📑 Attention Is All You Need
🔗 reference link
Summary !
💭
Self-Attention은 자기자신 문장에 대한 단어끼리의 유사도를 구하는 방법이며,
Attention 함수의 종류는 다양하다.해당 논문에서는
Scaled-dot product함수를 사용하며,
이때, N차원으로 축소한 Q, K, V 벡터를 이용,
N겹의 Attention을 병렬로 처리하고 concatenation을 통해 합치는
Multi-head Attention방법을 적용한다.
1. Self Attention 👀
💡 입력 문장 내의 단어들끼리, 즉 자기자신 문장에 대한 유사도를 구하여 문맥을 파악
Self Attention의 `Q, K, V` = 입력 문장의 모든 단어 벡터들
- Query에 대한 모든 Key와의
유사도를 계산 !
1-1. Self Attention
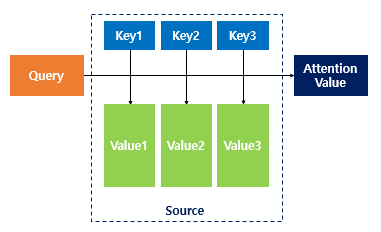
Self Attention example

Basic Attention function
-
Query에 대해서 모든 Key와의
유사도를 계산
유사도 = 가중치, 각 Key와 대응되는 Value 값에 반영- Return
Weighted Sum of Value
- Return
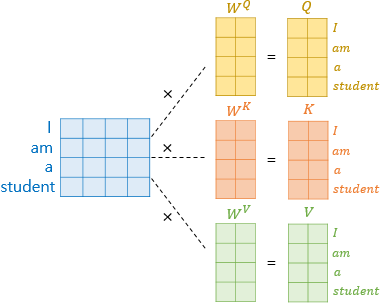
1-2. Self Attention의 Q, K, V 벡터
Self Attention example - word vector, W는 가중치 벡터
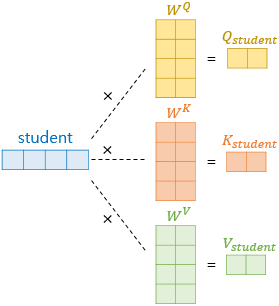
- Self Attention : 입력 문장의
단어 벡터들을 가지고 수행- 차원의 단어 벡터 →
Q, K, V벡터로 변환하여 이용
- 차원의 단어 벡터 →
- 해당 논문에서는 차원의 단어 벡터 → 차원의 Q, K, V로 변환
num_heads = 8
2. Scaled dot-product Attention ➗
💡 Attention mechanism
각 Q 벡터는 모든 K 벡터에 대하여
Attention score를 계산 ; 유사도Attention score를 이용하여 모든 V 벡터를
가중합Return `Context vector`
- 어텐션 함수의 종류는 다양하다
2-1. Scaled dot-product Attention
Scaled dot-product example (128, 32 is an arbitary num)
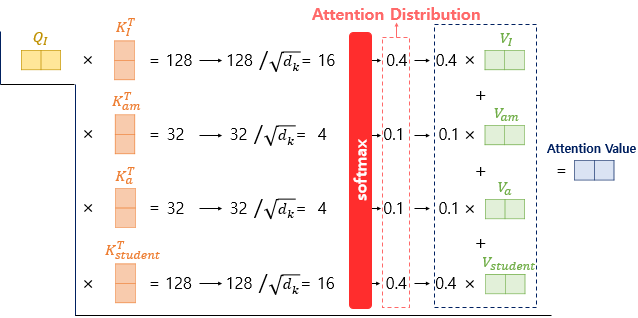
-
연산 개념
Input
[ I am a student ]-
벡터끼리 Dot-product
- 입력 문장의 단어 벡터 → 변환된
Q, K, V 벡터를 이용 - 단어 ‘I’에 대한 Q 벡터가 모든 K 벡터에 대해 연산
- 입력 문장의 단어 벡터 → 변환된
-
스케일링
- ;
- 단어 ‘I’ - 각 단어 ‘I’, ‘am’, ‘a’, ‘student’와의 연관성을 의미
- Return
Attention score
- Return
-
Attention value
- Softmax(Attention score)
- 각 단어에 대응되는 V 벡터에 대해 가중합
- Return
Context vector
- Return
-
2-2. 행렬을 통한 일괄 연산
각 단어에 대해 벡터 연산을 하는 대신, 문장 단위의 행렬을 이용하여 연산
- 위의 연산 개념에 벡터 대신
행렬을 대입- Return
Context matrix
- Return
위 실제 수식을 행렬로 시각화
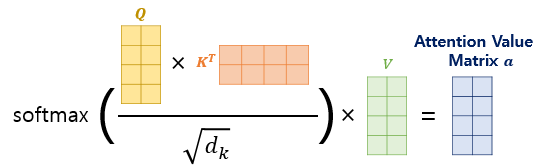
Q, K, V 행렬 변환 example
-
수식에 사용된 행렬 크기 정리
입력 문장의 길이 문장 행렬의 크기 Q, K 벡터의 차원 V 벡터의 차원 Q, K 행렬의 크기 V 행렬의 크기 위의 가정에 따르면, 가중치 행렬의 크기 추정 가능 이때, 논문에 따르면, 이므로, Attention Value Matrix
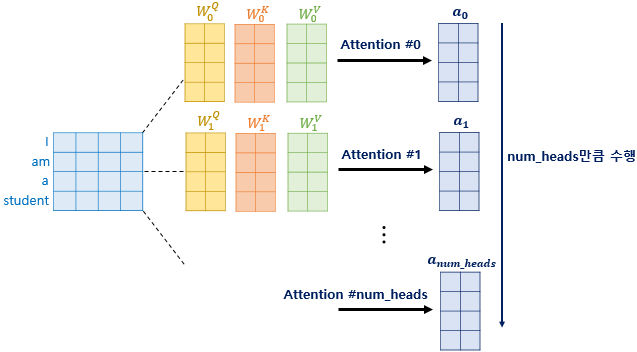
3. Multi-head Attention 🤯
💡 Why Multi-head?
여러 개의 Attention head = `여러 개의 시각`즉, 다양한 시각에서 유사도 정보를 수집하기 위함
3-1. Multi-head
Multi-head Attention example, Attention head의 개수 = num_heads
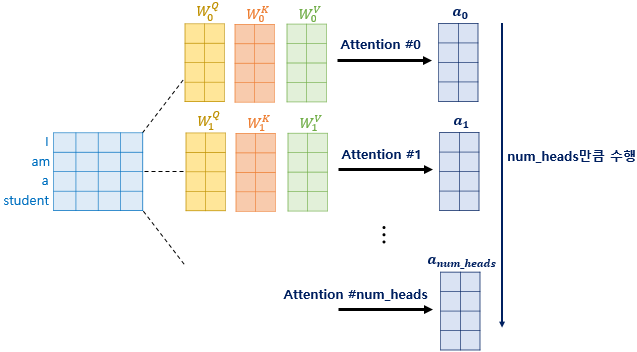
-
어텐션 헤드의 개수만큼 병렬 어텐션 연산
- 각 Attention 값 행렬 =
Attention head- 각 Attention head의 가중치 행렬 값은 모두 다른 값
- 각 Attention 값 행렬 =
-
연산 절차
-
각기 다른 가중치 행렬을 이용한 병렬 어텐션 수행
- Return
Attention head
- Return
-
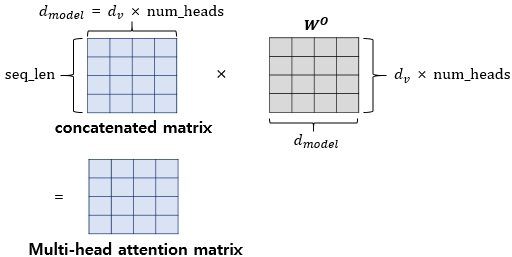
모든 Attention head 연결
- Return
concatenated matrix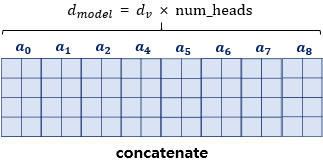
- Return
-
가중치 행렬 곱하기
-
Return
Multi-head Attention Matrix- Input 문장 행렬과
동일 크기 유지
- Input 문장 행렬과
-
-
💭 Matrix 크기가 유지되어야 하는 이유?
- Transformer - 동일한 구조의 `encoder`를 6 layer 쌓은 구조 ⇒ 다음 `encoder`에 다시 입력되기 위함
