
상황: 연관된 엔티티가 많을 때, 연관된 엔티티까지 조회하여 페이징처리 할 때
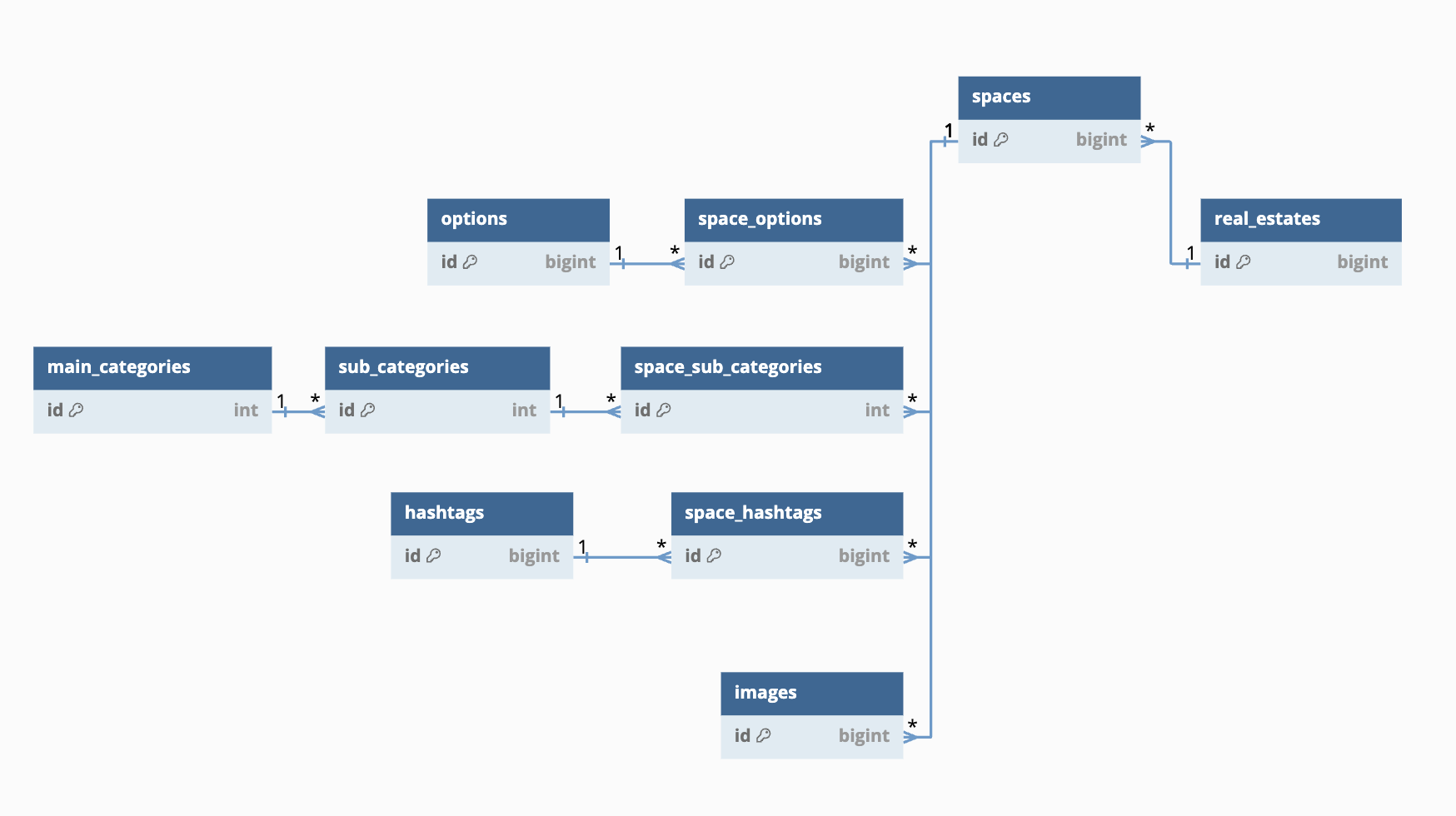
- 프로젝트 DB 구조는 위와 같았다. 공간 정보와 연관된 엔티티를 조회하면서 페이징 처리를 했는데 JPA가 만들어주는 쿼리는 심히 당황스러웠다. 페이징을 위한 쿼리 2개와 일대다 연관된 엔티티(4개)를 각각 조인해서 가져오는 쿼리 4개, 총 6개를 예상했지만 실제로는 52개의 쿼리가 발생하고 있었다. 연관 엔티티를 가져올 때 N+1문제가 발생하는 것이다.
### 1. 페이징 쿼리 (2개)
select
count(s1_0.id)
from
spaces s1_0;
select
s1_0.id,s1_0.closing_time, ...
from
spaces s1_0
limit
0,10;
### 2. space, realEstate
select
re1_0.id,re1_0.dong,re1_0.jibun_address,re1_0.road_address,re1_0.sido,re1_0.sigungu,re1_0.deleted_at,re1_0.floor,re1_0.has_elevator,re1_0.has_parking,re1_0.user_id
from
real_estates re1_0
where re1_0.id=1;
// 10개의 쿼리 반복
### 3. space와 spaceImage (값 컬렉션)
select
ip1_0.space_id,ip1_0.image_paths
from
space_images ip1_0
where
ip1_0.space_id=1;
// 10개의 쿼리 반복
### 4. space, SpaceOption, Option (OneToMany, ManyToOne)
select
so1_0.space_id,so1_0.option_id,o1_0.id,o1_0.name
from
space_options so1_0
left join
options o1_0 on o1_0.id=so1_0.option_id
where so1_0.space_id=1;
// 10개의 쿼리 반복
### 5. space, subCategory, MainCategory
select
sc1_0.space_id,sc1_1.id,sc1_1.main_category_id,mc1_0.id,mc1_0.name,sc1_1.name
from
space_sub_categories sc1_0
join
sub_categories sc1_1 on sc1_1.id=sc1_0.sub_category_id
left join
main_categories mc1_0 on mc1_0.id=sc1_1.main_category_id
where
sc1_0.space_id=1;
// 10개의 쿼리 반복
### 6. space, hashtag
select
h1_0.space_id,h1_1.id,h1_1.name
from
space_hashtags h1_0
join
hashtags h1_1 on h1_1.id=h1_0.hashtag_id
where h1_0.space_id=1;
// 10개의 쿼리 반복어떻게 연관된 엔티티를 한 번에 가져올 수 있을까?
1. fetch join
- fetch join이란 연관관계에 있는 엔티티를 한 번에 조인해서 가져오는 것을 말한다. 다대일 관계에선 결과 행이 변함이 없기 때문에 여러 다대일 관계를 fetch join해도 문제가 생기지 않는다. 하지만, 일대다 관계에선 아래와 같은 문제가 생긴다.
1) 메모리에서 페이징
- 일대다 연관관계 엔티티와 fetch join하게 되면, 페이징은 ‘일’을 기준으로 하려고 하지만 행은 ‘다’를 기준으로 생성된다. 따라서 조인된 결과 데이터는 예상보다 많아진다. 따라서 JPA는 일대다 엔티티를 페이징할 때 데이터베이스 레벨에서 수행하지 않고 애플리케이션 메모리에서 수행하고 다음과 같은 경고를 띄운다.
- 즉, 페이징 할 데이터가 많다면 OutOfMemory로 시스템이 갑자기 종료될 수 있다.
firstResult/maxResults specified with collection fetch; applying in memory - sql 쿼리를 보면 limit절이 없어진 것을 확인할 수 있다.
- 즉, 페이징 할 데이터가 많다면 OutOfMemory로 시스템이 갑자기 종료될 수 있다.
select
s1_0.id,s1_0.closing_time, ...
from
spaces s1_0
left join
space_options so1_0 on s1_0.id=so1_0.space_id
left join
options o1_0 on o1_0.id=so1_0.option_id
// limit ?- 실제로 공간과 옵션을 조인하여 페이징 쿼리를 실행했을 때 10개가 보여야 할 데이터가 2개만 보였다. join 과정에서 중복된 데이터가 생기고, 이를 제거하는 과정에서 반환되어야 할 데이터가 없어진 것이다. 즉, 페이징 쿼리와 fetch join 쿼리는 분리되어 실행되어야 한다.
2) 두 개 이상 fetch join하지 못함
- 메모리 문제뿐만 아니라 JPA에서는 두 개 이상의 일대다 관계를 fetch join하지 못한다. 그 이유는 JPA는 객체와의 관계 또한 추적하고 있어, 일대다 컬렉션이 늘어날수록 카티시안 곱이 생겨 메모리에 저장해야 할 데이터가 기하급수적으로 증가하기 때문이다. 따라서, JPA에서는 하나의 fetch join만 가능하다.
- 여러 개의 일대다 엔티티 또는 컬렉션을 fetch join하게 되면 아래와 같은 에러를 만난다.
org.hibernate.loader.MultipleBagFetchException: cannot simultaneously fetch multiple bags: [com.juny.spacestory.space.domain.Space.imagePaths, com.juny.spacestory.space.domain.Space.questions2. BatchSize, EntityGraph
1) 일대다 관계
- 그럼 일대다 관계에 있는 연관 엔티티를 가져올 때, 한 번에 가지고 올 개수를 정하여 N+1문제를 완화할 수 있다. 이는 @BatchSize 어노테이션으로 가능하다.
@OneToMany(mappedBy = "space", cascade = CascadeType.ALL, orphanRemoval = true)
@BatchSize(size = 10)
private List<SpaceOption> spaceOptions = new ArrayList<>();select
so1_0.space_id,so1_0.option_id,o1_0.id,o1_0.name
from
space_options so1_0
left join
options o1_0 on o1_0.id=so1_0.option_id
where
so1_0.space_id in (1,2,3,4,5,6,7,8,9,10);- 여기서 N+1문제를 해결할 수 있다고 말하지 않은 이유는 BatchSize에 따라 쿼리 발생 횟수가 달라지기 때문이다.
- BatchSize가 10인데, 가져와야 할 데이터가 100개라면? N+1 문제는 아니더라도 N/BatchSize + 1 문제가 발생한다.
- 그렇다면, BatchSize를 아주 크게 잡으면 되지 않을까?
- OutOfMemory 에러로 프로그램이 갑자기 종료될 수 있다. 또한 JPA 영속성 컨텍스트의 1차 캐시가 커져 느려질 수 있으며, 대용량 데이터로 캐시가 덮어 쓰여 cache hit rate가 떨어질 수 있다.
2) 다대일 관계
- 다대일 관계에서는 @Batch Size를 적용할 수 없다. 아래와 같은 에러가 발생한다.
Property 'realEstate' may not be annotated '@BatchSize'- 위에서 언급한 대로 다대일 관계에서는 fetch join으로 연관된 엔티티를 한 번에 가져와도 결과 행이 많아지지 않기 때문에 안전하다. 여러 번의 fetch join도 문제가 되지 않는다.
List<Space> spaces = queryFactory.selectFrom(space)
.leftJoin(space.realEstate, realEstate).fetchJoin()
.offset(page * size)
.limit(size)
.fetch();- @EntityGraph를 사용하면 특정 엔티티를 조회할 때 연관된 엔티티를 명시적으로 함께 가져올 수 있다.
@NamedEntityGraph(name = "Space.withRelations", attributeNodes = {
@NamedAttributeNode("realEstate"),
})
public class Space {
...
}
public interface SpaceRepository extends JpaRepository<Space, Long>, CustomSpaceRepository {
@EntityGraph(value = "Space.withRelations", type = EntityGraph.EntityGraphType.LOAD)
Page<Space> findAll(Pageable pageable);
...
}- N+1 문제가 발생하여 52개의 쿼리가 발생했지만, @BatchSize와 @EntityGraph를 적용하면 6개의 쿼리로 모든 정보를 가져오는 것을 확인할 수 있다
## 1. 공간 페이징 쿼리(다대일 엔티티는 fetch join)
select
s1_0.id,s1_0.closing_time, ...
from
spaces s1_0
left join
real_estates re1_0 on re1_0.id=s1_0.real_estate_id limit 0,10;
## 2. 전체 개수
select count(s1_0.id) from spaces s1_0;
## 3. 공간 - 이미지
select
ip1_0.space_id,ip1_0.image_paths
from
space_images ip1_0
where
ip1_0.space_id in (1,2,3,4,5,6,7,8,9,10);
## 4. 공간 - 옵션
select
so1_0.space_id,so1_0.option_id,o1_0.id,o1_0.name
from
space_options so1_0
left join
options o1_0 on o1_0.id=so1_0.option_id
where
so1_0.space_id in (1,2,3,4,5,6,7,8,9,10);
## 5. 공간 - 카테고리
select
sc1_0.space_id,sc1_1.id,sc1_1.main_category_id,mc1_0.id,mc1_0.name,sc1_1.name
from
space_sub_categories sc1_0
join
sub_categories sc1_1 on sc1_1.id=sc1_0.sub_category_id
left join
main_categories mc1_0 on mc1_0.id=sc1_1.main_category_id
where sc1_0.space_id in (1,2,3,4,5,6,7,8,9,10);
## 6. 공간 - 해시태그
select
h1_0.space_id,h1_1.id,h1_1.name
from
space_hashtags h1_0
join
hashtags h1_1 on h1_1.id=h1_0.hashtag_id
where
h1_0.space_id in (1,2,3,4,5,6,7,8,9,10);cf. BatchSize vs 서브쿼리
- 전자는 단순하고, batchSize가 작을수록 빠르게 동작한다 (물론 쿼리는 많이 실행된다). 서브쿼리는 space와 real_estate 테이블이 클수록 더 느리게 동작한다. 전체 요소를 가져오는 데 있어 훨씬 유연하게 동작하지만, 조건이 추가될수록 쿼리가 복잡하기에 유지보수 하기 어려워진다.
// BatchSize
SELECT ip1_0.space_id, ip1_0.image_paths
FROM space_images ip1_0
WHERE ip1_0.space_id IN (1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
// 서브쿼리
SELECT ip1_0.space_id, ip1_0.image_paths
FROM space_images ip1_0
WHERE ip1_0.space_id IN (
SELECT s1_0.id
FROM spaces s1_0
LEFT JOIN real_estates re1_0 ON re1_0.id = s1_0.real_estate_id
);3. 쿼리 분리 (Mybatis)
- 그런데, 쿼리를 더 줄일 수 있지 않을까? 공간 번호를 페이징 처리해서 가져오고, 가져온 공간 번호에 대한 연관된 엔티티를 join해서 한 번에 가져오는 것이다.
- 하지만 JPA를 사용해서 쿼리를 분리해도 일대다 연관관계에 있는 엔티티를 가져올 때 N+1문제가 발생한다. 그럼 단순히 SQL을 사용하는 (객체 관계를 추적하지 않는) Mybatis를 이용하면 되지 않을까? 물론 JPA의 NativeQuery도 가능하지만 Mybatis를 사용하면 SQL을 사용하면서 동적 쿼리도 손쉽게 만들수 있으며, 객체 매핑도 편리하다.
// 전체 사이즈 가져오는 쿼리
SELECT COUNT(*) FROM spaces;
// 조회할 공간 아이디를 가져오는 쿼리
SELECT id FROM spaces ORDER BY id LIMIT 10 OFFSET 0;
// 공간 정보와 연관된 엔티티를 한 번에 가져오는 쿼리
SELECT
s.id AS space_id,
...,
r.id AS real_estate_id,
...,
si.image_paths AS image_paths,
o.id AS option_id,
o.name AS option_name,
so.space_id AS space_option_space_id,
sc.id AS sub_category_id,
sc.name AS sub_category_name,
mc.id AS main_category_id,
mc.name AS main_category_name,
h.id AS hashtag_id,
h.name AS hashtag_name
FROM
spaces s
LEFT JOIN
real_estates r ON s.real_estate_id = r.id
LEFT JOIN
space_images si ON s.id = si.space_id
LEFT JOIN
space_options so ON s.id = so.space_id
LEFT JOIN
options o ON so.option_id = o.id
LEFT JOIN
space_sub_categories ssc ON s.id = ssc.space_id
LEFT JOIN
sub_categories sc ON ssc.sub_category_id = sc.id
LEFT JOIN
main_categories mc ON sc.main_category_id = mc.id
LEFT JOIN
space_hashtags sh ON s.id = sh.space_id
LEFT JOIN
hashtags h ON sh.hashtag_id = h.id
WHERE
s.id IN ( 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 );쿼리 수가 적다고 해서 무조건 빠른 건 아니라는 것을 명심하자! 쿼리 수가 적어짐에 따라 DB 연산에 부하가 크다면 더 느려질 수도 있다. 하지만, 네트워크 통신인 DB 쿼리는 애플리케이션 연산 속도보다 느리기 때문에 가급적 쿼리 수를 줄이는 것이 좋다.

꾸준하게