레드 와인 품질이라는 csv파일로 머신러닝 프로세스를 쭉 따라고 보았다.
모델 비교
다양한 모델을 불러와 성능을 비교해보도록 하겠다.
라이브러리 추가
## 기본 패키지 모음
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
## 전처리 및 모델링 준비를 위한 패키지
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.model_selection import train_test_split
## 실제 모델링을 위한 패키지
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn import tree
from sklearn.ensemble import RandomForestClassifier
## 모델 평가를 위한 패키지
from sklearn.metrics import classification_report
from sklearn import metrics파일 불러오기
wine = pd.read_csv('/content/winequality_red.csv')
wine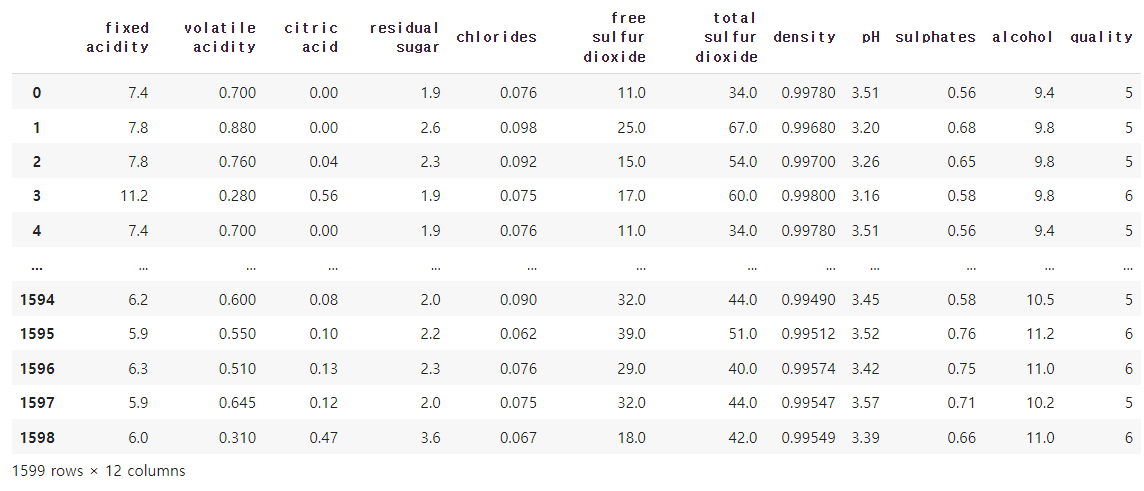
위와 같은 칼럼들로 구성되어 있다.
특성별 데이터 시각화
wine.describe()
wine.isnull().sum()
wine['quality'].unique()
sns.countplot(x='quality', data=wine)
# 특성별도 데이터를 시각화 하여 데이터에 대한 정보를 파악합니다
df1 = wine.select_dtypes([int, float])
for i, col in enumerate(df1.columns):
plt.figure(i)
sns.barplot(x='quality', y =col, data=df1)x축은 품질칼럼으로 고정이고, y축은 나머지 칼럼으로 구성한다.
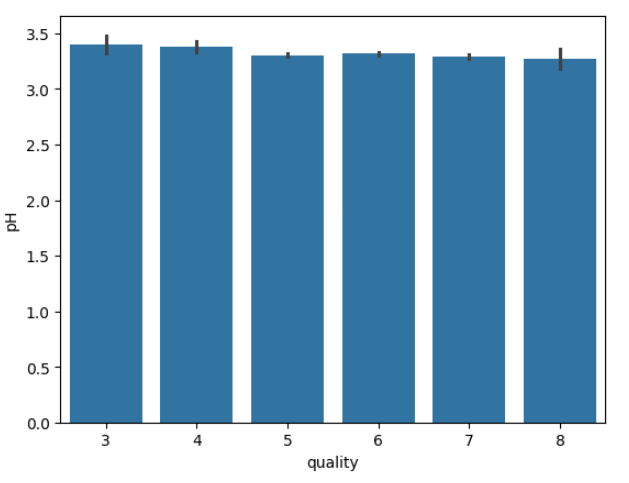
위와 같은 그래프는 각각의 특성이 차이가 거의 없어 좋지 않은 구성이다.
라벨 인코딩
나는 6.5점을 기준으로 와인을 구분하겠다고 선언을 해주었다.
bins = (2, 6.5, 8)
group_names = ['bad', 'good']
wine['quality'] = pd.cut(wine['quality'], bins = bins, labels = group_names)6.5보다 낮으면 0(나쁜 와인), 높으면 1(좋은 와인)으로 구분 목표
label_quality = LabelEncoder()
wine['quality'] = label_quality.fit_transform(wine['quality'])위의 코드에서 bad와 good은 모델이 제대로 인식하지 못하므로 LabelEncoder로 숫자로 바꿔주었다.
종속변수와 독립변수 구분
##종속변수와 독립변수를 나누어주는 작업
x = wine.drop('quality', axis = 1)
y = wine['quality']
## 변수별로 Train과 Test 쓸 데이터 셋을 분류x
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2, random_state = 42)
## 측정 지표의 표준화.
sc = StandardScaler()
x_train = sc.fit_transform(x_train)
x_test = sc.fit_transform(x_test)x(학습데이터)는 최종적으로 예측하고자 하는 품질 칼럼을 제외한 데이터이고 y(테스트데이터)는 정답(품질 칼럼)이 포함된 데이터이다.
학습데이터 : 평가데이터 = 8 : 2로 나누었으며 seed를 고정해주었다. 데이터는 최종적으로 표준화 되었다.

로지스틱 회귀 모델
model = LogisticRegression()
model.fit(x_train, y_train)
y_pred = model.predict(x_test)
print(classification_report(y_test, y_pred))
print("Accuracy:", metrics.accuracy_score(y_test, y_pred))
print("Precision:", metrics.precision_score(y_test, y_pred))
print("Recall:", metrics.recall_score(y_test, y_pred))SVC
model_svc = SVC()
model_svc.fit(x_train, y_train)
y_pred_svc = model_svc.predict(x_test)
print(classification_report(y_test, y_pred_svc))
print("Accuracy:", metrics.accuracy_score(y_test, y_pred_svc))
print("Precision:", metrics.precision_score(y_test, y_pred_svc))
print("Recall:", metrics.recall_score(y_test, y_pred_svc))KNN
model_knn = KNeighborsClassifier(5)
model_knn.fit(x_train, y_train)
y_pred_knn = model_knn.predict(x_test)
print(classification_report(y_test, y_pred_knn))
print("Accuracy:", metrics.accuracy_score(y_test, y_pred_knn))
print("Precision:", metrics.precision_score(y_test, y_pred_knn))
print("Recall:", metrics.recall_score(y_test, y_pred_knn))NB
model_NB = GaussianNB()
model_NB.fit(x_train, y_train)
y_pred_NB = model_NB.predict(x_test)
print(classification_report(y_test, y_pred_NB))
print("Accuracy:", metrics.accuracy_score(y_test, y_pred_NB))
print("Precision:", metrics.precision_score(y_test, y_pred_NB))
print("Recall:", metrics.recall_score(y_test, y_pred_NB))Decision Tree
model_tree = tree.DecisionTreeClassifier()
model_tree.fit(x_train, y_train)
y_pred_tree = model_tree.predict(x_test)
print(classification_report(y_test, y_pred_tree))
print("Accuracy:", metrics.accuracy_score(y_test, y_pred_tree))
print("Precision:", metrics.precision_score(y_test, y_pred_tree))
print("Recall:", metrics.recall_score(y_test, y_pred_tree))RandomForest
model_rfc = RandomForestClassifier(n_estimators=200)
model_rfc.fit(x_train, y_train)
y_pred_rfc = model_rfc.predict(x_test)
print(classification_report(y_test, y_pred_rfc))
print("Accuracy:", metrics.accuracy_score(y_test, y_pred_rfc))
print("Precision:", metrics.precision_score(y_test, y_pred_rfc))
print("Recall:", metrics.recall_score(y_test, y_pred_rfc))모델 성능 비교
print("Logistic Regression Accuracy:", metrics.accuracy_score(y_test, y_pred))
print("Support Vector Machine Accuracy:", metrics.accuracy_score(y_test, y_pred_svc))
print("KNN Accuracy:", metrics.accuracy_score(y_test, y_pred_knn))
print("Gausian NB Accuracy:", metrics.accuracy_score(y_test, y_pred_NB))
print("Decision Tree Accuracy:", metrics.accuracy_score(y_test, y_pred_NB))
print("Random Forest Accuracy:", metrics.accuracy_score(y_test, y_pred_rfc))
acc_df = pd.DataFrame({'classifier':
['Logistic Regression ',
'Support Vector Machine',
'KNN',
'Gausian NB',
'Decision Tree',
'Random Forest'],
'accuracy':
[metrics.accuracy_score(y_test, y_pred),
metrics.accuracy_score(y_test, y_pred_svc),
metrics.accuracy_score(y_test, y_pred_knn),
metrics.accuracy_score(y_test, y_pred_NB),
metrics.accuracy_score(y_test, y_pred_tree),
metrics.accuracy_score(y_test, y_pred_rfc),
]
})
최종적으로 RandomForest가 가장 높은 성능을 보여주었다.
Decision Tree 추가 정리
##종속변수와 독립변수를 나누어주는 작업
x = wine.drop('quality', axis = 1)
y = wine['quality']
## 변수별로 Train과 Test 쓸 데이터 셋을 분류x
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2, random_state = 42)
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(random_state = 2023)
dt.fit(x_train, y_train)
print(dt.score(x_train, y_train))
print(dt.score(x_test, y_test))import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize =(10,7))
plot_tree(dt)
plt.show()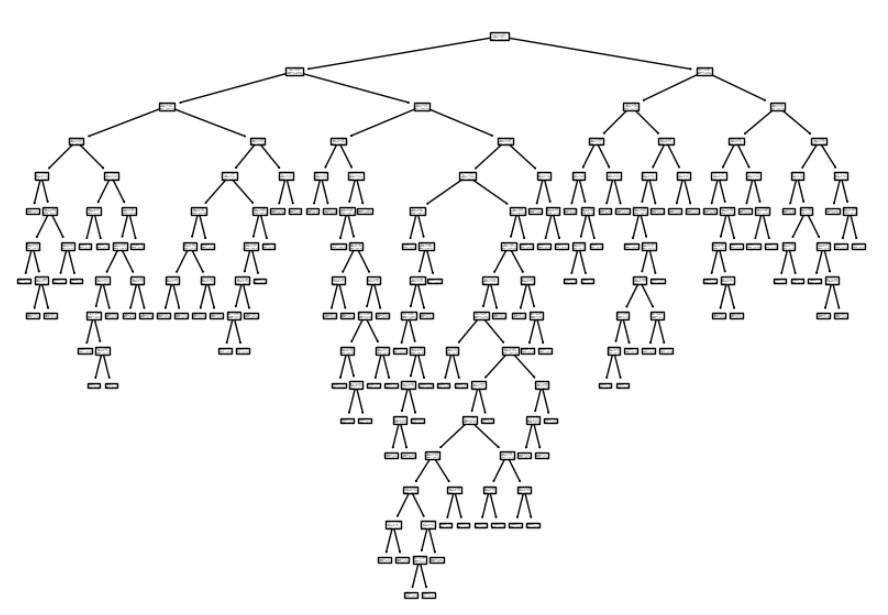
와인 데이터셋에서 트리의 구조는 위와 같으며, 가지수가 너무 많으면 과적합 위험이 있다. 또한, 설명하기도 힘들다.
트리의 가장 윗단만 뜯어서 살펴보자.
plt.figure(figsize =(10,7))
plot_tree(dt, max_depth = 1, filled = True)
plt.show()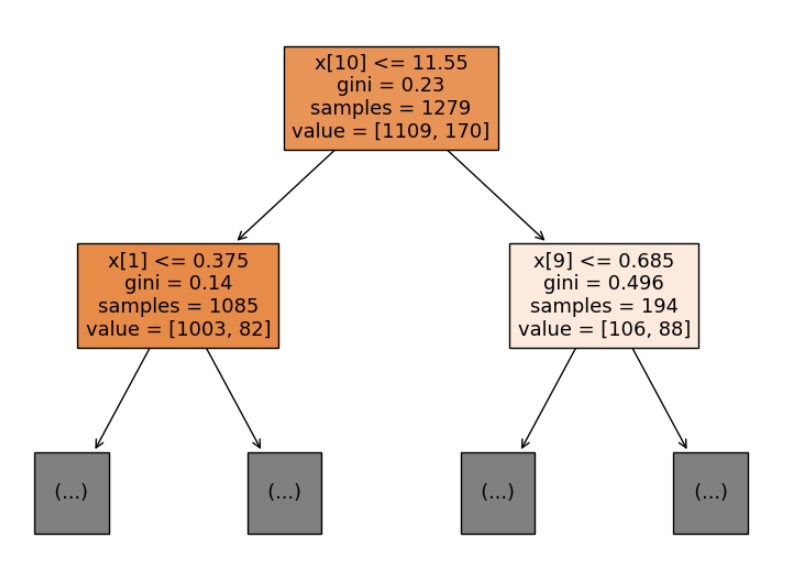
위 그림에서 맨 윗단의 11.55는 알코올지수(칼럼 10번)가 11.55보다 낮은 것들이라는 뜻이다. gini 계수는 해당 노드가 얼마나 잘 분류되었는지를 나타내는 척도로, 순도가 높을수록(0에 가까울수록) 한 클래스의 데이터만 존재하게 된다고 한다. 반대로 1에 가까울수록 노드의 데이터 분포가 균등하다는 뜻이 된다. 결국 트리는 기니 계수가 가장 많이 감소하는(0에 가까운) 분기를 선택한다. samples는 데이터가 총 1279개라는 뜻이고 value의 첫번째 값은 품질 6.5이하인 음료 1109개, 품질 6.5이상인 음료 170개로 구성되있다는 뜻이다.
