Spark Architecture Intro
Introduction to Apache Spark Architecture
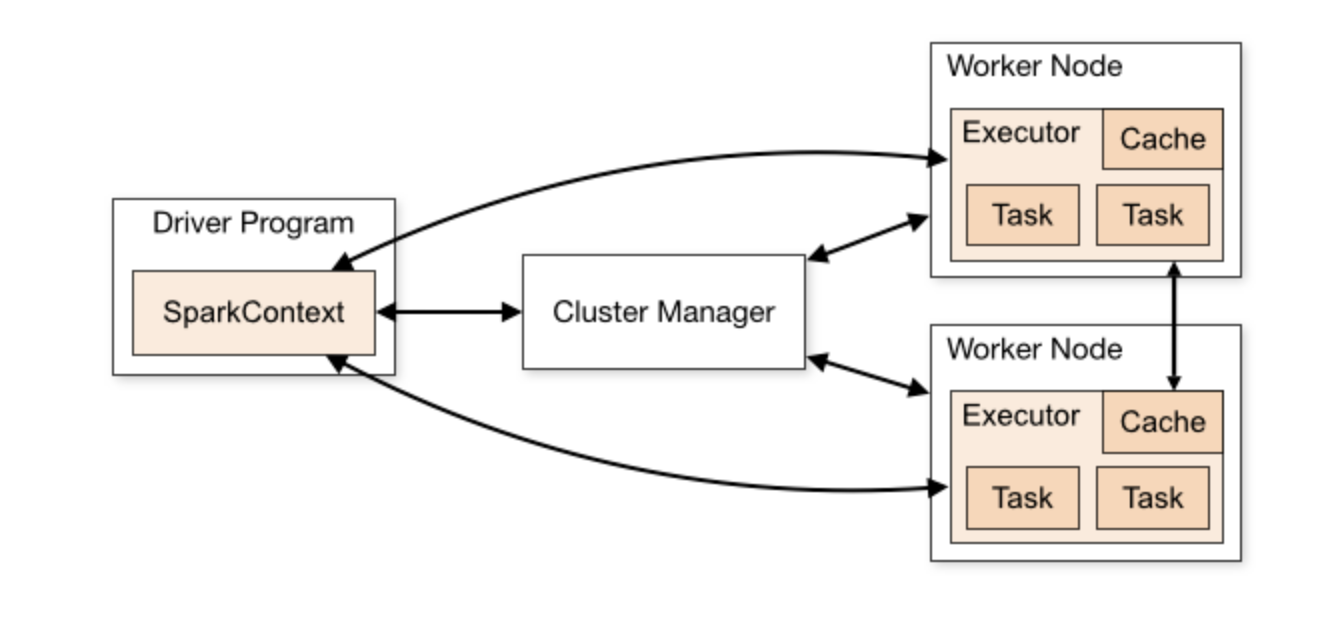
Spark application이 어떻게 jobs, stages, tasks로 나누어지는지?
Filtering - distributed computing
Q. 초콜렛 박스에 100봉지가 있는데 한사람이 60초만에 갈색만 골라서 다 먹을수 있게 하는 방법?
어떻게 문제를 해결할까?
Spark cluster
-consists of components
-mini nodes (virtual and physical machine)
Databricks 에서는 only one executor & only one node
One executor per node 가 제일 best
In single node, multiple executor인 경우,
Driver + executor = spark cluster
Cluster = consistst of mini nodes (components)
Yarn - run 2 executor(same nodes)
Inside of node = slots/threads/cores
Executors X cores = tasks
Partition of every task
One task = each partitions
Core - hardware
Cluster is multiple executor * driver
Node - individual machine
Counting - stages
- Stage1 = local count
일을 분담했는데 끝나지 못한 task가 있다면 다른 사람에게 분담하여서 해결한다
- Stage2 = Global counting
driver에게 데이터를 손댈수 있도록 해주는 방법
Result 가 turn back 했을 때 비로소 driver가 리턴된 데이터 값을 받을수 있다
stage1이 모두 끝나야지만 stage2로 넘어갈수 있다
Distinct - shuffle
*Stage 1 = local distinct
In local bag, there are local distinct things
When we open the bag, we can find out the distinct colors of chocolate
데이터가 움직여서 executor에게 할당 되어지는 경우
How the shuffle works?
Combine the data which is same
Color by colors
Move into the data to proceed next stage
*Stage 2 = global distinct
executor가 움직여서 데이터를 가져오는 경우
여러개가 있는 같은 데이터를 하나로 병합한다
Change red -> included value
Red -> #ffoooo
Return result to driver -> stage 2 is done
꼭 data를 sort를 해야 하는가?
Bucketing?
Conclusion of stage #1 -> new dataset 이 shuffle file로 바뀜
Shuffle = rearrange the data (between cluster and stage)
Variable vs Data type
