
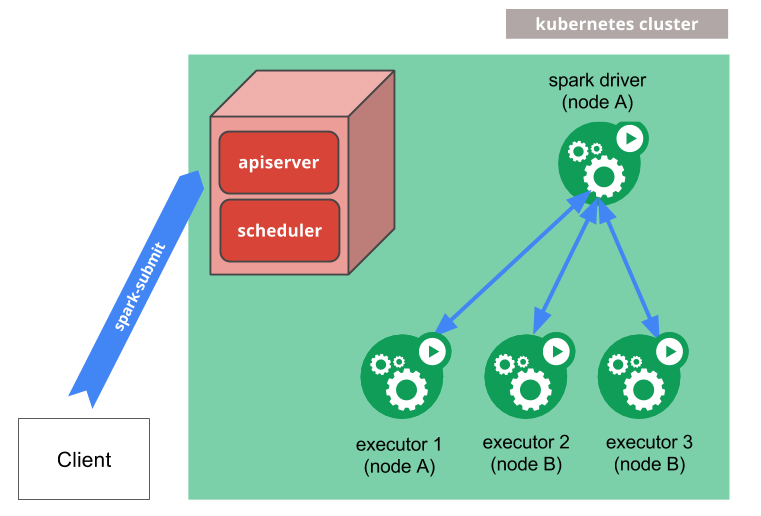
앞서 프로젝트 개요의 System Architecture에서 데이터를 처리하는 전반적인 작업들을 Kubernetes Cluster 상에서 진행할 것이라 하였다. 따라서 이번 포스팅에서는 해당 작업들 중 Spark Cluster를 구성하는 과정에 대해 다뤄보려고 한다.
우선 Spark Cluster를 구성하는 순서는 다음과 같다.
- Spark 작업을 실행할 Dockerfile 구성하기
- 새로운 작업을 Submit 하여 Cluster 상에서 실행하기
- Airflow 상에서 Operator를 이용해 자동으로 task 진행하기
1. Spark 작업을 실행할 Dockerfile 구성하기
Spark 자체에서 공식적으로 Dockerfile을 제공하고 있다. 처음엔 이걸 그대로 Build해 job을 제출해 보았으나 다음과 같은 문제가 발생하였다.
실행에 필요한 python 파일이 담긴 폴더 전달하기
문제 상황
java나 scala 같은 경우에는 build를 통해 jar파일을 만들어 jar 파일과 class path 정보를 제공하면 된다.
하지만, Python은 실행에 필요한 파일들을 직접 전송해야 한다는 차이점이 있다. 절대 경로를 바탕으로 올바르게 실행되기 위해 Spark 폴더를 통으로 보내야 했는데, 아쉽게도 그런 방법은 없었다.
그렇다고, 각 파일을 하나하나 보내기에는 절대경로를 이용해 다른 파일의 모듈을 import한 탓에 이 또한 경로 설정 오류로 실행되지 않았다.
선택한 방법
결국 고민하다가 Dockerfile 생성 시 특정 위치로 폴더를 전체 복사해 옮기는 방법을 이용했다.
또한, 환경 변수로 Pythonpath를 설정해 절대경로를 이용하더라도 잘 찾아 실행될 수 있도록 하였다.
따라서 Spark에서 제공하는 Dockerfile에 Spark application 파일들이 저장된 폴더를 복사하고 pythonpath 환경변수를 설정하는 부분을 추가하여 재구성을 진행하였다.
2. 작업을 Submit 하여 Cluster 상에서 실행하기
Spark submit을 할 때, 클러스터 모드라면 master를 kubernetes endpoint url로 바꿔 주어야 한다.
또한, Client mode에서는 외부 라이브러리의 경우 Driver path를 지정만 해주면 되는 상황이였는데, Cluster 모드의 경우에는 jar옵션을 통해 보내주어야 했다. 둘의 차이는 다음과 같았다.
1) driver-class-path:
Spark 드라이버 프로세스의 클래스 경로 지정에 이용된다. Client mode에서는 드라이버 프로세스가 클라이언트에서 실행되니 이를 이용해 설정이 가능하다.
2) jars:
Spark cluster의 각 워커 노드에 전달 될 jar 파일 지정에 이용된다.
Cluster mode에서는 spark application이 worker mode에서 실행되니, jar 옵션을 이용해 필요한 jar 파일을 배포해 주어야 한다.
그외에 Dockerfile을 받아와 kubernetes cluster상에서 build하기 위해서는 Cloud registry정보 또한 전달해 주어야 했다.
-> 해당 부분은 미리 Kubernetes Cluster에 secret으로 Registry 정보를 등록해 두고 submit configuration에 secret명을 전달하는 방식으로 이용하였다.
3. Airflow 상에서 Operator를 이용해 자동으로 task 진행하기
이 부분은 다음 포스팅에서 다뤄보려고 한다.
Reference
- Spark on Kubernetes, Apache spark https://spark.apache.org/docs/latest/running-on-kubernetes.html
