멀티모달 데이터를 분류하여 분석할 일이 있었는데요. 멀티모달 베이스라인 중에서 자주 등장하는 것중 하나가 VisualBERT가 있습니다.
VisualBERT란 BERT의 Transformers 모델에 [텍스트,이미지]를 넣는 식으로 멀티모달용 임베딩을 만들어내는 모델입니다.
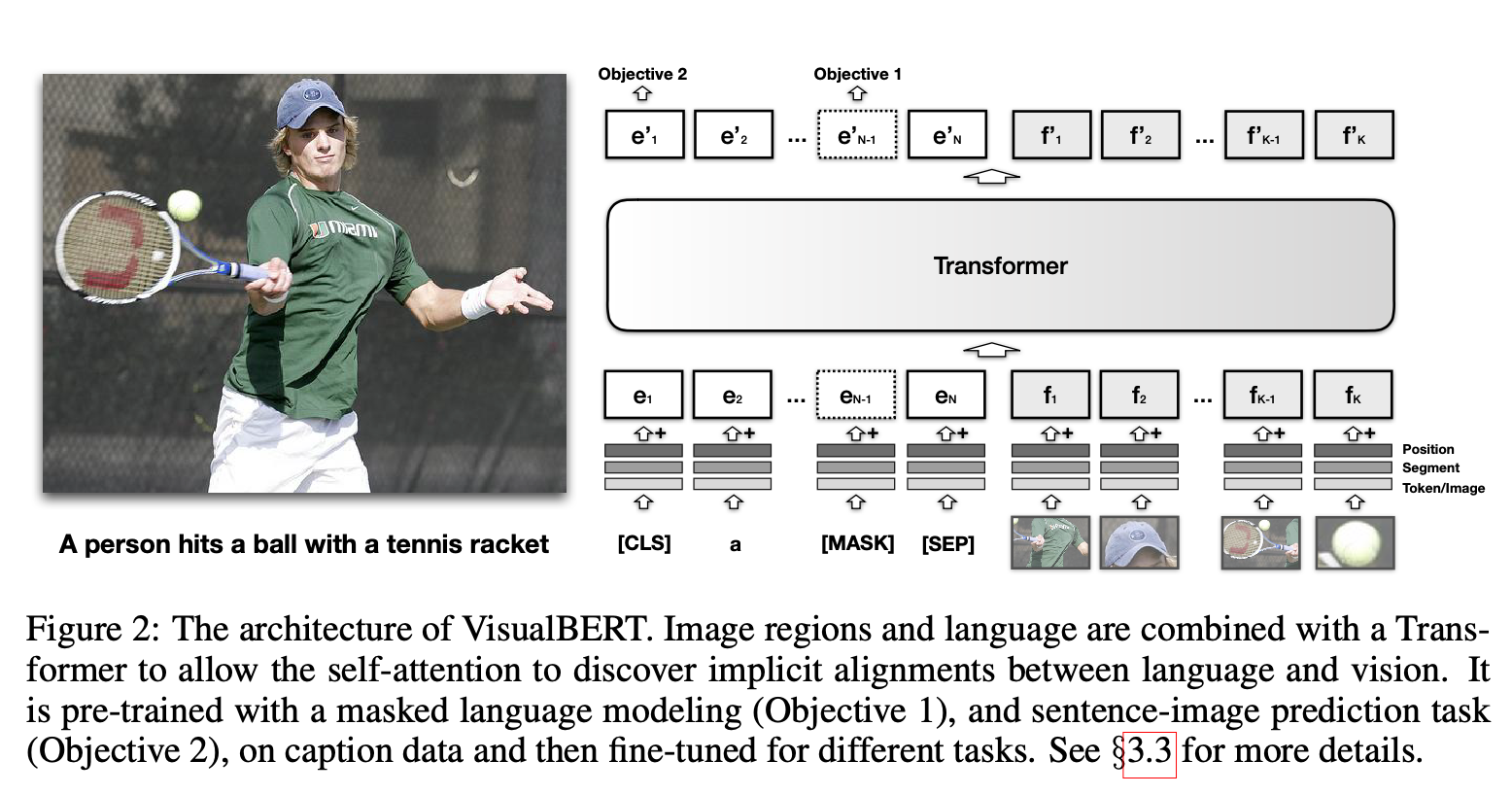
사전학습은 이미지 캡셔닝을 위한 유명한 데이터셋인 COCO를 이용해서 학습을 했는데요, 논문처럼 VAQ 테스트로 사용할 수도 있지만, 사전학습 모델 학습과정에서 이미 텍스트랑 이미지를 한꺼번에 보는 멀티모달적인 학습력!!을 가졌다고 보기때문에 멀티모델 데이터를 위한 다운스트림 테스크의 임베딩으로 사용하기도 합니다.
목표: VisualBERT를 위한 이미지 피쳐 추출하기
VisualBERT를 COCO로 학습한 사전학습 임베딩이 HuggingFace에도 올라와있는데 (링크) 문제는...
# Assumption: *get_visual_embeddings(image)* gets the visual embeddings of the image.
from transformers import BertTokenizer, VisualBertModel
import torch
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
model = VisualBertModel.from_pretrained("uclanlp/visualbert-vqa-coco-pre")
inputs = tokenizer("The capital of France is Paris.", return_tensors="pt")
visual_embeds = get_visual_embeddings(image).unsqueeze(0)
visual_token_type_ids = torch.ones(visual_embeds.shape[:-1], dtype=torch.long)
visual_attention_mask = torch.ones(visual_embeds.shape[:-1], dtype=torch.float)
inputs.update(
{
"visual_embeds": visual_embeds,
"visual_token_type_ids": visual_token_type_ids,
"visual_attention_mask": visual_attention_mask,
}
)
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_stateget_visual_embeddings이라는 함수가 없다는 문제가 있어서 이미지 인풋을 도대체 어떻게 넣어줘야하나?는 문제를 발견했습니다. 이럴땐 역시 패키니 내 코드를 뜯어보는 것으로!
튜토리얼 코드의 공백 채우기
HuggingFace 내 VisualBERT 코드가 어떻게 돌아가는지 폴더를 확인하여 발견한 demo.ipynb [URL]를 확인해보면 아웃풋의 형태와 추출 방식을 얻을 수 있습니다.
from processing_image import Preprocess
# load models and model components
frcnn_cfg = Config.from_pretrained("unc-nlp/frcnn-vg-finetuned")
frcnn = GeneralizedRCNN.from_pretrained("unc-nlp/frcnn-vg-finetuned", config=frcnn_cfg)
image_preprocess = Preprocess(frcnn_cfg) # HERE!
# run frcnn
images, sizes, scales_yx = image_preprocess(URL)
output_dict = frcnn(
images,
sizes,
scales_yx=scales_yx,
padding="max_detections",
max_detections=frcnn_cfg.max_detections,
return_tensors="pt",
)
features = output_dict.get("roi_features")간략하게 정리하자면..
processing_image.py내Preprocess클래스에서 이미지 전처리를 통해images, sizes, scales_yx추출Faster RCNN (frcnn)기반 사전학습 모델을 통해 Region of Interest(RoI)의 이미지 피쳐 추출- 이제 준비완료! VisualBERT의 visual embedding을 구했습니다
베이스라인 실험 진행을 위한 데이터로더의 예시
앞서 찾은 이미지 전처리 코드를 포함해 VisualBERT를 사용하기 위한 데이터로더의 예시를 함께 올려둡니다 [code]
(*코드 내 데이터 경로를 수정해서 사용해야합니다)
참고링크

도파민 중독