[Story Generation] Inducing Positive Perspectives with Text Reframing (ACL, 2022)
Story Generation Study (2022 Summer)
목록 보기
1/2
DSAIL@SKKU
Summer Seminar - Story Generation
2022. 08. 10.
Chapter 4. Story Generation & Story Completion
- Inducing Positive Perspectives with Text Reframing (ACL, 2022) ⬅️
- https://github. com/GT-SALT/positive-frames - Generating Biographies on Wikipedia: The Impact of Gender Bias on the Retrieval-Based Generation of Women Biographies (ACL, 2022)
- Genre-Controllable Story Generation via Supervised Contrastive Learning (WWW, 2022)
TL;DR
- 심리학 이론을 바탕으로 부정적인 텍스트를 의미는 지킨 상태로 긍정적으로 재서술하기
- Keyword: NLG, text style transfer, positvie reframing, positive psychology
연구배경: What problem are they trying to solve?

- Text style transfer(TST): 텍스트의 감정 등 텍스트의 일부 특징을 변화시키는 테스크
- 주요 활용처: 편견 줄이기(de-baising), 다시쓰기(para-phrasing)나 정치적 관점 변화(political leaning), 감정이나 주제 바꾸기 (sentiment and topical tranfer) 등
- 이 연구는 새로운 테스크를 제안하는데 바로 'positive reframing'이라는 문제다
- 간단히 말하면 "물이 반밖에 없네!"(라는 부정적인 관점)을 "물이 반이나 남았네!"(라는 긍정적인 관점으로 변화시키는 작업이다
연구방법: What is their approach?
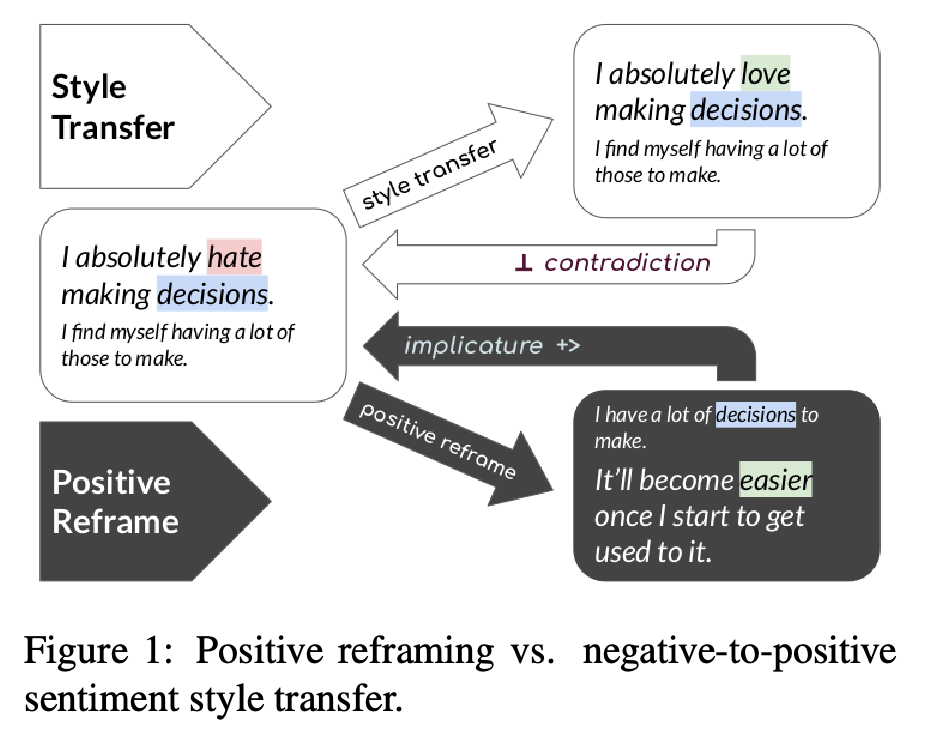
- 왜 이 테스크가 중요한가?
- 이 논문은 긍정심리학쪽에서 이론적 배경을 가져와 NLP 테스크에 접목한다.
- 부정적인 관점을 긍정적인 관점으로 변화시켜야 하는 이유는 긍정적인 마인드가 소셜미디어 상에서 빠르게 퍼진다는 점
- 긍정적인 관점은 커뮤니티 간 갈등 감소와 그룹 간 협업을 촉진 시킬 수 있다는 점을 연구문제의 중요성으로 설명한다.
- 기존 방식과 차이
- 부정적인 텍스트를 긍정적인 텍스트로 바꾸는 작업은 sentiment transfer라는 이름으로 연구된 논문과 비슷!하다고 볼 수 있다
- 하지만 저자들의 주장하기론, <오리지널 텍스트, 변화된 텍스트> 이렇게 짝지어진 데이터가 적어서, 비지도학습 방법에 의존하게 되어, 의미는 냅두고 감정만 변화시키가 어려웠다고 한다
- 그동안은 부정적인 단어 바꿔치기나 긍정적인 단어 삽입하는 식으로 이뤄졌다
- 그래서 저자들이 하고 싶은건 바로 <오리지널 텍스트, 변화된 텍스트> 이렇게 짝어진 데이터를 만드는 작업을 하고, 추가로 현재 최신 모델들의 'positive reframing' 성능을 확인하는 것이다
데이터셋 생성 전략: 그런데 어떻게 문장을 다시 쓸건가?
- 저자들이 하고 싶은건 결국 부정적인 관점의 오리지널 텍스트에 대해 긍정적인 관점의 텍스트를 만드는 건데, 도대체 이 긍정적인 관점의 텍스트는 어떻게 만들고, 긍정적인 관점이라는 건 어떻게 정의할까?
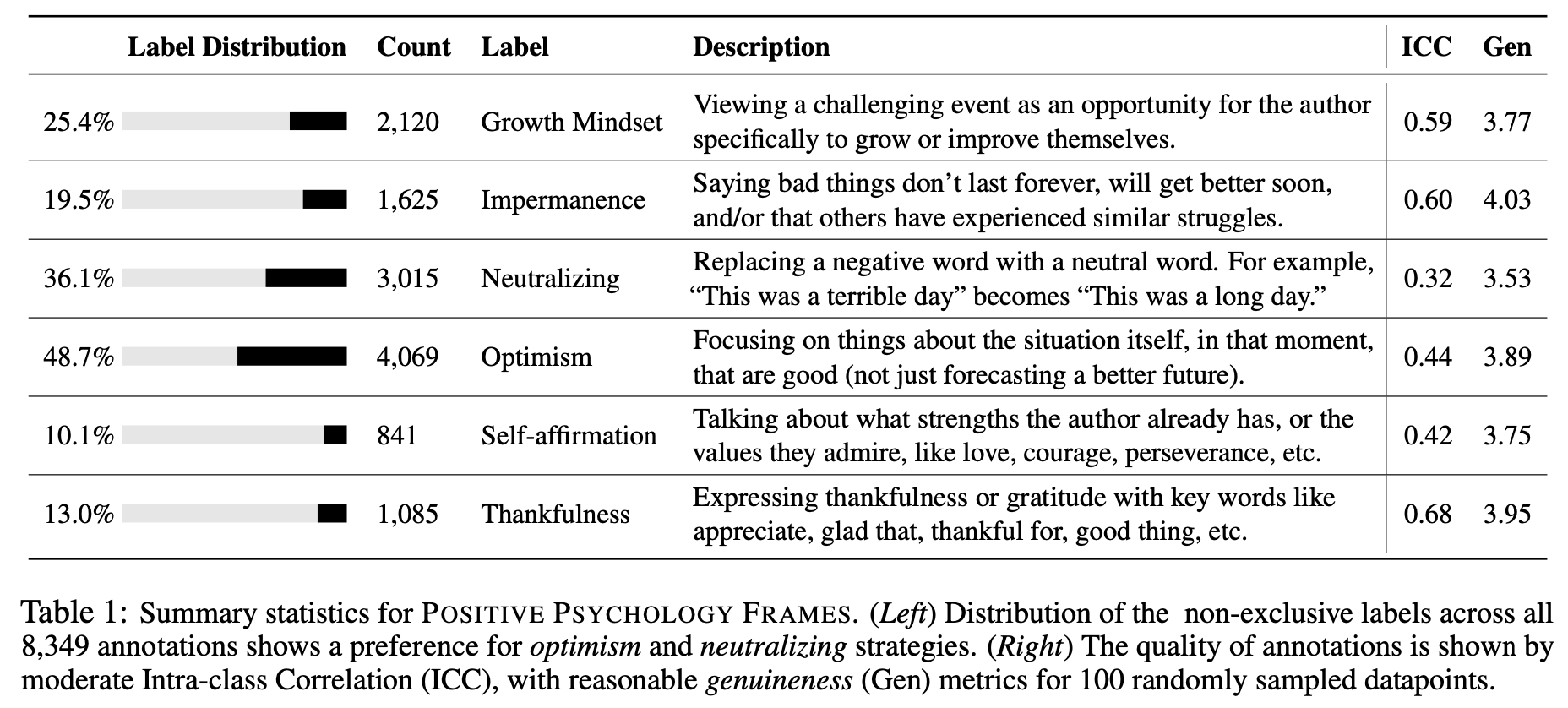
- 저자들은 부정적인 관점의 텍스트는 인지왜곡을 포함하고 잇다고하고, 이에 대한 대응책으로 긍정심리학에서 사용하는 <본격! 긍정적으로 바라보는 6가지 전략 (Harris et al., 2007)>을 사용한다.
- Growth Mindset: 부정적인건 바꾸고 성장하면 되지!
- "나는 너무 게으르다" -> "나는 더 나은 시간 관리를 배우기로 결심했다"
- Impermanence: 다들 부정적인 경험을 한다고 생각하는 것
- "이 시험을 망쳤으니, 학교에 가기엔 너무 멍청했나 봐" -> 이것은 내가 바라던 시험 점수가 아니었지만, 모든 사람들이 가끔 실수를 한다."
- Neutralizing: 부정적인 관점을 빼고 중립적으로 서술해보기
- "웬디의 고객 서비스가 형편없다" -> "웬디의 고객 서비스가 어느 정도 개선이 필요할 수 있다"
- Optimism: 낙관적인 관점으로 바라보기
- "이번 주 완전 힘들었다. 에효 벌써 금요일이다" -> "긴 한 주였지만, 이제 주말이기 때문에 나는 다시 시작하고, 쉬고, 유튜브도 봐야지~"
- Self-affirmation: 자신의 장점들을 나열해보기
- Thankfulness: 감사하는 마인드를 장착
Dataset
-
트위터에서 2012-2021년에 작성된 #stressed 트윗을 추출한다: 1M
-
전처리를 수행한다: 너무 짧은 문장과 해시태그와 혐오발언 제거 (HateSonar)
-
어노테이션 시작: 8,687개의 트윗을 랜덤 추출
-
204명의 어노테이션 작업자들에게 6가지 전략에 대한 가이드라인 설명 후, 간단한 자격테스트 수행
-
어노테이션 진행: (1) 6개 전략 중 무엇을 선택할지 알아서 정하고, (2) 다시쓰고, (3) 전후 문장의 긍정도 1-5점으로 평가하기
-
8,349개의 트윗 데이터셋 완성!
-
정말 데이터가 잘 만들었는지 알기 위해, 100개의 랜덤 결과 트윗으로 추가 테스트 진행
-
두가지를 점검함
- Intra-class Correlation (ICC): 변화된 문장 주고 6개 전략중 해당 전략 맞추기 -> 카테고리 간의 상호 응집성 파악 가능
- genuineness (Gen): 진짜 같은지 -> 다시 작성한 트윗이 진짜 같은지 파악 가능
실험
Task Formulation
- 기술적으로 해당 문제는 조건부 생성 문제라고 할 수 있고, 목적함수 역시 기본적인 텍스트 생성용 함수를 사용했다
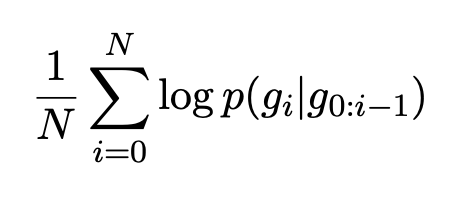
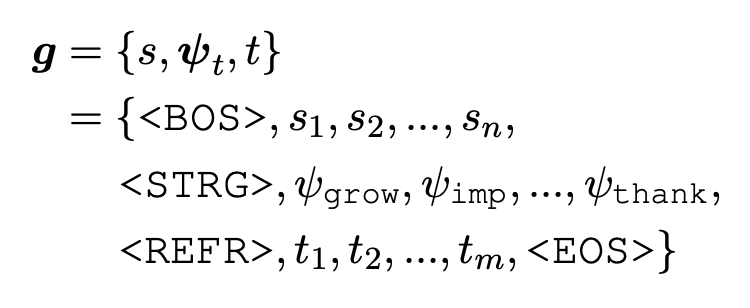
-
여기서 는 오리지널 텍스트, ,는 6가지 전략중 하나 는 재서술한 텍스트
-
실험은 총 3개를 진행한다.
- 그냥 생성하기: Unconstrained generation
- 조건부 생성: Controlled generation
- 예측하기: Prediction
결과
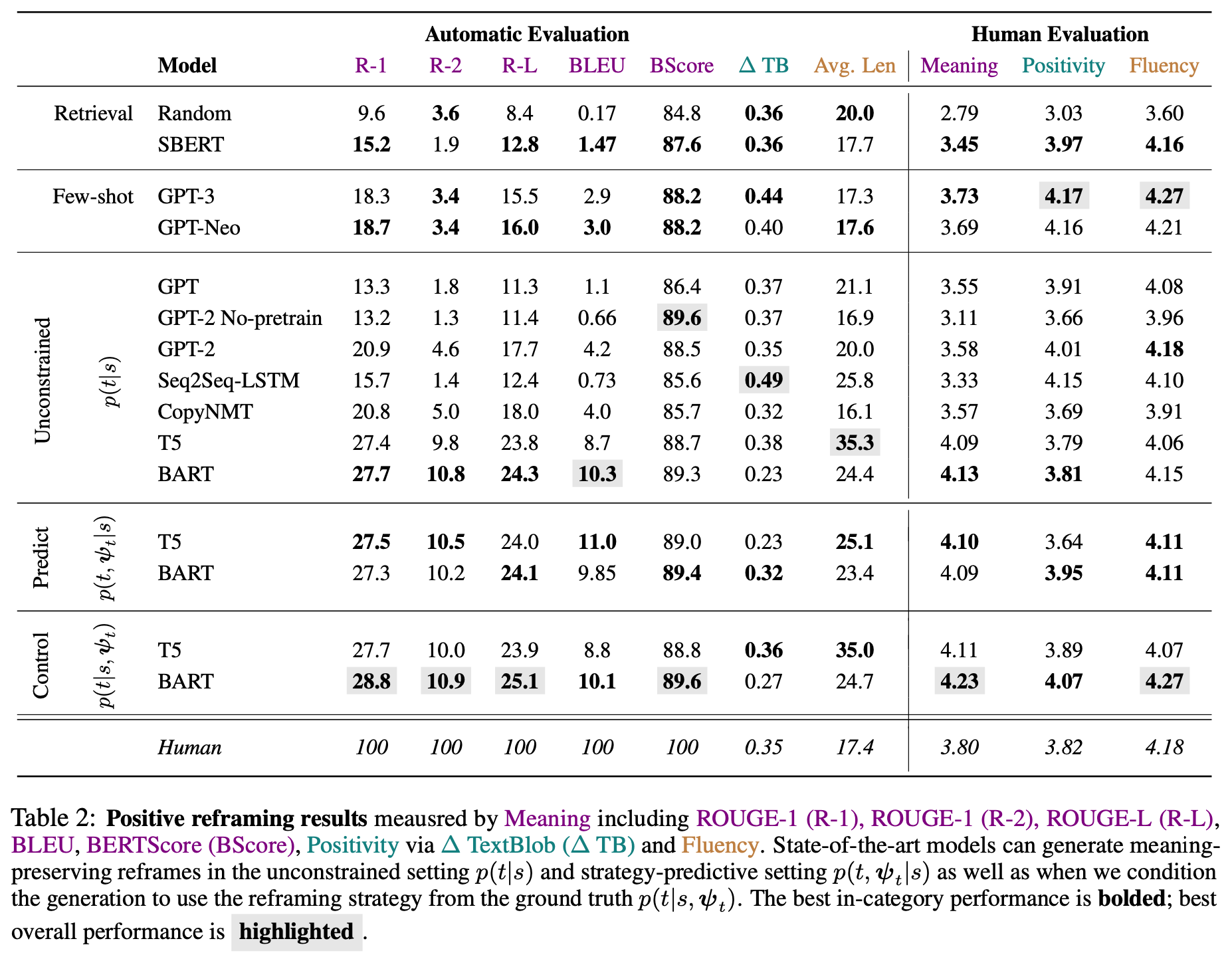
- Unconstrained generation
- BART, T5 > GPT: GPT가 안되는 이유는 아마 사전학습을 소설로 했기 때문이라고 설명한다
- Controlled generation
- Unconstrained의 결과보다 조금 상승했음을 알 수 있다
- Human Evaluation
- BART가 대부분 우위를 보이고 있음
- GPT-3 셋팅은 잘하는듯 보이지만 의미보존 능력이 떨어짐
- Error Analyasis
- BART의 결과 랜덤 100개를 뽑아서 에러 유형을 분석
(1) insubstantial changes (26%): 변화가 조금만 된 경우 ("I hate it" -> "I don’t like it.")
(2) contra- dictions to the premise (9%): 전제에 대한 모순 ("울 것 같아, 이 수학 수업은 통과가 불가능해" -> "이 수학 수업은 어렵지만 나는 통과할 수 있다는 것을 알아")
(3) self-contradictions (6%): 자기 모순 ("사람들에게 마음을 여는 것을 좋아하지 않지만, 그것을 할 용기가 있어서 기쁘다")
(4) hallucinations (2%): 그냥 말도 안되는 것
- Prediction
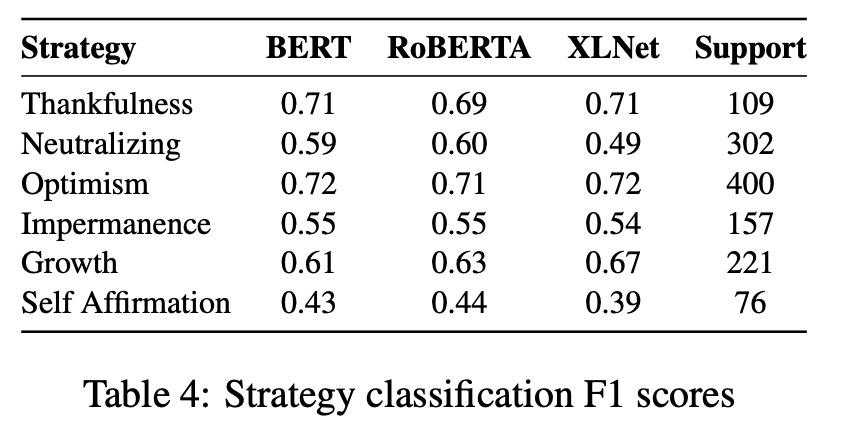
- 이 파트는 왜 있냐면, 이렇게 6가지 전략으로 바꾸는 작업이 과연 분류로도 학습가능한가를 알아보기 위해서라고 설명한다.
- 결론적으로 학습할만하다는 결론을 내린다.
결론
- 부정 -> 긍정이라는 새로운 테스크를 심리학적 참고문헌을 이용해서 논리적으로 연구 필요성 제공, 그전에 비슷한 연구도 있었지만 이 연구만의 특화점을 잘 표현했음
- 주요 모델 제안은 없었지만 꼼꼼한 데이터셋과 평가방식이 이 논문의 장점!
- 벤치마크 데이터셋으로 사용해볼 수도 있을 거 같다. 또다르게는 페르소나 생성 등도 예상 사용처로 언급하고 있음

도파민 중독
잘 읽고 갑니다~ ㅎ_ㅎ