
배치
- 배치란 주기적으로 <대량>의 반복적인 데이터 작업을 처리하기 위해 사용하는 방식
배치가 필요한 상황
- 대량의 집계 데이터 생성(ex: 월별 매출, 월별 환불액, 한 달 동안 신규 회원 수, 월간 상품별 판매량 …)
- DB에 있는 대량의 데이터를 백업 용도로 새로운 서버에 저장할 때
- 특정 조건(ex: 30일 연속 출석, 특정 답변 개수마다 등급, 매달 말 예금에 대한 이자…)을 맞춘 다수의 사용자들에게 보상 지급할 때
- 다수의 사용자에게 광고 이메일, 공지 사항을 보낼 때
어떤 이벤트가 발생하자마자 즉각적으로 처리를 해야 하는 실시간 작업이 아니라면, 데이터를 모아 일괄적으로 처리하면 아래와 같은 이점을 누릴 수 있다.
- 모아서 처리하기 때문에 더 적은 DB 접근(네트워크 접근)이 가능
- 서버 유휴 시간에 배치 프로세스 실행하면 서버 자원을 효율적으로 사용
꼭 스프링 배치를 사용해야 할까?
1. 배치 작업 중간에 에러가 발생했다면?
- 처음부터 다시 작업을 시작하는 건 굉장히 비효율적이다.
- 중복해서 처리되면 안 되는 경우(ex: 보상 지급) 실패 지점까지는 건너뛰거나 롤백해야 한다.
- 물론, 스프링 배치 프레임워크를 사용하지 않고 특정 배치 작업을 실행할 ID, 진행 지점을 파일에 기록한 뒤 실패했다면 파일을 읽어 실패했던 부분 이후부터 재개할 수 있다. 또는 진행한 부분까지 롤백하는 로직을 직접 구현할 수 있다.
2. 더 많은 요구사항
- 특정 작업을 중복해서 실행하고 싶지 않다면? 조건마다 처리할 작업을 다르게 하고 싶다면?
- 실패했을 경우 재시도할 횟수를 지정하고 싶다면?
- 실패해도 치명적이지 않은 에러는 무시하고 진행하고 싶다면?
- 트랜잭션으로 묶이는 작업이 많다면? 배치 작업마다 트랜잭션 격리 수준을 지정하고 싶다면?
- …
- 이러한 기능들을 사용자가 일일이 구현해야 한다.
- 스프링 배치 프레임워크를 이용하면 대량의 데이터를 효율적으로 처리하면서도 데이터의 무결성을 유지할 수 있는 다양한 방법을 제공한다.
스프링 배치 구조
- 배치는 읽고, 처리하고, 쓰는 작업을 반복적으로 실행한다. 여러 배치 작업(Job)이 존재할 수 있고 하나의 작업은 여러 독립적인 단계(Step)를 가질 수 있다. 각 단계는 읽고, 처리하고, 쓰는 작업을 반복한다.
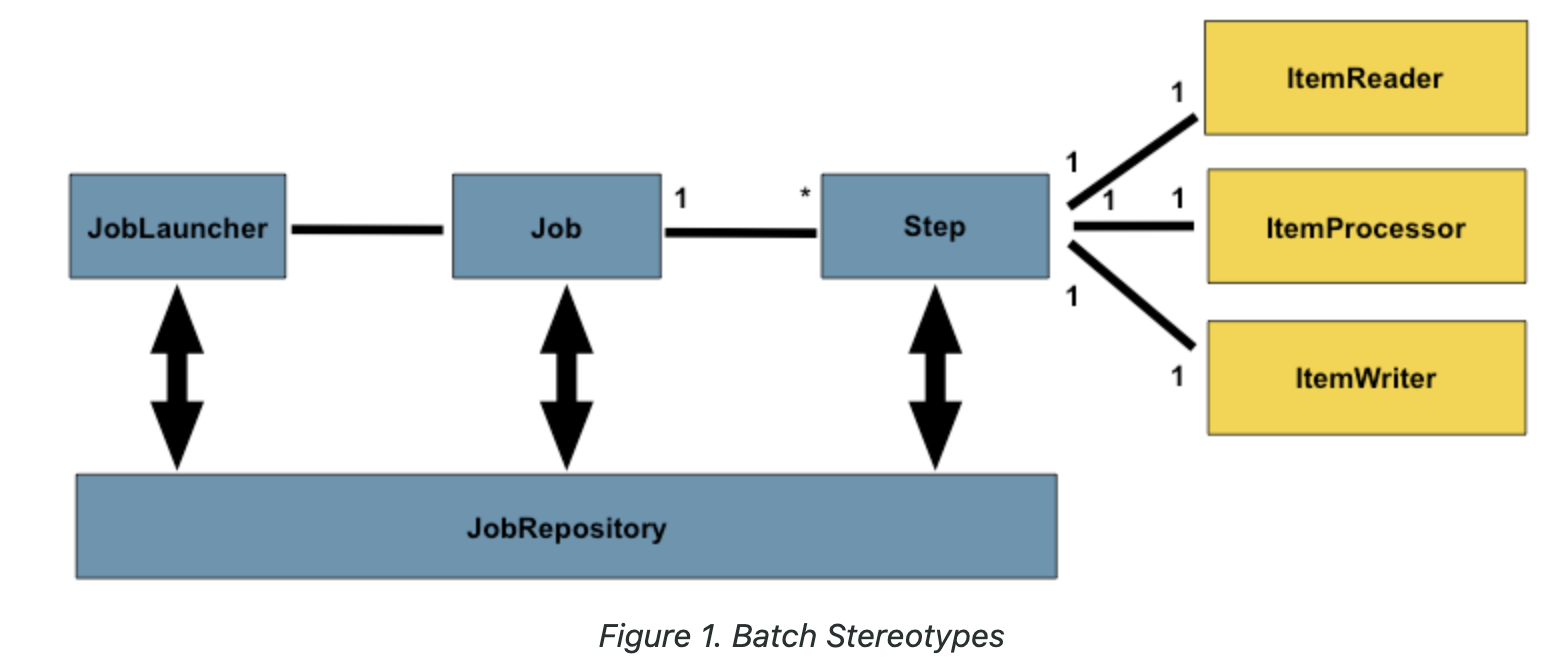
1. JobLauncher
@FunctionalInterface
public interface JobLauncher {
JobExecution run(Job job, JobParameters jobParameters) throws JobExecutionAlreadyRunningException, JobRestartException, JobInstanceAlreadyCompleteException, JobParametersInvalidException;
}
public interface JobRegistry extends ListableJobLocator {
void register(JobFactory jobFactory) throws DuplicateJobException;
void unregister(String jobName);
}- 스프링 배치 작업(Job)을 시작하는 인터페이스이다. 실행할 작업(Job)과 파라미터(jobParameter)를 받는다. jobParameter를 토대로 실행할 작업 식별한다. 같은 파라미터를 사용하면 동일한 작업으로 인식한다.
- JobRegistry에 있는 여러 작업 정보를 토대로 실행할 배치 작업(Job)을 실행한다.
- 일반적으로 스케줄러 또는 컨트롤러에서 JobLauncher와 JobRegistry를 주입받아 사용한다.
@Configuration
@RequiredArgsConstructor
public class AggregationScheduler {
private final JobLauncher jobLauncher;
private final JobRegistry jobRegistry;
@Scheduled(cron = "0 0 2 15 * *", zone = "Asia/Seoul")
public void getSalesAndRefunds() throws Exception {
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM");
String date = dateFormat.format(new Date());
JobParameters jobParameters = new JobParametersBuilder()
.addString("date", date)
.toJobParameters();
jobLauncher.run(jobRegistry.getJob("saleAggregationJob"), jobParameters);
}
}
2. Job
- Job은 하나의 배치 작업을 말하며, 배치 처리 기본 단위이다.
- 하나의 Job은 여러 개의 Step(독립적인 처리 단위)으로 구성된다.
@Bean
public Step cancelPendingOrdersStep() {
return new StepBuilder("cancelPendingOrdersStep", jobRepository)
.<Order, Order>chunk(10, platformTransactionManager)
.reader(pendingOrdersReader())
.processor(pendingOrdersProcessor())
.writer(pendingOrdersWriter())
.build();
}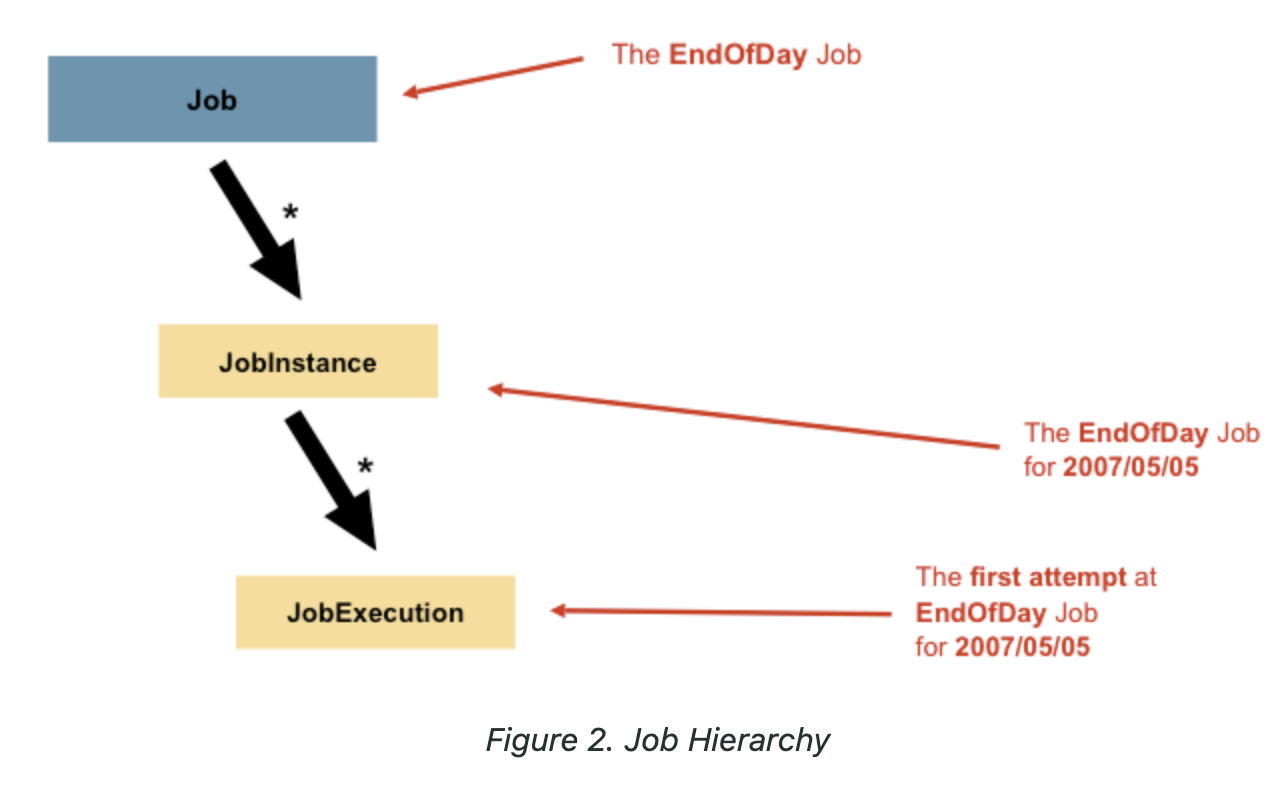
- 하나의 Job으로부터 파라미터 값을 이용하여 여러 JobInstance를 만들 수 있으며, JobInstance로 실제 실행을 할 수 있다. 재시도, 재시작 등의 이유로 하나의 JobInstance는 여러 개의 JobExecution(실행)을 가질 수 있다.
// job이름과 job 파라미터로 jobInstance 생성
public interface JobRepository {
...
JobInstance createJobInstance(String jobName, JobParameters jobParameters);
}
// job과 JobParameter에 관해 JobExecution 반환
public interface JobLauncher {
JobExecution run(Job job, JobParameters jobParameters) throws JobExecutionAlreadyRunningException, JobRestartException, JobInstanceAlreadyCompleteException, JobParametersInvalidException;
}3. Step
- Job 내에서 실행되는 독립적인 처리 단위로, 읽고 처리하고 쓰는 단계를 반복한다.
@Bean
public Step cancelPendingOrdersStep() {
return new StepBuilder("cancelPendingOrdersStep", jobRepository)
.<Order, Order>chunk(10, platformTransactionManager)
.reader(pendingOrdersReader())
.processor(pendingOrdersProcessor())
.writer(pendingOrdersWriter())
.build();
}
@Bean
public RepositoryItemReader<Order> pendingOrdersReader() {
LocalDateTime oneMonthAgo = LocalDateTime.now().minusMonths(1);
return new RepositoryItemReaderBuilder<Order>()
.name("pendingOrdersReader")
.repository(orderRepository)
.methodName("findByStatusAndCreatedAtBefore")
.arguments(OrderStatus.결제대기, oneMonthAgo)
.pageSize(10)
.sorts(Map.of("createdAt", Sort.Direction.ASC))
.build();
}
@Bean
public ItemProcessor<Order, Order> pendingOrdersProcessor() {
return order -> {
if (order.getCreatedAt().isBefore(LocalDateTime.now().minusDays(7))) {
order.ChangeOrderStatus(OrderStatus.결제만료);
}
return order;
};
}
@Bean
public RepositoryItemWriter<Order> pendingOrdersWriter() {
return new RepositoryItemWriterBuilder<Order>()
.repository(orderRepository)
.methodName("save")
.build();
}- 읽기 → 처리 → 쓰기 작업은 청크 단위로 진행되는데, 대량의 데이터를 얼만큼 끊어서 처리할지에 대한 값으로 적당한 값을 선정
한 번에 굉장히 많은 양을 읽는다면 위험성이 크다. (OOM 위험, 작업 실패지점까지 데이터를 다시 읽고 처리하는 데 오래 걸릴 수 있음) 만약, 작은 양을 읽는다면 빈번한 I/O 요청 및 네트워크 요청이 발생한다. 서버 자원에 따라 테스트를 통해 적절한 값으로 설정한다.
@FunctionalInterface
public interface ItemReader<T> {
@Nullable
T read() throws Exception, UnexpectedInputException, ParseException, NonTransientResourceException;
}
@FunctionalInterface
public interface ItemProcessor<I, O> {
@Nullable
O process(@NonNull I item) throws Exception;
}
@FunctionalInterface
public interface ItemWriter<T> {
void write(@NonNull Chunk<? extends T> chunk) throws Exception;
}- ItemReader, ItemProcessor, ItemWriter로 인터페이스를 제공하며, 다양한 구현체를 제공함. (JDBC, JPA, …)
스프링 배치 메타데이터 테이블
- 스프링 배치에서 배치 작업을 실행할 때 사용하는 테이블을 말한다. 어떤 배치 작업을 실행하는지, 언제 실행했는지 등 다양한 정보를 추적하고 관리한다.
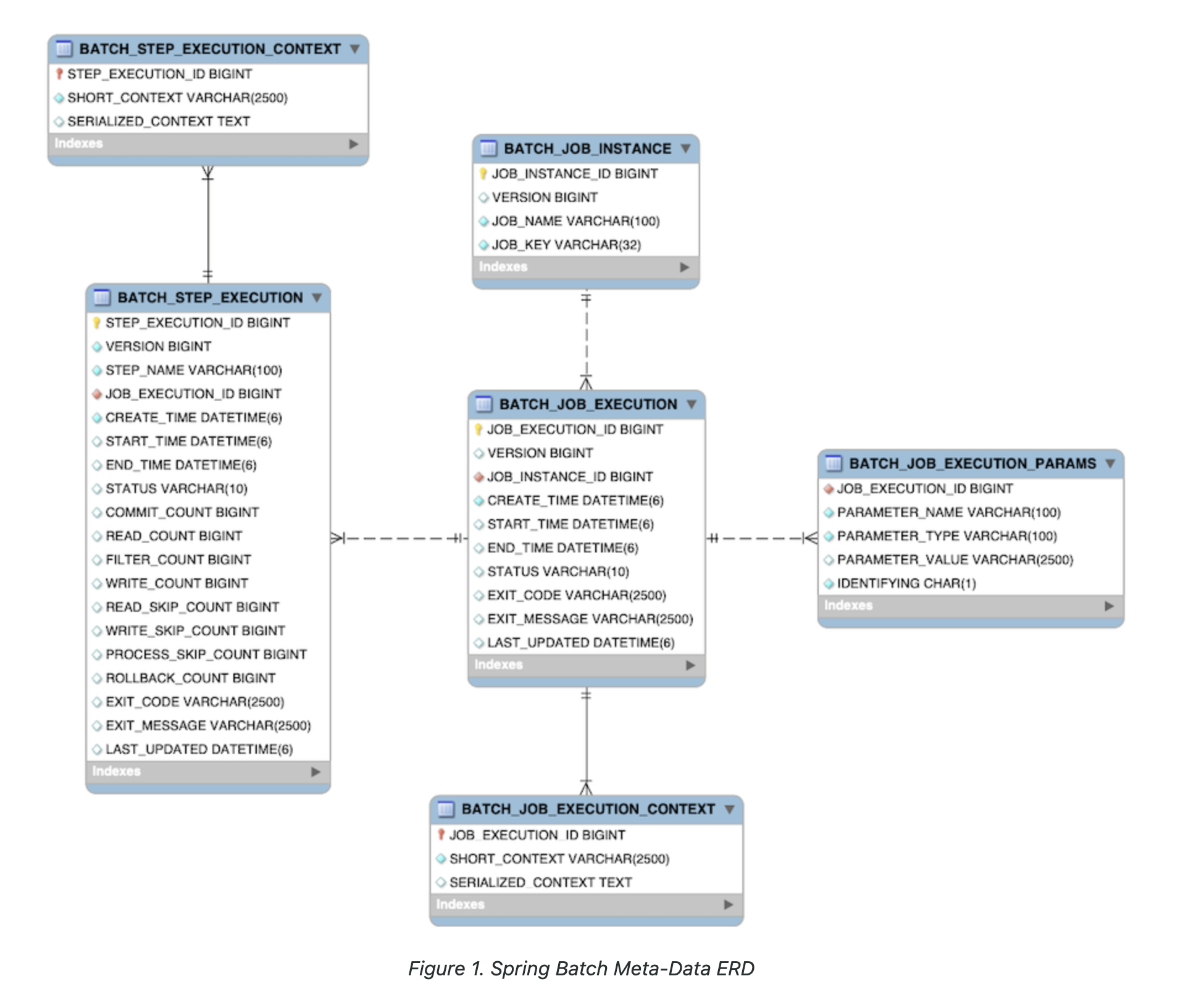
1. BATCH_JOB_INSTANCE
- 배치 작업(Job)의 인스턴스를 관리한다.
- 주요 필드
JOB_INSTANCE_ID: 작업 인스턴스의 고유 식별자JOB_NAME: 작업의 이름JOB_KEY: 작업의 고유 키 (파라미터에 기반하여 생성됨)
SELECT JOB_INSTANCE_ID, JOB_NAME
FROM BATCH_JOB_INSTANCE
WHERE JOB_NAME = 'firstJob' AND JOB_KEY = '5bafbcc37c869ccbab63a820955f1cec';
// JOB_NAME, JOB_KEY가 일치하는 JOB_INSTANCE_ID와 JOB_NAME 가져옴INSERT INTO BATCH_JOB_INSTANCE(JOB_INSTANCE_ID, JOB_NAME, JOB_KEY, VERSION)
VALUES (7, 'firstJob', 'ceda08b8a0eb8ede34b1e7b2cc83a66b', 0)
;
// 배치 잡 인스턴스 추가2. BATCH_JOB_SEQ
- 고유 식별자를 생성하고 관리한다.
- 주요 필드
ID: 시퀀스 값을 저장(파라미터에 따라 잡 인스턴스가 생성될 때마다 변경)UNIQUEKEY: 작업 종류 식별
UPDATE BATCH_JOB_SEQ
SET ID = LAST_INSERT_ID(ID + 1)
LIMIT 1;
// 마지막으로 삽입된 아이디 값 + 1로 ID 갱신3. BATCH_JOB_EXECUTION
- 각 단계 실행의 세부 정보 저장한다.
- 주요 필드
STEP_EXECUTION_ID: 단계 실행의 고유 식별자JOB_EXECUTION_ID: 관련된 작업 실행의 IDSTEP_NAME: 단계 이름START_TIME,END_TIME: 단계 실행의 시작 및 종료 시간STATUS: 단계의 상태COMMIT_COUNT,READ_COUNT,FILTER_COUNT,WRITE_COUNT: 각종 처리 정보
SELECT JOB_EXECUTION_ID, START_TIME, END_TIME, STATUS, EXIT_CODE, EXIT_MESSAGE, CREATE_TIME, LAST_UPDATED, VERSION
FROM BATCH_JOB_EXECUTION E
WHERE JOB_INSTANCE_ID = 6
AND JOB_EXECUTION_ID
IN (
SELECT MAX(JOB_EXECUTION_ID)
FROM BATCH_JOB_EXECUTION E2
WHERE E2.JOB_INSTANCE_ID = 6
);
// JOB_INSTANCE_ID 6이고, 가장 최근에 실행된 JOB_EXCUTION_ID에서 시작 시간, 종료 시간, 상태, 종료 메시지 등의 관련 정보 가져옴
SELECT JOB_EXECUTION_ID, START_TIME, END_TIME, STATUS, EXIT_CODE, EXIT_MESSAGE, CREATE_TIME, LAST_UPDATED, VERSION
FROM BATCH_JOB_EXECUTION
WHERE JOB_INSTANCE_ID = 6
ORDER BY JOB_EXECUTION_ID DESC;
// JOB_INSTANCE_ID 6에 대한 모든 작업 실행을 내림차순으로 검색 (가장 최근 잡 실행 목록)
INSERT INTO BATCH_JOB_EXECUTION(JOB_EXECUTION_ID, JOB_INSTANCE_ID, START_TIME, END_TIME, STATUS, EXIT_CODE, EXIT_MESSAGE, VERSION, CREATE_TIME, LAST_UPDATED)
VALUES (7, 7, NULL, NULL, 'STARTING', 'UNKNOWN', '', 0, '2024-08-14T13:19:15.578+0900', '2024-08-14T13:19:15.578+0900')
;
// 배치 잡 실행 로우 추가
SELECT VERSION
FROM BATCH_JOB_EXECUTION
WHERE JOB_EXECUTION_ID = 7;
// JOB_EXECUTION_ID가 7인 작업 실행의 버전을 조회
UPDATE BATCH_JOB_EXECUTION
SET
START_TIME = '2024-08-14T13:19:15.589+0900',
END_TIME = NULL,
STATUS = 'STARTED',
EXIT_CODE = 'UNKNOWN',
EXIT_MESSAGE = '',
VERSION = 1,
CREATE_TIME = '2024-08-14T13:19:15.578+0900',
LAST_UPDATED = '2024-08-14T13:19:15.590+0900'
WHERE
JOB_EXECUTION_ID = 7
AND VERSION = 0;
// JOB_EXECUTION_ID가 7이고 버전이 0인 작업 실행의 상태를 업데이트(STARTING->STARTED, 0 -> 1)4. BATCH_JOB_EXECUTION_PARMAS
- 작업 실행에 사용된 매개변수를 관리한다.
SELECT JOB_EXECUTION_ID, PARAMETER_NAME, PARAMETER_TYPE, PARAMETER_VALUE, IDENTIFYING
FROM BATCH_JOB_EXECUTION_PARAMS
WHERE JOB_EXECUTION_ID = 6;
// JOB_EXECUTION_ID가 6인 작업이 사용한 매개변수를 가져옴5. BATCH_STEP_EXECUTION
- 각 단계 실행의 세부 정보 관리한다.
- 주요 필드
STEP_EXECUTION_ID: 단계 실행의 고유 식별자JOB_EXECUTION_ID: 관련된 작업 실행의 IDSTEP_NAME: 단계 이름START_TIME,END_TIME: 단계 실행의 시작 및 종료 시간STATUS: 단계의 상태COMMIT_COUNT,READ_COUNT,FILTER_COUNT,WRITE_COUNT: 각종 처리 메트릭
SELECT STEP_EXECUTION_ID, STEP_NAME, START_TIME, END_TIME, STATUS, COMMIT_COUNT, READ_COUNT, FILTER_COUNT, WRITE_COUNT, EXIT_CODE, EXIT_MESSAGE, READ_SKIP_COUNT, WRITE_SKIP_COUNT, PROCESS_SKIP_COUNT, ROLLBACK_COUNT, LAST_UPDATED, VERSION, CREATE_TIME
FROM BATCH_STEP_EXECUTION
WHERE JOB_EXECUTION_ID = 6
ORDER BY STEP_EXECUTION_ID;
// JOB_EXECUTION_ID가 6인 작업 실행 내 각 단계의 실행 세부 정보를 검색
INSERT INTO BATCH_STEP_EXECUTION(STEP_EXECUTION_ID, VERSION, STEP_NAME, JOB_EXECUTION_ID, START_TIME, END_TIME, STATUS, COMMIT_COUNT, READ_COUNT, FILTER_COUNT, WRITE_COUNT, EXIT_CODE, EXIT_MESSAGE, READ_SKIP_COUNT, WRITE_SKIP_COUNT, PROCESS_SKIP_COUNT, ROLLBACK_COUNT, LAST_UPDATED, CREATE_TIME)
VALUES (7, 0, 'firstStep', 7, NULL, NULL, 'STARTING', 0, 0, 0, 0, 'EXECUTING', '', 0, 0, 0, 0, '2024-08-14T13:19:15.601+0900', '2024-08-14T13:19:15.600+0900')
;
// 스텝 실행 인스턴스 추가
UPDATE BATCH_STEP_EXECUTION
SET
START_TIME = '2024-08-14T13:19:15.606+0900',
END_TIME = NULL,
STATUS = 'STARTED',
COMMIT_COUNT = 0,
READ_COUNT = 0,
FILTER_COUNT = 0,
WRITE_COUNT = 0,
EXIT_CODE = 'EXECUTING',
EXIT_MESSAGE = '',
VERSION = 1,
READ_SKIP_COUNT = 0,
PROCESS_SKIP_COUNT = 0,
WRITE_SKIP_COUNT = 0,
ROLLBACK_COUNT = 0,
LAST_UPDATED = '2024-08-14T13:19:15.606+0900'
WHERE
STEP_EXECUTION_ID = 7
AND VERSION = 0;
// STEP_EXECUTION_ID가 7이고 버전이 0인 단계 실행의 상태를 업데이트6. BATCH_JOB_EXECUTION_CONTEXT
- 작업 실행의 컨텍스트 정보를 관리
- 주요 필드
JOB_EXECUTION_ID: 관련된 작업 실행의 IDSHORT_CONTEXT: 짧은 컨텍스트 정보SERIALIZED_CONTEXT: 직렬화된 컨텍스트 정보
SELECT SHORT_CONTEXT, SERIALIZED_CONTEXT
FROM BATCH_JOB_EXECUTION_CONTEXT
WHERE JOB_EXECUTION_ID = 6;
// JOB_EXECUTION_ID가 6인 작업 실행의 컨텍스트 정보 가져옴쿼리를 보고 어떻게 동작하는지 그림으로 표현해 보았다.
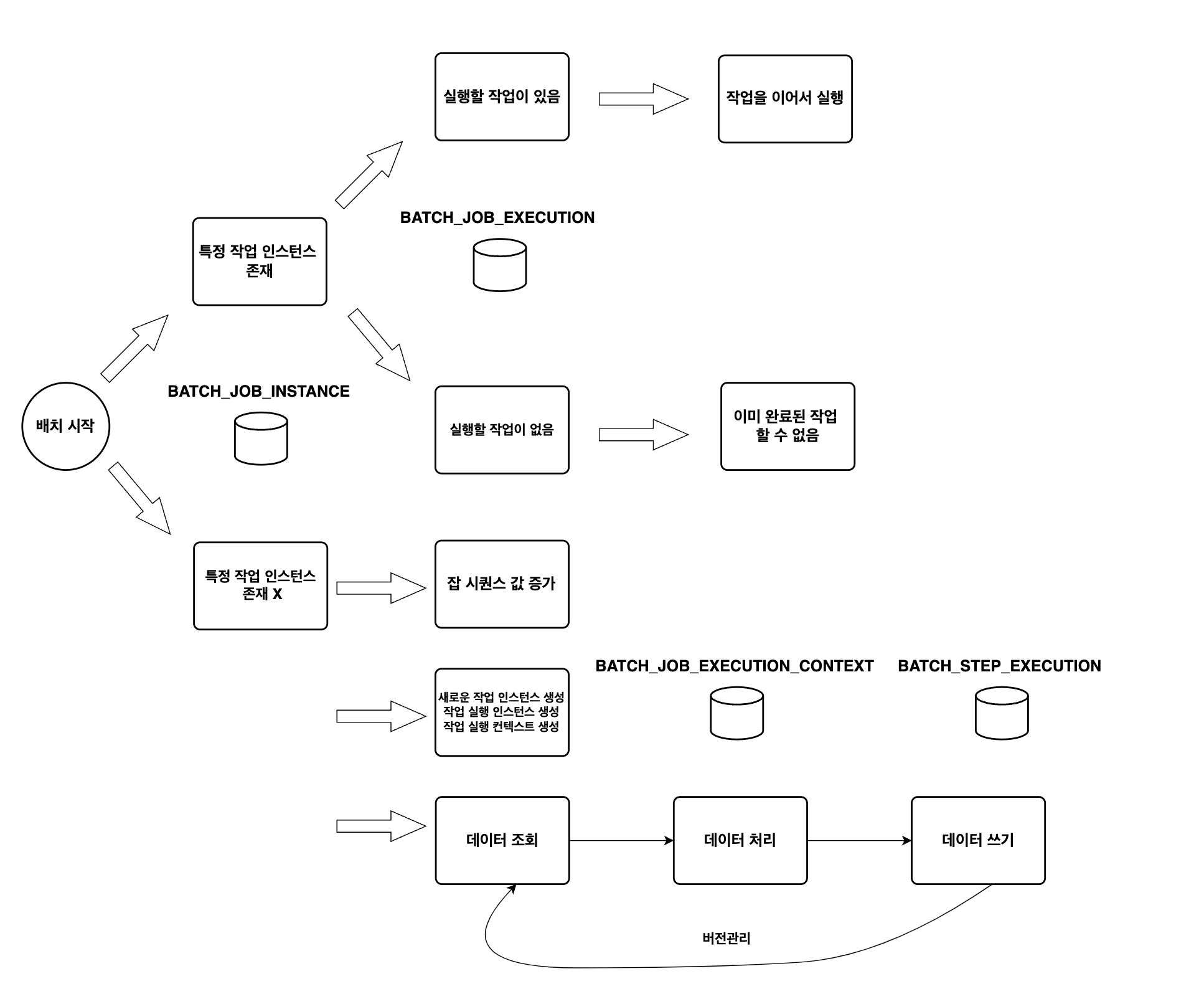
Job과 Step 세부 설정
1. Job
1) 순차적으로 실행하거나 조건에 따라 실행(Step Flow)
public Job footballJob(JobRepository jobRepository) {
return new JobBuilder("footballJob", jobRepository)
.start(playerLoad())
.next(gameLoad())
.next(playerSummarization())
.build();
}
@Bean
public Job job(JobRepository jobRepository, Step stepA, Step stepB, Step stepC, Step stepD) {
return new JobBuilder("job", jobRepository)
.start(stepA)
.on("*").to(stepB)
.from(stepA).on("FAILED").to(stepC)
.from(stepA).on("COMPLETED").to(stepD)
.end()
.build();
}2) 잡 실행 전후에 특정 작업 추가(Listener)
@Bean
public JobExecutionListener jobExecutionListener() {
return new JobExecutionListener() {
@Override
public void beforeJob(JobExecution jobExecution) {
JobExecutionListener.super.beforeJob(jobExecution);
}
@Override
public void afterJob(JobExecution jobExecution) {
JobExecutionListener.super.afterJob(jobExecution);
}
};
}
@Bean
public Job sixthBatch() {
return new JobBuilder("sixthBatch", jobRepository)
.start(sixthStep())
.listener(jobExecutionListener())
.build();
}
2. Step
1) Tasklet과 Chunk 단위로 읽어오는 방식
(1) Tasklet
- 단순한 작업을 하나의 Tasklet으로 정의하여 수행한다.
- 전체 작업을 하나의 트랜잭션으로 관리한다.
@Bean
public Step taskletStep(StepBuilderFactory stepBuilderFactory) {
return stepBuilderFactory.get("taskletStep")
.tasklet((contribution, chunkContext) -> {
// 간단한 작업 로직
return RepeatStatus.FINISHED;
})
.build();
}(2) Chunk 방식
- Chunk 방식은 데이터를 일정한 크기로 나누어 읽고, 처리하고, 저장하는 방식이다.
- Chunk 단위로 트랜잭션을 관리한다.
2) 특정 예외 건너뛰기, 다시 시도하기(Skip, Retry)
- Step의 과정 중 예외가 발생하게 되면 예외를 특정수까지 건너뛸 수 있도록 설정한다.
- Retry는 Step의 과정 중 예외가 발생하게 되면 예외를 특정수까지 반복할 수 있도록 설정한다.
@Bean
public Step skipStep() {
return new StepBuilder("skipStep", jobRepository)
.<BeforeEntity, AfterEntity> chunk(10, platformTransactionManager)
.reader(beforeSixthReader())
.processor(middleSixthProcessor())
.writer(afterSixthWriter())
.faultTolerant()
.skip(Exception.class)
.noSkip(FileNotFoundException.class)
.noSkip(IOException.class)
.skipLimit(10)
.build();
}
public Step retryStep() {
return new StepBuilder("retryStep", jobRepository)
.<BeforeEntity, AfterEntity>chunk(10, platformTransactionManager)
.reader(beforeReader())
.processor(processor())
.writer(afterWriter())
.faultTolerant()
.retry(Exception.class)
.retryLimit(3)
.noRetry(FileNotFoundException.class)
.noRetry(IOException.class)
.build();
}
3) WRITER 트랜잭션 제어
- Writer시 특정 예외에 대해 트랜잭션 롤백을 제외할 수 있다.
@Bean
public Step noRollbackStep(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder("noRollbackStep", jobRepository)
.<String, String>chunk(2, transactionManager)
.reader(itemReader())
.writer(itemWriter())
.faultTolerant()
.noRollback(ValidationException.class)
.build();
}4) Step 전후에 특정 작업 추가(Listener)
@Bean
public StepExecutionListener stepExecutionListener() {
return new StepExecutionListener() {
@Override
public void beforeStep(StepExecution stepExecution) {
StepExecutionListener.super.beforeStep(stepExecution);
}
@Override
public ExitStatus afterStep(StepExecution stepExecution) {
return StepExecutionListener.super.afterStep(stepExecution);
}
};
}
@Bean
public Step stepListerStep() {
return new StepBuilder("stepListerStep", jobRepository)
.<BeforeEntity, AfterEntity> chunk(10, platformTransactionManager)
.reader(beforeSixthReader())
.processor(middleSixthProcessor())
.writer(afterSixthWriter())
.listener(stepExecutionListener())
.build();
}
스프링 배치 실행 방법
1. 컨트롤러
@RestController
@RequiredArgsConstructor
public class BatchController {
private final JobLauncher jobLauncher;
private final JobRegistry jobRegistry;
@GetMapping("/jobs/cancel-orders")
public String firstApi(@RequestParam("value") String value) throws Exception {
JobParameters jobParameters = new JobParametersBuilder()
.addString("date", value)
.toJobParameters();
jobLauncher.run(jobRegistry.getJob("cancelPendingOrdersJob"), jobParameters);
return "ok";
}
}2. 스케줄러
@Configuration
@RequiredArgsConstructor
public class AggregationScheduler {
private final JobLauncher jobLauncher;
private final JobRegistry jobRegistry;
@Scheduled(cron = "0 0 2 15 * *", zone = "Asia/Seoul")
public void getSalesAndRefunds() throws Exception {
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM");
String date = dateFormat.format(new Date());
JobParameters jobParameters = new JobParametersBuilder()
.addString("date", date)
.toJobParameters();
jobLauncher.run(jobRegistry.getJob("salesAndRefundsJob"), jobParameters);
}
}
꾸준하게