Basic Concepts of Databricks
Workflow to extract insights from data
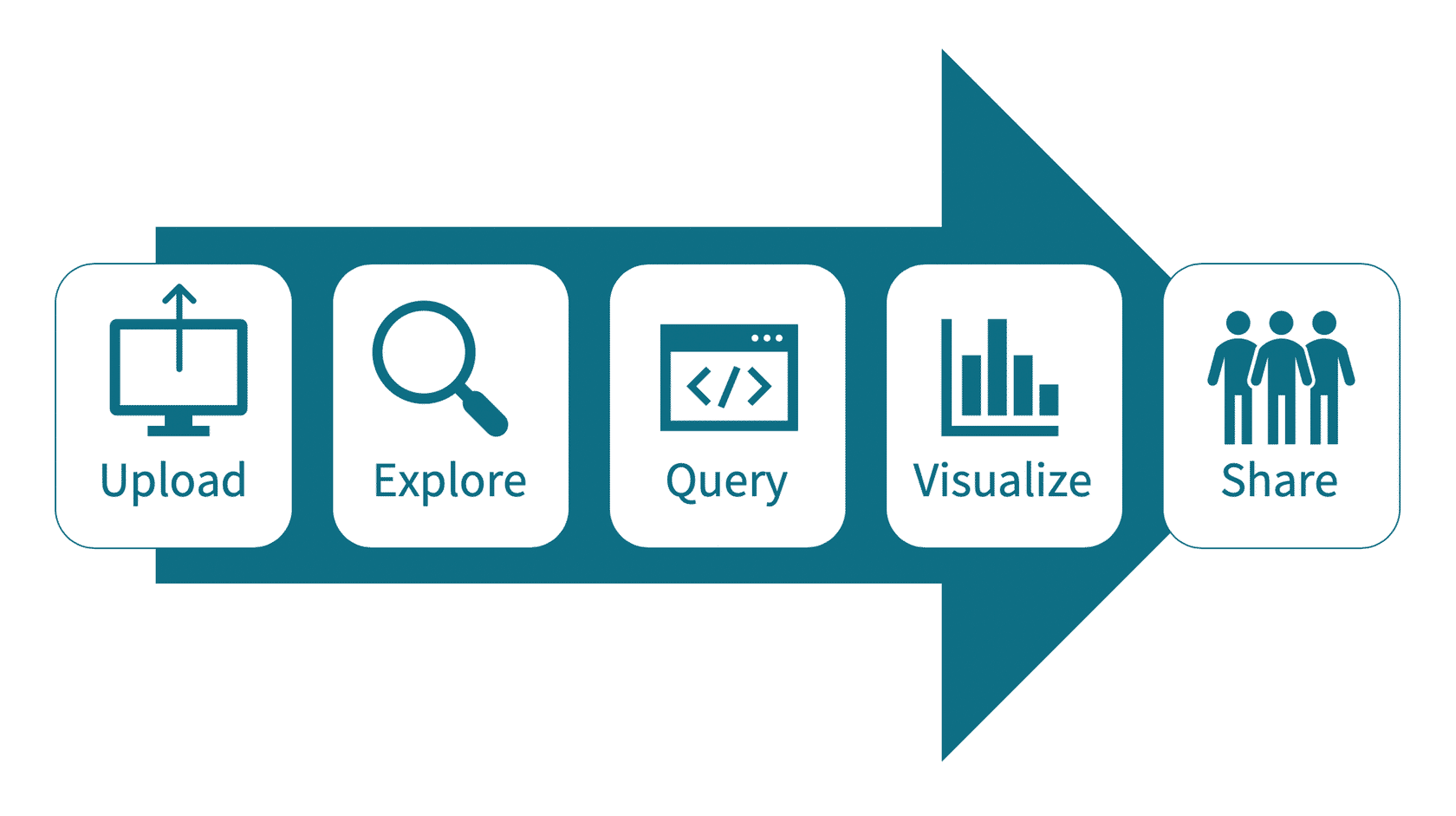
1. create a notebook 데이터 인사이트 뽑아오기
2. create a table 쿼리를 작성하기 전에 데이터 미리보기
3. query table 쿼리 작성
4. visualize data / bar chart를 통해 볼수 있게 됨
5. 다른 사람과 공유가능
DBSF(databricks file system)
Databricks에 있는 데이터들은 external data sources이다. Databricks는 보안적으로 잘되어 있기 때문에 이를 사용하게 되면 데이터가 날아가거나 복제되는 일을 거의 막을수 있다.
Clusters
비지니스에서 사용되는 모든 (데이터 사이언스, 엔지니어, 비지니스 팀 포함) 데이터를 한곳에 모아 놓은 것
Notebooks
Notebook 환경에서 SQL 쿼리를 작성한다. notebook에서 sql 쿼리를 실행시키고 싶으면 클러스터와 꼭 연결이 되어 있어야 한다
Jobs
일, 주단위로 자동으로 돌아가게 해주는 시스템 BI dashboard w/o manual involvement
Metastore
metastore 은 테이블을 관리하고 -> 유저들이 데이터를 공유할수 있게 해주는 공간
malformed / parquet
리소스가 부족한경우 / 지연처리
parsing policy - tsy
ETL / SLA
빅데이터에서 insights 얻는 방법을 위해서
우리가 생각해봐야 할 질문들
how to stream data
how to store data?
how to protect data?
data security policy?
unified data analytics?
high flux event data = data coming in massive volume
UDA approach -> 데이터를 오래 저장할수 있는 방법 / 비지니스 목적
-batch data
historical purchases
-streaming data - purchase data / trending topics / social media
long term data storage
-structured and unstructured data stay together
생각해보면 좋을 질문 -> what type of interest client would have?
characteristics of enterprise cloud service
-security is stable than other thing
-protect data
- database 설정
- number of shuffle partitions 설정
parquet table 같은 경우는 오류가 많이 나서 delta table을 사용한다
사용방법
1. 기존에 모든 데이터를 삭제한다
2. 데이터를 변형시킨다 - 함수를 이용해서
delta table
--> includes 데이터가 객체 형태로 저장/ 델다 트렌젝션 로그가 데이터와 함께 객체 형태로 저장 / 테이블이 메타스토어에 저장됨 (옵션)
delta lake 사용방법
1. parquet -> delta table로 변경
-file -> delta files로 변경 -> delta table등록 (자동으로 수정이 안되기 때문에 수작업 진행) -> DESCRIBE라는 커맨드 키를 이용해서 델타 테이블 형성 -> 특정 테이블의 records를 카운팅 한다 [table의 format은 당연히 delta이다. ]
- delta table에 새로운 파일 넣기
새로운 deta table 만들기
OLTP 비지니스 프로세스
- on-line transaction processing
-fast
OLAP 분석
-on-line analytical processing
-business data warehouse
-slow
*what is the difference between OLTP & OLAP?
Fundamentals of Delta Lake
목표
data management solutions가 어떻게 바뀌어왔는지 이해
data의 level
delta lake가 어떻게 조직이 겪고 있는 문제를 해결해줄수 있는지 이해
Data Warehouses
- helpful to decision support & business intelligence applications in the past
- 회사에는 unstructured, semi-structured, data with high variety 가 있는데, data warehouse는 structured data만 핸들링 가능했음
Data Lakes
-repositories for raw data in a variety of formats
-lack critical features
- do not support ACID transactions ..
- X barch or streaming job
Lakehouse
-cloud data platform design pattern
-low-cost storage
key features
storage is decoupled from compute
open storage formats, tools, and processing engines
support for diverse data types ranging from unstructured to structured data
support for diverse workloads, including SQL and analytics, data science, and machine learning
transaction support
end-to-end streaming
