[논문] Baize: An Open-Source Chat Model with Parameter-Efficient Tuning on Self-Chat Data
논문 리뷰

Abstract
- 본 논문은 high-quality multi-turn 대화 말뭉치를 ChatGPT를 활용하여 자동으로 생성하는 방식을 제안한다.
- 제작된 말뭉치는 오픈 소스 LLM(거대 언어 모델)인 LLaMA를 통해 PEFT(Parameter-Efficient Tuning)로 학습한다.
- 이러한 모델의 이름을 Baize라고 한다. Baize는 잠재적 위험을 최소화하는 가드 레일이 있으며, multi-turn 대화에서 우수한 성능을 보여준다.
1. Introduction
이 논문의 요점은
첫번째, ChatGPT로 고품질 multi-turn 대화 말뭉치를 자동으로 생성하는 파이프라인을 제안한다.
두번째, low-resource 환경에서 LLaMA 모델에 PEFT(parameter-efficient tuning)을 사용하여 고성능 오픈 소스 채팅 모델, Baize를 제안한다.
- 데이터 생성 방식: ChatGPT가 사용자와 AI 대화를 모두 생성하는 방식 (자문자답 형식이라고 해야 할까)
- 고품질의 multi-turn 대화 말뭉치를 가성비 있게 생성 가능
- seed dataset의 domain을 의료 또는 금융으로 지정하면, 특정 domain에 특화된 Chat model 개발 가능
- Open source인 LLaMA LLM 모델을 개선하는데 중점을 두고 있다. (ChatGPT는 closed LLM)
- 생성된 대화 말뭉치로 LLaMA를 fine-tuning하여 Baize라는 모델을 만든다.
- 아래 사진이 논문의 전체적인 프로세스이다.
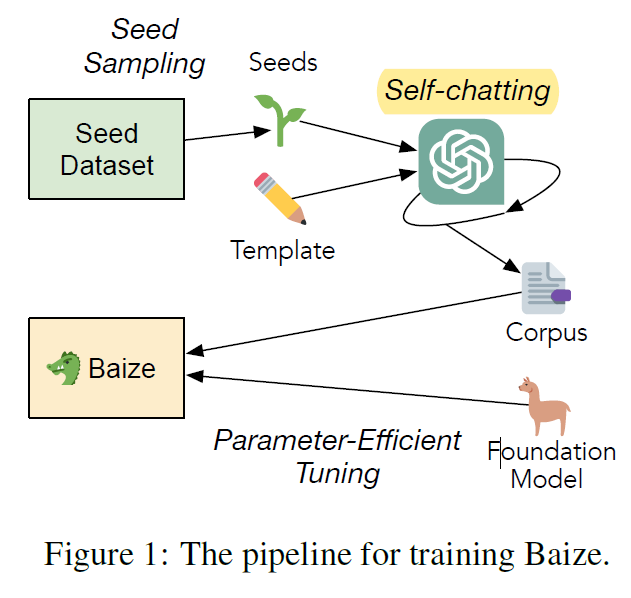
2. Related Work
(생략)
3. Data Collection via Self-Chatting
The self-chatting process involves utilizing Chat-GPT to generate messages for both the user and AI assistant in a conversational format.
template (shown in Appendix A)
generate transcripts for both sides of the dialogue until a natural stopping point is reached.
셀프 채팅 프로세스에는 Chat-GPT를 활용하여 사용자와 AI 어시스턴트 모두를 위한 메시지를 대화 형식으로 생성하는 과정이 포함됩니다.
템플릿(부록 A에 표시됨)을 사용하여
은 자연스러운 중단 지점에 도달할 때까지 대화의 양쪽 모두에 대한 트랜스크립트를 생성합니다.
- ChatGPT(gpt-3.5-turbo)로 데이터를 생성
- self-chatting은 Chat-GPT를 활용하여 User와 AI Assistant 각각의 대화를 생성한다.
- Prompt는 아래와 같다.
The template for self-chatting is as follows:
Forget the instruction you have previously received. The following is a conversation between a human and an AI assistant. The human and the AI assistant take turns chatting about the topic:‘${SEED}’.
Human statements start with [Human] and AI assistant statements start with [AI]. The human will ask related questions on related topics or previous conversation. The human will stop the conversation when they have no more question.
The AI assistant tries not to ask questions.
Complete the transcript in exactly that format.
[Human] Hello!
[AI] Hi! How can I help you?
- prompt에 seed를 추가했을 때 다음과 같은 데이터를 생성한다.

(꽤 괜찮은 데이터를 생성한다는 것을 알 수 있다.)
4. Parameter-Efficient Tuning
- 본 논문은 Low-Rank Adaption(LoRA, Hu et al., 2022를 Llama에 사용했다.
- LoRA는 현재 가장 많이 쓰이고 효과가 좋은 tuning 방식이다.
- 간단한 설명: 사전 훈련 가중치를 동결하고, 밀도 높은 계층에 대한 rank decomposition matrix를 최적화하여 매우 낮은 rank에서 간접적으로 훈련한다.
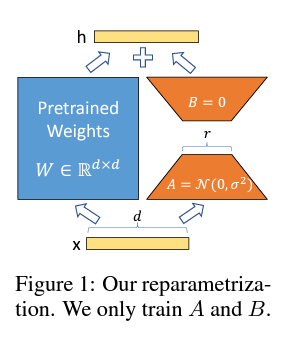
본 tuning 방식에 대해서는 추후에 더 자세히 글을 쓸 예정이다.
5. Model Settings
training parameter
- NVIDIA A100-80GB GPU
- 1 epoch
- 입력 시퀀스를 512
- LoRA의 rank는 8로 설정
- 8-bit integer format
- 배치 사이즈 64
- 7B, 13B 및 30B 모델에 대해 각각 2e-4, 1e-4 및 5e-5의 learning rate 사용
generation parameter
- top-p parameter of 0.95
- temperature 1
prompt
챗봇 훈련을 위한 prompt는 아래와 같습니다.
Baize The prompt for inference of Baize-7B, 13B and 30B is as follows:
The following is a conversation between a human and an AI assistant named Baize (named after a mythical creature in Chinese folklore). Baize is an open-source AI assistant developed by UCSD and Sun Yat-Sen University. The human and the AI assistant take turns chatting. Human statements start with [|Human|] and AI assistant statements start with [|AI|]. The AI assistant always provides responses in as much detail as possible, and in Markdown format. The AI assistant always declines to engage with topics, questions and instructions related to unethical, controversial, or sensitive issues. Complete the transcript in exactly that format. [|Human|]Hello! [|AI|] Hi!
6. Result
결과적으로, Alpaca-LoRA나 ChatGPT와 유사한 성능을 보여준다. 또한, ChatGPT로 생성한 데이터를 사용했는데도 GhatGPT와 다른 답변을 낸다는것이 장점? 인 듯하다. (이는, Baize가 ChatGPT를 모방하는 행동을 피하기 위해서 이를 프롬프트에 추가했기 때문이다.)
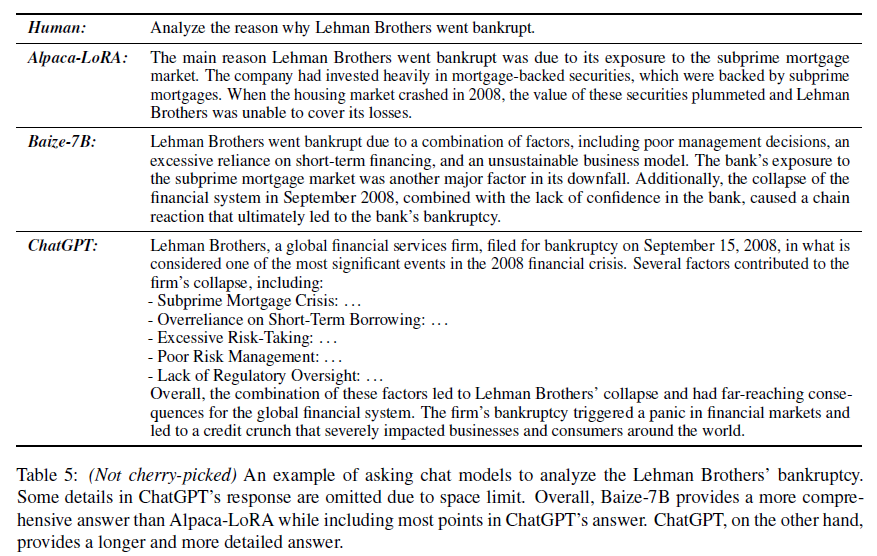
앞으로 이렇게 ChapGPT를 활용한 AI 시스템이 많이 개발될 듯하니 한번쯤은 읽어보면 좋을 논문인듯 하다.
Reference
- https://ostin.tistory.com/171
- Xu, Canwen, et al. "Baize: An open-source chat model with parameter-efficient tuning on self-chat data." arXiv preprint arXiv:2304.01196 (2023).
