사람이 일하면 러닝머신, 기계가 일하면 머신러닝
머신러닝의 큰 틀에 맞춰 유명한 데이터 예제인 타이타닉 데이터를 분석해보았다.
1. 데이터 추가
from sklearn.datasets import fetch_openml
# fetch_openml을 사용하여 타이타닉 데이터셋 불러오기
titanic = fetch_openml('titanic', version=1, as_frame=True)
# 데이터 프레임으로 변환
titanic_data = titanic.frame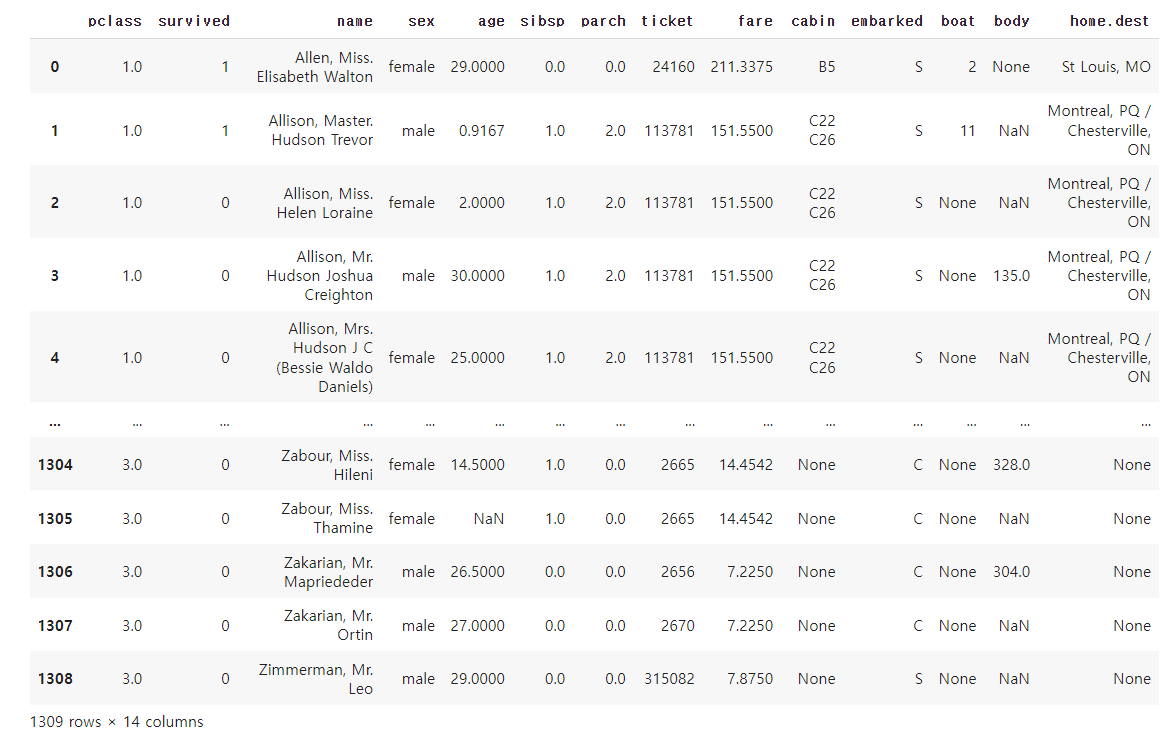
1309행 14개의 칼럼으로 이루어져 있다.
2. 데이터 확인
# 데이터의 처음 5행을 출력하여 데이터를 본다.
print(titanic_data.head())
# 데이터셋의 통계적 요약을 출력
print(titanic_data.describe())
# 결측치가 있는지 확인
print(titanic_data.isnull().sum())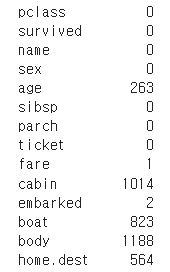
null값의 합을 구해 결측치가 존재함을 확인하였다.
3. 데이터 전처리
3.1 결측치 처리
import pandas as pd
# ['age']변수의 평균값으로 null값을 채워라
titanic_data['age'].fillna(titanic_data['age'].mean(), inplace=True)
# 머신러닝에서는 최대한 숫자로 쓰는게 좋다. map으로 변경
titanic_data['sex'] = titanic_data['sex'].map({'male': 0, 'female': 1})
# 불필요한 열 제거
titanic_data = titanic_data.drop(['name', 'ticket', 'cabin', 'embarked', 'boat', 'body', 'home.dest'], axis=1)위의 사진에서 결측치가 존재하는 칼럼을 수정하였다. age칼럼은 평균값(mean)으로 채웠으며, 성별은 원활한 학습을 위해 0과 1로 형변환 해주었다. 그리고 필요하지 않은 칼럼을 제거하는 과정을 거쳤다. 여기서 결측치에 관해 주의깊게 봐야하는데, 무작정 제거하면 데이터의 수가 작아지므로 모델 성능이 감소한다. 반대로 전부 아무값이나 대체했을 경우는 신빙성이 감소한다. 정답 데이터에 결측치가 있다면, 준지도 학습으로 다른 데이터를 기반으로 대체하거나 삭제할지 추정한다.

데이터의 info를 찍어봤을 때 fare칼럼이 1개의 결측치가 존재하므로 평균값을 넣어둔다.
titanic_data['fare'].fillna(titanic_data['fare'].mean(), inplace=True)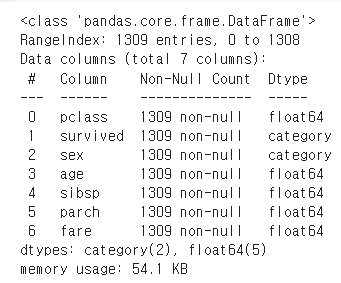
잘 사라진 것을 볼 수 있다.
4. 데이터 분할
from sklearn.model_selection import train_test_split
# 입력 변수와 타겟 변수 분리
X = titanic_data.drop(['survived'], axis=1) # 'survived' 컬럼 제외# X에는 타겟이 있으면 안됨
y = titanic_data['survived'] # 타겟 변수 # y에만 정답이 있어야 한다.
# 데이터 분할: 훈련 세트 80%, 테스트 세트 20%
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # random_state -> 고정된 값으로 분할이 가능앞에서 정제된 데이터를 훈련시킬 데이터와 정답 데이터로 분리하고 특정 % 만큼 분리한다.
5. 알고리즘 선택 - 베이스라인 모델
from sklearn.ensemble import RandomForestClassifier
# 랜덤 포레스트 분류기 인스턴스 준비!
model = RandomForestClassifier(random_state=42)보통 성능이 좋다고 알려진 xgboost나 randomforest 모델을 많이 사용한다고 한다. 여기서 random_state 변수는 지정해주지 않으면 값이 계속 바뀐다고 한다!
6. 학습
model.fit(X_train, y_train)데이터 전처리만 잘 끝낸다면 뒤 과정들은 비교적 쉽게 구현할 수 있다.
7. 예측
# 테스트 데이터를 가지고 predict(예측)한다.
predictions = model.predict(X_test)
예측은 위의 결과처럼 0과 1로 표현이 된다. 이를 알아보기 쉬운 수치로 평가하면 끝이 난다.
8. 평가
실제값과 예측값이 일치하는지 정확도로 판단한다. 물론, 정확도만 맹신하면 안된다.
from sklearn.metrics import accuracy_score
# 실제값과 예측값을 비교
accuracy = accuracy_score(y_test, predictions)
# 두 데이터가 얼마나 일치하는지 점검
print(f"Accuracy: {accuracy}") 보통 학습과 평가간의 정확도 차이가 10% 이상이면 과적합(학습된 데이터만 잘 맞추는 상태)이라고 한다.
평가 이후 스탠스 2가지
- EDA로 돌아가서 처음부터 진행한다. (대부분의 경우)
- 성능에 만족하므로 하이퍼파리미터 튜닝(맨 마지막)
# 중요도 시각화
import matplotlib.pyplot as plt
# 변수 중요도 추출
feature_importances = model.feature_importances_
# 변수 이름과 중요도를 매핑
feature_names = X_train.columns
feature_importance_dict = dict(zip(feature_names, feature_importances))
# 중요도에 따라 변수 정렬
sorted_importance = sorted(feature_importance_dict.items(), key=lambda x: x[1], reverse=True)
# 중요도 시각화
plt.figure(figsize=(10, 8))
plt.barh([item[0] for item in sorted_importance], [item[1] for item in sorted_importance])
plt.xlabel('Importance')
plt.ylabel('Feature')
plt.title('Feature Importances in Random Forest Model')
plt.gca().invert_yaxis() # 높은 중요도가 위로 오게 정렬
plt.show()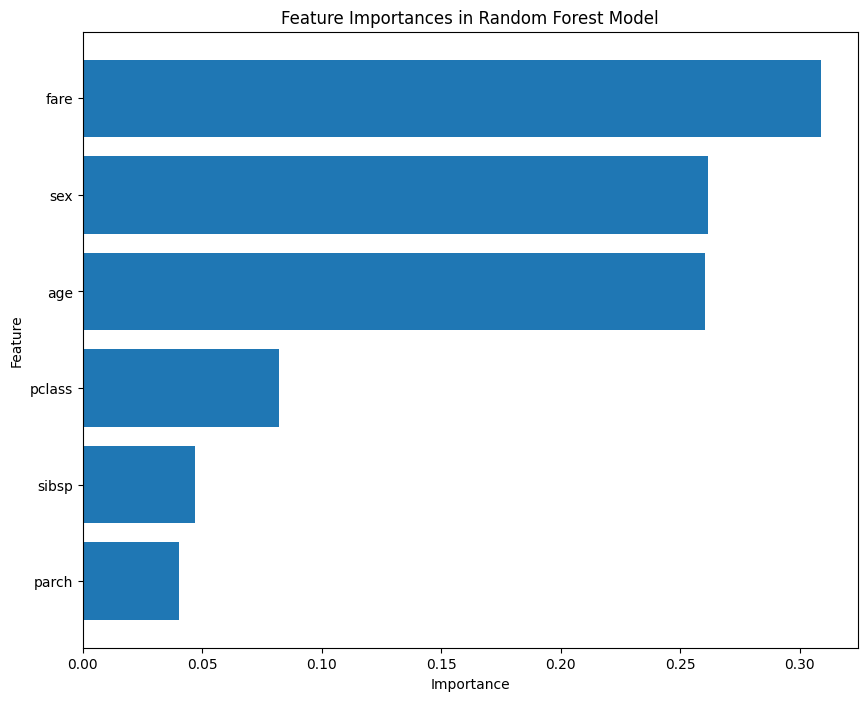
EDA를 더해야 할 필요성이 보인다. 다만 이번 시간에는 추가로 진행하지는 않겠다.
9. 튜닝
from sklearn.model_selection import GridSearchCV
# 모든 경우의 수를 실습해보고 확인하기
param_grid = {'n_estimators': [50, 100, 200], 'max_depth': [5, 10, 20]}
grid_search = GridSearchCV(model, param_grid, cv=5)
grid_search.fit(X_train, y_train)# 테스트 데이터를 가지고 predict(예측)한다.
predictions_grid = grid_search.predict(X_test)from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_test, predictions_grid) #실제값과 예측값을 비교해줘
print(f"Accuracy: {accuracy}") # 두 데이터가 얼마나 일치하는지 점검이렇게 한 사이클이 구성된다고 한다.
