inplace=True옵션을 주어, 수정된 값이 원본에 반영되도록 한다.(기본 옵션은 False로 원본은 바뀌지 않는다)
결측치 제거
import pandas as pd
import numpy as np
data = {'이름': ['홍길동', '임꺽정', None],
'나이': [30, None, 40],
'도시': ['서울', '부산', '광주']}
df = pd.DataFrame(data)
# 결측치가 포함된 데이터프레임 출력
print("원본 데이터프레임:\n", df)위와 같은 data가 있다고 한다. 여기서 문자형 데이터는 describe()에서 통계량이 나오지 않음을 기억하자. count()는 사용할 수 있다.
# 결측치 제거
df.dropna(inplace=True)
# 결측치가 제거된 데이터프레임 출력
print("\n결측치 제거 후 데이터프레임:\n", df)위 코드를 통해 None값이 속해있지 않은 데이터가 출력된다.
데이터프레임 / 시리즈
데이터프레임 선언은 다음과 같다.
import pandas as pd
df = pd.DataFrame({
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'City': ['New York', 'Paris', 'Berlin']
})df라는 데이터프레임을 선언해주었다. 이후, df의 각 속성을 알아보도록 하자.
shape
print("Shape:", df.shape)
# (3,3)shape 메서드는 데이터가 몇행 몇열인지 알려준다. 보기에서는 3행 3열이라고 출력된다.
dtype
print("Data Types:\n", df.dtypes)타입은 df변수안의 원소들이 어떤 자료형인지 보여준다. 문자는 object라고 나옴을 확인하였다.
index
print("Index:", df.index)
# Index: RangeIndex(start=0, stop=3, step=1)인덱스는 0부터 3이전까지 1씩 증가한다고 나온다. 즉, 0, 1, 2 이다.
astype
처음에는 문자형으로 된 value값이라 하더라도 astype 함수를 통해 형변환이 가능하다.
import pandas as pd
# 예시 데이터프레임 생성
data = {
'Name': ['Alice', 'Bob'], # 문자열 타입
'Age': ['25', '30'], # 숫자 데이터를 문자열로 표현
'Member': ['True', 'False'], # 불린 데이터를 문자열로 표현
'Join Date': ['2021-01-01', '2021-07-01'] # 날짜 데이터를 문자열로 표현
}
# DB -> 문자열로 저장하면 메모리 / 저장용량 효율적
df = pd.DataFrame(data)
# 데이터 타입 변환
df['Age'] = df['Age'].astype(int) # 'Age' 열을 정수형으로 변환
df['Member'] = df['Member'].astype(bool) # 'Member' 열을 불린형으로 변환
df['Join Date'] = pd.to_datetime(df['Join Date']) # 'Join Date' 열을 datetime으로 변환
# 결과 출력
print(df)
print(df.dtypes)시간을 변경할때만 to_datetime()함수를 사용하고 나머지 형태는 astype() 함수로 변경이 가능하다. 추가로 알아두면 좋은 정보는 DB에 문자열로 저장하면 메모리 / 저장용량 측면에서 효율적이라고 한다.
위와 같은 데이터프레임 형태의 데이터를 선언했다고 하더라도 이 중, 1가지 목록만 가져온다면 Series 형태로 가져오게 된다.
df_joindate = df['Join Date']
df_joindate
# Name: Join Date, dtype: datetime64[ns]df_joindate.info()
<class 'pandas.core.series.Series'>2가지 목록을 가져온다면 데이터 프레임 형태이다.
df_joindate = df[['Join Date', 'Age']]
df_joindate.info()
# <class 'pandas.core.frame.DataFrame'>loc, iloc
loc[행이름, 열이름]로 내가 원하는 이름의 행과 열에 접근할 수 있다.
import pandas as pd
import numpy as np
# 예시 데이터프레임 생성
data = {
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'City': ['New York', 'Paris', 'Berlin']
}
df = pd.DataFrame(data)
# 단일 열 선택 -> 결과는 Series
age_series = df['Age']
print(type(age_series))
# 다중 열 선택 -> 결과는 DataFrame
subset_df = df[['Name', 'City']]
print(type(subset_df))
# loc 사용 예시
# [행 / 열]
print(df.loc[:, 'Age'])
# iloc 사용 예시
print(df.iloc[:, 1])
# 결측치 추가
df.loc[1, 'Age'] = np.nan
# 결측치 확인
print(df['Age'].isnull())이를 활용하여 결측치 추가, 제거, 특정 행/열에 접근 등을 할 수 있다.
Series 메서드
# Series 메서드 활용
import pandas as pd
# Series 생성
data = pd.Series([10, 20, 20, 30, 40])
# sum(), mean(), value_counts() 사용 예시
print("Sum:", data.sum()) # 합계
print("Mean:", data.mean()) # 평균
print("Value Counts:\n", data.value_counts()) # 빈도 계산import pandas as pd
# Series 생성
data = pd.Series([10, 15, 20, 25, 30])
# 다양한 메서드 활용
print("Minimum:", data.min()) # 최소값
print("Maximum:", data.max()) # 최대값
print("Standard Deviation:", data.std()) # 표준편차
print("Variance:", data.var()) # 분산
print("Number of Unique Values:", data.nunique()) # 고유값 개수
# 데이터프레임 요약
df = pd.DataFrame({
'Age': [25, 30, 35, 40, 45],
'Salary': [50000, 55000, 60000, 65000, 70000]
})
print("\nDataFrame Summary:\n", df.describe())
print("\nDataFrame Info:")
df.info()위의 예시들처럼 Series 객체의 합계, 평균, 최소, 최대, 분산, 고유값 개수 등을 확인할 수 있다.
각 요소별 연산
데이터프레임 각 요소에 사칙연산, 불린연산 등을 할 수 있다.
# 실습!
test = pd.read_csv("/content/sample_data/california_housing_train.csv")
test
# 데이터프레임의 'housing_median_age' 열을 Series로 변환하고 숫자형으로 변환
test_series = test['housing_median_age']# 각 요소에 2 곱하기
test_times_two = test_series * 2
test_times_two# 불린 연산이 가능하다 -> 해당하는 값만 가져올 수 있다.
high_age = test_series > 17.0
high_age.head()# 조건을 만족하는 요소만 필터링
filtered_series = test_series[high_age]
filtered_series.head()rename, columns
rename, columns 메서드로 열의 이름을 변경 가능하다. 일반적으로 rename을 권장한다고 한다.
import pandas as pd
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]
})
# 열 이름 변경
# columns({변경하기전 : 변경한 후, 변경하기전 : 변경한 후})
df = df.rename(columns={'A': 'X', 'B': 'Y', 'C': 'Z'})
print(df)# 모든 열 이름 변경
df.columns = ['X', 'Y', 'Z']
print(df)새로운 열 추가
df라는 데이터프레임에 Salary라는 열을 추가하는 코드이다.
import pandas as pd
df = pd.DataFrame({
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35]
})
df['Salary'] = [50000, 60000, 70000] 일반적으로 많이 사용하지는 않고 데이터 결합시에 concat이나 join을 많이 쓴다고 한다.
drop
drop이라는 메서드로 특정 행/열을 삭제 가능하다. 이는 머신러닝 / 딥러닝 등에서 분석에 필요한 변수만 가져올 때 사용한다. axis=1이라 하면 열/컬럼을 제거하고 axis=0(기본값)을 사용하면 행을 삭제한다.
df = df.drop('Age', axis=1) # axis=1 열/컬럼 (주의)
print(df)concat
서로 다른 데이터프레임을 연결할 수 있다.
# Sample DataFrames
df1 = pd.DataFrame({'A': [1, 2], 'B': [3, 4]})
df2 = pd.DataFrame({'A': [5, 6], 'B': [7, 8]})
# 가로로 연결 (열 방향)
result = pd.concat([df1, df2], axis=1)
print(result)
# A B A B
# 0 1 3 5 7
# 1 2 4 6 8axis를 1로 주면 가로로 연결(열 방향)하며 0이면 세로로 연결한다.(기본값)
EDA
EDA의 진행과정은 다음과 같다!
# 1. 조건에 대해서 / 내가 무엇을 할지에 대해서 잘 정의하는 것이 중요
# 2. 이 중에서 반복작업을 하는게 무엇이 있는가?
# -> 대시보드를 만들어 자동 업데이트 할 수도
# -> 반복문/함수로 프로그램화 해도 가능
# 3. 반복이 되면 패턴이 보임
# -> 패턴을 가지고 EDA를 추가적으로 진행해 해당 패턴이 왜 발생했는가?
# 모델 생성
다음과 같은 데이터셋이 있다.
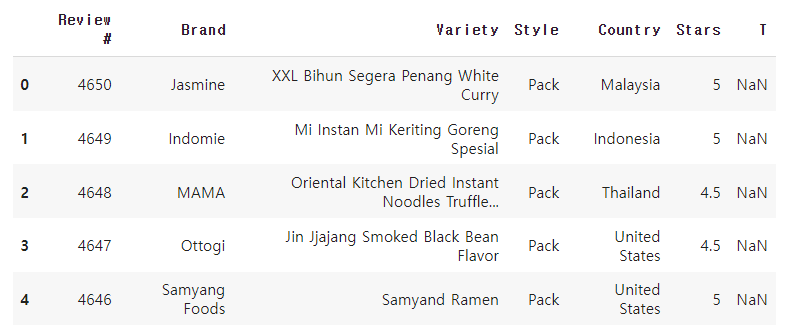
info로 찍은 정보는 다음과 같다.
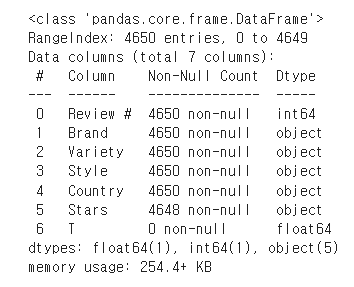
describe정보는 다음과 같다.
value_counts
이 데이터셋의 Brand칼럼의 값을 세어 보자.
dataset['Brand'].value_counts()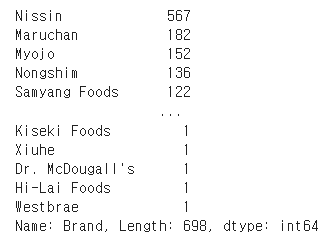
고유값 확인
# 고유값 확인 -> 중복되지 않는 값!
dataset.nunique()
결측치 제거
# True = 1 False = 0
print(dataset.isnull().sum()) # null의 갯수가 sum
T칼럼과 Stars칼럼에 결측치 개수를 확인하였다.
열 삭제
# 'T' 열 삭제
dataset = dataset.drop('T', axis=1)# Starts의 결측치 2개도 삭제
dataset = dataset.dropna()Stars 칼럼의 숫자들은 문자형이므로 형변환후 describe 적용
# 문자형을 숫자로 변경하는 방법 1. astype 2. to_numeric
dataset['Stars'] = pd.to_numeric(dataset['Stars'], errors='coerce')결측치가 제거된 데이터는 다음과 같다.
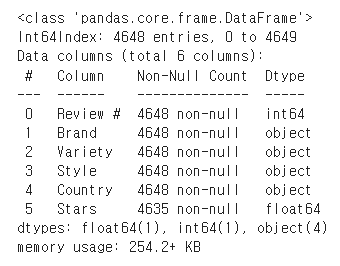
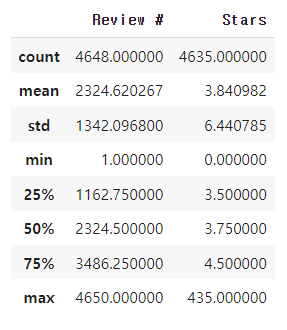
IQR 기준 이상치 제거
# IQR 기반 이상치 제거
Q1 = dataset['Stars'].quantile(0.25)
Q3 = dataset['Stars'].quantile(0.75)
IQR = Q3 - Q1
dataset = dataset[~((dataset['Stars'] < (Q1 - 1.5 * IQR)) | (dataset['Stars'] > (Q3 + 1.5 * IQR)))]위의 과정을 거치면 Starts 칼럼은 다음과 같다.

중복 데이터 제거
# 중복 데이터 확인 - duplicated()
duplicates_count = df.duplicated().sum()
print(duplicates_count)# 전체 데이터에 대한 중복 제거
df = df.drop_duplicates()# 특정 컬럼에 대한 중복 제거
# 예: 'Brand' 컬럼 기준 중복 제거
df = df.drop_duplicates(subset=['Brand'])박스플롯으로 확인하는 이상치
dataset = pd.read_csv('/content/The-Big-List-20231127-Reviews-to-4650.csv', encoding='latin1') # 인코딩이 필요한 경우 변경
# 'Stars' 컬럼의 비숫자 값을 NaN으로 변환
dataset['Stars'] = pd.to_numeric(dataset['Stars'], errors='coerce')
# NaN 값 제거
dataset = dataset.dropna(subset=['Stars'])
# 'Stars' 컬럼에 대한 박스플롯 생성
plt.boxplot(dataset['Stars'])
plt.title('Boxplot of Stars Ratings')
plt.ylim(1, 5) # y축 범위를 1에서 5로 설정
plt.show()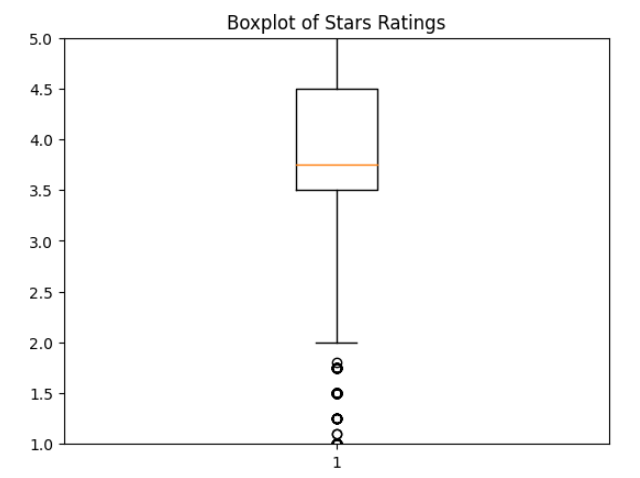
피드백
이번 연도에 학교다닐때 데이터분석 부분만 1학기는 들었던 것 같은데 이걸 하루안에 하기는 확실히 쉽지 않다. 강사님은 그 분야의 전문가니까 어찌어찌 배우긴 했는데 부족하니 스스로 좀더 해보라고 하셨다 ㅎㅎ. 하지만, 나는 백엔드 개발자를 목표로 하기에 가볍게만 보고 넘어가고 추후에 나오면 다시 찾아보도록 하겠다. 내일은 머신러닝 수업을 한다고 했는데 두렵다.
