
기본 미션 📣
01-2 확인문제 3번 | 프로그램이 실행되려면 반드시 ( 메모리 )에 저장되어 있어야 합니다.
02-1 확인문제 3번 | 1101(2)을 음수로 표현한 값은 0011 입니다.
선택 미션 📣
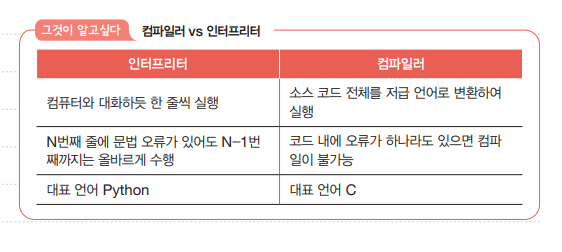
p100 스택과 큐 개념정리 | 스택이란 한쪽 끝이 막혀 있는 통과 같은 저장 공간을 말한다. 한쪽 끝이 막혀 있어 마지막으로 저장한 데이터부터 빼내야한다. 그래서 '나중에 저장한 데이터를 가장 먼저 빼내는 데이터 관리 방식(후입선출)' 이라는 점에서 LIFO(Last In First Out) 자료구조라고도 한다.
큐는 스택과 달리 양쪽이 뚫려 있는 통과 같은 저장 공간을 말한다. 한쪽으로는 데이터를 저장하고 다른 한쪽으로는 먼저 저장한 데이터를 빼내는데, 그래서 '가장 먼저 저장된 데이터부터 빼내는 데이터 관리 방식(선입선출)' 이라는 점에서 FIFO(First In First Out) 자료 구조라고도 한다.
01-1 컴퓨터 구조를 알아야 하는 이유
✏️ 컴퓨터 구조 지식은 나를 다양한 문제를 스스로 해결할 줄 아는 개발자로 만들어준다.
✏️ 컴퓨터 프로그래밍 문법만 알았을 때 컴퓨터는 '미지의 대상' 이지만 컴퓨터의 구조를 알게되었을 때는 '분석의 대상' 이 된다.
✏️ 컴퓨터 구조를 이해하면 입출력뿐아니라 성능, 용량, 비용까지 고려하는 개발자가 될 수 있다.
📌 내가 만든 프로그램은 어떤 환경에서 어떻게 작동하는지는 내가 가장 잘 이해하고 있어야 하고, 프로그램을 위한 최적의 환경을 스스로 판단할 수 있어야 한다.
🔺클라우드 서비스(AWS)
01-2 컴퓨터 구조의 큰 그림
✏️ 컴퓨터가 이해하는 정보 : 데이터와 명령어
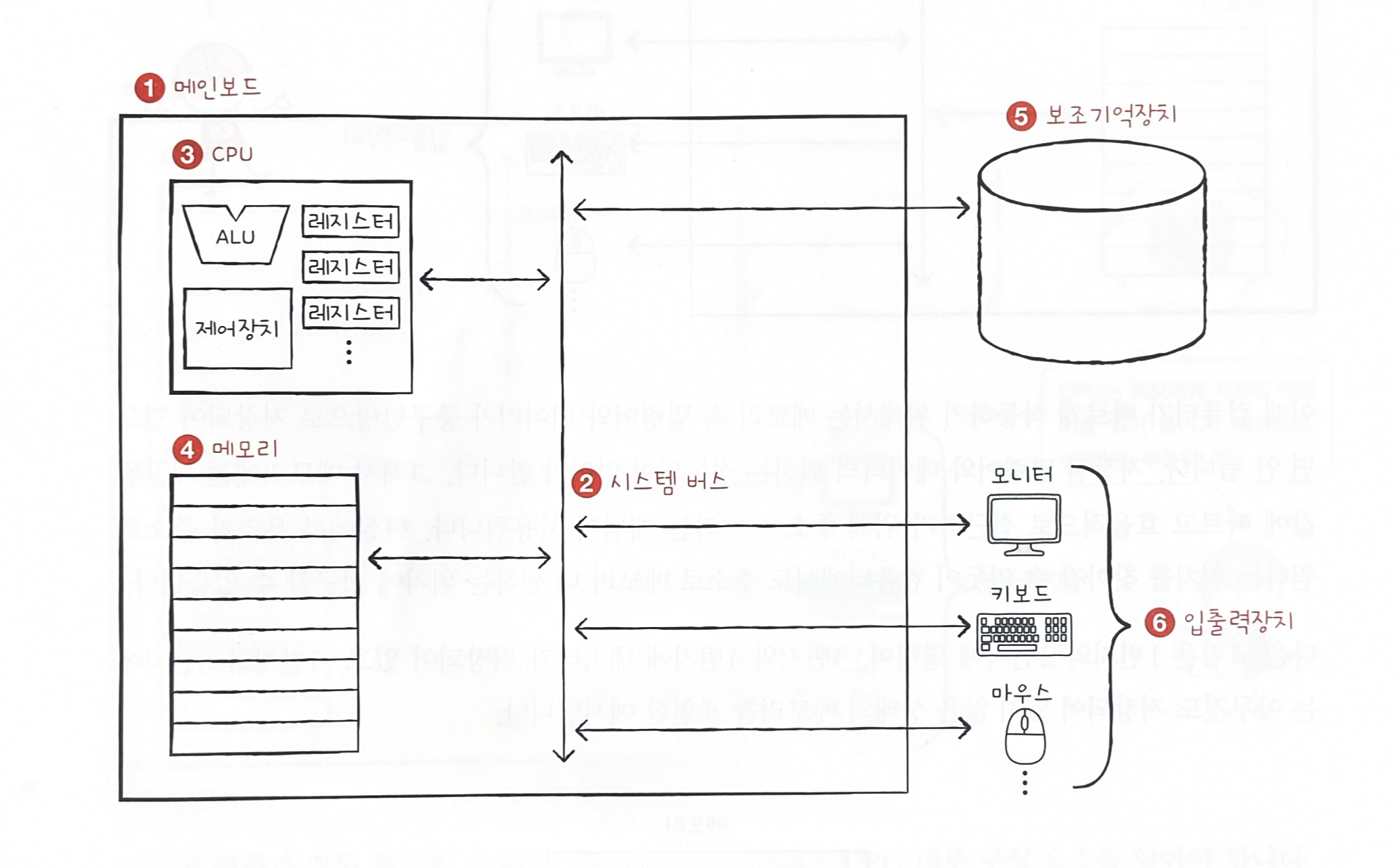
 ✏️ 컴퓨터의 네 가지 핵심 부품 : 주기억장치, 중앙처리장치, 보조기억장치, 입출력장치
✏️ 컴퓨터의 네 가지 핵심 부품 : 주기억장치, 중앙처리장치, 보조기억장치, 입출력장치
 ➕ RAM과 ROM의 차이
➕ RAM과 ROM의 차이
RAM은 휘발성 메모리로, 작업 중인 파일을 한시적으로 저장한다.
ROM은 컴퓨터에 지시사항을 영구히 저장하는 비휘발성 메모리이다.
메모리
✏️ 메모리는 현재 실행되는 프로그램의 명령어와 데이터를 저장하는 부품이기 때문에 프로그램이 실행되기 위해서는 반드시 메모리에 저장되어 있어댜 한다.
✏️ 메모리는 주소라는 개념을 사용하는데 저장된 값에 빠르고 효율적으로 접근하기 위함이다.
✏️ 단점 : 가격이 비싸 저장용량이 적다, RAM이기 때문에 전원을 끄면 저장된 내용이 삭제된다.
CPU
✏️ CPU는 메모리에 저장된 값을 읽고, 해석하고, 실행한다.
✏️ CPU의 내부 핵심 구성 요소 : 산술논리연산장치(ALU), 레지스터, 제어장치
- ✏️ ALU는 계산하는 장치로 컴퓨터 내부에서 수행되는 대부분의 계산을 한다.
- ✏️ 레지스터는 임시저장장치로 프로그램을 실행하는데 필요한 값들을 임시로 저장한다. 레지스터는 여러 개 존재하고 각자 다른 이름을 가지고 있다.
- ✏️ 제어장치는 제어 신호를 발생시키고 명령어를 해석한다. 제어 버스를 통해 제어 신호를 내보낸다.
보조기억장치
✏️ 전원이 꺼져도 프로그램을 저장한다.
✏️ 보조기억장치의 예 : 하드디스크, SSD, USB 메모리, DVD, CD-ROM
✏️ 마우스, 키보드와 같은 일반적인 입출력장치에 비해 메모리를 보조한다는 특별한 기능을
하는 입출력장치로도 볼 수 있다.
🔎 메모리와 보조기억장치의 차이점
메모리는 실행되는 프로그램을 저장한다면, 보조기억장치는 보관할 프로그램을 저장한다.
입출력장치
✏️ 컴퓨터 외부에 연결되어 컴퓨터 내부와 정보를 교환할 수 있는 부품이다.
➕ 입력장치 : 키보드, 마우스, 스캐너, 웹캠, 마이크
출력장치 : 모니터, 프린처, 스피커
메인보드와 시스템 버스
 ✏️ 시스템 버스 안에 주소 버스와 데이터 버스, 제어 버스가 있다.
✏️ 시스템 버스 안에 주소 버스와 데이터 버스, 제어 버스가 있다.
- ✏️ 주소 버스는 주소를 주고 받는 통로로, CPU가 메모리에서 읽고자 하는 주소를 전달하는 등 에 역할을 한다.
- ✏️ 데이터 버스는 명령어와 데이터를 주고 받는 통로로, 데이터를 내보내거나 제어신호와 주소를 보고 데이터를 보낸다.
- ✏️ 제어 버스는 제어 신호를 주고 받는 통로로, 제어 장치에 신호를 내보낸다.
02-1 0과 1로 숫자를 표현하는 방법
✏️ 비트( bit )는 0과 1을 나타내는 가장 작은 정보 단위로,
여덟 개의 비트를 묶어 바이트라고 한다. (1byte = 8bit)
✏️ n비트는 2ⁿ가지 정보를 표현할 수 있다.
✏️ 바이트를 제외한 kB, MB, GB, 그 이상의 단위는 모두 이전 단위를 1,000개 묶어 표현한다.
🔎 kB와 KiB를 혼동해서 쓰면 안된다.
| 기호(이름) | 값 | 기호(이름) | 값 |
|---|---|---|---|
| kB(킬로바이트) | 1000¹ = 10³ | KiB(키비바이트) | 1024¹ = 2¹⁰ |
| MB(메가바이트) | 1000² = 10⁶ | KiB(메비바이트) | 1024² = 2²⁰ |
| MB(기가바이트) | 1000³ = 10⁹ | KiB(기비바이트) | 1024³ = 2³⁰ |
| MB(테라바이트) | 1000⁴ = 10¹² | KiB(테비바이트) | 1024⁴ = 2⁴⁰ |
| MB(페타바이트) | 1000⁵ = 10¹⁵ | KiB(페비바이트) | 1024⁵ = 2⁵⁰ |
| MB(엑사바이트) | 1000⁶ = 10¹⁸ | KiB(엑스비바이트) | 1024⁶ = 2⁶⁰ |
| MB(제타바이트) | 1000⁷ = 10²¹ | KiB(제비바이트) | 1024⁷ = 2⁷⁰ |
| MB(요타바이트) | 1000⁸ = 10²⁴ | KiB(요비바이트) | 1024⁸ = 2⁸⁰ |
✏️ 정보 단위 중 워드(word)는 CPU가 한 번에 처리할 수 있는 데이터 크기를 의미한다. 워드 크기는 CPU마다 다르지만 대부분의 컴퓨터는 32비트 또는 64비트이다.
✏️ 우리가 일반적으로 사용하는 수는 십진수지만 컴퓨터가 이해하는 수는 이진수이다.
 ✏️ 혼동을 막기 위해 이진수를 표기할 때는 뒤에 ₍₂₎를 붙이거나 앞에 0b를 붙인다.
✏️ 혼동을 막기 위해 이진수를 표기할 때는 뒤에 ₍₂₎를 붙이거나 앞에 0b를 붙인다.
✏️ 이진수의 0과 1을 뒤집은 수를 1의 보수라고 하고, 거기에 1을 더한 값을 2의 보수라 한다.
✏️ 이진수를 음수로 표현하기 위해서는 2의 보수를 사용한다.
✏️ 2의 보수에 사전적의미는 '어떤 수를 그보다 큰 2ⁿ에서 뺀 값'이지만 쉽게 보자면 '모든 0과 1을 뒤집고 1을 더한 값'이다.
✏️ 어떤 수를 음수로 표현했을 때 이진수로만 봐서 그 수가 양수인지 음수인지 판별할 수 없다. 그래서 컴퓨터 내부에서는 플래그를 사용한다.
✏️ 2의 보수로 음수를 모두 표현하기에는 한계가 있다.
✏️ 데이터를 표현할 때 이진수로만 수를 표현하면 숫자의 길이가 너무 길어지기 때문에 십육진법도 자주 사용한다.
 ✏️ 혼동을 막기 위해 십육진수를 표기할 때도 뒤에 ₍₁₆₎를 붙이거나 앞에 0x를 붙인다.
✏️ 혼동을 막기 위해 십육진수를 표기할 때도 뒤에 ₍₁₆₎를 붙이거나 앞에 0x를 붙인다.
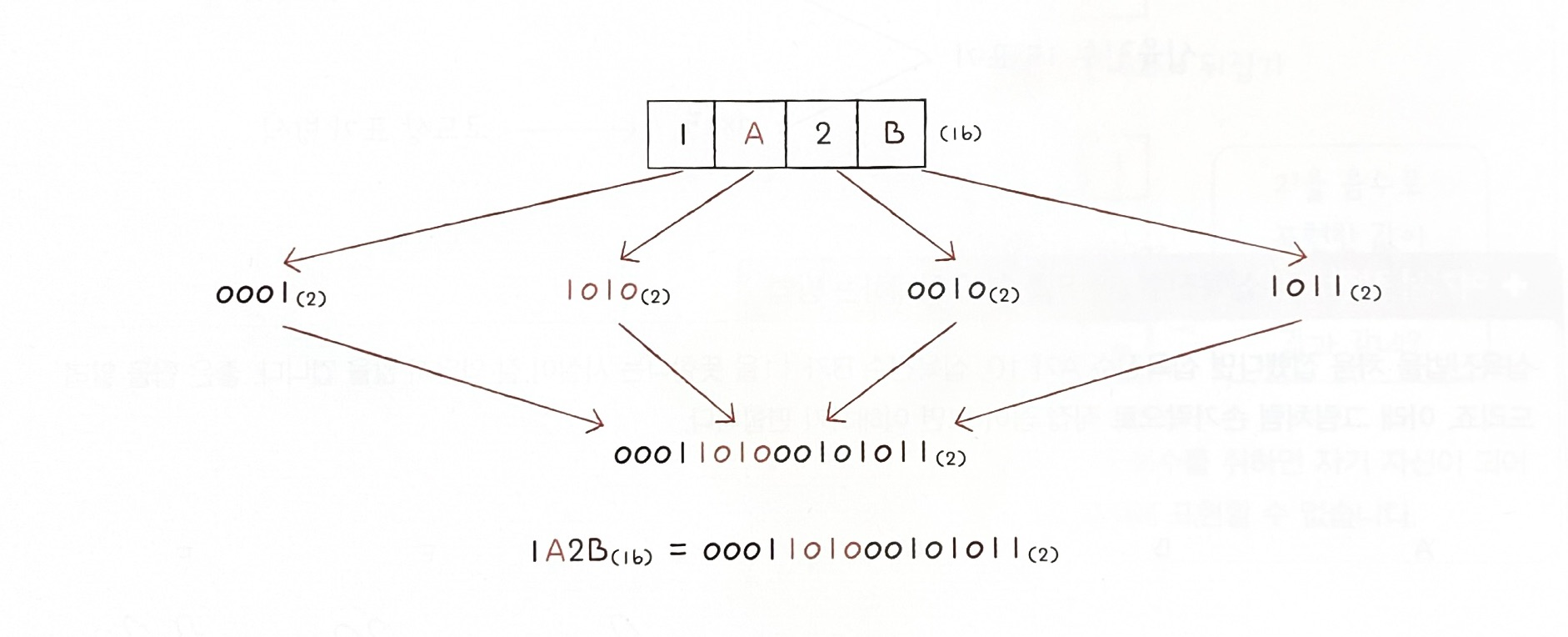
✏️ 십육진수를 이진수로 변환하기 위해서는 십육진수를 이루고 있는 각 글자를 따로따로
(4개의 숫자로 구성된) 이진수로 변환하고 그것들을 그대로 이어 붙이면 된다.
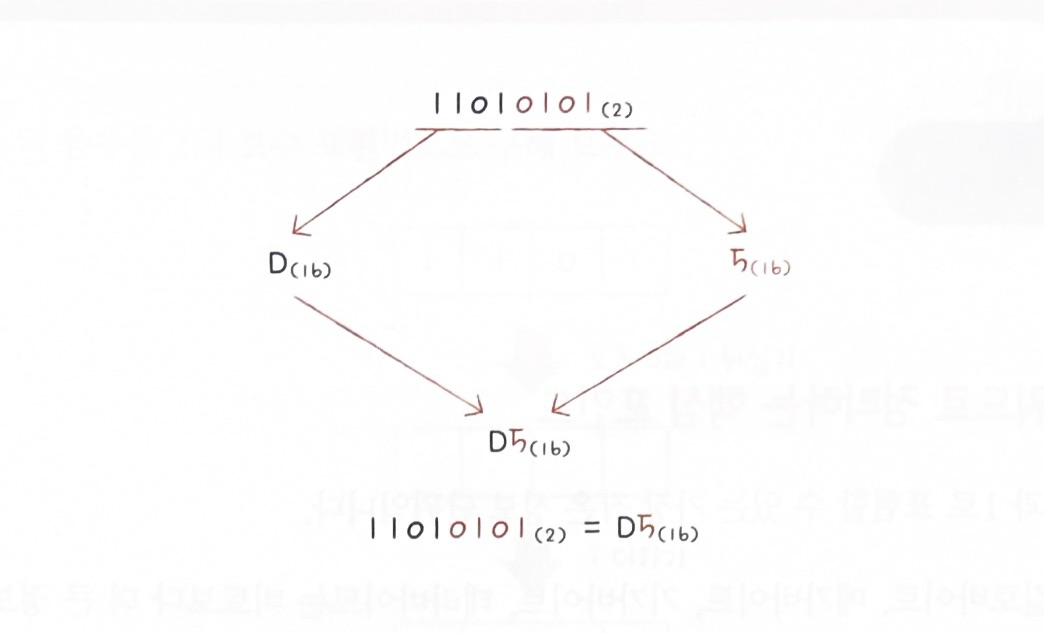
 ✏️ 이진수를 십육진수로 변환하기 위해서는 이진수 숫자를 네 개씩 끊고, 끊어 준 네 개의 숫자를 하나의 십육진수로 변환한 뒤 그대로 이어 붙이면 된다.
✏️ 이진수를 십육진수로 변환하기 위해서는 이진수 숫자를 네 개씩 끊고, 끊어 준 네 개의 숫자를 하나의 십육진수로 변환한 뒤 그대로 이어 붙이면 된다.
02-2 0과 1로 문자를 표현하는 방법
 ✏️ 문자 인코딩은 문자 집합에 속한 문자를 컴퓨터가 이해할 수 있는 0과 1로 변환하는 것으로 같은 문자 집합에 대해서도 다양한 인코딩 방법이 있을 수 있다.
✏️ 문자 인코딩은 문자 집합에 속한 문자를 컴퓨터가 이해할 수 있는 0과 1로 변환하는 것으로 같은 문자 집합에 대해서도 다양한 인코딩 방법이 있을 수 있다.
✏️ 문자 디코딩은 인코딩의 반대로 0과 1로 이루어진 문자 코드를 사람이 이해할
수 있는 문자로 변환하는 것이다.
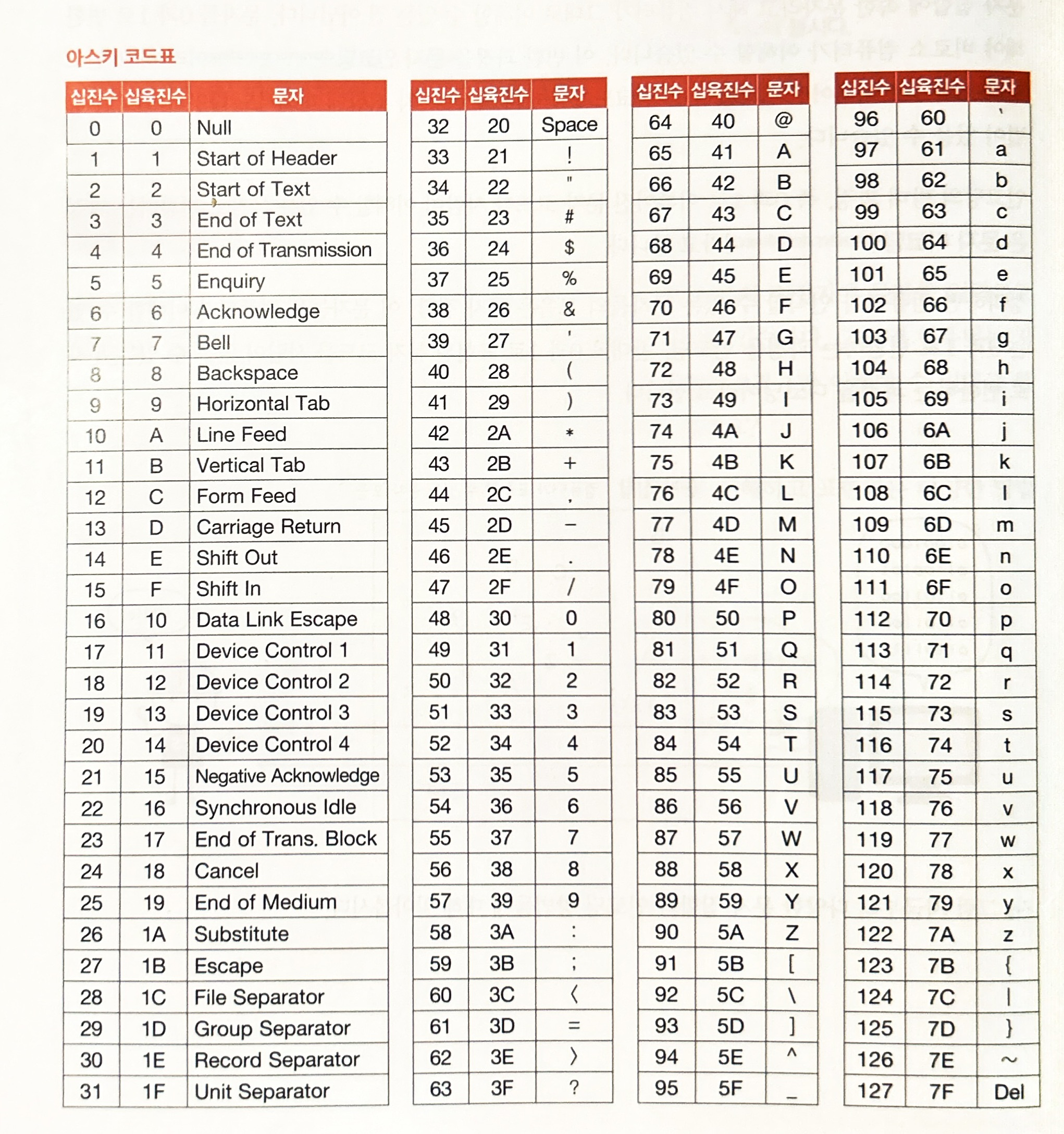 아스키 코드(ASCII)
아스키 코드(ASCII)
미국표준협회가 만든 정보 교환용 코드로 7비트로 구성되어있다.
따라서 2⁷가지 128개의 문자를 표현할 수 있다.
✏️ 아스키는 영어 알파벳과 아라비아 숫자, 일부 특수 문자가 있는 초창기 문자 집합 중 하나이다.
✏️ 아스키 문자에 대응된 고유한 수를 아스키 코드라 한다.
📌 실제로는 하나의 아스키 문자를 표현하기 위해 8비트를 사용하지만 8비트 중 1비트는 패리티 비트(parity bit)로 오류를 검출을 위해 사용하는 비트기 때문에 실질적으로 문자 표현을 위해 사용되는 비트는 7비트이다.
✏️ 근본적으로 아스키 문자 집합에 속한 문자들은 7비트로 표현하기에 한글뿐만 아니라 아스키 문자 집합 외의 문자, 특수문자를 표현할 수 없다는 단점이 있다.
🔺 확장 아스키(Extended ASCII)
EUC-KR
✏️ 한글 인코딩에는 완성형, 조합형에 두 가지 방식이 존재한다.
✏️ EUC-KR은 대표적인 완성형 인코딩 방식으로 한 글자에 2바이트를 부여한다.
- ✏️ 완성형 인코딩 방식은 초성, 중성, 종성의 조합으로 완성된 하나의 글자에 고유한 코드를 부여하는 방식으로, '가'는 1, '나'는 2와 같은 식으로 인코딩한다.
- ✏️ 조합형 인코딩은 초성을 위한 비트열, 중성을 위한 비트열, 종성을 위한 비트열을 할당하여 하나의 글자 코드를 완성하는 인코딩 방식이다.
✏️ EUC-KR로의 한계를 이겨내기 위해 확장된 버전인 CP949(Code Page 949)가 나왔지만 문제를 완전히 해결하진 못하였다.
유니코드 UTF-8
✏️ 유니코드는 여러 나라의 문자를 광범위하게 표현할 수 있는 통일된 문자 집합으로, 현대 문자를 표현할 때 가장 많이 사용되는 표준 문자 집합이다.
✏️ 유니코드는 아스키코드와 EUC-KR과 다르게 글자에 부여된 값 자체를 인코딩된 값으로 삼지 않고 이 값을 다양한 방법으로 인코딩한다. 인코딩 방법에는 크게 UTF-8, UTF-16, UTF-32 등이 있다.
✏️ UTF-8은 1바이트부터 4바이트까지 인코딩 결과를 만들어내어 인코딩한 값이 1바이트가 될 수도 2바이트, 3바이트가 될 수도 있다.
03-1 소스 코드와 명령어
✏️ 컴퓨터는 저급언어만 이해하고 실행할 수 있다. 그렇기 때문에 소스코드를 실행하려면 고급 언어를 저급 언어로, 즉 명령어로 변환해야 한다.

어셈블리어
✏️ 어셈블리어는 0과 1로 이루어진 기계어를 읽기 편한 형태로 번력한 저급언어이다.
✏️ 어셈블리어는 어떤 분야의 개발자인지에 따라 중요성이 달라지는데, 하드웨어와 밀접한 임베디드 개발자, 게임 개발자, 정보 보안 분야 등의 개발자는 어셈블리어를 많이 이용한다.
✏️ 이러한 분야의 개발자에게 어셈블리어는 프로그램 작동의 근본적인 단계를 알 수
있기 때문에 '작성의 대상'을 넘어 중요한 '관찰의 대상'이 되기도 한다.
✏️ 고급언어를 저급언어로 변환하는 방법은 컴파일 방식과 인터프리트 방식이있다.
컴파일 언어
✏️ 컴파일 언어는 컴파일러에 의해 소스 코드 전체가 저급 언어로 변환되어 실행되는 고급 언어이다. 대표적으로는 C언어가 있다.
✏️ 컴파일 언어로 작성된 소스 코드는 코드 전체가 저급 언어로 변환되는 과정을 거치는데, 이를 컴파일이라 하고 컴파일을 수행하는 도구를 컴파일러라 한다.
✏️ 컴파일러는 소스 코드 내에 오류가 있는지 따지며 컴파일하는데 하나라도 오류가 있다면 해당 소스 코드는 컴파일에 실패한다.
✏️ 컴파일러가 성공적으로 저급 언어로 변환한 코드는 목적 코드라고 한다.
인터프리터 언어
✏️ 인터프리터 언어는 인터프리터에 의해 소스 코드가 한 줄씩 실행되는 고급 언어이다. 대표적으로는 Python이 있다.
✏️ 인터프리터 언어로 작성된 소스 코드는 코드가 한 줄씩 저급 언어로 변환되는데, 이 때 실행해주는 도구를 인터프리터라 한다.
✏️ 인터프리터 언어는 소스 코드를 한 줄씩 실행하기 때문에 소스 코드 N번째 줄에 문법 오류가 있더라도 N-1번째 줄까지는 올바르게 수행된다.
✏️ 목적 파일은 컴파일 언어가 저급 언어로 변환된 파일일 뿐이므로 목적 코드가 실행되기 위해서는 목적 파일에는 없는 외부 기능들과 목적 파일을 연결 짓는 작업이 필요하다.
이러한 작업이 링킹이다.
03-2 명령어의 구조
✏️ 명령어는 연산 코드와 오퍼랜드로 구성되어 있다.
오퍼랜드
✏️ '연산에 사용할 데이터' 또는 '연산에 사용할 데이터가 저장된 위치'를 오퍼랜드라 한다.
✏️ 오퍼랜드가 담기는 영역을 오퍼랜드 필드라고 하는데, 오퍼랜드 필드에는 데이터나 메모리, 레지스터 주소가 온다. 다만 숫자나 문자와 같이 연산에 사용할 데이터를 직접 명시하기보다는, 많은 경우 연산에 사용할 데이터가 저장된 메모리 주소나 레지스터 이름을 담는다. 그래서 오퍼랜드 필드를 주소 필드라고도 한다.
✏️ 오퍼랜드는 명령어 안에 하나도 없을 수도, 여러 개가 있을 수도 있다. 여기서 오퍼랜드 갯수에 따라 0-주소 명령어, 1-주소 명령어라 한다.
연산 코드
✏️ '명령어가 수행할 연산'을 연산 코드라 한다.
✏️ 연산 코드의 종류는 매우 많지만, 가장 기본적인 연산 코드 유형은 크게 네 가지로
① 데이터 전송 ② 산술/논리 연산 ③ 제어 흐름 변경 ④ 입출력 제어가 있다.
✏️ 연산코드는 CPU마다 다르지만 공통된 종류만 보자면
데이터 전송
- MOVE : 데이터를 옮겨라
- STORE : 메모리에 저장하라
- LOAD ( FETCH ) : 메모리에서 CPU로 데이터를 가져와라
- PUSH : 스택에 데이터를 저장하라
- POP : 스택의 최상단 데이터를 가져와라
산술/논리 연산
- ADD / SUBTRACT / MULTIPLY / DIVIDE : 덧셈 / 뺄셈 / 곱셈 / 나눗셈을 수행하라
- INCREMENT / DECREMENT : 오퍼랜드에 1을 더하라 / 오퍼랜드에 1을 빼라
- AND / OR / NOT : AND / OR / NOT 연산을 수행하라
- COMPARE : 두 개의 숫자 또는 TRUE / FALSE 값을 비교하라
제어 흐름 변경
- JUMP : 특정 주소로 실행 순서를 옮겨라
- CONDITIONAL JUMP : 조건에 부합할 때 특정 주소로 실행 순서를 옮겨라
- HALT : 프로그램의 실행을 멈춰라
- CALL : 되돌아올 주소를 저장한 채 특정 주소로 실행 순서를 옮겨라
- RETURN : CALL을 호출할 때 저장했던 주소로 돌아가라
입출력 제어
- READ ( INPUT ) : 특정 입출력 장치로부터 데이터를 읽어라
- WRITE ( OUTPUT ) : 특정 입출력 장치로 데이터를 써라
- START IO : 입출력 장치를 시작하라
- TEST IO : 입출력 장치의 상태를 확인하라
가 있다.
주소 지정 방식
✏️ 연산의 대상이 되는 데이터가 저장된 위치를 유효 주소라 하는데, 주소 지정 방식은 유효 주소를 찾는 방법을 말한다.
- ✏️ 즉시 주소 지정 방식은 연산에 사용할 데이터를 오퍼랜드 필드에 직접 명시하는 방식으로, 데이터의 크기가 작아지는 단점이 있지만 다른 것들에 비해 빠르다.
- ✏️ 직접 주소 지정 방식은 오퍼랜드 필드에 유효 주소를 직접적으로 명시하는 방식으로, 즉시 주소 지정 방식보다는 데이터의 크기가 커졌지만 연산 코드의 길이만큼 비트 수가 줄었다.
- ✏️ 간접 주소 지정 방식은 유효 주소의 주소를 명시하는 방식으로, 앞서 말한 방식들보다는 데이터의 크기가 크지만 두 번의 메모리 접근이 필요하기 때문에 일반적으로 느리다.
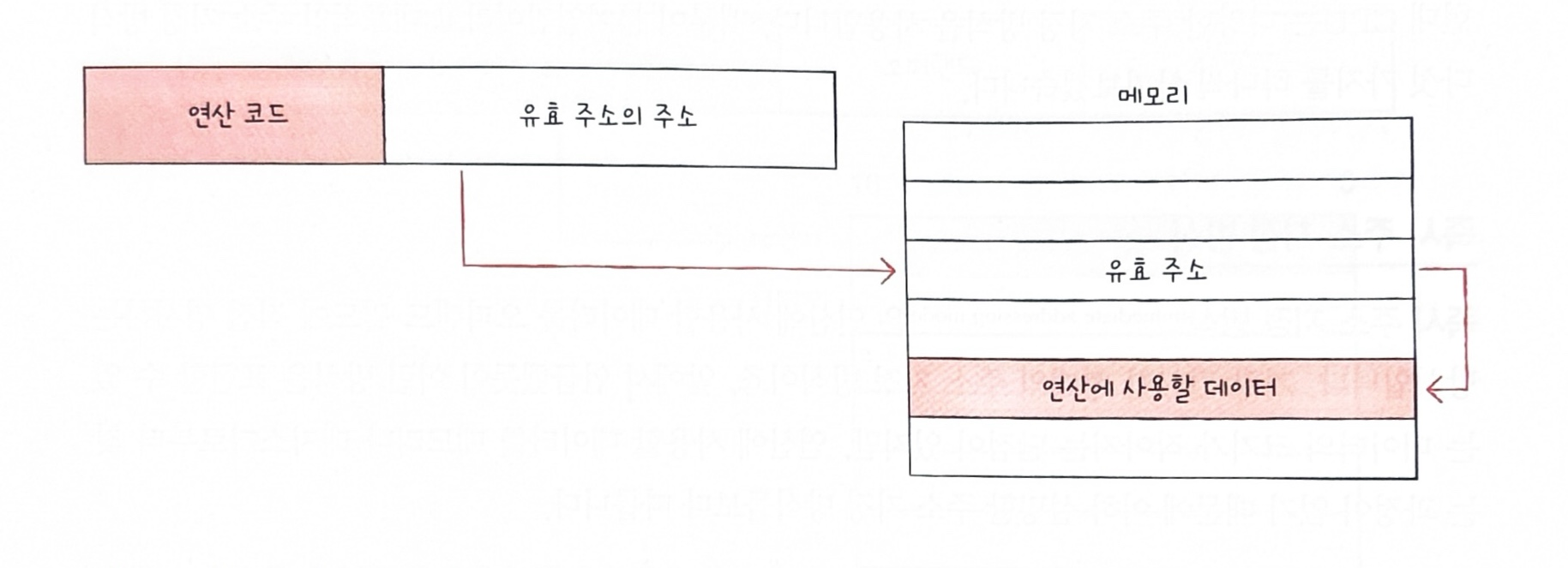
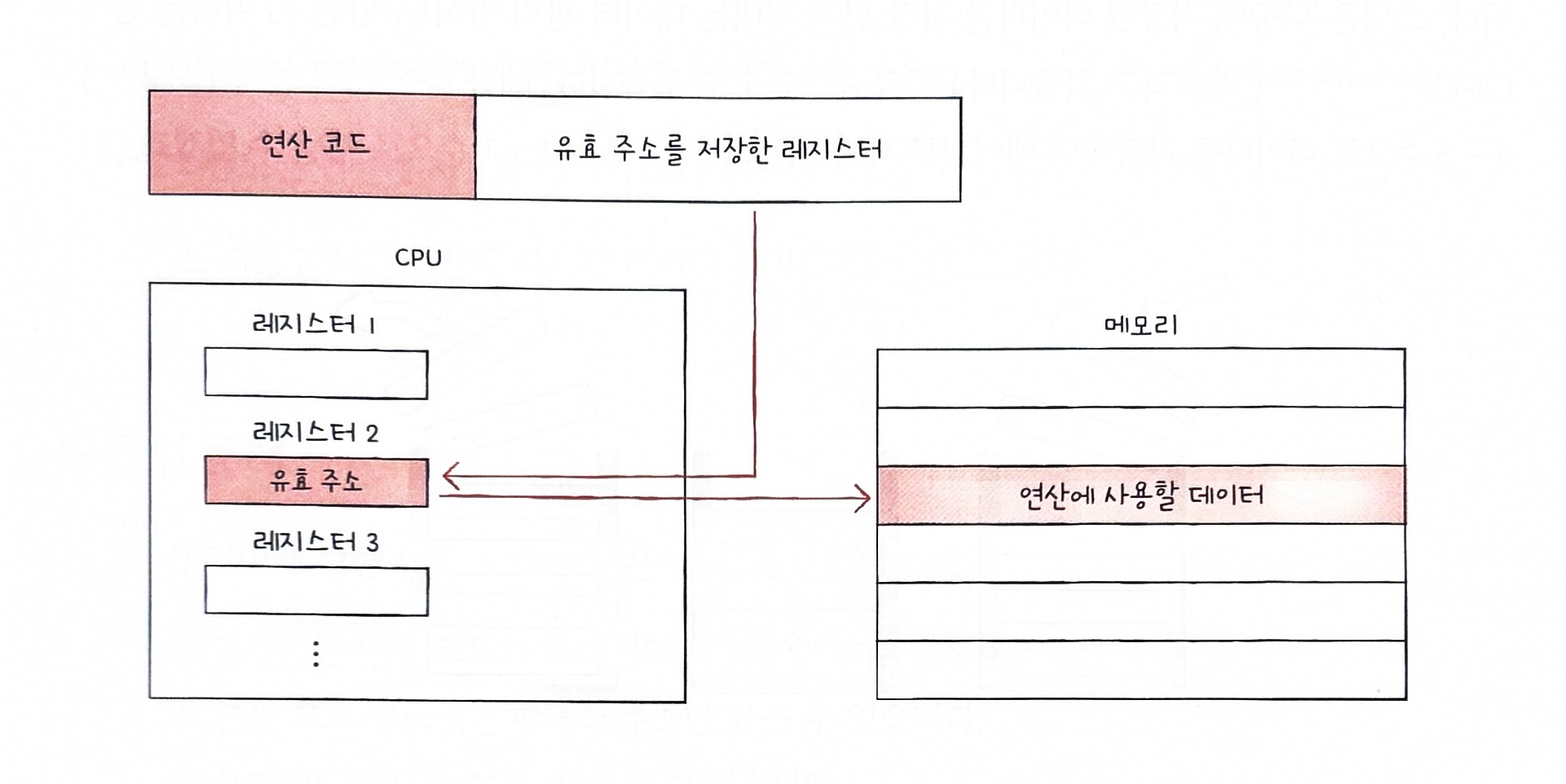
- ✏️ 레지스터 주소 지정 방식은 직접 주소 지정 방식과 비슷하게 연산에 사용할 데이터를 저장한 레지스터를 오퍼랜드 필드에 직접 명시하는 방법이다. 일반적으로 CPU 외부에 메모리에 접근하는 것보다 CPU 내부에 레지스터에 접근하는 것이 더 빠르기 때문에 앞 방식들보다 빠르지만 데이터 크기의 관한 문제는 똑같이 갖고 있다.
- ✏️ 레지스터 간접 주소 지정 방식은 연산에 사용할 데이터를 메모리에 저장하고, 그 주소를 저장한 레지스터를 오퍼랜드 필드에 명시하는 방법이다. 간접 주소 지정 방식과 비슷하지만, 메모리에 접근하는 횟수가 한 번으로 줄어든다는 장점이 있다.


와 넘 잘했어요