기본 개념
로지스틱 회귀분석은 선형 회귀분석과 유사하지만 종속변수가 양적변수가 아닌 2개 또는 다중 변수라고 한다. 즉, 어떤 분류로 들어갈지에 대한 예측도를 보여준다.
구매/미구매, 성공/실패, 합격/불합격 등을 예측할 때 가장 좋으며, 3개 이상인 경우는 잘 사용하지 않는다고 한다.
기존 선형회귀를 따라가되, 종속변수를 1이 될 확률로 변환하여 0과 1의 여부를 예측한다.
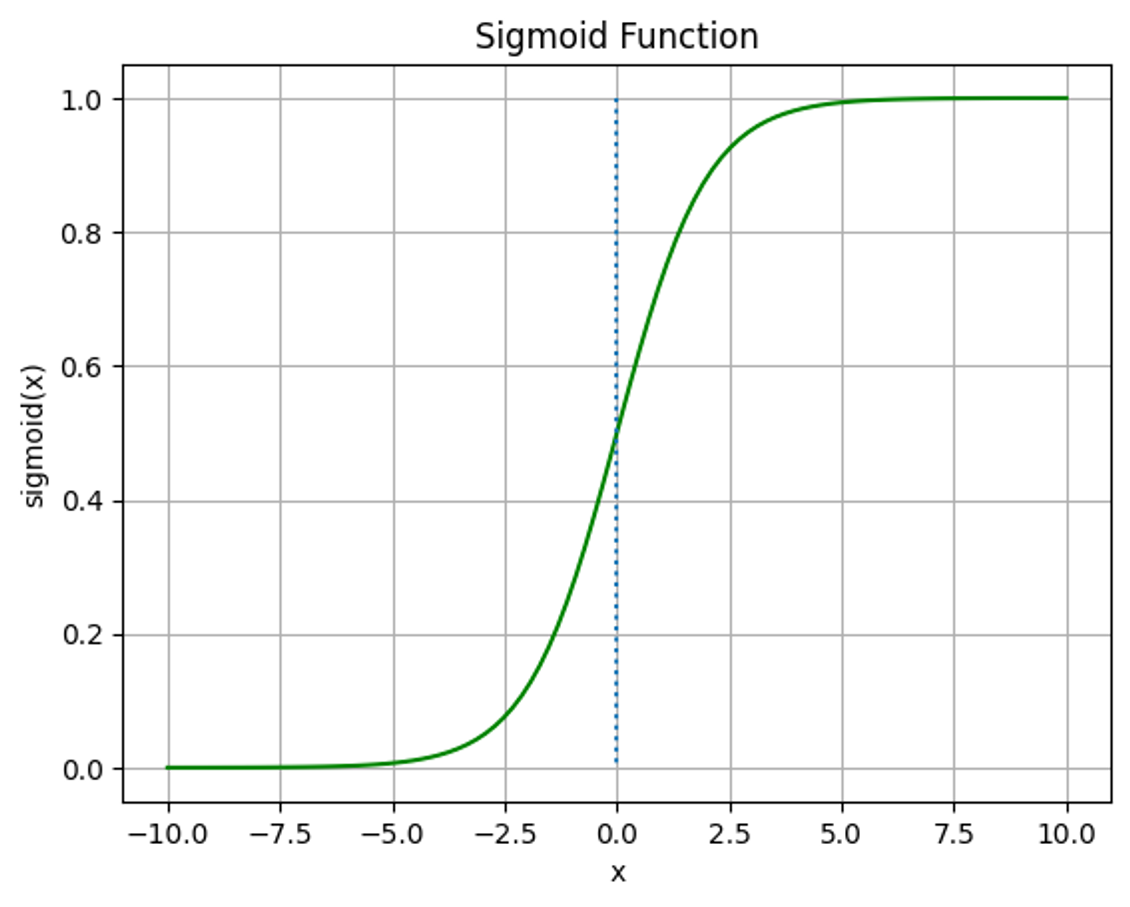
위 사진에서 파란색 선은 변경 가능하다. 이 선을 기준으로 이상이면 1, 이하면 0 이렇게 분류한다.
오즈비
오즈란 사건이 발생할 가능성이 발생하지 않을 가능성보다 어느정도 큰지를 나타내는 값인데 이걸 통해 사람이 업무를 할 때보다 머신러닝 모델이 얼마나 효율을 낼지 알 수 있다고 한다.
사람 4시간 → 머신러닝 정확도 80% → 변수 4.00 → 시간 1시간(4배의 효율)
발생 확률이 그렇지 않을 확률과 50:50으로 같으면 1.0으로 차이가 없는 것이고, 두배면 2.0, 다섯배면 5.0이 된다. 수식으로 나타내면 다음과 같다.
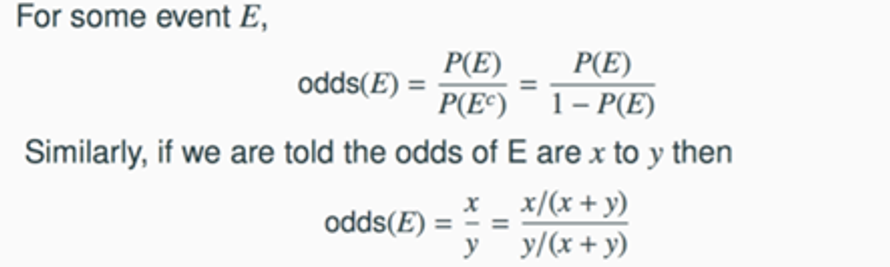
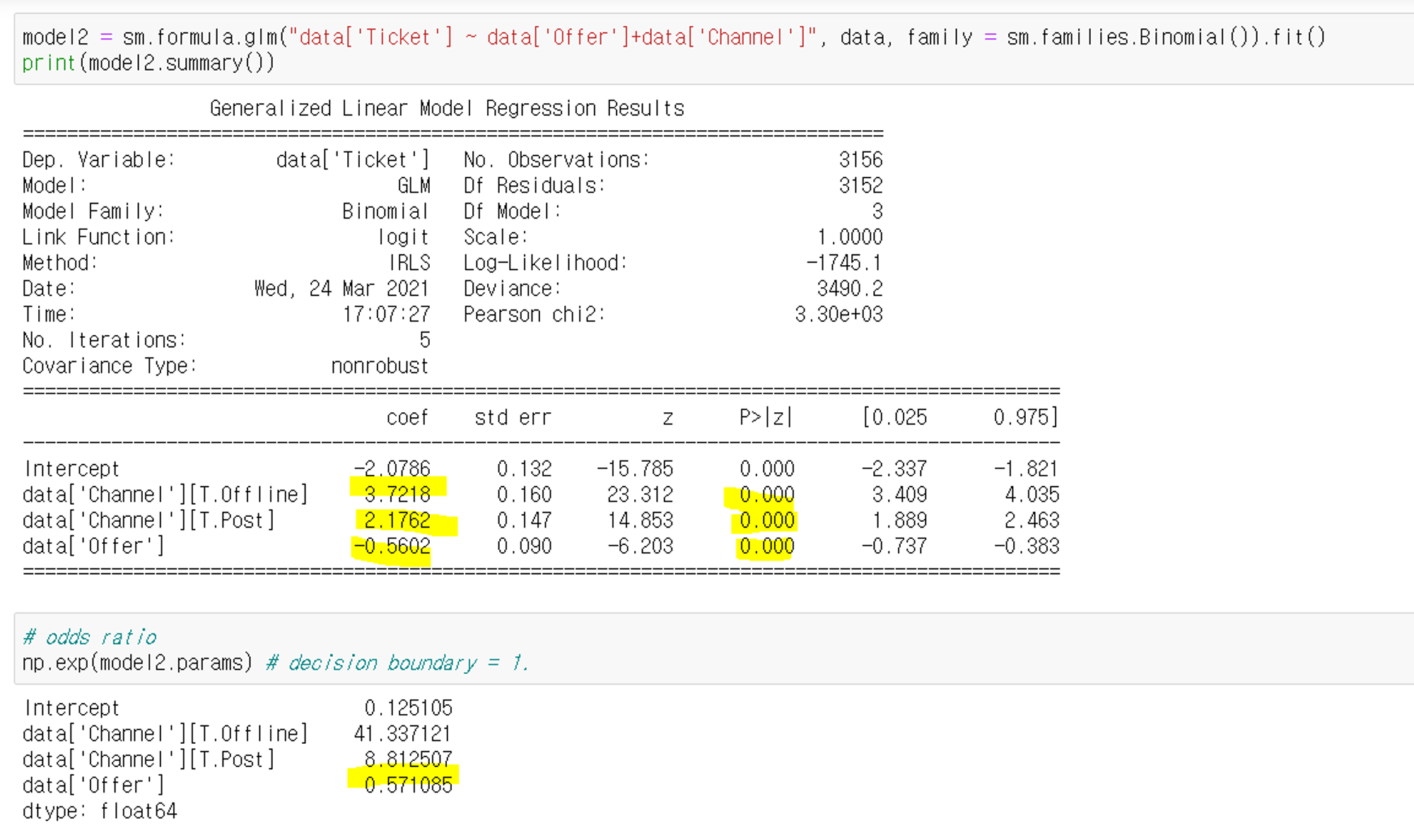
위의 사진에서 p값도 중요한데 p값이 0.05보다 작아야 의미있는 데이터라고 한다. 그리고, 오즈비가 41이라는 얘기는 기준인 이메일보다 41배 가량 더 효과적이란 이야기이다.
실습
개인 대출 csv파일로 로지스틱 회귀를 살펴보았다. 내용이 많지만 통계쪽 지식이 별로 없어서 이해하기 어려웠기에 이정도만 하고 넘어가도록 하겠다. 판다스와 마찬가지로 부딪히면 그때그때 찾아보는 걸로 하겠다.
피드백
오전에는 모두의 연구소 소장님이 인공지능의 역사와 발전과정, 앞으로 어떻게 대처해야 할지에 대해 설명해주셨다. 현재 소프트웨어의 발전은 빠르지만 하드웨어는 비교적 느린 부분이 있는데 만약 더욱 발전해서 인공지능과 합쳐진다면 그때는 좋은 세상이라고 할 수 있을까? 인공지능은 좋은 도구? 이지만 무서운 면도 존재하는 것 같다.
소장님의 특강을 듣고 머신러닝부분을 짧은 시간이지만 훑어 봤는데 쉽지 않다. 머신러닝 프로세스는 대략적이나마 이해가 된 것 같고 선형회귀부터 애매해지더니 로지스틱은 음 필요성 정도만 이해하고 넘어가기로 하였다. 강사님도 이렇게 짧은 시간에 나갈 내용이 아니라고 하시니 진짜 그런 것 같다. 통계학과나 수학 전공하신 분들이 조금 있는 것 같은데 그분들만 이해되었을 것 같다. 역시 수학은 어렵다.
