
이번 글에서는 Airflow를 이용해 데이터 처리 작업을 자동화 하는 부분에 대해 설명해보고자 한다.
Airflow를 이용해 데이터를 처리하고 저장하는 과정의 자동화를 이루기 위해 다음과 같은 과정을 진행하기로 계획 하였다.
- PostgreSQL, S3, Kuberenetese hook을 이용해 Connction 생성
- Operator를 이용해 Task를 정의하고 순서대로 실행
- Task 실행을 위한 Variables 저장
개발 단계에서는 Airflow에서 제공하는 Docker-compose 를 이용하여 작업을 진행하였다. 이후 Airflow 또한 Kubernetes Cluster 상에서 배포할 계획이다.
1. Hook을 이용한 Connection 설정
결론부터 말하자면, 지금은 Kubernetes connection만 이용 중이다.
다만, 이전에 spark작업을 airflow container 상에서 client mode로 작업을 수행할 때 연결을 수행하며 오류에 부딪히고 해결한 과정이 있는데, 이는 Airflow 기여기에 작성해 두었다.
사실 Spark 작업을 실행하기 위해 Spark Operator와 Kubernetes Operator 둘 중 하나를 선택해야 했다. 처음에는 Spark Operator를 이용하려다가 이후에 설명할 이유로 인해 Kubernetes Operator를 이용하게 되었기에 일단 둘다 설정은 진행해 봤다.
Spark와 Kubernetes 연결 설정은 어렵지 않았다.
먼저 Spark의 경우에는 다음의 정보가 필요했다.
- Host: Spark 작업을 실행할 kubernetes host api
- Port: Spark 작업을 실행할 kubernetes host port
- Extra information
- deploy-mode: 배포 모드, 외부 클러스터에서 실행하는 것이니 cluster mode
- nameespace: 작업을 실행할 kubernetes상의 namespace
kubernetes연결에는 다음의 정보를 입력해 주었다.
- Kube config path: airflow worker 컨테이너 내 kube config의 위치
- Namespace: 작업을 실행할 kubernetes상의 namespace
- Cluster context: 작업을 실행할 cluster id
2. Operator를 이용해 Task를 정의하고 순서대로 실행
1. 어떤 Operator를 이용할까?
Airflow에서 Spark job을 제출하는 방법을 2가지 정도 생각해 보았다.
- SparkSubmitOperator
- SparkKubernetesOperator
여기에서 EMROperator는 왜 없나 라는 생각을 할 수도 있는데, 본 프로젝트는 Naver Cloud Platform을 이용중이며 Ncloud에는 비슷한 Data forest가 있으나, EMROperator를 이용할 수 있는 것은 아니였기에 이는 제외하였다.
SparkSubmitOperator는 Airflow container 상에서 spark-submit 명령어를 실행하기에 컨테이너에 필요한 Spark 소프트웨어를 모두 설치해 주어야 한다.
그에 반면 SparkKubernetesOperator는 Airflow와 Kubernetes를 연결하고 이를 SparkApplication 이라는 Kubernetes custom resource를 이용해 실행할 수 있다.
이러한 사실만으로는 둘 중 어떤것을 사용하는게 더 나을지 판단하기가 어려웠고, 두 Operator의 장단점을 찾아 비교해 보았다.
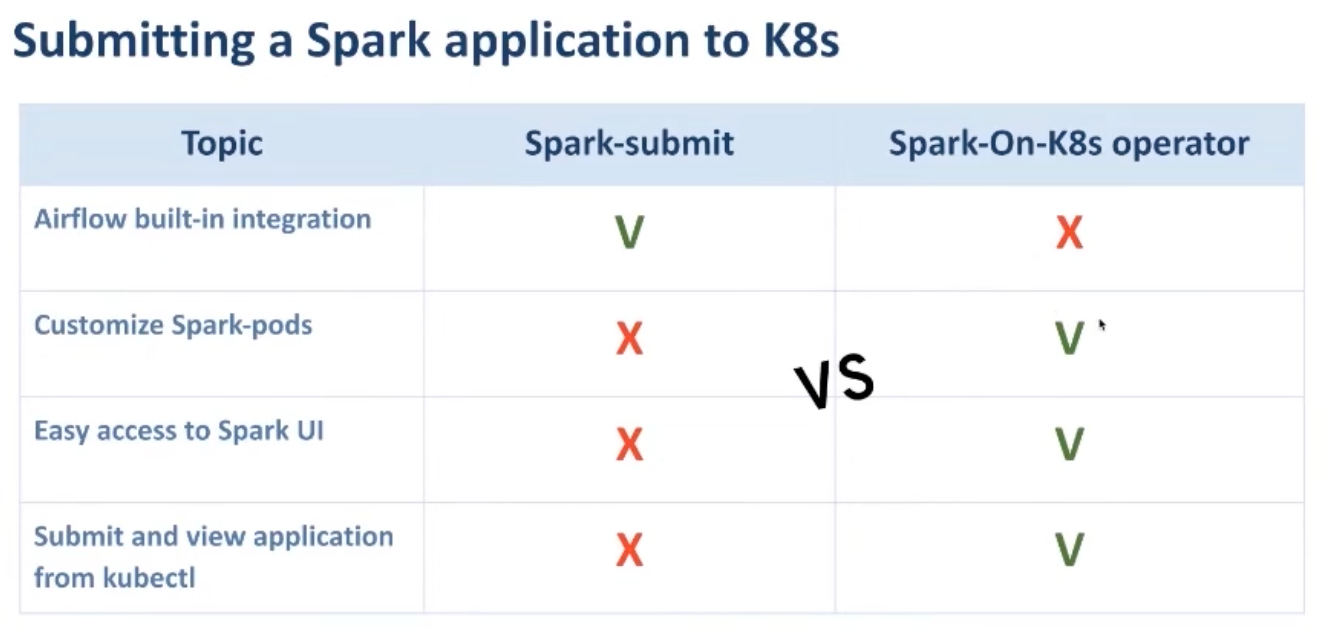
일단 Spark-on-kubernets Operator에서 발표 당시 둘의 차이에 대해 비교한 발표의 일부분이다.
-
Airflow built-in integration: Spark-submit operator의 경우 이미 airflow상에서 쉽게 이용할 수 있도록 구현이 되어 있어 이부분에서는 Spark submit이 우위를 점한 것 같다.
발표자들이 발표 전 구현하던 시기에는 Spark Kubernetes Operator가 없어서 그랬던 것 같기도 하다.그래서 이 부분을 해결하기 위해 직접 구현을 하여 지금은 해결된 이야기.
-
Custimize Spark-pods: Spark submit은 어플리케이션의 일반적인 실행 명령을 제공하지만, 아무래도 Kubernetes 자원 관리, 환경 변수 설정, node affinity 및 ConfigMap 또는 볼륨 마운트와 같은 Kubernetes 관련 작업과 같은 고급 설정은 힘들다고 한다.
반면 Spark on Kubernetes Operator는 이러한 설정까지도 yaml파일에 작성해 customization이 가능하다고 한다.
하지만 이것도 발표자들이 발표하던 시기까지 그런거고 새로운 spark 버전에서는 이런 상세한 부분까지도 spark-submit으로 설정할 수 있도록 구현 되었다고 한다...!
-
Easy to access Spark UI와 Submit and view application from kubectl: spark-submit으로 실행할 경우에는 만약 airflow container에 이용할 kubernetes cluster를 연결해 놓지 않은 이상 어디에서 어떻게 실행되는지에 대한 정보를 볼 수 없다는 단점이 있다.
Spark on Kubernetes Operator는 어쨌든 컨테이너 상에 kubernetes 설정을 해놓고 진행하니 이런 부분들을 Kubectl 명령어로 쉽게 확인할 수 있다는 걸 이야기 한것 같다. -
추가적으로 생각한 차이점은 spark submit의 경우 spark 버전이 바뀔때마다 dockerfile을 수정 해주어야 하는 반면, spark on kubernetes의 경우에는 yaml 파일만 수정해주면 되어 상대적으로 업데이트를 간단히 수행할 수 있었다.
일단 이런 점들을 고려해 봤을때, 일단 당장 내가 해야 하는일만 놓고 봤을 때는 Spark Submit을 이용한다면 airflow에 spark를 설치하고 Kubernetes의 정보만 옮기면 되는 상황이고, Kubernetes Operator를 이용한다면 airflow를 빌드할때 ncloud의 kubernetes service를 이용하기 위한 설정들을 추가해 주어야 하는 상황이였다.
2. Spark Submit Operator를 이용
그래서 먼저 Spark Submit Operator를 이용해 보기로 했다. 일단 로컬에서 spark submit 명령어로 job을 문제 없이 실행하기도 했고 이걸 그대로 옮기기만 하면 될것이라 생각했다. 전혀 그렇지 않았지만 말이다
Spark Connection을 생성하고, Operator에 추가로 Kube_config파일을 함께 추가해 주었다.
그 결론은, 인증 오류로 인한 작업 수행 불가 였다.
이는, ncp의 kubernetes 서비스가 airflow container 내에서 authenticate되지 않아 인증 오류가 계속 발생하는 것이였다. 따라서 Ncloud의 문서에 나와있는대로 airflow의 Dockerfile에 자동으로 authenticate도 진행할 수 있도록 추가해 주었다.
그러고 나니, Spark on Kubernetes Operator를 이용하면 작업이 수행하는 상황이 되어 굳이 airflow에 spark를 설치할 이유가 없게 되었다.
3. Spark Kubernetes Operator 이용
이 이후부터는 간단했다. Kubernetes connection을 설정하고 설정한 클러스터상에서 yaml파일을 제출해 spark application을 실행하게 하면 되었다.
결론
이로써, 쉬워보이는 길이 다가 아니라 진행 과정에 대해 꼼꼼히 살펴보고 효율적인 방법을 실행해야 삽질을 덜 한다는걸 다시금 느꼈다. 쉽게 가려다 돌아돌아 왔다.
So... TODO
이후에는 아래의 작업도 같이 진행해보려 한다.
- Druid 작업도 Kubernetes Pod Operator를 이용해 실행
- 최종적으로 Airflow를 Kuberenetes에 배포
