
인덱스
데이터가 백만개, 천만개라면 아래 쿼리는 어떻게 동작할까?
SELECT * FROM users WHERE name = 'juny';- name에 Index가 걸려있지 않다면 전체 테이블을 찾는 과정(full scan)을 거친다. name에 Index가 있다면, 마치 이진 탐색처럼 동작하여 더 빨리 데이터를 찾아낼 수 있다.
왜 인덱스를 사용해야 할까?
SELECT * FROM users WHERE name = 'juny';
DELETE FROM spaces WHERE deleted_at < '2024.10.12';
UPDATE users SET is_totp_enabled = true WHERE id = 10;
SELECT * FROM users U JOIN question Q ON U.id = Q.id;- 조건을 만족하는 튜플(들)을 빠르게 조회, 정렬(order by), 그룹핑(group by)하기 위해 사용한다.
인덱스 사용하기
SELECT * FROM users WHERE name = 'juny';
CREATE INDEX name_idx ON users (name); - 만약 인덱스가 적용된 컬럼에 고유성을 보장하고 싶다면 UNIQUE 제약 조건을 부여한다.
SELECT * FROM users WHERE is_totp_enabled = false AND phone_number IS NOT NULL;
CREATE UNIQUE INDEX totp_enabled_phone_number_idx ON users (is_totp_enabled, phone_number);- 단순히 인덱스를 설정할 땐 테이블 밖에서 인덱스가 선언되지만, UNIQUE 제약 조건으로 인덱스를 부여했다면, 고유성을 보장하기 위해 테이블 안에서 인덱스가 생성되는 것을 확인할 수 있다.

사용 중인 인덱스 조회하기
SHOW INDEX FROM users;
- Index가 Unique 여부, 멀티 컬럼 인덱스 여부 등을 알려준다.
주의할 점
CREATE UNIQUE INDEX totp_enabled_phone_number_idx ON users (is_totp_enabled, phone_number);
SELECT * FROM users WHERE phone_number = '010-1234-5678';
SELECT * FROM users WHERE is_totp_enabled = false OR phone_number IS NOT NULL;- index가 먼저 is_totp_enabled 기준으로 정렬되고나서 phone_number 기준으로 정렬된다. 위의 phone_number만으로 쿼리를 조회하게 되면 index를 제대로 사용할 수 없기에 full scan을 하게된다.
- 마찬가지로 OR 조건일 때도 한 쪽 조건에 대해선 index가 제대로 동작하지만, 뒤에 있는 조건에 대해선 제대로 동작하지 않는다.
- 또한, 인덱스 키 값에 변형이 가해진 후 비교되는 경우 절대 B-TREE의 빠른 검색 기능을 사용할 수 없다. 이미 변형된 값은 B-TREE 인덱스에 존재하는 값이 아니다. 따라서 함수나 연산을 수행한 결과로 정렬한다거나 검색하는 작업은 B-TREE의 장점을 이용할 수 없다.
즉, 사용되는 query에 맞춰서 적절하게 Index를 걸어주어야 한다. 하지만, Index를 생성하면 데이터가 저장될 때마다 매번 정렬해야 하므로 저장하는 과정이 복잡하고 느려지게 된다. 인덱스는 저장 성능을 희생하고, 그 대신 데이터의 읽기 속도를 높이는 기능이라고 볼 수 있다.
Full Scan이 더 좋은 경우
- 인덱스를 통해 테이블의 레코드를 읽는 것은 인덱스를 거치지 않고 바로 테이블의 레코드를 읽는 것보다 높은 비용이 드는 작업이다.
- DBMS 옵티마이저에서는 인덱스를 통해 레코드 1건을 읽는 것이 테이블에서 직접 레코드 1건을 읽는 것보다 4~5배 정도 비용이 더 많이 드는 것으로 예측한다. 전체 테이블 레코드의 20~25%를 넘어서면 인덱스를 이용하지 않고 풀 스캔이 더 효율적일 수 있다.
BTREE 인덱스 동작 방식
- 자식이 두 개인 Binary Search Tree(이진 탐색 트리)를 더 일반화한 형태이다. 자녀 노드의 최대 개수를 상황에 맞게 결정하여 사용할 수 있다.
BTREE 인덱스
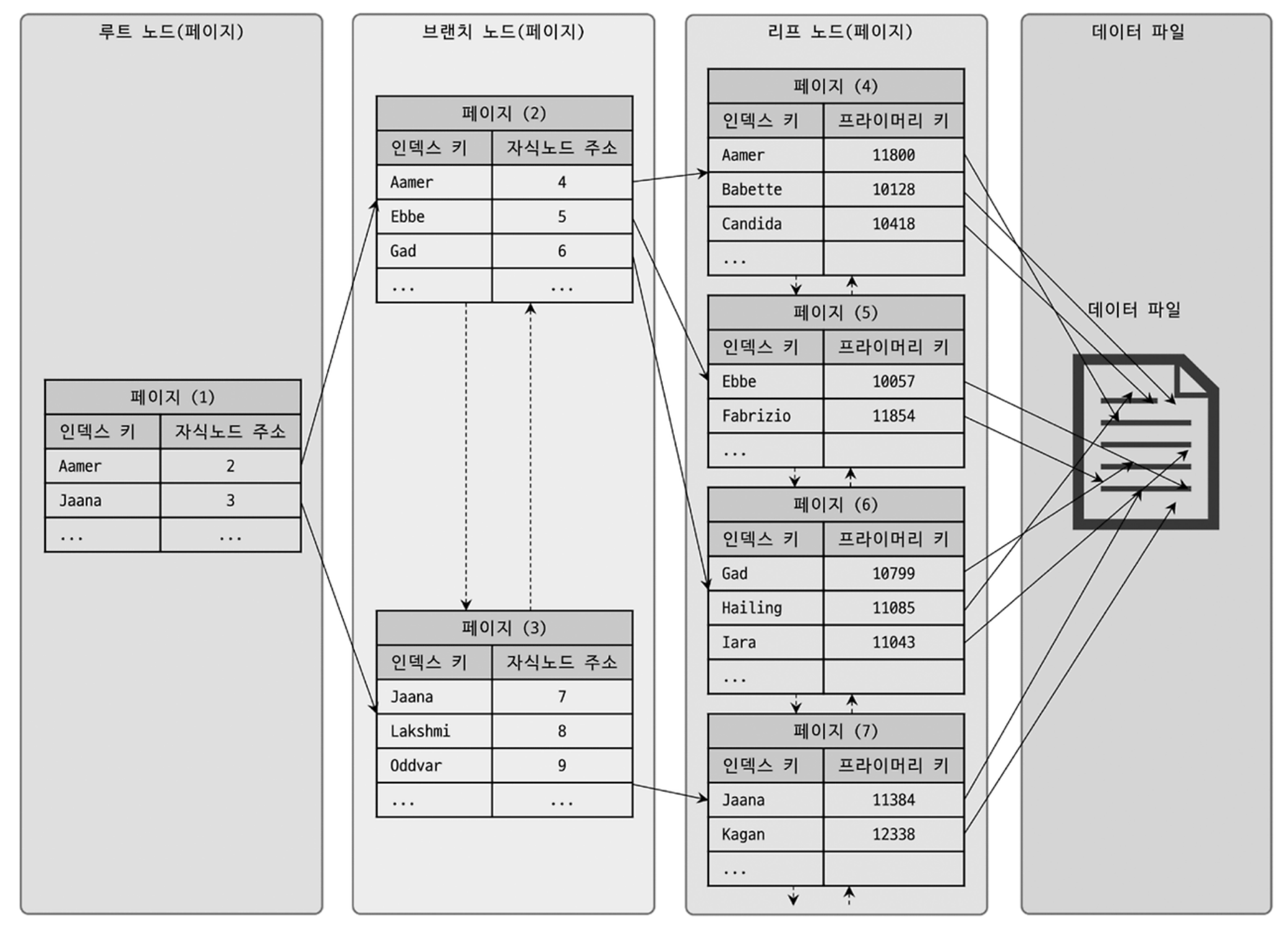
- 트리 구조 최상위에 하나의 루트 노드(Root node) 가 존재하고 그 하위에 자식 노드가 붙어 있는 형태를 말한다. 트리 구조 가장 하위에 있는 노드를 리프 노드(Leaf node) 라 하고, 트리 구조에서 루트와 리프 노드가 아닌 노드를 브랜치 노드(Branch node), 인터널 노드(Internal node)라고 한다.
- 데이터베이스에서 인덱스와 실제 데이터가 저장된 데이터는 따로 관리되는데, 인덱스의 리프 노드는 항상 실제 데이터 레코드를 찾아가기 위한 주솟값을 가지고 있다. 인덱스는 테이블의 키 컬럼만 가지고 있으므로 나머지 컬럼을 읽으려면 데이터 파일에서 해당 레코드를 찾아야하기 때문이다.
BTREE 파라미터
1. 각 노드의 최대 자녀 수(M)
- 최대 M개의 자녀를 가질 수 있는 BTREE를 M차 BTREE라고 부른다.
2. 각 노드의 최대 KEY 수(M - 1)
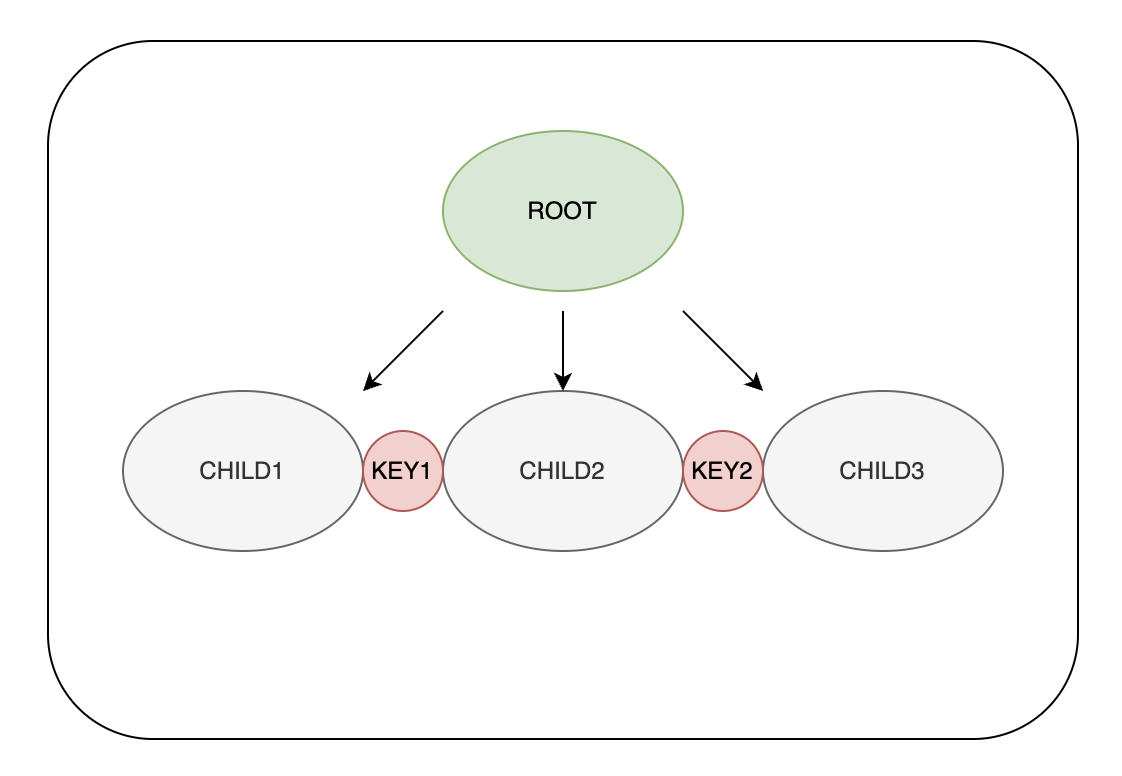
- 3개의 자녀를 가질 수 있는 BTREE라면 2개의 KEY를 가져야 한다.
3. 각 노드의 최대 자녀 수([M / 2])
- 당연하게 root 노드와 leaf 노드는 제외한다.
- 이 조건을 맞추어야 하는 이유는 균형을 유지하기 위해서다. 균형이 유지되지 않는 BTREE는 특정 데이터 형식에 대해 Log(n)에 동작하는 것이 아닌 O(1)에 가깝게 동작할 수 있다. 데이터가 많아질 때 극심한 성능차이를 보일 수 있다.
4. 각 노드의 최소 KEY 수([M / 2] - 1)
- 각 노드의 최대 자녀 수에 의해 자동적으로 결정되는 값이다.
BTREE 성질
- internal 노드의 KEY 수가 x개라면, 자녀 노드의 수는 언제나 x+1 개다.
- 노드가 최소 하나의 key는 가지기 때문에 몇 차 BTREE인지 상관없이 internal 노드는 최소 두 개의 자녀를 가진다.
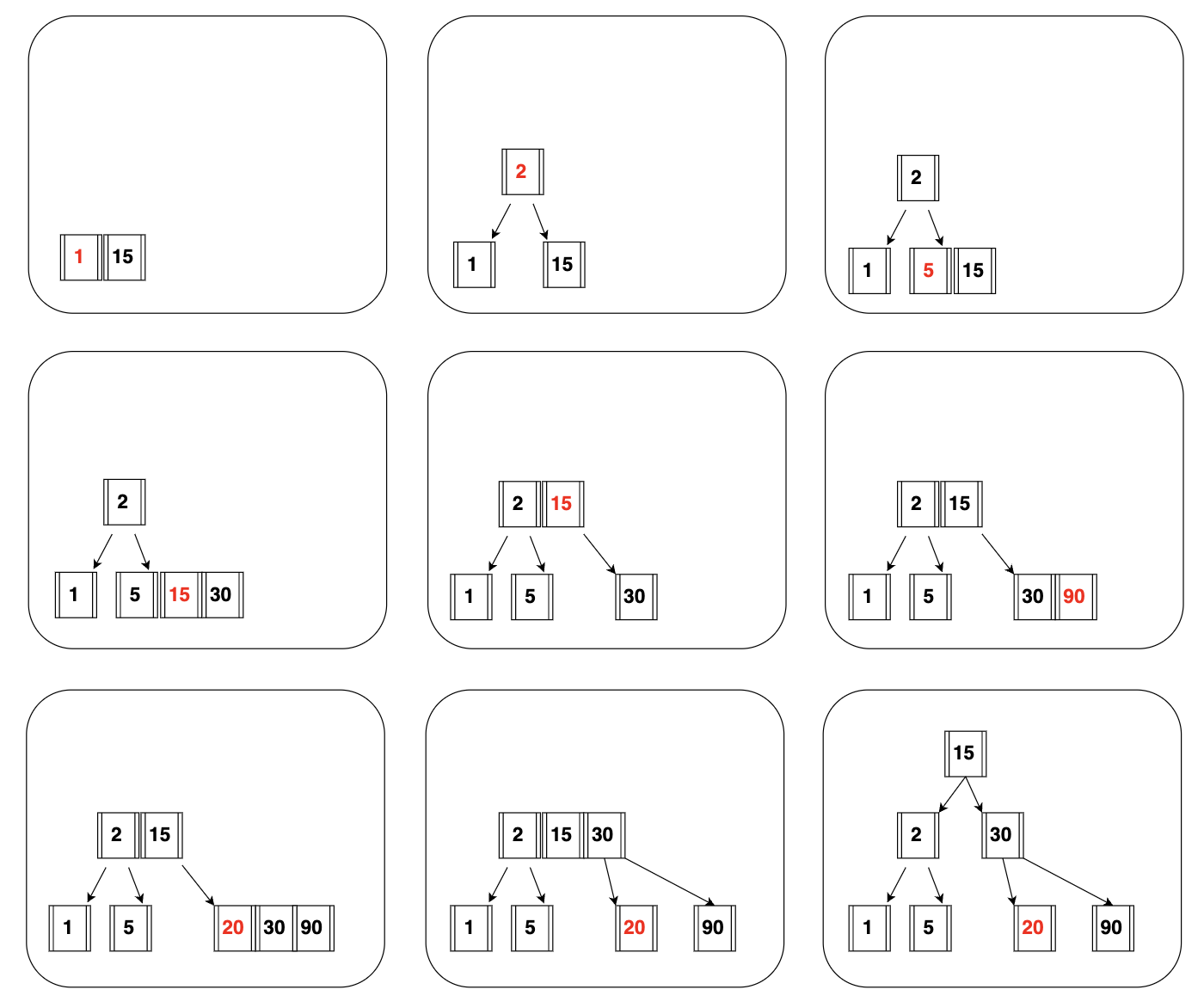
삽입 동작 방식
테이블에 레코드를 추가하는 작업 비용을 1이라고 하면, 인덱스에 키를 추가하는 작업 비용을 1.5 정도로 예측한다. 중요한 것은 비용의 대부분이 메모리와 CPU에서 처리하는 시간이 아니라 디스크로부터 인덱스 페이지를 읽고 쓰기를 해야 해서 걸리는 시간이다.
1. 추가는 항상 leaf 노드에 한다.
2. 노드가 넘치면 가운데 KEY를 기준으로 좌우 KEY 들을 분할하고 가운데 KEY는 승진한다.
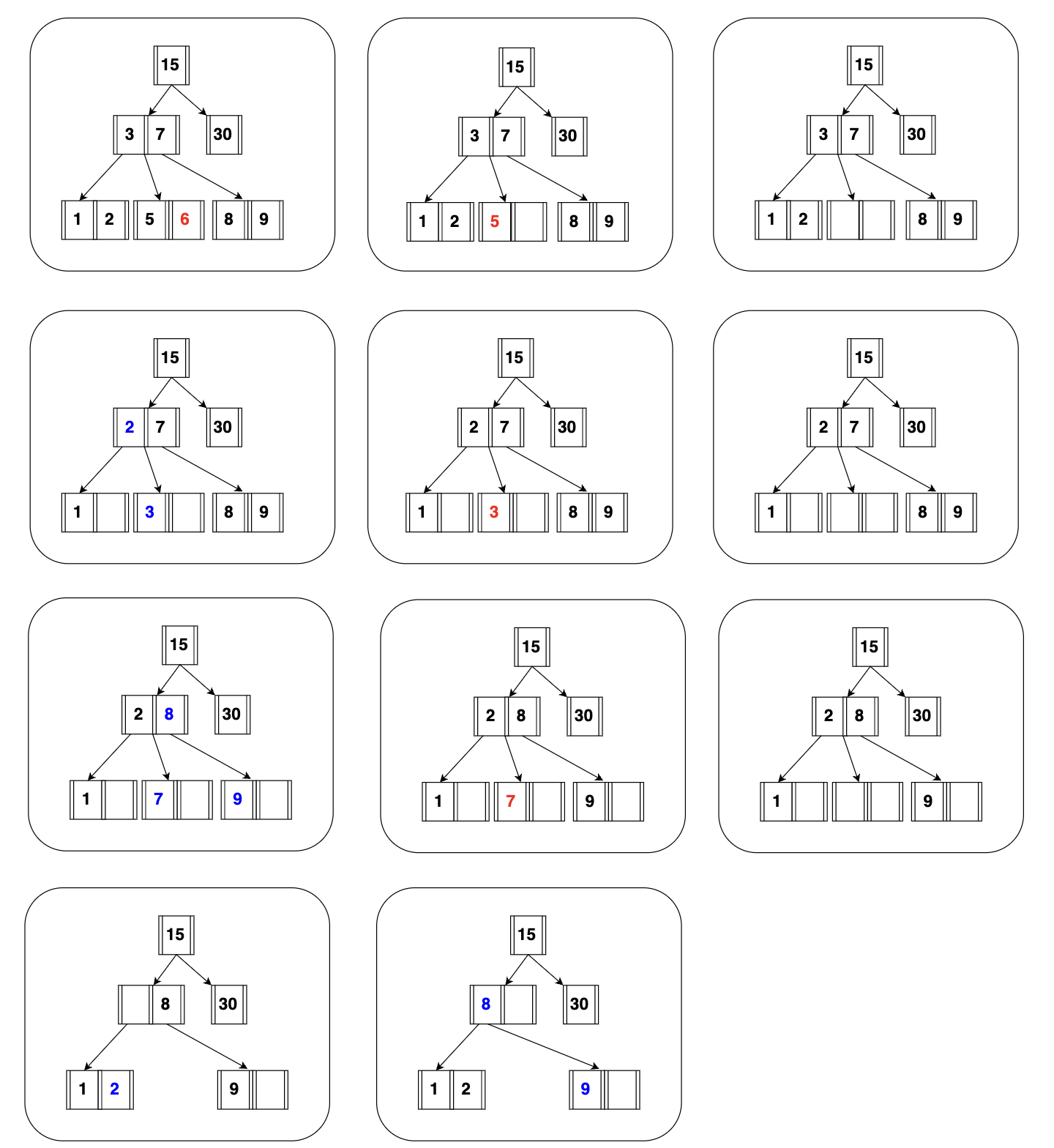
삭제 동작 방식
키 값이 저장된 B-TREE 리프 노드를 찾아서 삭제 마크만 하면 된다. 삭제 마킹된 인덱스 공간은 계속 그대로 방치되거나 재활용할 수 있다. 마킹 작업 또한 디스크 쓰기가 필요하므로 I/O 작업이다. InnoDB에서는 이 작업 또한 지연처리 될 수 있다.
1. 삭제는 항상 leaf 노드에 한다.
2. 삭제 후 최소 KEY 수보다 적어졌다면 재조정한다.
1) KEY 수가 여유 있는 형제의 지원을 받는다.
- (1) 동생(왼쪽 형제)이 여유가 있다면
- 동생의 가장 큰 Key를 부모 노드의 나와 동생 사이에 둔다.
- 원래 그 자리에 있던 KEY는 나의 가장 왼쪽에 둔다.
- (2) 형(오른쪽 형제)이 여유가 있다면
- 형의 가장 작은 KEY를 부모 노드의 나와 형 사이에 둔다.
- 원래 그 자리에 있던 KEY는 나의 가장 오른쪽에 둔다.
2) 1)번이 불가능하다면 부모의 지원을 받고 형제와 합친다.
- (1) 동생이 있으면 동생과 나 사이의 KEY를 부모로부터 받는다.
- 그 KEY와 나의 KEY를 차례대로 동생에게 합친다.
- 나의 노드를 삭제한다.
- (2) 동생이 없으면 형과 나 사이의 KEY를 부모로부터 받는다.
- 그 KEY와 형의 KEY를 차례대로 나에게 합친다.
- 형의 노드를 삭제한다.
3) 2번 후 부모에 문제가 있다면 거기서 다시 재조정한다.
- (1) 부모가 root 노드가 아니라면
- 그 위치에서부터 다시 1번부터 재조정한다.
- (2) 부모가 root 노드고 비어있다면
- 부모 노드를 삭제한다.
- 직전에 합쳤던 노드가 root 노드가 된다.
Internal 노드에서 데이터 삭제하려면, leaf 노드에 있는 데이터와 위치를 바꾼 후 삭제하는 데 순서를 보장하기 위해 삭제할 데이터의 선임자나 후임자를 찾아야 한다. 자세한 설명은 생략한다.
왜 DB Index에 BTREE가 사용될까?
- BTREE는 균형 트리이기 때문에 최악의 데이터 셋에 대해서도 O(logN)을 보장한다.
그런데, AVL-Tree 또는 Red-Black TREE도 O(logN)을 보장하는 데 왜 BTREE를 사용할까?
- Database는 메모리가 아닌 디스크에 있는 데이터를 블럭 단위로 읽어오는 것이다. 물론 한 번 읽어온 것은 InnoDB 버퍼풀 메모리에 저장되지만, 처음 접근할 때는 디스크에서 읽어온다.그림으로 BTREE와 AVL TREE 구조에 따른 디스크 접근 횟수를 살펴보자.
- 찾아야 할 데이터는 5, 8, 7, 9 블록이고, 루트노드만 메모리에 올라와있다고 해보자.
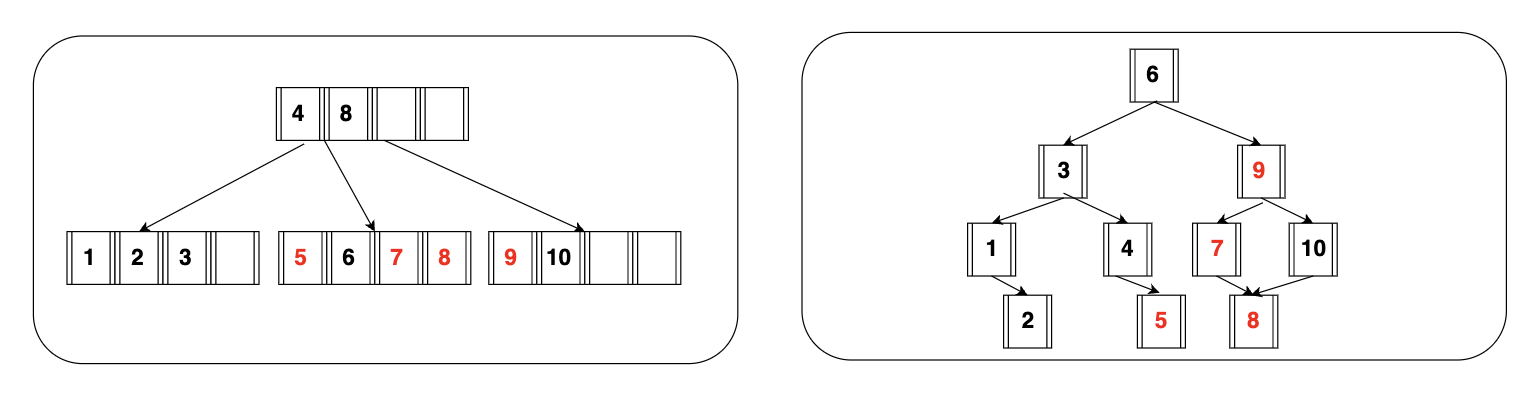
- 5차 BTREE 구조에선 2번의 디스크 접근, AVL 트리 구조에서는 4번의 디스크 접근이 발생한다.
즉, BTREE처럼 연관된 데이터를 한 블럭에 모아 저장하면 디스크 접근을 최소화할 수 있다.
참고자료
- RealMySQL 8.0
- 쉬운코드 유튜브
