1. 대용량 서비스 레퍼런스 아키텍처
대용량 서비스를 위한 플랫폼의 아키텍처는 일반적으로 다음과 같은 형태를 가지고 있다.
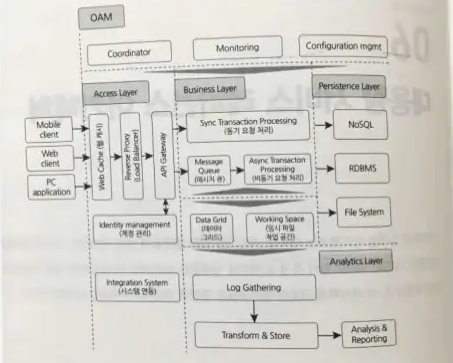
서버에서 트랜잭션을 처리할 때 3가지 계층을 거치게 되는데, 앞으로 소개할 Access Layer, Business Layer, Persistent Layer가 그것이다.
Access Layer
클라이언트로부터 요청을 처음으로 받는 계층.
요청에 대해 사용자 인증, 인가를 수행한 후 비즈니스 로직으로 전달한다.
-
웹 캐시
Access Layer에서 가장 앞 단에 위치하는 것은 웹 캐시로, 웹에서 사용되는 정적 자원을 캐싱한다.
서비스 지역이 넓다면 CDN 서비스를 이용해 캐시 서버를 분산해 어디서든 로딩타임을 줄일 수 있다. -
Reverse Proxy
Reverse Proxy는 웹 서버의 역할을 하면서 정적 콘텐츠에 대한 서비스를 제공하거나, 요청에 대한 인증을 수행한다. -
API Gateway(옵션)
API Gateway의 기능은 다음과 같다.- API 인증처리와 키 관리
API를 호출하는 클라이언트가 인증된 사용자인지 확인하고, 인증된 사용자에게는 API 키(또는 토큰)을 발급하는데, 이 키에 대한 발급부터 업데이트, 파기의 전체 주기를 관리한다. - 로드 밸런싱
단일 엔드포인트에서 여러 개의 API 서버들로 부하를 분산해준다. - 공통 기능 처리
로그처리나 인증은 API Gateway가 없다면 각 서버마다 필요하지만, 이를 통합하여 변경이 있떠라도 API Gateway만 배포하면 된다. - 다수의 엔드포인트 제공
같은 API라도 다수의 엔드포인트로 API를 제공할 수 있다.
또한 엔드포인트별로 속성을 부여해 같은 API라도 서로 다른 속성을 부여해 제공할 수 있다. - 개발자 포털
유튜브 API 나 페이스북 API처럼 API 사용자가 들어가서 사용 가이드를 볼 수 있는 곳이 개발자 포털이다.
개발자 포털은 API 액세스를 위한 토큰을 발급하거나, 매뉴얼 제공, 테스트베드를 제공하는 등의 기능을 한다. - 변환 로직
API Gateway는 API 변환 기능도 있는데, 이는 프로토콜을 변환하는 것도 있고, 메시지 포맷이나 메시지 교환 패턴 등을 변환하기도 한다. - 서비스 버스
API Gateway를 중앙 버스 구조로 만듦으로써 통신 토폴로지를 단순화할 수 있다. - 매시업
이는 여러 API를 묶어서 새로운 API를 만드는 기능이다.
- QoS 컨트롤
API에 대한 호출을 통제할 수 있다. API를 유료로 서비스한다면 반드시 필요한 기능이다.
- API 인증처리와 키 관리
-
계정 관리
회원이 있는 서비스라면 사용자 관리 기능이 존재한다.
시스템의 규모가 커지고 사용자의 종류도 많아지면 독립된 공통 컴포넌트인 IDM(Identity Management System)을 사용한다.- 계정 관리 시스템의 주요 기능
- 사용자 관리
- 사용자 계정 생명주기 관리: 가입 신청, 승인, 계정 활성화, 정지, 탈퇴 등 필요에 따른 전반적인 계정의 생명주기 관리
- 사용자 로그인 정보관리: 계정과 비밀번호 관리.
- 사용자 정보 관리: 로그인 정보 외의 보가적인 프로필 정보 관리.
- 사용자 역할 관리: IDM에서는 역할을 정의하고 역할과 사용자간 관계를 관리하는 기능을 제공해야 한다.
- 계정 정보 프로비저닝: 계정 정보가 변경되었을 때, 연계된 다른 시스템에 전달.
- 접근 제어: 시스템의 기능에 대해 접근을 제어할 수 있도록. 여러 시스템간의 접근제어나 접근 수단에 따라서도 제어 메커니즘이 달라진다.
- 사용자 인증/권한인가 처리
- SSO(Single Sign On): 통합된 계정으로 로그인해서 다른 독립된 시스템을 같이 사용할 수 있음.(네이버 계정으로 카페, 블로그 같이 사용하는 것)
- 계정 정보 페더레이션: 계정 정보 제공자(Idp)와 계정 정보 사용자(Sp)를 연계하는 것. (페이스북 계정으로 타사 서비스에 로그인하는 것)
- 타 서비스 연동: 위에서 언급한 것처럼 서로 다른 시스템을 연동하는데, 이 때 연동에 사용되는 기술로는 SAML, Open ID, OAuth 등이 있다.
- 감사와 리포팅: 감사는 누가 무엇을 했는가에 대한 기록과 추적. 리포팅은 기록을 표나 그래프 형태로 보여주는 것.
- 계정 관리 모델
- 개별 분산 모델: 각각의 독립된 서비스가 서로 다른 계정 체계 사용. 네이버는 네이버 아이디로, 다음은 다음아이디로 로그인하는 것.
- 중앙 집중형 모델: 모든 서비스가 중앙집중화된 계정 관리 시스템 사용.
- 페더레이션 모델: 각 서비스는 독립된 계정 시스템을 사용하지만 페더레이션을 통해 연동.
- 계정 관리 시스템의 주요 기능
-
시스템 연동
대외 시스템 또는 대내 시스템간 연동을 수행하는 시스템을 통합 시스템이라 하고, 엔터프라이즈에서는 EAI 아키텍처로 구현된다.
통합 시스템은 대내 거래 통합 계층, 대외 거래 통합 계층, 배치 거래 통합 계층으로 구성된다.-
대내 거래 통합 계층: 내부 시스템간의 업무 통합
-
대외 거래 통합 계층: 기업간의 거래. 트랜잭션 보장이 불가능하므로 비교할 수 있는 거래 로그 정보 저장이 중요
-
배치 거래 통합 계층: 대용량 데이터를 송신 시스템에서 수신 시스템으로 전송. 다른 시스템간의 거래 정보를 맞추기 위한 것과 분석을 위한 정보용으로 나뉜다.
-
인터페이스: EAI의 가장 기본적인 아키텍처 모듈. 송수신 시스템을 통합하는 부분에 대한 아키텍처
- Inbound: 송신 시스템과 연동하여 요청을 받고 응답을 송신 시스템에 보내는 역할. 어댑터와 메시지 변환으로 구분
- Mediation: 입력된 메시지를 가공하고 중계. 내용에 따라 적절한 수신 시스템으로 라우팅, 맵핑, 메시지 교환 패턴을 처리.
- Outbound: 처리가 끝난 메시지를 수신 시스템에 전달
-
모니터링 및 장애 관리
-
거래 로그: 송수신 내용을 확인하고 EAI 시스템 장애 시 송수신 시스템과 거래 내용을 맞춰 복구하는데 사용된다. 로그에 사용되는 ID는 전사 표준 전문의 헤더에 정의하고 공통된 ID 사용.
로그 접근 방식은 파일과 DB. 파일은 IO 성능은 빠르고 DB 장애 의존성 적은 대신 추적이 불편. DB는 이와 반대. -
에러 처리 로직: 장애감지, 장애원인 리포팅, 장애해결의 단계로 구성. 장애에 대한 처리 정책(Fault-Policy)를 인터페이스마다 정의하고, 장애가 발견, 리포팅되면 Error-Hospital이라는 곳에 모은다.
-
장애 처리 정책: Error-Hospital에 모인 장애는 무시, 보고, 재시도, 수동처리의 4가지 정책으로 정의할 수 있다.
-
-
Business Layer
비즈니스 컴포넌트는 요청을 받아서 데이터베이스나 파일에서 데이터를 쓰거나 읽어서 비즈니스 로직에 따라 처리한다.
-
동기 요청 처리
동기적 요청은 일반적인 요청-응답 형식이다.
일반적인 시스템 호출 방식이고, 가장 기본적이지만 다음과 같은 문제가 존재한다.- 생산성 문제
단순한 REST API를 개발하더라도 자바의 경우 수많은 기술이 필요하다.
그래서 요즘은 이런 API 개발은 자바 플랫폼 대신 파이썬, 루비 Node.js 등의 간결한 언어를 사용해 빠르게 개발한다.
다만 안정성, 견고성이 필요한 부분에서는 여전히 자바를 사용한다. - 용량 문제
자바 기반의 애플리케이션은 다음과 같은 스레드 풀 구조를 사용한다.
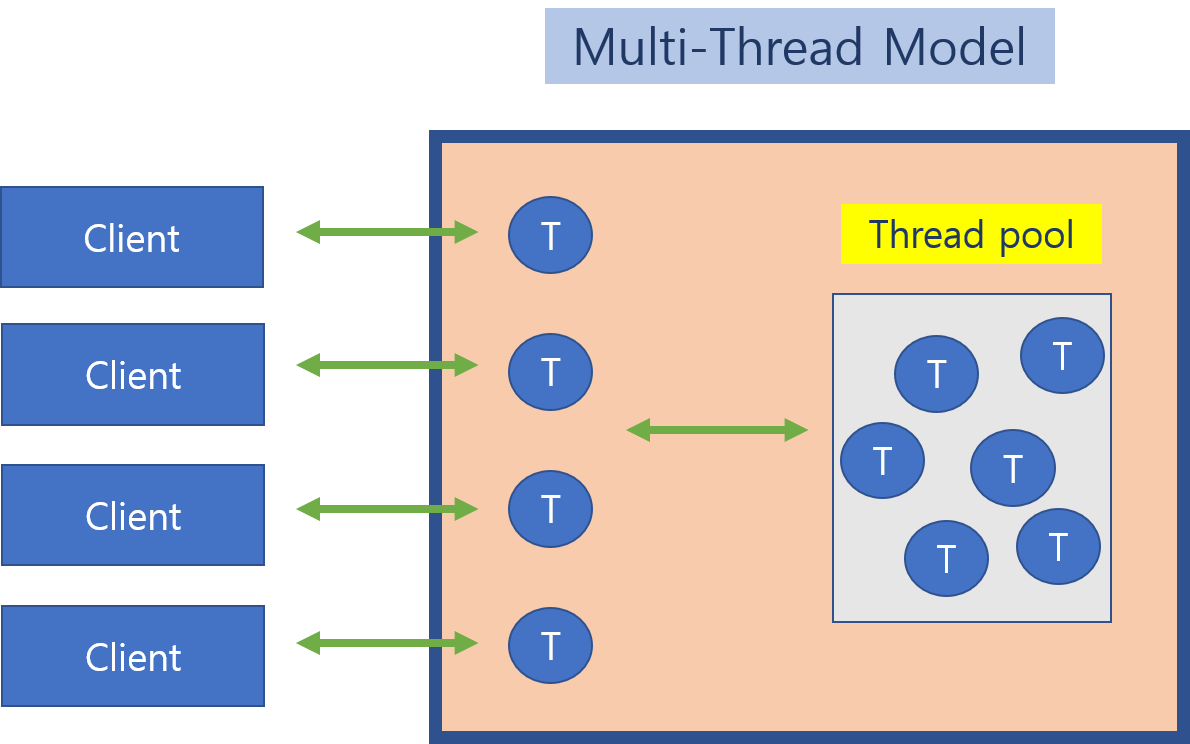
요청이 오면 스레드를 꺼내 처리하고 처리가 끝나면 스레드를 풀로 돌려보낸다.
동시에 처리할 수 있는 요청의 수는 스레드 풀의 스레드 수까지만 가능하고, IO작업이 있을 경우 IO호출을 해놓고 스레드는 CPU를 사용하지 않는 비효율성이 존재한다.
현대 대용량 서비스는 수만 건의 요청을 함께 처리해야 하는데 이런 환경에서는 처리하기가 어렵다.
따라서 Node.js처럼 싱글 스레드 기반의 비동기 처리가 가능한 서버를 사용하기도 한다. - SN 아키텍처
분산 처리 시스템을 구성하는 여러 개의 노드가 서로 종속성을 가지지 않고 독립적으로 작동하는 아키텍처이다.
노드간 종속성은 상태 정보로 인해 발생하는데, 이러한 상태 정보를 다른 계층(예전에는 클라이언트의 쿠키, 최근에는 데이터베이스)에 저장함으로써 종속성을 제거할 수 있다.
- 생산성 문제
-
데이터 그리드를 이용한 상태 정보 저장소
데이터 그리느는 여러 개의 서버와 메모리를 연결해 저장소를 만들어 놓고 이를 애플리케이션 서버에서 접근해 사용하는 메모리 클러스터이다.
서버간 클러스터링으로 인해 장애가 발생해도 자동으로 fail over가 가능하고, 확장성을 제공한다.
하지만 메모리에 저장되므로 전체 서버가 다운된다면 모든 데이터가 날아가게 된다. -
메시지 큐를 이용한 비동기 요청 처리
시간이 오래 걸리는 대규모 작업의 경우 비동기로 요청을 처리하는 것이 유리하다.
비동기적으로 처리할 때는 메시지 큐를 사용해 요청을 쌓아 놓고 응답과 상관 없이 요청을 처리하게 된다.-
에러 처리
비동기식 처리는 요청에 대한 응답을 받지 않기 때문에 요청이 제대로 처리되었는지 알 수 없다.
메시지 큐에서 꺼낸 메시지가 제대로 처리되지 않으면 메시지는 그대로 유실되므로, 이에 대한 대비가 필요한데, 일반적으로 에러가 발생한 메시지는 에러 큐로 전달되도록 설정한다.
이후의 처리방법에 대해서는, 재처리, 무시, 알림, 사람이 처리하는 방식을 사용한다. -
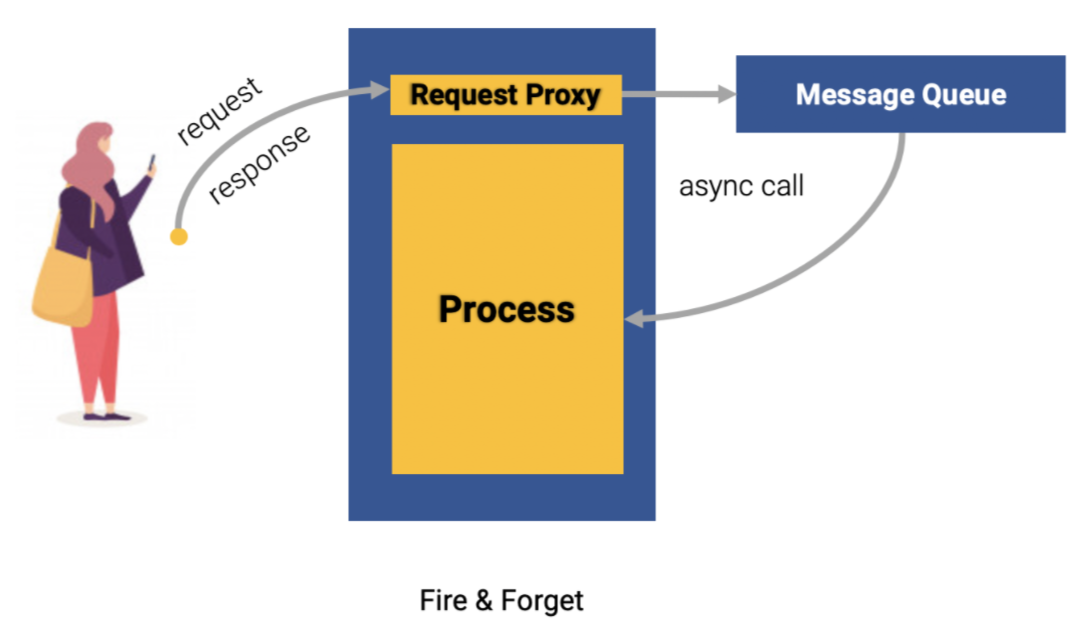
비동기 메시지 패턴
메시지 큐의 메시지를 처리하는 패턴은 다음과 같다.Fire and Forget

큐에 메시지가 들어갔으면 결과에 관계 없이 응답을 기다리지 않고 바로 반환하는 방식Publish & Subscribe
메시지가 등록된 모든 구독자에게 전달되므로 1:N 관계의 비동기 처리를 구현할 때 사용
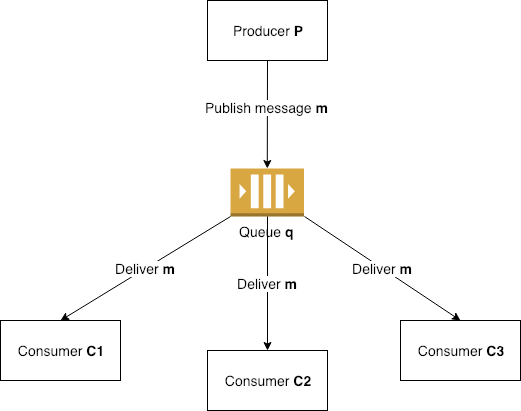
Routing
큐에 저장된 메시지를 조건에 따라 특정 비즈니스 컴포넌트로 라우팅하는 방식
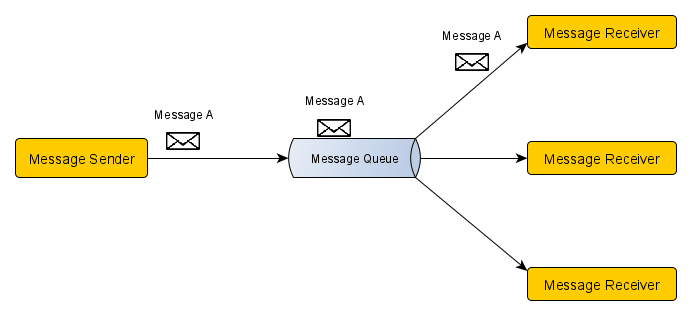
Call Back
일반적으로 비동기 처리는 처리 결과에 대한 응답을 받을 수 없지만 콜백 패턴을 사용해 응답을 받도록 할 수 있다.
콜백 방식을 사용하기 위해서는 콜백 주소와 Correlation ID를 통해 어느 요청에 대한 응답 메시지인가를 식별할 수 있어야 한다. -
메시지 큐 구성 시 고려해야 할 사항
-
성능 및 페일오버를 고려한 Persistence: 메모리, 디스크 또는 RDBMS를 고려할 수 있다. 각각 장단점이 있으므로 이를 고려해 결정
-
펜딩 메시지로 인한 Out of Memory: 메모리에 메시지를 저장한다면, 적체된 메시지가 계속 쌓여 발생하는 메모리 부족 에러에 주의해야 한다.
-
트랜잭션 지원 기능
높은 신뢰성이 필요하다면 트랜잭션 지원 기능도 고려해야 한다. -
클러스터링 기능
클러스터링을 지원하는 메시지 큐는 페일오버 기능과 분산처리로 인한 장점이 있으므로 고려해 볼 만하다.
-
-
-
임시 파일 작업 공간
비동기 처리나 분산 환경에서는 작업을 위해 임시로 파일을 저장하는 공간이 필요하다.
이러한 공간은 S3와 같은 아카이빙 스토리지를 사용할 수 있지만, 이 경우 파일 시스템에 직접 마운트하는 것이 불가능하므로 로컬 디스크에 파일을 업로드하는 작업이 추가로 필요하다. -
메시징 프로토콜
일반적으로 메시징 프로토콜은 HTTP JSON 기반의 REST 방식을 많이 사용한다.
이는 단순하고 텍스트 기반이라는 점에서 플랫폼에 상관 없이 사용할 수 있어 선호되지만,
속도 측면에서 디메리트가 존재한다.
그렇기 때문에 바이너리 프로토콜을 사용하여 성능과 용량 측면에서 효율성을 추구할 수 있지만, 바이너리 포맷을 정의하고 구현하는 것은 손이 많이 드는 작업이다.
그래서 거대 IT 기업에서 바이너리 기반의 통신을 지원하기 위해 PB나 Thrift와 같은 오픈소스화하여 공개하고 있다.
Persistent Layer
Persistent Layer는 처리할 데이터를 저장하는 공간이다. 전통적으로는 RDBMS를 많이 사용했지만 최근에는 NoSQL을 사용한 대용량 저장 서비스도 활용하고 있다.
-
RDBMS
RDBMS는 요청을 바로 처리하는 OLTP와 데이터를 모아서 분석하고 리포팅하는 OLAP로 크게 나눌 수 있다.
OLTP를 위한 RDBMS 설계 시 고려할 만한 아키텍처로는 다음과 같은 것들이 있다. -
Query off Loading
DB 트랜잭션의 70~90%는 읽기와 관련된 작업이다. 따라서 Read와 Update 작업을 분리함으로써 DB의 처리량을 향상시킬 수 있다.
DB를 Master DB, Staging DB, Slave DB로 나누어, Master DB에는 쓰기만을 허용하고 Slave DB를 읽기 목적으로 사용한다.
Master DB의 내용을 Staging DB에 복제하고, Staging DB에 복제한 내용을 Slave DB에 복제한다.
여기서 Staging DB의 역할은 Master DB에서 복제할 때의 부하를 줄이기 위한 경유지이다. -
샤딩
샤딩은 데이터베이스의 용량 한계를 극복하기 위한 기술이다.
샤딩으로 데이터를 분산할 때는 다음과 같이 수평 또는 수직으로 나눌 수 있다.
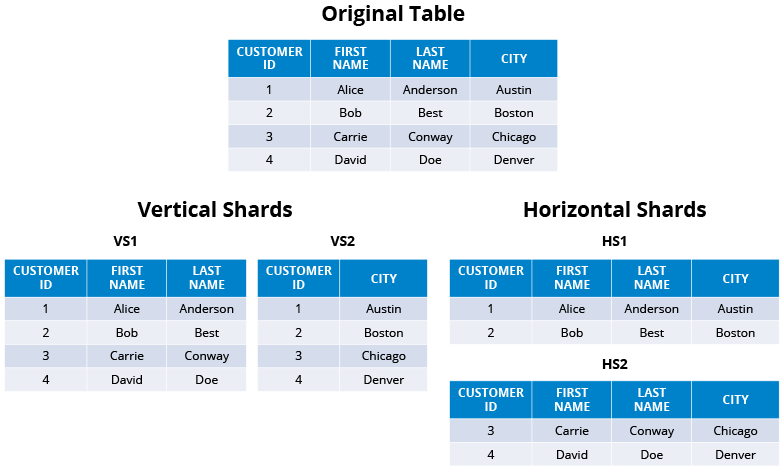
데이터를 샤딩할 때는 의미 있는 데이터를 기준으로 나눌 수 있는데, 이 경우 편중 현상이 발생할 수 있음에 유의해야 한다.
한편 의미 없는 데이터(해시 방식)을 사용하면 데이터를 골고루 분산시켜 배치할 수 있다. -
파일 시스템
파일 시스템은 각 프로그래밍 언어의 API를 사용해 접근하지만, 실제 하드웨어나 파일 시스템의 구조는 SDK, 운영체제, 파일 시스템, 스토리지 하드웨어 계층으로 복잡하게 구성되어 있다.
최근에는 S3와 같은 object storage를 사용해 많은 사용자가 동시에 접속하는 대용량 파일 서비스 구조를 구축하기도 한다.
Analysis Layer
Analysis Layer는 트랜잭션 처리에 의한 결과와 로그를 분석하는 계층이다.
-
전통적인 OLAP 방식의 분석
전통적인 기업형 업무에서는 RDBMS 기반의 분석 시스템을 사용해왔다.- ETL
ETL(Extract Transform Loading)은 여러 데이터 소스로부터 데이터를 수집해 변환 및 저장하는 역할을 한다. - 데이터 웨어하우스와 데이터 마트
OLTP 시스템에서 수집된 모든 데이터는, 중앙집중화된 데이터 웨어하우스에 우선 저장된다.
그리고 각 부서에 따라 정제되어 데이터 마트에 저장되는데, 이는 부서의 업무 성격에 따라 구조가 다르고 자유롭게 변경할 수 있도록 하기 위함이다.
- ETL
-
Map & Reduce 기반의 분석
대용량 데이터를 다루게 되는 경우가 많아지면서 기존의 RDBMS를 사용한 분석은 용량의 한계에 다다르게 되었다. 이를 해결하기 위해 나온 것이 하나의 큰 데이터를 여러 조각으로 나눠서 처리(Map) 후 처리 결과를 모아서 합치는(Reduce) 방식의 분석을 사용하게 되었다.
Map & Reduce 방식은 대용량 분석이 가능하지만, 데이터 수집, 변환 및 분석 리포팅의 전 과정을 직접 구현해야 한다는 단점이 있다. -
실시간 분석
전통적인 OLAP 방식이나 Map & Reduce 방식 모두 결국은 배치 방식을 통해 처리되기 때문에 신속한 의사결정을 위한 도구로 사용하기 어렵다.
그래서 실시간 분석을 통해 빠르게 대응할 수 있는 방식이 인기를 얻고 있다.
OAM Layer
OAM은 Operation, Administration & Monitor의 약자로, 시스템 운영자의 입장에서 필요한 관리 및 모니터링 기능을 뜻한다.
-
CMDB(Configuration Management DB)
분산 시스템이나 여러 컴포넌트가 조합된 시스템을 구축할 경우, 각각의 설정 정보를 저장하기 위한 공용 데이터베이스가 필요한데, 이 때 사용하는 것이 CMDB이다. -
모니터링
시스템을 운영함에 있어 시스템의 건전성을 확인하고 장애 발생의 전조를 인식하며, 장애 발생시 이를 추적할 수 있도록 하는 것이 모니터링이다.
모니터링은 인프라스트럭처, DBMS, 미들웨어, 애플리케이션 각각의 계층에서 수행된다. -
로그 관리
로그는 시스템에서 발생하는 모든 행위에 대한 기록이다.
최근 빅데이터를 쉽게 활용할 수 있게 되면서 그 중요성이 더욱 올라간 로그는, 어떤 종류의 로그를 수집하고, 어떻게 로그를 수집하고, 모인 로그를 어떻게 분석하고 사용하고, 분석된 결과를 어떻게 볼 것인가에 대한 관점을 설정하는 것이 중요하다.
클라우드 인프라
기존의 온프레미스 방식의 인프라는 구매해 설치하거나 임대가 필요했는데, 클라우드 컴퓨팅이 발달하면서 원격의 컴퓨팅 자원을 손쉽고 빠르게 사용할 수 있게 되었다.
-
클라우드 컴퓨팅의 배포 모델에 따른 분류
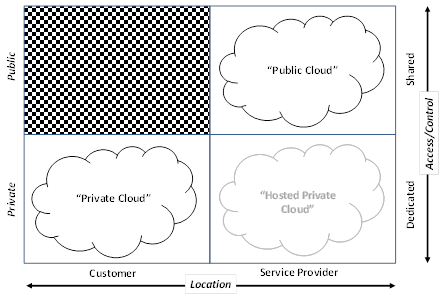
-
클라우드 컴퓨팅의 서비스 단계에 따른 분류
-
IaaS(Infrastructure as a Service)
IT 서비스를 제공하기 위한 주요 인프라 자원을 공유 자원 형태로 관리하고, 이를 나눠서 제공하는 형태의 서비스이다.
사용자는 인프라 위의 리소스를 할당받아 OS와 미들웨어를 각자 설치하여 서비스를 이용한다.
가장 유명한 것은 AWS의 서비스이다. -
PaaS(Platform as a Service)
IaaS가 대용량의 사용자를 가진 서비스에서 사용한다면 Paas는 그보다 한 계층 위에서 미리 구현된 서비스 라이브러리도 제공하여 애플리케이션을 개발할 수 있도록 돕는다. -
SaaS(Software as a Service)
소프트웨어 서비스로 완성된 형태의 애플리케이션을 서비스하는 형식이다.
애플리케이션의 사용에 대해서만 비용을 지불하고 그 외에 대해서는 일절 관여하지 않는다.
-
-
클라우드 컴퓨팅의 장단점
-
쉽고 빠르다
웹 콘솔을 통해 인프라를 배포하고 설정할 수 있기에 전문 지식이 없어도 네트워크 구성이 가능하다. 또한 클릭 몇 번만으로 지구 반대편에도 서버를 빠르게 올릴 수 있다. -
초기 투자 비용이 저렴
기본적으로 쓴 만큼 돈을 내는 구조이기 때문에 초기에 적은 비용으로도 서버를 사용할 수 있다. -
무제한의 확장성
서버의 용량이 모자라면 바로 새로운 서버를 설정하면 되기 때문에 손쉽게, 무제한의 확장이 가능하다. -
싸지 않음
서버에 대한 비용뿐 아니라 네트워크, 디스크에 대한 비용이 모두 별도로 계산되므로, 사용하지 않는 서버를 켜놓게 되면 서버 외의 비용도 포함되어 많은 비용이 발생한다. -
성능이 생각보다 떨어짐
결국 다른 사용자와 인프라를 공유해서 쓰기 때문에 CPU 성능은 물론 IO 성능도 온프레미스에 비하면 많이 떨어진다. -
다른 아키텍처를 가져야함
성능 제약으로 인해, 아키텍처도 이에 맞추어 구성해야 한다. -
불안정
AWS의 EC2 인스턴스의 SLA는 현재 99.99%이다. (출처: https://cloudonaut.io/aws-sla-are-you-able-to-keep-your-availability-promise/)
그런데도 생각보다 서버가 죽는 경우가 잦다.
다른 사용자와 하드웨어를 공유하는 것이기 때문에 절대적인 성능 예측이 힘들다.
-
글로벌 서비스 아키텍처
여러 국가에 걸쳐 서비스를 하게 될 경우, 다양한 케이스를 고려한 아키텍처를 설계해야 한다.
-
법적인 이슈에 대한 검토
국가별로 법적인 제약사항이 다를 수 있기 때문에 이를 확인한 후에 시스템을 디자인해야 한다. -
시스템 위치 선정
주로 유럽이나 미국에 두는 것이 일반적이며, 아시아 지역을 위해서는 싱가포르, 홍콩, 일본 등에도 센터를 둘 수 있다. -
운영에 관련된 고려 사항
데이터 센터가 있는 곳에 두는 것이 가장 좋지만, 고객 대응이 있다면 언어 권역별로 인건비가 싼 곳을 택한다. -
기술적인 고려 사항
-
센터의 레벨과 분류
데이터 센터의 경우 게층형으로 나누어 HQ(Head Quarter), RC(Regional Center), Edge로 분류할 수 있다.
HQ는 전체 센터의 중심으로, 공통적으로 필요한 시스템이 위치한다.
RC는 각 권역을 서비스한다.
Edge는 권역에서 커버하지만 네트워크 속도 등의 영향을 받거나 법적 이슈를 피해가기 위해 일부의 시스템만 위치시킬 때 사용한다. -
Request Routing
클라이언트는 RC, HQ 아무 곳으로나 동일한 API를 호출할 수 있고, 그 다음 실제 비즈니스 로직이나 데이터가 있는 곳으로 요청이 전달된다. -
센터 간의 데이터 복제
데이터 복제는 권역에 걸쳐 같은 데이터를 제공하기 위해서 또는 장애시 fail over를 위해 필요하다.- 솔루션 레벨: 솔루션 자체기능을 사용하는데 RDBMS의 경우 CDC(Change Data Capture), 즉 변경 로그를 사용해 복제한다.
- 애플리케이션 레벨: ETL 솔루션등으로 업데이트된 내용을 복제 대상에 INSERT, UPDATE하는 방식이다. 운영 테이블을 그대로 사용할 수는 없다.
- 인프라 레벨: 디스크 자체를 DRBD를 사용해 블록레벨에서 복제한다.
-
데이터 복제 토폴로지
- Multi Master: 모든 데이터 노드간에 양방향으로 데이터 복제가 가능하고, 각 노드에서 데이터에 대한 읽기, 쓰기가 가능
- Master Slave: Master에서 Slave 방향으로만 복제가 가능하고, Master 노드에서만 쓰기가, Slave 노드에서는 읽기만 허용한다.
- Multi Write: 데이터베이스간 복제를 사용하지 않고 복제가 필요한 데이터베이스 모두에 동시에 쓰는 방식이다.
-
L10N과 I18N
Localization을 줄여서 L10N이라고 하며, 소프트웨어를 지역에 맞게 수정하는 것으로, 언어나 단위, 키보드 입력체계를 지역에 맞추어 변경한다.
Internationalization 을 줄여서 I18N이라고 하며, 소프트웨어가 동시에 여러 지역화를 지원할 수 있는 구조로 되어 있는 것을 정의한다.
국제화와 지역화는 단순히 언어를 변경하는 것에 그치지 않고, 문화적 차이까지 고려해야 한다.
-
2. NoSQL
등장 배경
기존의 컴퓨팅 시스템은 기업의 복잡한 데이터를 처리, 분석하기 위한 것으로 그 양에는 한계가 있었다.
하지만 SNS가 발달하고 전세계를 대상으로 서비스하는 기업이 늘어나면서, 기존의 RDBMS를 사용한 데이터 처리는 용량의 한계가 발생했고, 데이터 자체도 복잡한 데이터보다 대량의 단순한 데이터로 패러다임이 이동하게 되었다.
이러한 수요를 바탕으로 기존 RDBMS 형태의 관계형 데이터베이스가 아닌 다른 형태의 데이터 저장 기술을 통칭하여 NoSQL이라고 부르며 시장에 등장하게 되었다.
NoSQL 특징
-
데이터 간의 관계를 정의하지 않음
RDBMS처럼 데이터의 관계를 외래 키 등으로 정의하지 않고, 조인도 불가능하다. -
대용량의 데이터 저장
-
분산형 구조
하나의 고성능 머신에 데이터를 저장하는 것이 아니라 서버 수십 대를 연결하여 데이터를 분산 저장하는 구조이다. 따라서 서버에 장애가 났을 때도 데이터 유실이나 서비스 중지가 없다. -
고정되지 않은 테이블 스키마
NoSQL은 컬럼의 값의 타입도 이름도 제한이 없다.
CAP이론
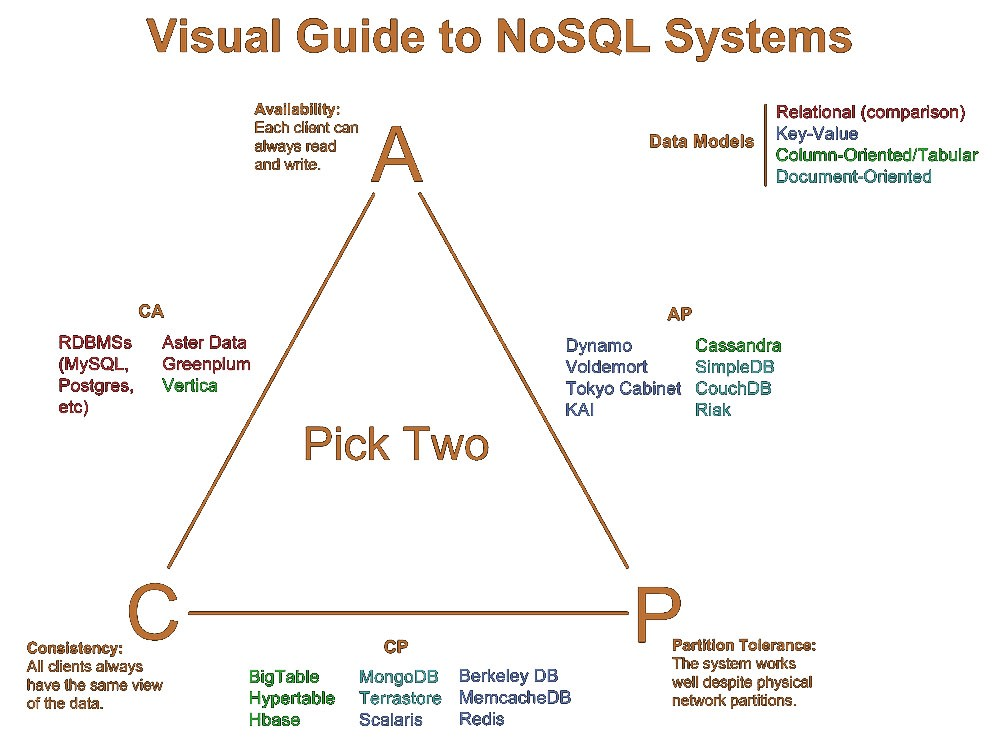
CAP 이론은 분산 컴퓨팅 환경이 일관성(Consistency), 가용성(Availability), 분산 허용(Partitioning Tolerance)의 3가지 특징으로 이루어져 있고, 이 중 두 가지만 만족할 수 있다는 이론이다.
NoSQL은 대부분 이 이론을 따르고 있으므로, NoSQL 선택시 이 이론에 대한 이해를 바탕으로, 업무의 특성에 맞게 선택해야 한다.
NoSQL 분류
-
Key/Value Store
가장 기본적인 방식으로, 고유한 키에 하나의 값을 가진 형태이다.
또한 이를 확장하여 Column Family라는 개념을 통해 key를 RDBMS의 PK, value를 (Column, Value) 조합으로 구성할 수 있다. -
Ordered Key/Value Stroe
Key/Value Store를 확장하여 저장 방식은 동일하나 내부적으로 키를 순서대로 정렬해서 저장한다.
NoSQL의 경우 정렬 기능을 제공하지 않기 때문에 이러한 기능이 자동으로 적용되는 것은 훨씬 유리하다 할 수 있다. -
Document Key/Value Store
Key/Value Store와 같은 구조로 저장하지만, 저장되는 값의 데이터타입이 Document라는 타입으로, XML, JSON, YAML과 같은 구조화된 데이터 타입을 통해 계층 구조를 표현할 수 있다.
사용시 주의점
-
과연 NoSQL이 필요한가
새로운 기술과 제품군을 사용하기 위해 들어가는 교육, 개발비용은 적지 않다.
현재 업무에 NoSQL이 정말 적절한지, 그만큼의 용량이 필요한지를 먼저 판단해야 한다.
우선 MySQL등 기존에 사용하던 기술을 사용하다가 도저히 용량을 감당할 수 없을 때 전환하는 것도 나쁜 선택이 아니다. -
적절한 제품군 선정
RDBMS라고 하면 대부분 비슷한 방식을 사용해 데이터를 저장하지만 NoSQL이라고 다 같은 방식이 아니다. 오히려 제품군마다 전혀 다른 특성을 가지고 있다. -
데이터 모델링
RDBMS가 데이터 모델링부터 시작해, 정규화를 통해 테이블을 만들어내고 해당 테이블에 대해 쿼리를 수행하여 결과를 뽑아낸다면 NoSQL은 정반대로 접근해야 한다.
먼저 수행할 쿼리를 정의하고 이에 맞추어 테이블을 정의하고, 성능 향상을 위해 중복을 허용해 테이블을 정의한다. -
RDBMS와 적절한 혼합
NoSQL은 어디까지나 대용량 데이터를 빠르게 저장/쿼리하기 위한 기술이다.
따라서 관계 정의가 필요하거나 복잡한 데이터의 경우에는 RDBMS에 저장하고 실제 데이터는 NoSQL에 저장하여 적절하게 혼합하여 사용하는 설계가 필요하다. -
하드웨어 설계 병행
처음부터 하드웨어 설계를 병행해야 한다.
또한 네트워크 카드도 물리적으로 분리하고, 같은 용량이라도 몇 개의 디스크를 사용할지와 같은 사항도 NoSQL을 도입하기 전에 검토해야 한다. -
운영 및 백업
NoSQL은 복잡도가 높고 분산되어 있으며, 하드웨어 관제까지 필요하기 때문에 전문적인 관리자가 있어야 하며, 모니터링 체계도 수립되어야 한다.
특히 용량 증설 시 데이터 재분배 작업이 필요할 수 있고 이 때 데이터가 유실되는 경우도 있기 때문에 증설에 관한 정책도 필요하다.
NoSQL 데이터 모델링
-
NoSQL과 RDBMS의 데이터 모델링 차이
-
개체 모델 지향이 아닌 쿼리 결과 지향 모델링
이미 설명한 것처럼, 둘의 모델링 방식은 정반대로 진행된다.
NoSQL은 복잡한 쿼리 기능이 없으므로 도메인 모델에서 어떤 쿼리 결과가 필요한지 미리 정의하고, 이 결과를 얻기 위한 데이터 저장 모델을 역순으로 디자인해야 한다. -
정규화가 아닌 역정규화
쿼리의 효율성을 위해 데이터를 정규화하지 않고, 의도적으로 중복된 데이터를 저장하는 식으로 비정규화된 데이터 모델 설계 방식으로 접근해야 한다.
-
데이터 모델링 패턴
-
기본적인 데이터 모델링 패턴
-
역정규화
역정규화는 중복을 허용하는 것이다. NoSQL은 조인 기능이 없으므로 역정규화를 통해 테이블간의 조인 없이 필요한 정보를 1번의 IO로 가져올 수 있도록 한다. -
집계(Aggregation)
NoSQL의 특성으로는 스키마가 없다는 것이 있다. 이로 인해 RDBMS처럼 정해진 구조에 맞춰서 데이터를 넣을 필요가 없고, 따라서 여러 엔티티를 하나의 테이블로 쉽게 바꿀 수 있다. -
애플리케이션 조인
NoSQL에서 반드시 조인을 수행해야 할 경우에는 애플리케이션 단에서 로직으로 처리해 준다.
-
-
확장된 데이터 모델링 패턴
-
Atomic Aggregation
NoSQL에서는 두 개 이상의 테이블을 업데이트할 때 트랜잭션이 보장되지 않는다.
다만 테이블 하나에 대해서는 원자서을 보장하므로, 테이블을 하나의 테이블로 합쳐 트랜잭션 불일치 문제를 해결할 수 있다. -
Index Table
인덱스가 없는 NoSQL은 키 이외의 필드를 이용하여 검색하면 전체 테이블을 스캔하거나, 키 이외의 필드에 대해서는 검색이 불가능하다.
이 때문에 인덱스를 위한 별도의 인덱스 테이블을 만드는 방식을 채택하기도 한다. -
Composite Key
키를 정의할 때 콜론(:)을 사용해 복합 키를 사용한다. 이 키를 어떻게 정의하냐에 따라 정렬 기능이다 그룹화를 구현할 수 있기 때문에 복합 키가 중요하다. -
Inverted Search Index
검색 엔진은 사이트의 모든 페이지의 단어를 색인하여 URL에 맵핑하여 저장한다.
이 때 검색 키워드를 키로, URL을 값으로 하는 테이블을 만드는데, 이 방식을 Inverted Search Index라고 한다.
-
NoSQL 데이터 모델링 절차
-
도메인 모델 파악
저장하고자 하는 도메인을 파악하여 데이터 개체와 개체 간의 관계를 정의하고 도식화한다.
RDBMS의 모델링 방법과도 유사하다. -
쿼리 결과 디자인
도메인 모델을 기반으로 애플리케이션에 의해 쿼리되는 결괏값을 먼저 결정한다.- 패턴을 이용한 데이터 모델링
이 과정에서 역정규화를 통해 데이터를 중복으로 저장할 수 있도록 한다.
특히 Composite Key를 사용하여 정렬을 가능하도록 할 수 있다. - 후보 선정과 테스트
모델링한 데이터 구조를 효과적으로 실행할 수 있는 NoSQL을 찾는다. 실제로 부하 테스트, 안정성, 확장성 테스트를 거친 후 가장 적합한 솔루션을 선택한다.
- 패턴을 이용한 데이터 모델링
