Summary !
💭 (입력값, 직전까지 계산된 히든벡터)를 기반으로,
개별 또는 순차 데이터를 처리하여 예측을 수행하는 "재귀적" 모델
Sequence dataRecursive
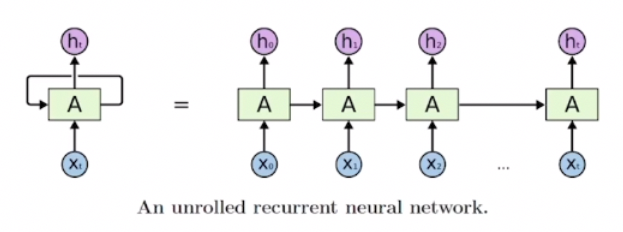
1. RNN model structure 🔒
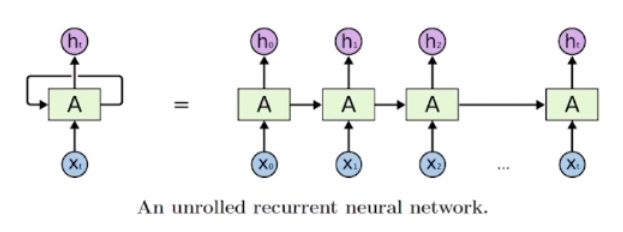
“The same function and set of parameters are used at every time step.”
- 각 단계마다 동일한 모듈 A가 재귀적으로 호출되며, 이전 스텝의 출력이 다음 스텝의 입력으로 사용된다.
- N-1 step's output → N step's input
RNN Function & Parameters
RNN의 기본 함수는 다음과 같으며, 이를 통해 매 스텝마다 hidden state 가 갱신된다.
: 현재 스텝()에서의 Input data
: 직전 스텝()까지 계산된 Hidden-state vector
: Hidden-state vectoroutputat
-
:
RNN function, 에서의 Hidden state vector ()를 출력한다.- : Linear transformation matrix → 선형 변환 수행
-
:
Outputvector at , based on
Hidden state vector () 연산
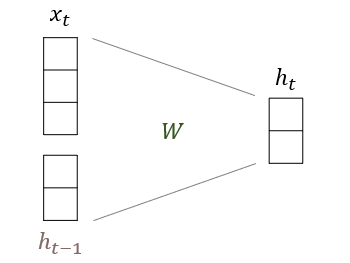
가정 :
타임 , 입력 벡터 와 이전 타임스텝의 출력 벡터 의 크기를 각각
-
라고 가정하면,
-
FC layer의 선형 변환 matrix W는, 임을 알 수 있다.
(의 크기 역시 와 동일하게 유지되어야 하기 때문)
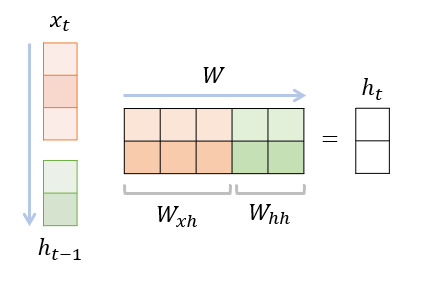
연산 과정 :
은 와 내적을 거친다. 이때,
-
Matrix 의 좌측 은, 벡터와만 계산된다.
-
마찬가지로, Matrix 의 우측 은, 벡터와만 계산된다.
즉, 으로, 변환을 수행한다.
이후 task에 따라 추가적인 Output layer의 선형 변환 Matrix 와 곱하여 - 최종 Ouput 가 출력된다.- 마찬가지로, 의 변환을 수행한다.
- 의 활용
- Binary classification : (1차원, 스칼라값) → sigmoid func → 확률값
- Multi-class classification : (class 수 만큼의 차원을 가지는 벡터) → softmax → 확률분포
2. 다양한 RNN models ➰
Many or One ?
: 태스크와 데이터에 맞는 구조로 조합하여 이용한다.
Many <- Sequential data
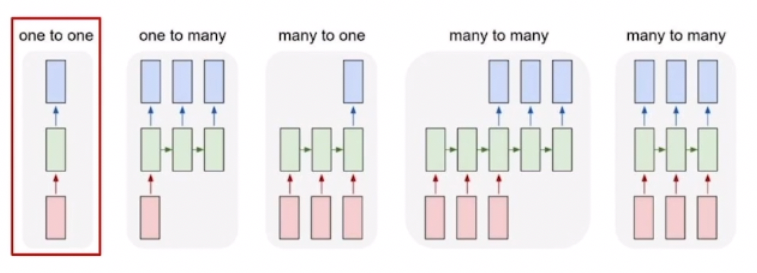
< 5 differenct models from RNN >
1. One to One
- 입력, 출력의 타임스텝 = 1
- Sequence data X
- (키, 몸무게, 나이) ⇒ 저혈압, 고혈압 분류
2. One to Many
- 입력만 하나의 타임스텝
- 다음 스텝의 입력이 없는 경우, 동일 크기의 0 값을 input
- Image captioning task (1 img ⇒ sequential words)
3. Many to One
- 출력만 하나의 타입스텝
- 매 타임스텝에 Sequential data input, 마지막 스텝에 output
- Sentiment classification (sequential words ⇒ pos / neg)
4. Many to Many (1)
- 입력, 출력 데이터가 모두 연속적
- 입력 데이터를 모두 받은 후, 출력 데이터 생성
- Machine translation
5. **Many** to **Many** (2)
- 입력, 출력 데이터가 모두 연속적
- 입력이 주어지는 매 타임스텝마다 예측 출력을 수행
- 실시간성 요구 task : video classification - frame level
- 단어별 문장성분 예측!
